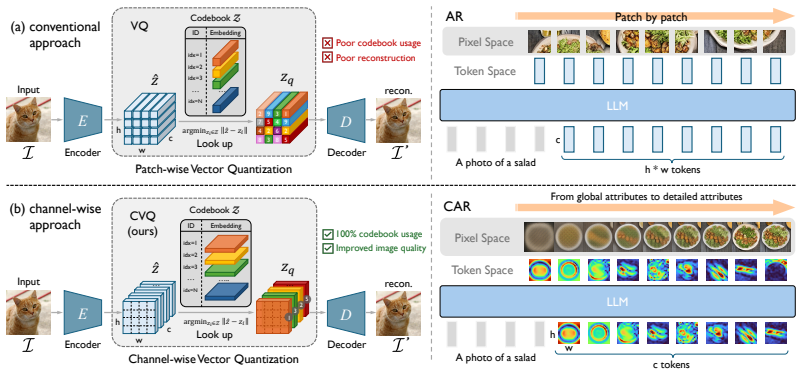
Channel-wise Vector Quantization
Pith reviewed 2026-06-29 22:37 UTC · model grok-4.3
The pith
Channel-wise vector quantization represents images as discrete levels of visual details by quantizing each feature map channel rather than spatial patches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CVQ quantizes each channel of the feature map, representing an image as discrete levels of visual details rather than as a grid of spatial patches. Based on CVQ, the Channel-wise Autoregressive model predicts image channels sequentially, first sketching global structure and then refining fine-grained attributes.
What carries the argument
Channel-wise Vector Quantization, which assigns a discrete token to every channel across the feature map to encode progressive visual detail levels.
If this is right
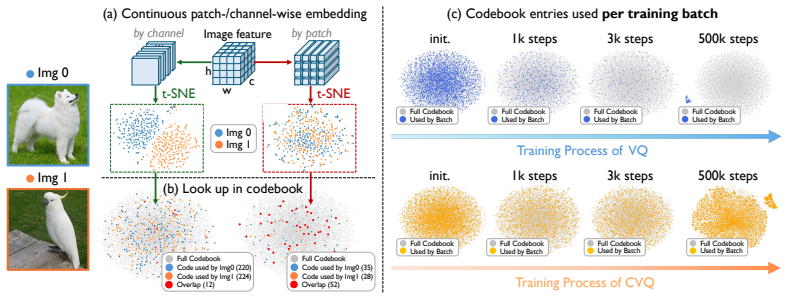
- CVQ reaches 100% codebook utilization with codebooks larger than 16K without extra regularization.
- CVQ produces higher reconstruction quality than conventional vector quantization.
- The Channel-wise Autoregressive model reaches a DPG score of 86.7 and a GenEval score of 0.79 on text-to-image benchmarks.
Where Pith is reading between the lines
- If detail levels prove more natural than spatial order for autoregression, future models could reorder token prediction by information complexity rather than raster scan.
- The channel-wise formulation might apply to other dense feature maps where channels already separate coarse and fine information.
- Avoiding codebook collapse at 16K entries without auxiliary losses indicates the ordering itself stabilizes large discrete spaces.
Load-bearing premise
That quantizing each channel of the feature map produces a representation of the image as discrete levels of visual details that supports effective next-channel autoregressive prediction.
What would settle it
A side-by-side test on a standard dataset showing that channel-wise quantization yields no gain in reconstruction quality or codebook utilization compared with conventional patch-wise vector quantization.
Figures




read the original abstract
We present Channel-wise Vector Quantization (CVQ), a novel image tokenization paradigm that replaces patch-wise tokens with channel-wise tokens. Unlike conventional vector quantization, which assigns a discrete token to each patch feature vector, CVQ quantizes each channel of the feature map. This formulation represents an image as discrete levels of visual details, rather than as a grid of spatial patches. Based on CVQ, we introduce a new visual autoregressive framework with "next-channel prediction". Instead of rendering images patch by patch in raster order, our Channel-wise Autoregressive (CAR) model predicts image channels sequentially, producing progressively enriched visual details. Specifically, it first sketches global structure and then refines fine-grained attributes, akin to a human artist's workflow. Empirically, we show that: (1) CVQ achieves 100% codebook utilization with a 16K+ codebook size without any bells and whistles, and substantially improves reconstruction quality over conventional VQ; and (2) CAR attains a DPG score of 86.7 and a GenEval score of 0.79, demonstrating strong effectiveness for text-to-image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Channel-wise Vector Quantization (CVQ), a tokenization method that quantizes each channel of the feature map rather than patch-wise feature vectors, thereby representing an image as discrete levels of visual details. It further proposes a Channel-wise Autoregressive (CAR) model based on next-channel prediction instead of raster-order patch prediction. The central empirical claims are 100% codebook utilization for codebooks of size 16K+ without auxiliary techniques, improved reconstruction over standard VQ, and strong text-to-image results (DPG 86.7, GenEval 0.79).
Significance. If the reported utilization and generation metrics hold under scrutiny, the channel-wise formulation offers a direct, low-overhead solution to the well-known codebook-collapse problem in vector-quantized image models and introduces a new autoregressive ordering that builds global structure before fine details. This could influence discrete latent modeling for both reconstruction and conditional generation tasks.
major comments (2)
- [Abstract] Abstract: the assertion of '100% codebook utilization with a 16K+ codebook size without any bells and whistles' is load-bearing for the novelty claim yet provides no definition or measurement protocol (e.g., fraction of codes appearing at least once across the full training or test set, or per-image entropy); without this in the experiments section the result cannot be reproduced or compared.
- [Abstract] Abstract: the interpretation that channel-wise tokens correspond to 'discrete levels of visual details' and that next-channel prediction therefore mimics an artist's workflow is presented as motivation but lacks any supporting ablation, visualization, or quantitative test (e.g., progressive reconstruction quality after k channels); this assumption directly motivates the CAR architecture and therefore requires explicit validation.
minor comments (2)
- The abstract states that CVQ 'substantially improves reconstruction quality' but supplies no PSNR, SSIM, or FID numbers, nor the baseline VQ model and codebook size used for comparison; these metrics should appear in the results section.
- Notation for the channel-wise token sequence and the autoregressive factorization p(x_1 … x_C | text) is not introduced in the abstract; a short methods paragraph or equation would clarify the shift from spatial to channel ordering.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of '100% codebook utilization with a 16K+ codebook size without any bells and whistles' is load-bearing for the novelty claim yet provides no definition or measurement protocol (e.g., fraction of codes appearing at least once across the full training or test set, or per-image entropy); without this in the experiments section the result cannot be reproduced or compared.
Authors: We agree that an explicit definition and measurement protocol are required for reproducibility. In the revised manuscript we have added a precise definition in Section 4 (Experiments): codebook utilization is the fraction of codes that appear at least once across all tokens generated on the full test set. The abstract has been updated to reference this protocol. revision: yes
-
Referee: [Abstract] Abstract: the interpretation that channel-wise tokens correspond to 'discrete levels of visual details' and that next-channel prediction therefore mimics an artist's workflow is presented as motivation but lacks any supporting ablation, visualization, or quantitative test (e.g., progressive reconstruction quality after k channels); this assumption directly motivates the CAR architecture and therefore requires explicit validation.
Authors: The channel-wise formulation naturally decomposes the feature map into independent detail levels, which directly motivates the next-channel ordering. While overall reconstruction and generation metrics provide supporting evidence, we acknowledge the absence of explicit progressive visualizations. In the revision we will add qualitative figures showing reconstruction quality after successive channels to strengthen this motivation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces CVQ as a modeling choice (quantizing channels of the feature map rather than spatial patches) and reports direct empirical outcomes: 100% codebook utilization for large codebooks and downstream generation scores (DPG 86.7, GenEval 0.79). No equations, fitted parameters, or self-citations are shown that would make these results equivalent to their inputs by construction. The next-channel autoregressive framework is likewise presented as an architectural decision whose validity rests on measured performance rather than any self-referential derivation or uniqueness theorem imported from prior author work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard vector quantization and autoregressive modeling assumptions hold for the channel-wise reformulation.
invented entities (1)
-
Channel-wise tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Flextok: Resampling images into 1d token sequences of flexible length
Roman Bachmann, Jesse Allardice, David Mizrahi, Enrico Fini, O ˘guzhan Fatih Kar, Elmira Amirloo, Alaaeldin El-Nouby, Amir Zamir, and Afshin Dehghan. Flextok: Resampling images into 1d token sequences of flexible length. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=DgdOkUUBzf. 3, 9, 16
2025
-
[3]
Language models are few-shot learners.Advances in neural information processing systems, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 2020. 3
2020
-
[4]
Maskgit: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11315–11325, 2022. 2
2022
-
[5]
Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InCVPR, 2021. 18
2021
-
[6]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025. 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426, 2023. 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Catok: Taming mean flows for one-dimensional causal image tokenization
Yitong Chen, Zuxuan Wu, Xipeng Qiu, and Yu-Gang Jiang. Catok: Taming mean flows for one-dimensional causal image tokenization. InCVPR, 2026. 3
2026
-
[9]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009. 6
2009
-
[10]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12873–12883, 2021. 2, 3, 5, 6
2021
-
[11]
Scaling rectified flow transform- ers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis. InForty-first International Conference on Machine Learning, 2024. 7 10
2024
-
[12]
Restructuring vector quantization with the rotation trick
Christopher Fifty, Ronald G Junkins, Dennis Duan, Aniketh Iyengar, Jerry W Liu, Ehsan Amid, Sebastian Thrun, and Christopher Ré. Restructuring vector quantization with the rotation trick. The Thirteenth International Conference on Learning Representations, 2025. 2, 6
2025
-
[13]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 15733–15744,
-
[14]
Flowtok: Flowing seamlessly across text and image tokens
Ju He, Qihang Yu, Qihao Liu, and Liang-Chieh Chen. Flowtok: Flowing seamlessly across text and image tokens. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 16629–16640, 2025. 9
2025
-
[15]
Statistics of patch offsets for image completion
Kaiming He and Jian Sun. Statistics of patch offsets for image completion. InEuropean conference on computer vision, pp. 16–29. Springer, 2012. 2, 4
2012
-
[16]
Towards accurate image coding: Improved autoregressive image generation with dynamic vector quantization
Mengqi Huang, Zhendong Mao, Zhuowei Chen, and Yongdong Zhang. Towards accurate image coding: Improved autoregressive image generation with dynamic vector quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 22596–22605, June 2023. 6
2023
-
[17]
Spec- tralar: Spectral autoregressive visual generation
Yuanhui Huang, Weiliang Chen, Wenzhao Zheng, Yueqi Duan, Jie Zhou, and Jiwen Lu. Spec- tralar: Spectral autoregressive visual generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 2, 3, 9
2025
-
[18]
Zhihao Huang, Xi Qiu, Yukuo Ma, Yifu Zhou, Junjie Chen, Hongyuan Zhang, Chi Zhang, and Xuelong Li. Nfig: multi-scale autoregressive image generation via frequency ordering.arXiv preprint arXiv:2503.07076, 2025. 2
-
[19]
Image-to-image translation with conditional adversarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 1125–1134, 2017. 5
2017
-
[20]
Dongwon Kim, Ju He, Qihang Yu, Chenglin Yang, Xiaohui Shen, Suha Kwak, and Liang- Chieh Chen. Democratizing text-to-image masked generative models with compact text-aware one-dimensional tokens.arXiv preprint arXiv:2501.07730, 2025. 7, 9
-
[21]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 7
2024
-
[22]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11523–11532, 2022. 3, 6
2022
-
[23]
Infinitystar: Unified spacetime autoregressive modeling for visual generation
Jinlai Liu, Jian Han, Bin Yan, Hui Wu, Fengda Zhu, Xing Wang, Yi Jiang, Bingyue Peng, and Zehuan Yuan. Infinitystar: Unified spacetime autoregressive modeling for visual generation. arXiv preprint arXiv:2511.04675, 2025. 7
-
[24]
Chuofan Ma, Yi Jiang, Junfeng Wu, Jihan Yang, Xin Yu, Zehuan Yuan, Bingyue Peng, and Xiaojuan Qi. Unitok: A unified tokenizer for visual generation and understanding.arXiv preprint arXiv:2502.20321, 2025. 2, 3, 7, 9
-
[25]
Xiaoxiao Ma, Mohan Zhou, Tao Liang, Yalong Bai, Tiejun Zhao, Huaian Chen, and Yi Jin. Star: Scale-wise text-to-image generation via auto-regressive representations.arXiv preprint arXiv:2406.10797, 2024. 7, 9
-
[26]
Finite scalar quantization: VQ-V AE made simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: VQ-V AE made simple. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=8ishA3LxN8. 3
2024
-
[27]
Randar: Decoder-only autoregressive visual generation in random orders
Ziqi Pang, Tianyuan Zhang, Fujun Luan, Yunze Man, Hao Tan, Kai Zhang, William T Freeman, and Yu-Xiong Wang. Randar: Decoder-only autoregressive visual generation in random orders. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 45–55, 2025. 2 11
2025
-
[28]
Sdxl: Improving latent diffusion models for high-resolution image synthesis.The Twelfth International Conference on Learning Representations, 2024
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.The Twelfth International Conference on Learning Representations, 2024. 7, 9
2024
-
[29]
Tokenflow: Unified image tokenizer for multimodal understanding and generation
Liao Qu, Huichao Zhang, Yiheng Liu, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Daniel K Du, Zehuan Yuan, and Xinglong Wu. Tokenflow: Unified image tokenizer for multimodal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025. 7
2025
-
[30]
Learning ordered representations with nested dropout
Oren Rippel, Michael Gelbart, and Ryan Adams. Learning ordered representations with nested dropout. InInternational Conference on Machine Learning, pp. 1746–1754. PMLR, 2014. 2, 3, 6, 8, 16
2014
-
[31]
Scalable image tokenization with index backpropagation quantization
Fengyuan Shi, Zhuoyan Luo, Yixiao Ge, Yujiu Yang, Ying Shan, and Limin Wang. Scalable image tokenization with index backpropagation quantization. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 2, 3, 4, 10
2025
-
[32]
DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
Wei Song, Yuran Wang, Zijia Song, Yadong Li, Zenan Zhou, Long Chen, Jianhua Xu, Jiaqi Wang, and Kaicheng Yu. Dualtoken: Towards unifying visual understanding and generation with dual visual vocabularies.arXiv preprint arXiv:2503.14324, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024. 2, 3, 7, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Hart: Efficient visual generation with hybrid autore- gressive transformer.The Thirteenth International Conference on Learning Representations,
Haotian Tang, Yecheng Wu, Shang Yang, Enze Xie, Junsong Chen, Junyu Chen, Zhuoyang Zhang, Han Cai, Yao Lu, and Song Han. Hart: Efficient visual generation with hybrid autore- gressive transformer.The Thirteenth International Conference on Learning Representations,
-
[35]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. 2, 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
NextStep Team, Chunrui Han, Guopeng Li, Jingwei Wu, Quan Sun, Yan Cai, Yuang Peng, Zheng Ge, Deyu Zhou, Haomiao Tang, Hongyu Zhou, Kenkun Liu, Ailin Huang, Bin Wang, Changxin Miao, Deshan Sun, En Yu, Fukun Yin, Gang Yu, Hao Nie, Haoran Lv, Hanpeng Hu, Jia Wang, Jian Zhou, Jianjian Sun, Kaijun Tan, Kang An, Kangheng Lin, Liang Zhao, Mei Chen, Peng Xing, Ru...
-
[37]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 2024. 2, 3
2024
-
[38]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. InAdvances in Neural Information Processing Systems, 2017. 2, 3, 5
2017
-
[40]
Switti: Designing scale-wise transformers for text-to-image synthesis
Anton V oronov, Denis Kuznedelev, Mikhail Khoroshikh, Valentin Khrulkov, and Dmitry Baranchuk. Switti: Designing scale-wise transformers for text-to-image synthesis. InProceed- ings of the Computer Vision and Pattern Recognition Conference, 2025. 7, 9
2025
-
[41]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024. 1, 3, 7 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Principal components
Xin Wen, Bingchen Zhao, Ismail Elezi, Jiankang Deng, and Xiaojuan Qi. “Principal components” enable a new language of images. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025. 3, 9, 16
2025
-
[43]
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation.arXiv preprint arXiv:2410.13848, 2024. 7, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Liquid: Language models are scalable and unified multi-modal generators
Junfeng Wu, Yi Jiang, Chuofan Ma, Yuliang Liu, Hengshuang Zhao, Zehuan Yuan, Song Bai, and Xiang Bai. Liquid: Language models are scalable and unified multi-modal generators. International Journal of Computer Vision, 2026. 7
2026
-
[45]
Vila-u: a unified foundation model integrating visual understanding and generation.The Thirteenth International Conference on Learning Representations, 2025
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, et al. Vila-u: a unified foundation model integrating visual understanding and generation.The Thirteenth International Conference on Learning Representations, 2025. 9
2025
-
[46]
Sana: Efficient high-resolution image synthesis with linear diffusion transformers.The Thirteenth International Conference on Learning Representations, 2025
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, et al. Sana: Efficient high-resolution image synthesis with linear diffusion transformers.The Thirteenth International Conference on Learning Representations, 2025. 7
2025
-
[47]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single trans- former to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528,
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Muse-vl: Modeling unified vlm through semantic discrete encoding
Rongchang Xie, Chen Du, Ping Song, and Chang Liu. Muse-vl: Modeling unified vlm through semantic discrete encoding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 24135–24146, 2025. 7
2025
-
[49]
Yilun Xu, Yang Song, Sahaj Garg, Linyuan Gong, Rui Shu, Aditya Grover, and Stefano Ermon. Anytime sampling for autoregressive models via ordered autoencoding.arXiv preprint arXiv:2102.11495, 2021. 3
-
[50]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 2, 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Vector-quantized image modeling with improved vqgan
Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved vqgan. InThe Tenth International Conference on Learning Representations, 2022. 2, 3, 6
2022
-
[52]
Language model beats diffusion - tokenizer is key to visual generation
Lijun Yu, Jose Lezama, Nitesh Bharadwaj Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A Ross, and Lu Jiang. Language model beats diffusion - tokenizer is key to visual generation. InThe Twelfth International Conference on Learning Representati...
2024
-
[53]
An image is worth 32 tokens for reconstruction and generation.Advances in Neural Information Processing Systems, 2024
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, and Liang-Chieh Chen. An image is worth 32 tokens for reconstruction and generation.Advances in Neural Information Processing Systems, 2024. 3, 7, 9
2024
-
[54]
Randomized au- toregressive visual generation
Qihang Yu, Ju He, Xueqing Deng, Xiaohui Shen, and Liang-Chieh Chen. Randomized au- toregressive visual generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 18431–18441, 2025. 2
2025
-
[55]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 586–595, 2018. 5 13
2018
-
[56]
Holistic tokenizer for autoregressive image generation
Anlin Zheng, Haochen Wang, Yucheng Zhao, Weipeng Deng, Tiancai Wang, Xiangyu Zhang, and Xiaojuan Qi. Holistic tokenizer for autoregressive image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 16916–16926, October
-
[57]
Movq: Modulating quantized vectors for high-fidelity image generation.Advances in Neural Information Processing Systems, 35:23412–23425, 2022
Chuanxia Zheng, Tung-Long Vuong, Jianfei Cai, and Dinh Phung. Movq: Modulating quantized vectors for high-fidelity image generation.Advances in Neural Information Processing Systems, 35:23412–23425, 2022. 3, 6
2022
-
[58]
Scaling the codebook size of vq-gan to 100,000 with a utilization rate of 99%
Lei Zhu, Fangyun Wei, Yanye Lu, and Dong Chen. Scaling the codebook size of vq-gan to 100,000 with a utilization rate of 99%. InAdvances in Neural Information Processing Systems,
-
[59]
Addressing representation collapse in vector quantized models with one linear layer
Yongxin Zhu, Bocheng Li, Yifei Xin, Zhihua Xia, and Linli Xu. Addressing representation collapse in vector quantized models with one linear layer. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 2, 3, 4, 6, 10
2025
-
[60]
Xianwei Zhuang, Yuxin Xie, Yufan Deng, Dongchao Yang, Liming Liang, Jinghan Ru, Yuguo Yin, and Yuexian Zou. Vargpt-v1.1: Improve visual autoregressive large unified model via iterative instruction tuning and reinforcement learning.arXiv preprint arXiv:2504.02949, 2025. 7
-
[61]
Lumina-next: Making lumina-t2x stronger and faster with next-dit.Advances in Neural Information Processing Systems, 2024
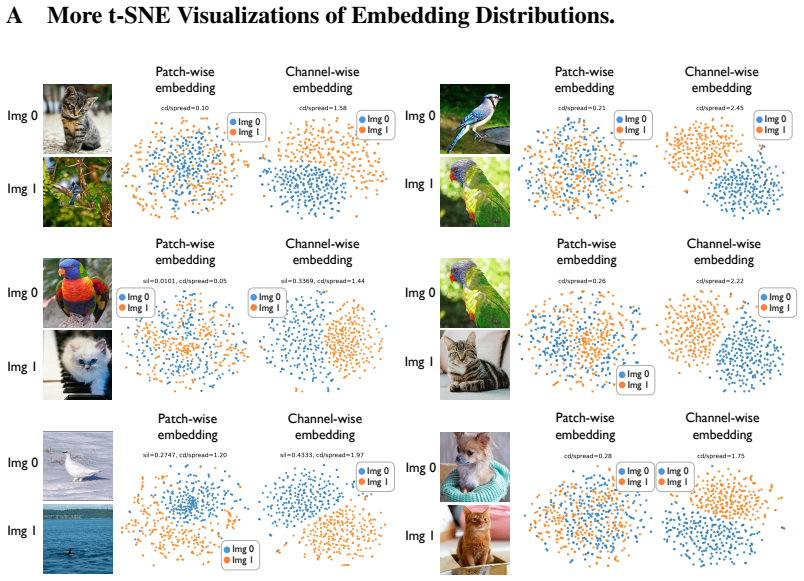
Le Zhuo, Ruoyi Du, Han Xiao, Yangguang Li, Dongyang Liu, Rongjie Huang, Wenze Liu, Xiangyang Zhu, Fu-Yun Wang, Zhanyu Ma, et al. Lumina-next: Making lumina-t2x stronger and faster with next-dit.Advances in Neural Information Processing Systems, 2024. 7 14 A More t-SNE Visualizations of Embedding Distributions. Img 0 Img 1 Img 0 Img 1 Patch-wise embeddingC...
2024
-
[62]
demonstrates that a nested dropout strategy, which stochastically removes nested sets of hidden units, enforces an ordered representation where importance decreases with the dimension index. For semi-linear autoencoders (comprising a linear or sigmoidal encoder with a linear decoder) under L2 loss, they establish that: (i) its optimal solutions are a subs...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.