Conditional KRR: Injecting Unpenalized Features into Kernel Methods with Applications to Kernel Thresholding
Pith reviewed 2026-06-29 22:27 UTC · model grok-4.3
The pith
Conditional kernel ridge regression can be reduced to standard kernel ridge regression on a residual kernel, at the cost of an O(1/sqrt(N)) term in expected test risk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
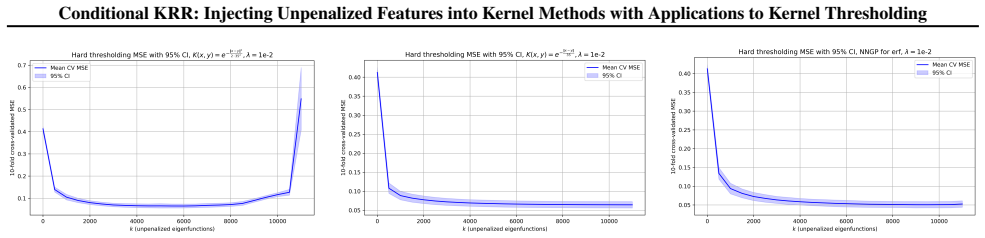
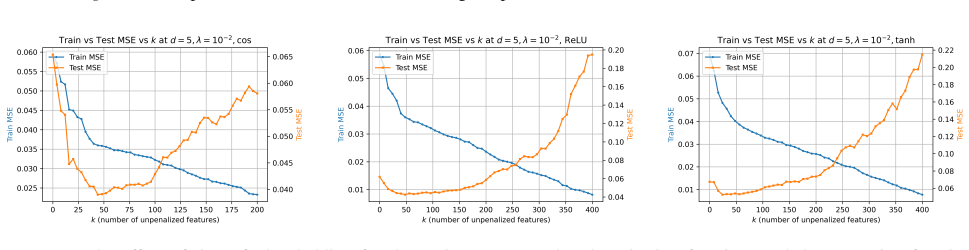
The behavior of conditional KRR reduces to that of KRR with the residual kernel, with an additional term in the expected test risk bounded by O(1/sqrt(N)), where the constant depends on F and the input distribution. This holds for cases where F is the first k principal eigenfunctions or k random features from the Mercer decomposition of K.
What carries the argument
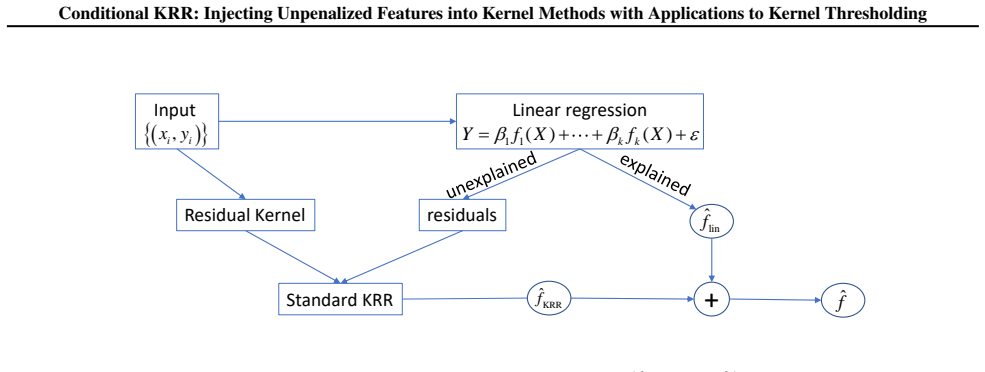
The residual kernel obtained after removing the component explained by the function class F, which allows reducing conditional KRR to standard KRR.
Load-bearing premise
The premise that the F-component of the regression function is more pronounced than the residual part is used to interpret the practical advantage over standard KRR.
What would settle it
Observing that the test risk difference between conditional KRR and residual KRR grows faster than O(1/sqrt(N)) on increasing sample sizes would falsify the reduction result.
Figures


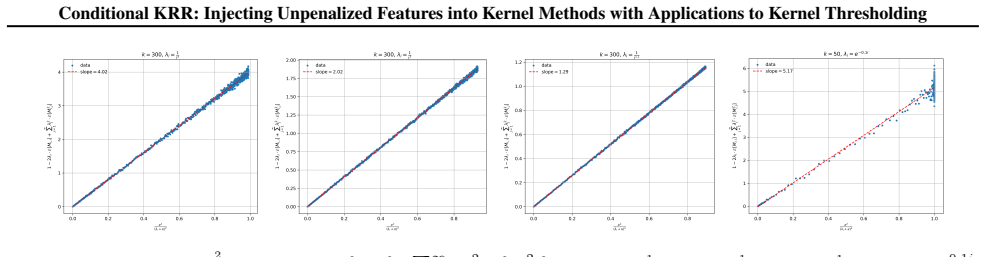
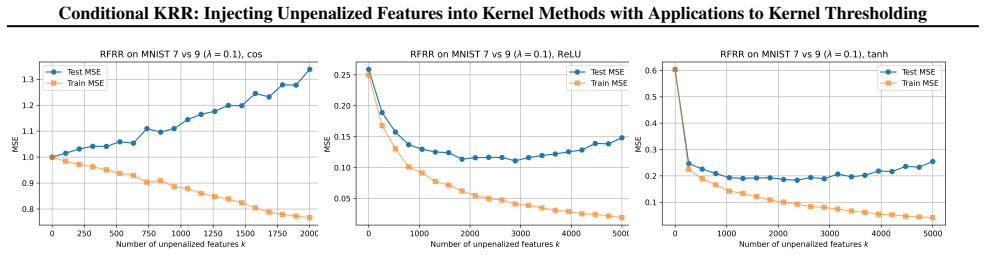
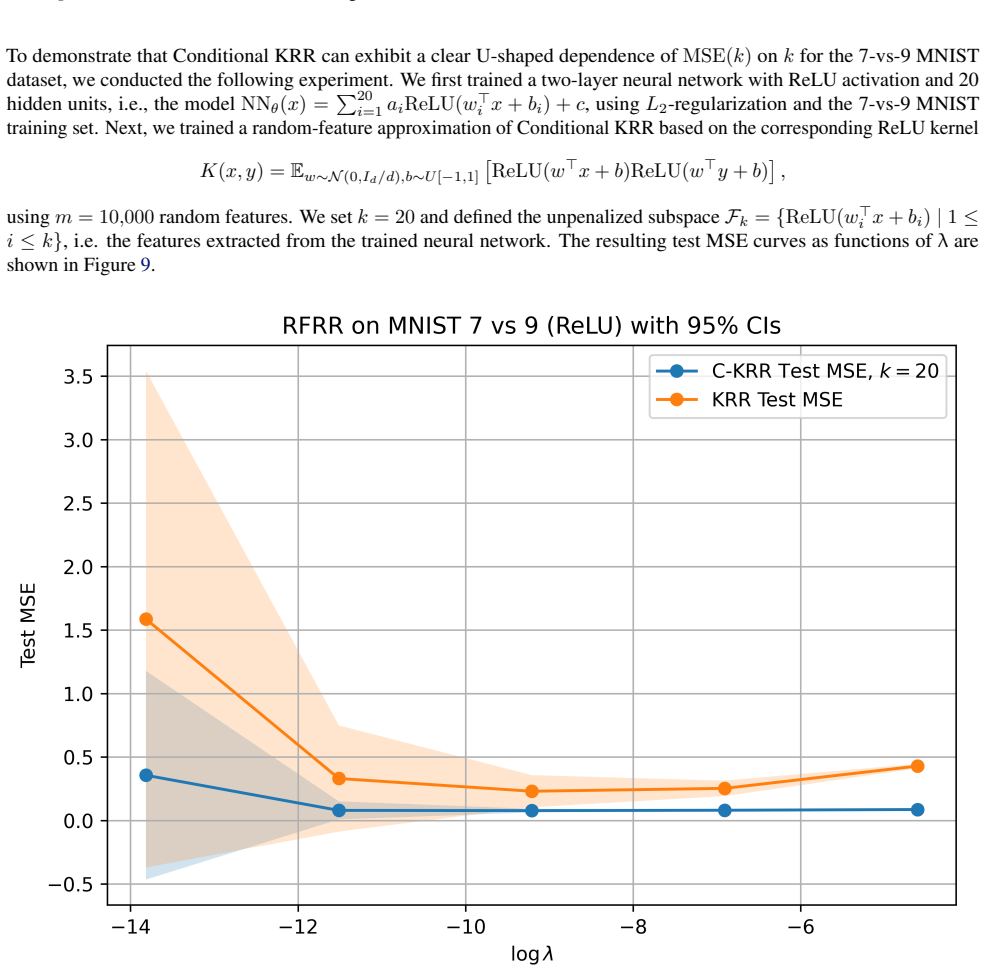
read the original abstract
Conditionally positive definite (CPD) kernels are defined with respect to a function class $\mathcal{F}$. It is well known that such a kernel $K$ is associated with its native space (defined analogously to an RKHS), which in turn gives rise to a learning method -- called conditional kernel ridge regression (conditional KRR) due to its analogy with KRR -- where the estimated regression function is penalized by the square of its native space norm. This method is of interest because it can be viewed as classical linear regression, with features specified by $\mathcal{F}$, followed by the application of standard KRR to the residual (unexplained) component of the target variable. Methods of this type have recently attracted increasing attention. We study the statistical properties of this method by reducing its behavior to that of KRR with another fixed kernel, called the residual kernel. Our main theoretical result shows that such a reduction is indeed possible, at the cost of an additional term in the expected test risk, bounded by $\mathcal{O}(1/\sqrt{N})$, where $N$ is the sample size and the hidden constant depends on the class $\mathcal{F}$ and the input distribution. This reduction enables us to analyze conditional KRR in the case where $K$ is positive definite and $\mathcal{F}$ is given by the first $k$ principal eigenfunctions in the Mercer decomposition of $K$. We also consider the setting where $\mathcal{F}$ consists of $k$ random features from a random feature representation of $K$. It turns out that these two settings are closely related. Both our theoretical analysis and experiments confirm that conditional KRR outperforms standard KRR in these cases whenever the $\mathcal{F}$-component of the regression function is more pronounced than the residual part.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines conditional KRR for conditionally positive definite kernels with respect to a function class F, reduces its expected test risk to that of standard KRR on a residual kernel plus an additive O(1/sqrt(N)) term (with constant depending on F and P_X), and applies the reduction to the cases where F consists of the leading k Mercer eigenfunctions of K or k random features drawn from a random-feature map of K. It claims that conditional KRR outperforms ordinary KRR in these settings whenever the F-component of the regression function dominates the residual component, with both theory and experiments supporting the claim.
Significance. If the reduction is valid, the result supplies a concrete mechanism for injecting unpenalized linear features into kernel ridge regression while retaining a kernel-method analysis, which is directly relevant to kernel thresholding and related hybrid methods. The O(1/sqrt(N)) additive term is standard in rate, but the explicit reduction to a residual kernel is the load-bearing technical step; when combined with the Mercer or random-feature choices of F it yields a falsifiable prediction about when the hybrid method improves upon plain KRR.
major comments (2)
- [Abstract / main theoretical result] Abstract / main theoretical result: the stated risk reduction equates conditional-KRR risk to residual-kernel KRR risk plus an additive term bounded by C(F,P_X)/sqrt(N). This identity holds for any target decomposition; the paper invokes the extra premise that the F-component dominates to conclude outperformance, yet supplies no quantitative threshold on the size of the F-component relative to the residual under which the residual-kernel advantage exceeds the O(1/sqrt(N)) penalty. Without such a condition the bound is consistent with conditional KRR being no better (or worse) than standard KRR.
- [Abstract] Abstract: the O(1/sqrt(N)) bound and the outperformance claim are asserted without any derivation steps, explicit list of assumptions on the kernel or on F, or the precise definition of the residual kernel. Because the central claim is precisely this reduction, the absence of these elements prevents verification that the bound is non-vacuous or that the hidden constant is independent of the target function.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / main theoretical result] Abstract / main theoretical result: the stated risk reduction equates conditional-KRR risk to residual-kernel KRR risk plus an additive term bounded by C(F,P_X)/sqrt(N). This identity holds for any target decomposition; the paper invokes the extra premise that the F-component dominates to conclude outperformance, yet supplies no quantitative threshold on the size of the F-component relative to the residual under which the residual-kernel advantage exceeds the O(1/sqrt(N)) penalty. Without such a condition the bound is consistent with conditional KRR being no better (or worse) than standard KRR.
Authors: The referee is correct that the risk identity is general and does not by itself guarantee outperformance. The manuscript states the outperformance claim qualitatively, conditioned on the F-component being 'more pronounced than the residual part,' which is justified by the fact that the residual kernel can yield strictly smaller excess risk when the target has a substantial component in F. To make the claim sharper, we will revise the relevant sections to state an explicit (if still qualitative) condition: conditional KRR outperforms standard KRR whenever the reduction in residual-kernel excess risk exceeds the additive O(1/sqrt(N)) term whose constant depends only on F and P_X. This revision will be made. revision: yes
-
Referee: [Abstract] Abstract: the O(1/sqrt(N)) bound and the outperformance claim are asserted without any derivation steps, explicit list of assumptions on the kernel or on F, or the precise definition of the residual kernel. Because the central claim is precisely this reduction, the absence of these elements prevents verification that the bound is non-vacuous or that the hidden constant is independent of the target function.
Authors: The abstract is deliberately concise and therefore omits the full technical details. The residual kernel is defined in Definition 3.2, the standing assumptions on the CPD kernel K and the class F appear in Section 2, and the main reduction (including the explicit dependence of the constant solely on F and P_X, independent of the target function) is stated as Theorem 3.3 with its proof in the appendix. These elements allow verification of the claim. If the referee prefers, we can add one sentence to the abstract that points to the relevant definition and theorem. revision: partial
Circularity Check
No circularity: bound derived independently of target decomposition
full rationale
The central result reduces conditional KRR risk to residual-kernel KRR risk plus an additive O(1/sqrt(N)) term whose constant depends only on F and P_X. This bound is stated to hold for any decomposition of the regression function; outperformance is invoked only under the separate, explicitly stated premise that the F-component dominates the residual. No equation equates the bound to a fitted quantity, renames an input, or reduces via self-citation to a prior result by the same authors. The derivation is therefore self-contained and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https: //doi.org/10.1007/s10208-006-0196-8
doi: 10.1007/s10208-006-0196-8. URL https: //doi.org/10.1007/s10208-006-0196-8. Chi, T.-C., Fan, T.-H., Ramadge, P. J., and Rudnicky, A. I. Kerple: kernelized relative positional embedding for length extrapolation. InProceedings of the 36th Inter- national Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Asso...
-
[2]
URL https://openreview.net/forum? id=Da_EHrAcfwd. Duchon, J. Splines minimizing rotation-invariant semi- norms in sobolev spaces. In Schempp, W. and Zeller, K. (eds.),Constructive Theory of Functions of Several Variables, pp. 85–100, Berlin, Heidelberg, 1977. Springer Berlin Heidelberg. ISBN 978-3-540-37496-1. Freund, Y . and Schapire, R. E. A decision- t...
-
[3]
Jacot, A., Gabriel, F., and Hongler, C
URL https://www.sciencedirect.com/ science/article/pii/S002200009791504X. Jacot, A., Gabriel, F., and Hongler, C. Neural tangent ker- nel: Convergence and generalization in neural networks. InProceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, pp. 8580–8589, Red Hook, NY , USA, 2018. Curran Asso- ciates Inc....
2018
-
[4]
cc/paper_files/paper/2022/file/ 08342dc6ab69f23167b4123086ad4d38-Paper-Conference
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ 08342dc6ab69f23167b4123086ad4d38-Paper-Conference. pdf. Marteau-Ferey, U., Ostrovskii, D., Bach, F., and Rudi, A. Beyond least-squares: Fast rates for regularized empirical risk minimization through self-concordance. In Beygelzimer, A. and Hsu, D. (eds.),Proceedings of the Thirty-Second Conf...
work page doi:10.1002/cpa 2022
-
[5]
Novelli, P., Prattic`o, M., Pontil, M., and Ciliberto, C
URL https://openreview.net/forum? id=7R7fAoUygoa. Novelli, P., Prattic`o, M., Pontil, M., and Ciliberto, C. Op- erator world models for reinforcement learning. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2025. Curran Associates Inc. ISBN 9798331314385. Poggio, T. and Girosi, F...
2025
-
[6]
doi: 10.1109/5.58326. Rahimi, A. and Recht, B. Random features for large-scale kernel machines. In Platt, J., Koller, D., Singer, Y ., and Roweis, S. (eds.),Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc.,
-
[7]
cc/paper_files/paper/2007/file/ 013a006f03dbc5392effeb8f18fda755-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2007/file/ 013a006f03dbc5392effeb8f18fda755-Paper. pdf. Schaback, R. and Wendland, H. Kernel techniques: From machine learning to meshless methods.Acta Numerica, 15:543–639, 2006. doi: 10.1017/S0962492906270016. Sch¨olkopf, B. The kernel trick for distances. In Leen, T., Dietterich, T., and Tresp, V . ...
-
[8]
cc/paper_files/paper/2000/file/ 4e87337f366f72daa424dae11df0538c-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2000/file/ 4e87337f366f72daa424dae11df0538c-Paper. pdf. Simon, J. B., Dickens, M., Karkada, D., and DeWeese, M. R. The eigenlearning framework: A conservation law perspective on kernel ridge regression and wide neural networks.Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https:/...
-
[9]
URL https://proceedings.mlr.press/ v244/takhanov24a.html. 10 Conditional KRR: Injecting Unpenalized Features into Kernel Methods with Applications to Kernel Thresholding Takhanov, R. On the intrinsic dimensions of data in kernel learning. InThe 29th International Conference on Ar- tificial Intelligence and Statistics, 2026. URL https: //openreview.net/for...
-
[10]
URL https://epubs.siam.org/doi/abs/10
doi: 10.1137/1.9781611970128. URL https://epubs.siam.org/doi/abs/10. 1137/1.9781611970128. Wendland, H.Scattered Data Approximation. Cambridge Monographs on Applied and Computational Mathematics. Cambridge University Press, 2004. Yang, Z., Lukasik, M., Nagarajan, V ., Li, Z., Rawat, A., Zaheer, M., Menon, A. K., and Kumar, S. Resmem: Learn what you can an...
-
[11]
cc/paper_files/paper/2023/file/ bf0857cb9a41c73639f028a80301cdf0-Paper-Conference
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ bf0857cb9a41c73639f028a80301cdf0-Paper-Conference. pdf. 11 Conditional KRR: Injecting Unpenalized Features into Kernel Methods with Applications to Kernel Thresholding A. Proof of Theorem 2.1 LetM(X)be the set of finite signed Borel measures onX. The following characterization of CPD require...
2023
-
[12]
log(4k δ ) is equivalent to 2kexp − N 28 3 kmax j:1≤j≤k ∥fj ∥2 L∞ (X) + 4 3 ! ≤ δ
-
[13]
So, using q 8 log( 2k δ ) N ≥ 1 N , we have α≤C KP 1 + max j:1≤j≤k ∥fj∥L∞(X) vuut12k s 8 log(2k δ ) N ≤ CKP 1 + max j:1≤j≤k ∥fj∥L∞(X) 6k1/2 log1/4( 2k δ ) N 1/4 ! ≤7C KP
In Lemma D.15 we haveα=C KP 1 + max j:1≤j≤k ∥fj∥L∞(X) q 6k 1 N +t . So, using q 8 log( 2k δ ) N ≥ 1 N , we have α≤C KP 1 + max j:1≤j≤k ∥fj∥L∞(X) vuut12k s 8 log(2k δ ) N ≤ CKP 1 + max j:1≤j≤k ∥fj∥L∞(X) 6k1/2 log1/4( 2k δ ) N 1/4 ! ≤7C KP . provided thatN≥k 2 log( 2k δ ) max j:1≤j≤k ∥fj∥4 L∞(X) . From Lemma D.15 we obtain that with probability at ...
2023
-
[14]
Theorem G.1.Letrank([f i(xj)]k i=1 N j=1) =kandu∈R k, w∈R m be the solution of the task(5)
(5) The meaning of this task is to give a budget on weights of features f ′ i while having a complete freedom in selection of weights for the featuresf i, i= 1,· · ·, k. Theorem G.1.Letrank([f i(xj)]k i=1 N j=1) =kandu∈R k, w∈R m be the solution of the task(5). Then, asm→+∞, u⊤ϕ(x) +w ⊤ψ(x)→f(x)with probability 1, wherefis the solution of the task(1). Pro...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.