TSFMAudit: Data Contamination Auditing in Forecasting Time Series Foundation Models
Pith reviewed 2026-06-30 11:57 UTC · model grok-4.3
The pith
TSFMAudit detects pretraining contamination in time series foundation models by spotting unusually fast adaptation during a fine-tuning probe.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretraining contamination in time series foundation models can be audited by observing that contaminated datasets produce faster loss reduction and smaller backbone movement after a fine-tuning probe, providing a practical signal when direct corpus access or documentation is unavailable.
What carries the argument
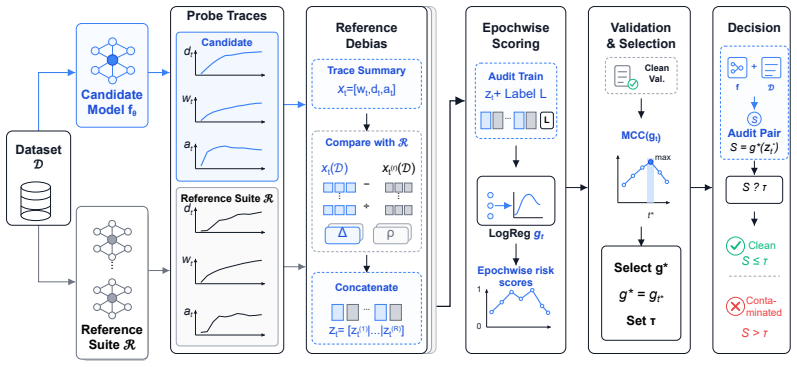
TSFMAudit, a probe-based auditing method that tracks adaptation dynamics (loss reduction rate and backbone parameter displacement) to classify datasets as contaminated or clean.
If this is right
- Evaluation sets flagged as contaminated can be excluded or down-weighted to produce less optimistic performance estimates for TSFMs.
- The method supplies an automated check that works even when training corpora lack complete public documentation.
- It extends contamination auditing techniques from language models to the continuous, heterogeneous setting of time series forecasting.
Where Pith is reading between the lines
- Auditing protocols could be run routinely on new TSFM releases before benchmark results are published.
- The same adaptation-dynamics signal might be tested on other sequential modalities where exact overlap checks are difficult.
- Combining the probe signal with any available sequence-level overlap checks could strengthen detection when partial documentation exists.
Load-bearing premise
That differences in adaptation speed and backbone movement during the probe are driven mainly by pretraining contamination rather than other dataset traits such as noise level, periodicity, or length, and that documented training sources give accurate binary contamination labels.
What would settle it
Finding a dataset with documented pretraining exposure that shows no faster loss drop or larger backbone shift than clean datasets, or a clean dataset that adapts faster than expected, would undermine the method.
Figures

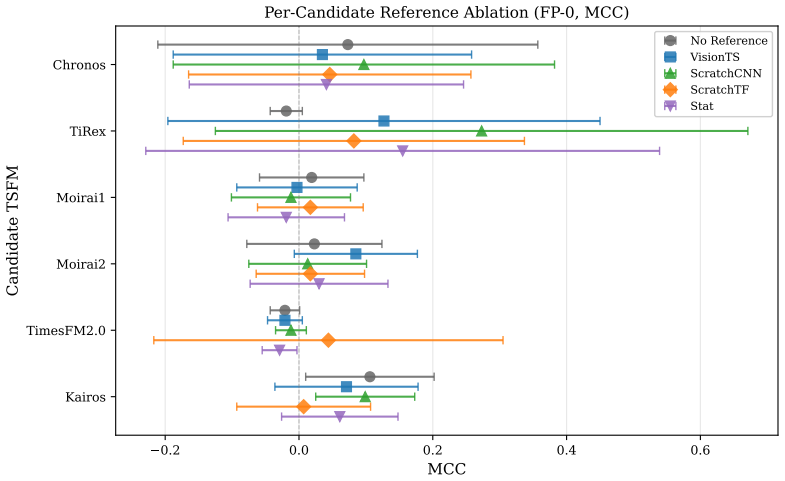
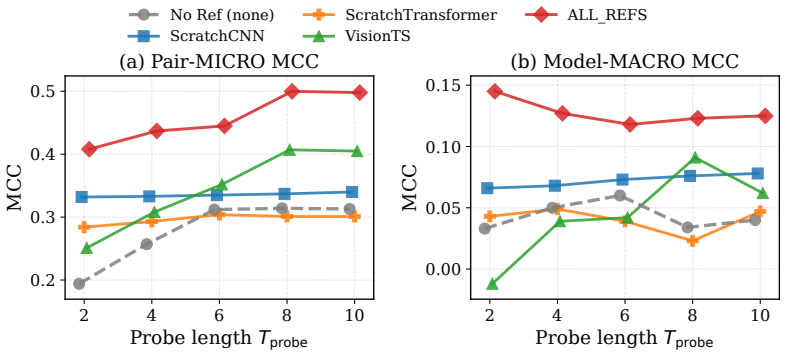
read the original abstract
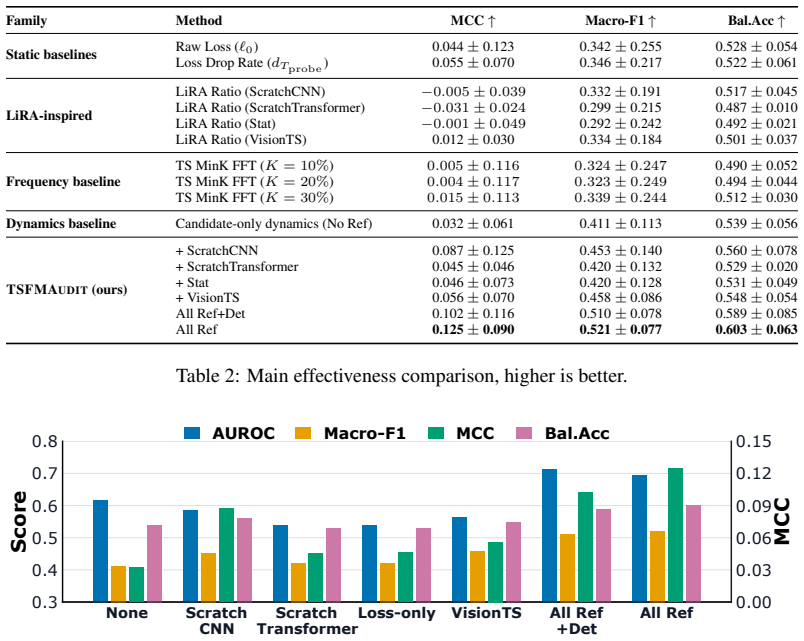
Time series foundation models (TSFMs) are increasingly pretrained on large corpora, raising concerns that evaluation datasets may have been exposed during pretraining and thus yield overly optimistic performance estimates. Auditing such contamination is challenging in time series because signals are continuous and heterogeneous, and often lack corpus documentation. To the best of our knowledge, this is the first work to study pretraining contamination auditing for TSFMs. We formalize the problem of pretraining contamination auditing for TSFMs and propose TSFMAudit, a method based on probe adaptation dynamics. Our key intuition is that contamination manifests as unusually efficient adaptation: after a fine tuning probe, contaminated datasets tend to exhibit faster loss reduction with smaller backbone movement. We evaluate TSFMAudit on 6 TSFMs and 187 datasets using documented training source evidence as supervision, and compare against 10 competitive baselines adapted from the LLM literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TSFMAudit, the first method for auditing pretraining data contamination in time series foundation models (TSFMs). It formalizes the auditing problem and proposes a probe-based approach that detects contamination via unusually efficient adaptation dynamics: faster loss reduction and smaller backbone parameter movement after fine-tuning. The method is evaluated on 6 TSFMs and 187 datasets, using documented training-source membership as binary supervision labels, and is compared against 10 baselines adapted from the LLM contamination literature.
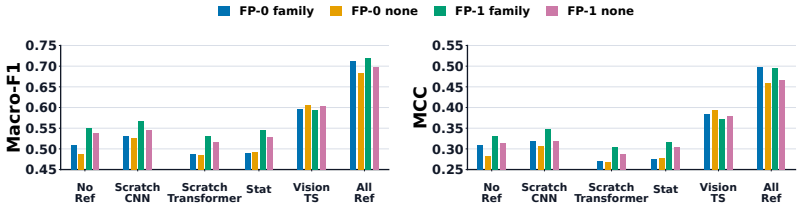
Significance. If the adaptation-dynamics signal proves robust to dataset covariates and the documented labels are reliable, the work would provide a practical auditing tool for TSFM evaluation, addressing a growing concern as these models scale. The scale of the evaluation (6 models, 187 datasets) and the explicit comparison to 10 baselines are strengths; however, the absence of reported quantitative results, error bars, or ablation studies in the provided abstract limits immediate assessment of effect sizes.
major comments (3)
- [Evaluation section] Evaluation section: the central claim that faster loss reduction and smaller backbone movement are caused by pretraining contamination (rather than by intrinsic dataset statistics) is load-bearing, yet the manuscript provides no explicit matching, stratification, or regression controls for covariates such as series length, noise level, periodicity, or stationarity. These factors can independently affect gradient magnitudes and convergence speed, risking spurious correlation with the documented-label supervision.
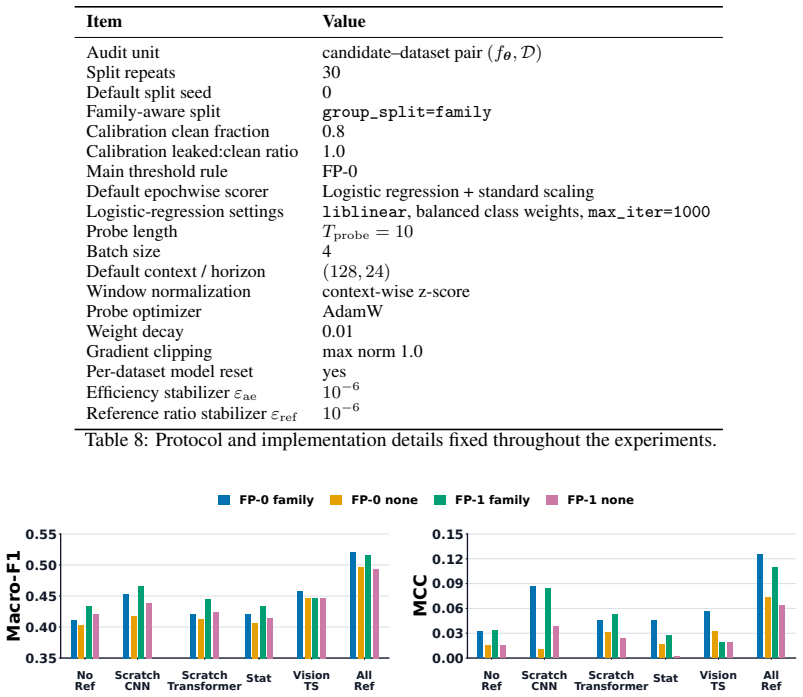
- [Supervision labels section] § on supervision labels: reliance on documented training-source evidence as ground truth is not accompanied by any analysis of label noise (false negatives from undocumented leakage or false positives from similar but non-identical series), which directly undermines validation of the probe metric.
- [Results section] Results section: no mention of statistical tests, confidence intervals, or ablation studies on the adaptation metrics (loss reduction rate, backbone movement) is visible, making it impossible to judge whether observed separation exceeds what would be expected from dataset-property variation alone.
minor comments (2)
- [Abstract] The abstract states the intuition and evaluation plan but supplies no quantitative results, error bars, or ablation summaries; adding a one-sentence summary of key effect sizes would improve readability.
- [Method section] Notation for the adaptation probe (loss reduction, backbone movement) should be defined with explicit equations early in the method section to avoid ambiguity when comparing to baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: the central claim that faster loss reduction and smaller backbone movement are caused by pretraining contamination (rather than by intrinsic dataset statistics) is load-bearing, yet the manuscript provides no explicit matching, stratification, or regression controls for covariates such as series length, noise level, periodicity, or stationarity. These factors can independently affect gradient magnitudes and convergence speed, risking spurious correlation with the documented-label supervision.
Authors: We acknowledge that the manuscript does not include explicit matching, stratification, or regression controls for the listed covariates. This is a valid concern. In the revised manuscript we will add a regression analysis controlling for series length, noise level, periodicity, and stationarity to isolate the contamination signal from intrinsic dataset properties. revision: yes
-
Referee: [Supervision labels section] § on supervision labels: reliance on documented training-source evidence as ground truth is not accompanied by any analysis of label noise (false negatives from undocumented leakage or false positives from similar but non-identical series), which directly undermines validation of the probe metric.
Authors: We agree that label noise merits discussion. The current work relies on documented training-source evidence as stated. In revision we will add an explicit analysis of potential label noise, including sensitivity checks for false positives from similar series; full quantification of undocumented leakage remains limited by lack of pretraining corpus access. revision: partial
-
Referee: [Results section] Results section: no mention of statistical tests, confidence intervals, or ablation studies on the adaptation metrics (loss reduction rate, backbone movement) is visible, making it impossible to judge whether observed separation exceeds what would be expected from dataset-property variation alone.
Authors: The manuscript reports results across 187 datasets and 10 baselines but does not include the requested statistical tests, confidence intervals, or ablations. We will add these elements, including tests on the adaptation metrics, in the revised results section. revision: yes
Circularity Check
No circularity detected; evaluation uses external documented labels
full rationale
The paper's core method measures adaptation dynamics (loss reduction and backbone movement after fine-tuning probe) on datasets and validates them against independent documented training-source membership labels. This supervision signal is external to the probe metrics and not derived from the same fitted parameters or self-citations. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citation chains appear in the derivation. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contamination manifests as unusually efficient adaptation (faster loss reduction with smaller backbone movement) after a fine-tuning probe
Reference graph
Works this paper leans on
-
[1]
Gift-eval: General time series forecasting model evaluation.arXiv preprint arXiv:2410.10393, 2024
Taha Aksu, Gerald Woo, Juncheng Liu, Xu Liu, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. Gift-eval: A benchmark for general time series forecasting model evaluation.arXiv preprint arXiv:2410.10393,
-
[2]
URL https://arxiv.org/abs/2505.23719. Leo Breiman. Random forests.Machine Learning, 45(1):5–32,
-
[3]
URLhttps://link.springer.com/article/10.1023/A:1010933404324
doi: 10.1023/A:1010933404324. URLhttps://link.springer.com/article/10.1023/A:1010933404324. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems (NeurIPS), 33:1...
-
[4]
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer
URLhttps://www.usenix.org/conference/ usenixsecurity21/presentation/carlini-extracting. Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. In2022 IEEE Symposium on Security and Privacy (SP), pages 1897–1914,
1914
-
[5]
doi: 10.1109/SP46214.2022.9833649. Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramèr, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations,
-
[6]
Yihong Dong, Xue Jiang, Huanyu Liu, Zhi Jin, Bin Gu, Mengfei Yang, and Ge Li
URLhttps://openreview.net/forum?id=ALISPmDPCq. Yihong Dong, Xue Jiang, Huanyu Liu, Zhi Jin, Bin Gu, Mengfei Yang, and Ge Li. Generalization or memorization: Data contamination and trustworthy evaluation for large language models. InFind- ings of the Association for Computational Linguistics: ACL 2024, pages 12039–12050,
2024
-
[7]
URL https://aclanthology.org/2024.findings-acl
doi: 10.18653/v1/2024.findings-acl.716. URL https://aclanthology.org/2024.findings-acl. 716/. Vitaly Feldman and Chiyuan Zhang. What neural networks memorize and why: Discovering the long tail via influence estimation. InAdvances in Neural Information Processing Systems 33 (NeurIPS 2020),
-
[8]
Kun Feng, Shaocheng Lan, Yuchen Fang, Wenchao He, Lintao Ma, Xingyu Lu, and Kan Ren
URL https://proceedings.neurips.cc/paper/2020/hash/ 1e14bfe2714193e7af5abc64ecbd6b46-Abstract.html. Kun Feng, Shaocheng Lan, Yuchen Fang, Wenchao He, Lintao Ma, Xingyu Lu, and Kan Ren. Kairos: Towards adaptive and generalizable time series foundation models,
2020
-
[9]
Kairos: Toward Adaptive and Parameter-Efficient Time Series Foundation Models
URL https: //arxiv.org/abs/2509.25826. Jonathan Frankle, David J. Schwab, and Ari S. Morcos. The early phase of neural network training. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Rakshitha Wathsadini Godahewa, Christoph Bergmeir, Geoffrey I
URL https: //arxiv.org/abs/2310.03589. Rakshitha Wathsadini Godahewa, Christoph Bergmeir, Geoffrey I. Webb, Rob Hyndman, and Pablo Montero-Manso. Monash time series forecasting archive. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2),
-
[11]
URL https: //arxiv.org/abs/2401.06059. Hao Li, Bowen Deng, Chang Xu, ZhiYuan Feng, Viktor Schlegel, Yu-Hao Huang, Yizheng Sun, Jingyuan Sun, Kailai Yang, Yiyao Yu, and Jiang Bian. MIRA: Medical time series foundation model for real-world health data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[12]
Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025
11 Chenghao Liu, Taha Aksu, Juncheng Liu, Xu Liu, Hanshu Yan, Quang Pham, Silvio Savarese, Doyen Sahoo, Caiming Xiong, and Junnan Li. Moirai 2.0: When less is more for time series forecasting. arXiv preprint arXiv:2511.11698,
-
[13]
Membership inference attacks by exploiting loss trajectory
Yiyong Liu, Zhengyu Zhao, Michael Backes, and Yang Zhang. Membership inference attacks by exploiting loss trajectory. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 2085–2098,
2022
-
[14]
URL https://dblp.org/rec/conf/ccs/Liu00022
doi: 10.1145/3548606.3560684. URL https://dblp.org/rec/conf/ccs/Liu00022. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations,
-
[15]
doi: 10.1016/j.ijforecast.2019.04.014. B. W. Matthews. Comparison of the predicted and observed secondary structure of T4 phage lysozyme.Biochimica et Biophysica Acta (BBA) - Protein Structure, 405(2):442–451,
-
[16]
URL https://www.sciencedirect.com/science/ article/abs/pii/0005279575901099
doi: 10.1016/0005-2795(75)90109-9. URL https://www.sciencedirect.com/science/ article/abs/pii/0005279575901099. Marcel Meyer, Sascha Kaltenpoth, Kevin Zalipski, and Oliver Müller. Rethinking evaluation in the era of time series foundation models: (un)known information leakage challenges,
- [17]
-
[18]
URL https://arxiv.org/ abs/2303.08774. Yonatan Oren, Nicole Meister, Niladri Chatterji, Faisal Ladhak, and Tatsunori Hashimoto. Proving test set contamination in black-box language models. InThe Twelfth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URLhttps://openreview.net/forum?id=KS8mIvetg2. Javier Pulido and Filipe Rodrigues. Time series foundation models as strong baselines in transporta- tion forecasting: A large-scale benchmark analysis.arXiv preprint arXiv:2602.24238,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
It's TIME: Towards the Next Generation of Time Series Forecasting Benchmarks
URLhttps://arxiv.org/abs/2602.12147. Xiangfei Qiu, Jilin Hu, Lekui Zhou, Xingjian Wu, Junyang Du, Buang Zhang, Chenjuan Guo, Aoying Zhou, Christian S. Jensen, Zhenli Sheng, and Bin Yang. TFB: Towards comprehensive and fair benchmarking of time series forecasting methods.Proceedings of the VLDB Endowment, 17(9): 2363–2377,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URL https://www.vldb.org/pvldb/ vol17/p2363-hu.pdf
doi: 10.14778/3665844.3665863. URL https://www.vldb.org/pvldb/ vol17/p2363-hu.pdf. Eghbal Rahimikia, Hao Ni, and Weiguan Wang. Re(visiting) time series foundation models in finance. arXiv preprint arXiv:2511.18578,
-
[22]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787,
2023
-
[23]
URL https: //aclanthology.org/2023.findings-emnlp.722/
doi: 10.18653/v1/2023.findings-emnlp.722. URL https: //aclanthology.org/2023.findings-emnlp.722/. Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. InThe Twelfth International Conference on Learning Representations,
-
[24]
URL https://dblp.org/rec/conf/sp/ShokriSSS17
doi: 10.1109/SP.2017.41. URL https://dblp.org/rec/conf/sp/ShokriSSS17. 12 Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith, and Yejin Choi. Dataset cartography: Mapping and diagnosing datasets with training dynamics. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing ...
-
[25]
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo
doi: 10.18653/v1/2020.emnlp-main.746. Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 53140–53164. PMLR,
-
[26]
cc/paper_files/paper/2021/file/bcc0d400288793e8bdcd7c19a8ac0c2b-Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/bcc0d400288793e8bdcd7c19a8ac0c2b-Paper.pdf. Shifeng Xie, Vasilii Feofanov, Jianfeng Zhang, Themis Palpanas, and Ievgen Redko. Cauker: Classification time series foundation models can be pretrained on synthetic data. InThe Fourteenth International Conference on Learning Representations,
2021
-
[27]
Benchmark Data Contamination of Large Language Models: A Survey
URLhttps://arxiv.org/abs/2406.04244. Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E. Gonzalez, and Ion Stoica. Rethinking benchmark and contamination for language models with rephrased samples,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
URL https: //arxiv.org/abs/2311.04850. Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understand- ing deep learning requires rethinking generalization. InInternational Conference on Learning Representations (ICLR),
-
[29]
This proxy label records documented exposure to the audited corpus
A zero label should be interpreted as no documented evidence in official sources, rather than as evidence that overlap is absent. This proxy label records documented exposure to the audited corpus. It should not be interpreted as direct evidence of benchmark test leakage. In particular, official documentation may establish shared provenance across renamed...
2024
-
[30]
Y” denotes documented exposure in official sources, and “N
To reduce space, datasets with identical labels and contiguous naming patterns are merged into grouped entries. In grouped rows, the reported labels apply to all datasets in the indicated range. Here, “Y” denotes documented exposure in official sources, and “N” denotes no documented evidence in official sources. 15 Table 6: Representative results in the n...
2010
-
[31]
Shared defaults.Unless otherwise stated, we use Tprobe = 10 probe epochs, batch size 4, and the context–horizon pair (L, H) = (128,24) following GIFT-Eval
Table 8 summarizes the protocol and implementation choices that are fixed throughout the experiments. Shared defaults.Unless otherwise stated, we use Tprobe = 10 probe epochs, batch size 4, and the context–horizon pair (L, H) = (128,24) following GIFT-Eval. The default learning rate is 10−3, while TimesFM2.0 uses10 −4 for stability. Window-level preproces...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.