On the Push-Based Asynchronous Federated Learning: A Bias-Correction Aggregation Approach
Pith reviewed 2026-06-30 11:38 UTC · model grok-4.3
The pith
PushCen-ADFL corrects aggregation bias in asynchronous decentralized federated learning by mixing messages in a shared centroid space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
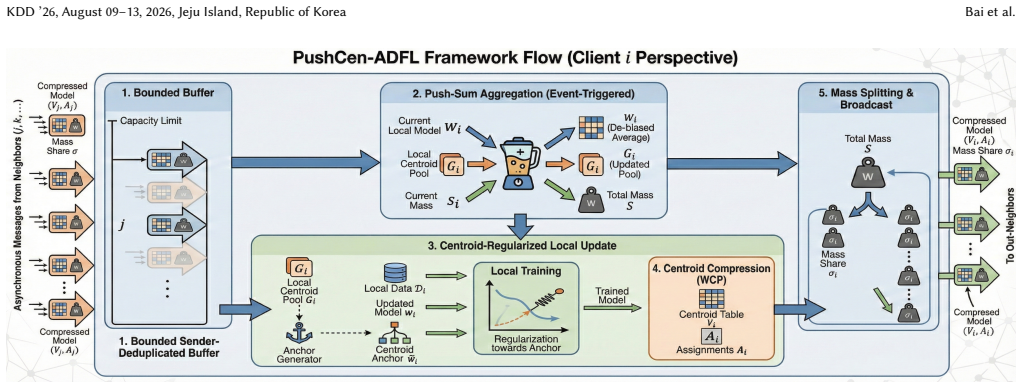
PushCen-ADFL couples communication, aggregation, and local stabilization in a shared centroid representation space, forming a closed loop between compression and optimization. Clients exchange centroid-form messages, apply average-preserving push-sum mixing to correct aggregation bias, and use a lightweight centroid regularization anchored in the same centroid space to mitigate drift under heterogeneity and staleness. A bounded, sender-deduplicated buffer further improves robustness under irregular asynchronous arrivals.
What carries the argument
The shared centroid representation space, where average-preserving push-sum mixing corrects bias and regularization mitigates drift while enabling message compression.
If this is right
- Stable training becomes possible without central coordination on directed topologies with delayed updates.
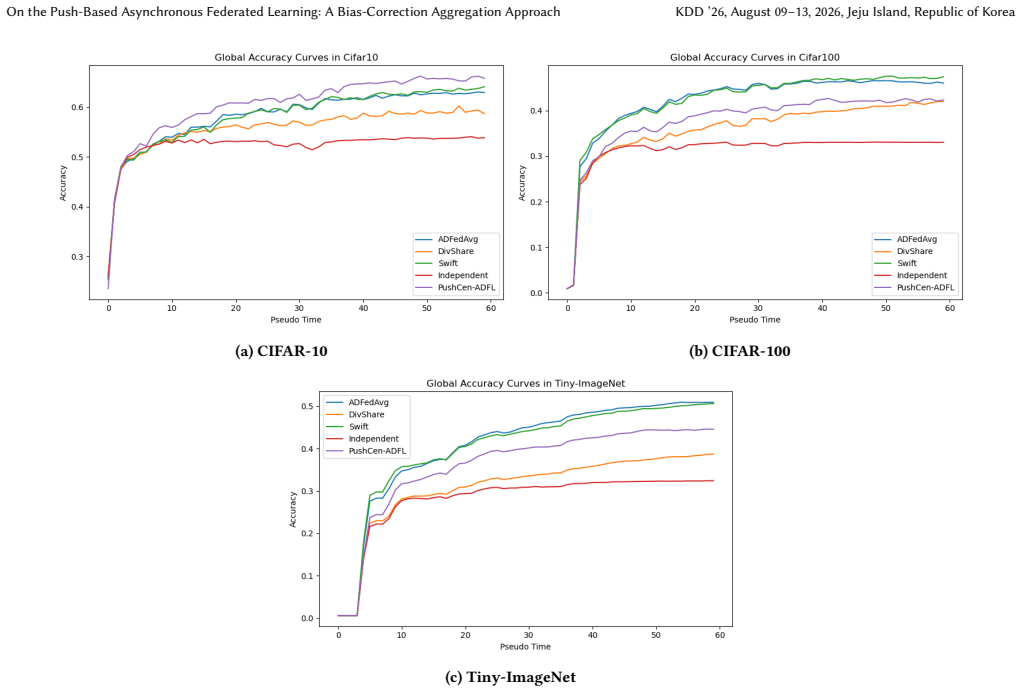
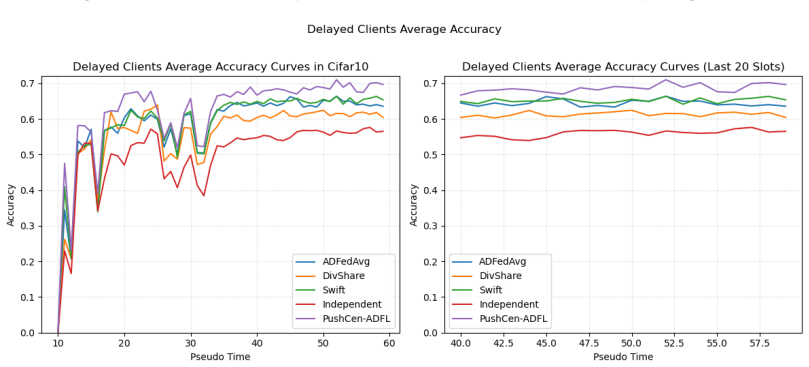
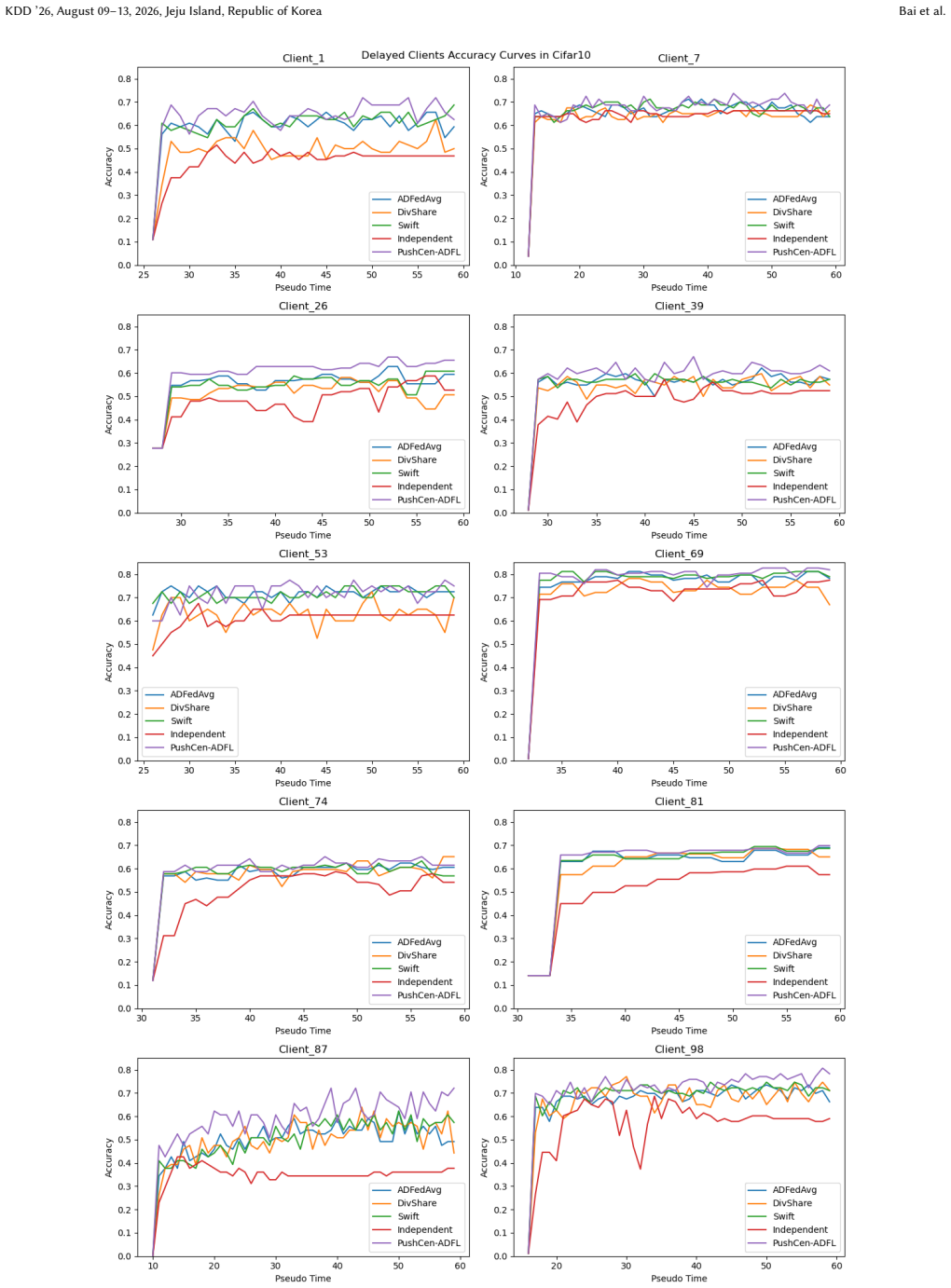
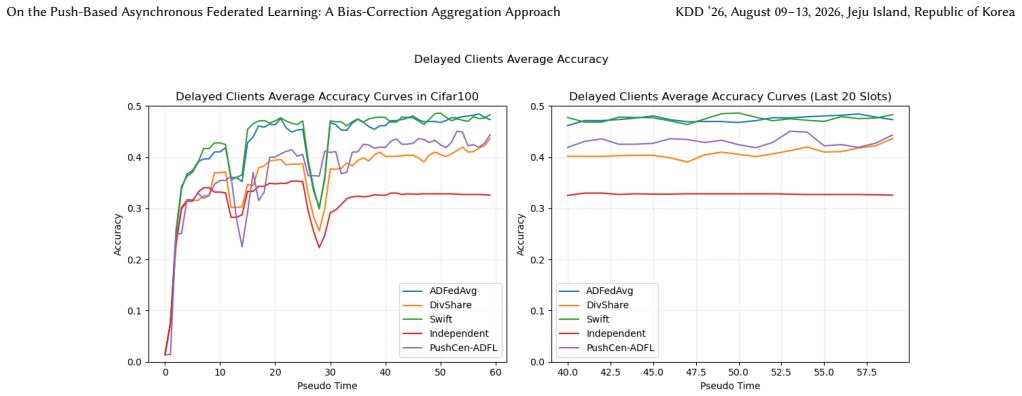
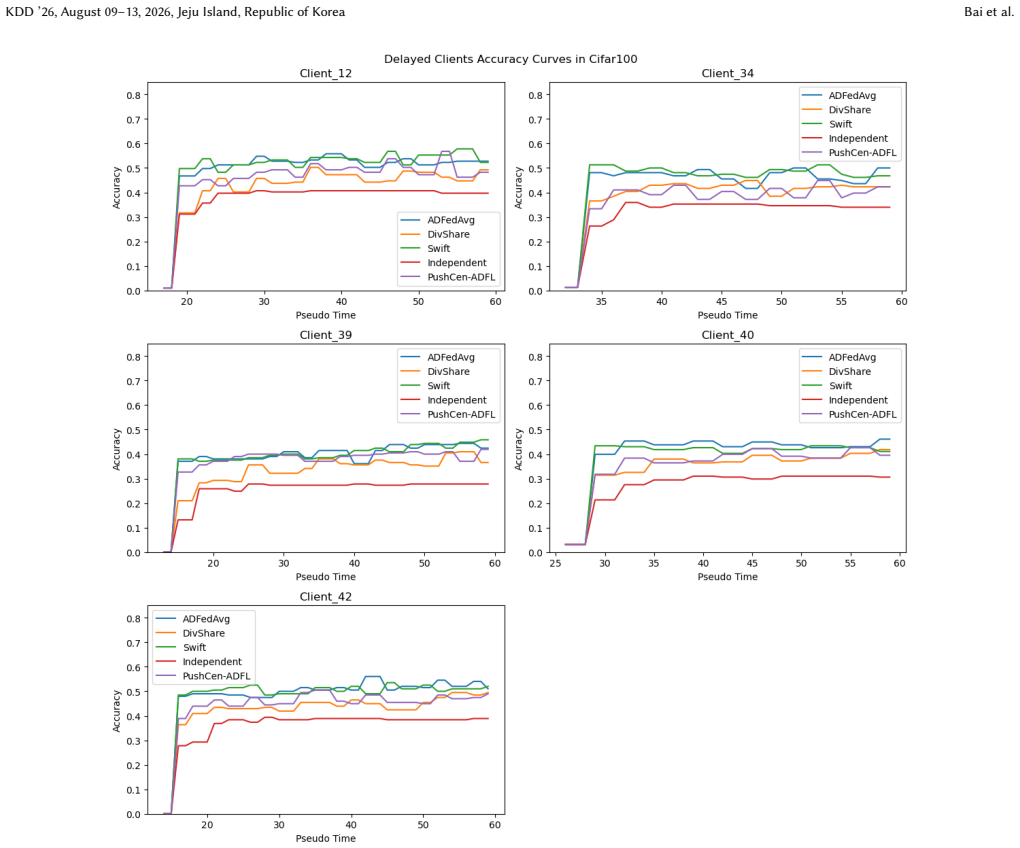
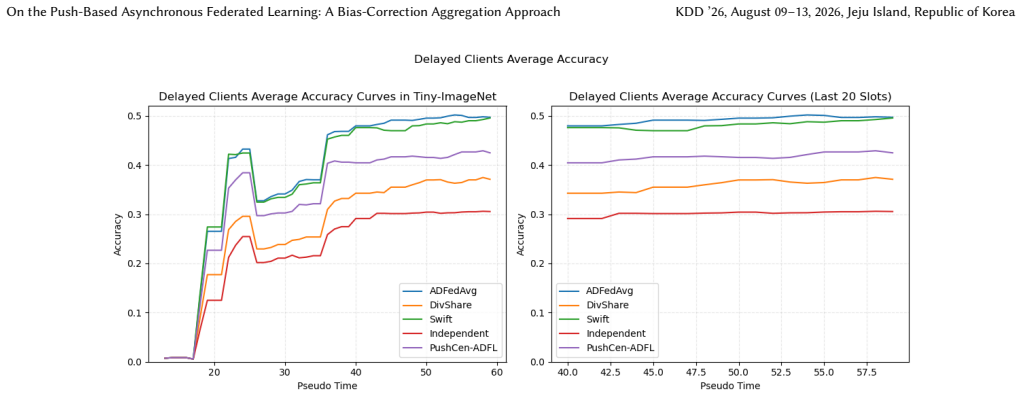
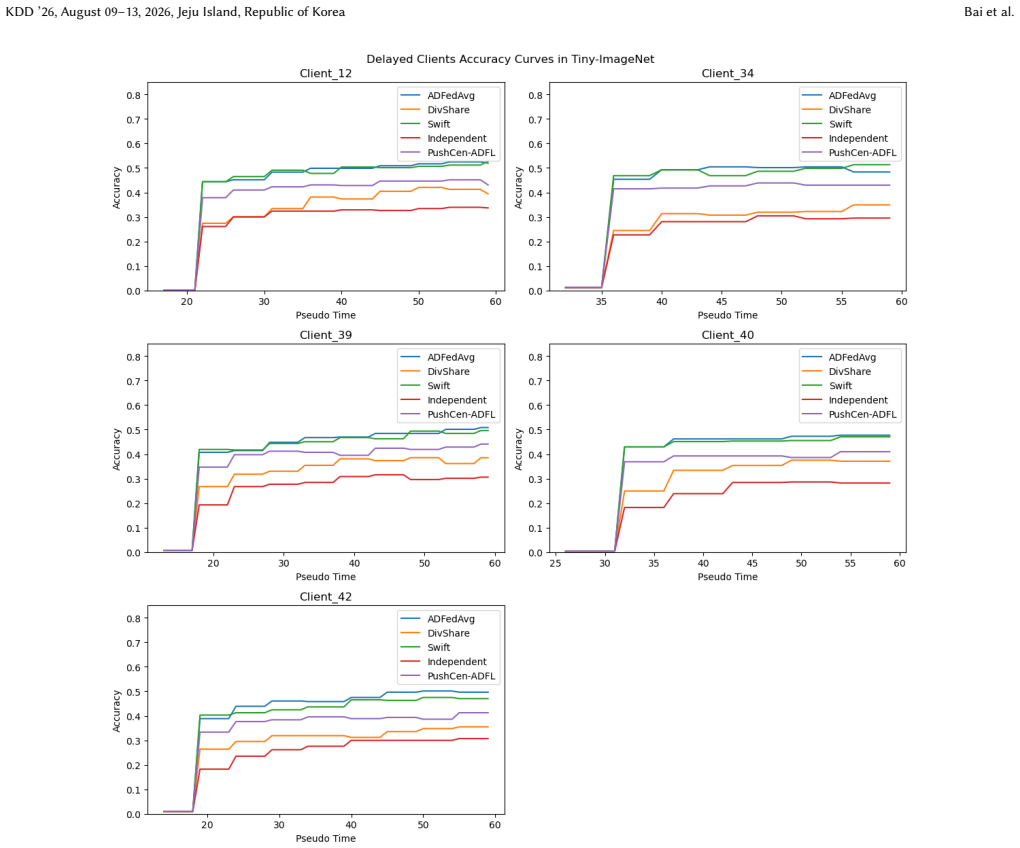
- Model accuracy increases by up to 6 percent under data heterogeneity.
- Per-push communication cost decreases by more than 80 percent.
- The method achieves a better accuracy-communication trade-off on vision datasets.
- A bounded sender-deduplicated buffer adds robustness to irregular asynchronous arrivals.
Where Pith is reading between the lines
- The centroid representation could support additional message compression methods beyond what is described.
- The bias-correction approach might extend to other asynchronous distributed optimization tasks outside federated learning.
- Performance on networks with thousands of clients remains an open question that could be tested directly.
Load-bearing premise
The assumption that average-preserving push-sum mixing in the centroid space will stably correct aggregation bias on directed topologies under non-IID data and staleness without introducing new instabilities.
What would settle it
A controlled test on a directed topology with high data heterogeneity and frequent client delays in which the method shows less than 1 percent accuracy gain or fails to cut per-push cost by at least 50 percent would challenge the central claims.
Figures
read the original abstract
Asynchronous decentralized federated learning (ADFL) eliminates central coordination and global synchronization, making it attractive for large-scale and heterogeneous systems. However, frequent peer-to-peer communication, asynchronous updates on directed topologies, and non-IID data jointly lead to excessive communication overhead, biased aggregation and severe model drift. We propose PushCen-ADFL, a communication-efficient ADFL framework that enables stable training under asymmetric communication and delayed client participation. PushCen-ADFL couples communication, aggregation, and local stabilization in a shared centroid representation space, forming a closed loop between compression and optimization. Clients exchange centroid-form messages, apply average-preserving push-sum mixing to correct aggregation bias, and use a lightweight centroid regularization anchored in the same centroid space to mitigate drift under heterogeneity and staleness. A bounded, sender-deduplicated buffer further improves robustness under irregular asynchronous arrivals. Experiments on vision datasets demonstrate that PushCen-ADFL improves accuracy under data heterogeneity by up to 6\% while reducing per-push communication cost by more than 80\%, achieving a favorable accuracy-communication trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PushCen-ADFL, a push-based asynchronous decentralized federated learning (ADFL) framework. It couples communication, aggregation, and local stabilization via a shared centroid representation space: clients exchange compressed centroid-form messages, apply average-preserving push-sum mixing to correct aggregation bias on directed topologies, and employ centroid regularization to mitigate model drift under non-IID data and staleness. A bounded sender-deduplicated buffer handles irregular asynchronous arrivals. Experiments on vision datasets are reported to yield up to 6% accuracy gains under heterogeneity while cutting per-push communication cost by more than 80%.
Significance. If the average-preserving property of push-sum mixing is shown to hold exactly under the centroid compression and bounded-buffer asynchrony, the approach would offer a practical mechanism for bias correction and communication efficiency in ADFL without central coordination. The closed-loop integration of compression and optimization in centroid space is a distinctive design choice. The empirical accuracy-communication trade-off on vision tasks, if reproducible with clear protocols, would be a useful data point for the field. However, the manuscript supplies no derivation, error analysis, or convergence argument for the bias-correction step, limiting the result's theoretical weight.
major comments (2)
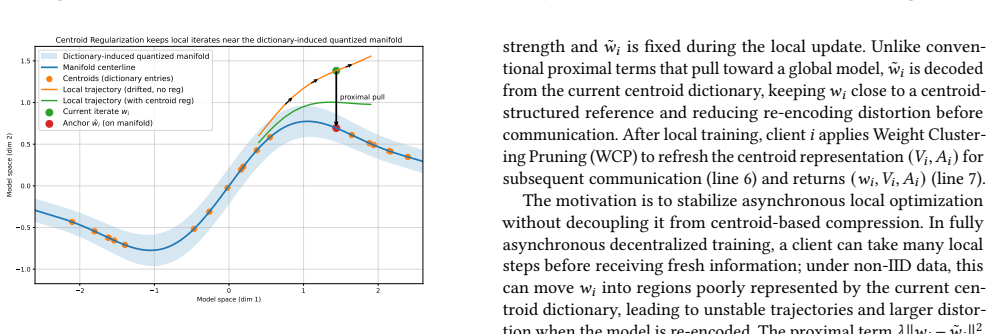
- [§3 (method description and push-sum mixing)] The central claim rests on average-preserving push-sum mixing in the centroid space to correct aggregation bias (§3, aggregation step and Algorithm 1). Push-sum requires exact column-stochastic weights for preservation; the manuscript does not demonstrate that lossy centroid compression (needed for the >80% cost reduction) or staleness from the bounded buffer leaves these weights unperturbed. On directed graphs with non-IID data this could allow residual bias to accumulate, directly undermining the robustness claim. No perturbation bound or invariance proof is supplied.
- [Experimental results section / Table 2] Table 2 (or equivalent experimental table) reports accuracy gains of up to 6% but supplies no error bars, number of runs, or statistical test; the baseline methods and exact non-IID partitioning are only sketched. Without these, it is impossible to assess whether the reported improvement is load-bearing evidence for the bias-correction mechanism or could be explained by hyper-parameter differences.
minor comments (2)
- [§2 and §3] Notation for the centroid representation and the push-sum weights is introduced without a consolidated table of symbols; readers must reconstruct the mapping between compressed messages and the column-stochastic matrix.
- [Abstract and §4] The abstract states 'improves accuracy under data heterogeneity by up to 6%' yet the main text does not explicitly state the reference method and dataset split that achieve this maximum; a single clarifying sentence would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important gaps in the theoretical justification and experimental rigor. We address each major comment below and commit to revisions that strengthen the manuscript without overstating current results.
read point-by-point responses
-
Referee: [§3 (method description and push-sum mixing)] The central claim rests on average-preserving push-sum mixing in the centroid space to correct aggregation bias (§3, aggregation step and Algorithm 1). Push-sum requires exact column-stochastic weights for preservation; the manuscript does not demonstrate that lossy centroid compression (needed for the >80% cost reduction) or staleness from the bounded buffer leaves these weights unperturbed. On directed graphs with non-IID data this could allow residual bias to accumulate, directly undermining the robustness claim. No perturbation bound or invariance proof is supplied.
Authors: We agree that the manuscript lacks a formal derivation or perturbation analysis showing that column-stochastic weights remain exactly preserved (or bounded) under centroid compression and the bounded sender-deduplicated buffer. This omission limits the strength of the bias-correction claim on directed topologies. In the revised manuscript we will add a dedicated subsection in §3 deriving the invariance property for the linear centroid compression and deduplication steps, or, if space-constrained, a first-order perturbation bound quantifying residual bias accumulation. We will also clarify that the current empirical results do not substitute for this analysis. revision: yes
-
Referee: [Experimental results section / Table 2] Table 2 (or equivalent experimental table) reports accuracy gains of up to 6% but supplies no error bars, number of runs, or statistical test; the baseline methods and exact non-IID partitioning are only sketched. Without these, it is impossible to assess whether the reported improvement is load-bearing evidence for the bias-correction mechanism or could be explained by hyper-parameter differences.
Authors: The referee is correct that the experimental reporting is insufficient for assessing statistical reliability and isolating the contribution of the bias-correction mechanism. In the revision we will expand the experimental section to report means and standard deviations over at least five independent runs, include the exact non-IID partitioning protocol (Dirichlet concentration parameter and client data sizes), provide full descriptions of all baselines with hyper-parameter settings, and add statistical significance tests (e.g., paired t-tests) for the reported accuracy differences. These changes will make the evidence for the claimed gains more robust. revision: yes
Circularity Check
No significant circularity; claims are empirical outcomes
full rationale
The abstract and description present PushCen-ADFL as a framework whose bias-correction and performance gains (up to 6% accuracy, >80% communication reduction) are reported as experimental results on vision datasets. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The 'closed loop' and average-preserving push-sum mixing are design elements whose validity rests on stated assumptions about weight summation and bounded buffers rather than reducing to self-definition or prior self-citation chains. Any concern that compression or staleness perturbs the preservation property is a correctness risk under the assumptions, not a circular reduction of the derivation to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdelkader Ilyes Ameur, Abderrahmane Lakas, Mohamed Bachir Yagoubi, and Omar Sami Oubbati. 2022. Peer-to-peer overlay techniques for vehicular ad hoc networks: Survey and challenges.Vehicular Communications34 (2022), 100455
2022
-
[2]
Mahmoud Assran, Nicolas Loizou, Nicolas Ballas, and Mike Rabbat. 2019. Sto- chastic gradient push for distributed deep learning. InInternational Conference on Machine Learning. PMLR, 344–353
2019
-
[3]
Sayan Biswas, Anne-Marie Kermarrec, Alexis Marouani, Rafael Pires, Rishi Sharma, and Martijn De Vos. 2025. Boosting asynchronous decentralized learning with model fragmentation. InProceedings of the ACM on Web Conference 2025. 685–696
2025
- [4]
-
[5]
Chen Chen, Hong Xu, Wei Wang, Baochun Li, Bo Li, Li Chen, and Gong Zhang
-
[6]
Baffle: Backdoor detection via feedback-based federated learning
Communication-Efficient Federated Learning with Adaptive Parameter Freezing. In2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS). 1–11. doi:10.1109/ICDCS51616.2021.00010
- [7]
-
[8]
Marina Danilova and Eduard Gorbunov. 2022. Distributed methods with absolute compression and error compensation. InInternational Conference on Mathematical Optimization Theory and Operations Research. Springer, 163–177
2022
-
[9]
Akash Dhasade, Anne-Marie Kermarrec, Erick Lavoie, Johan Pouwelse, Rishi Sharma, and Martijn De Vos. 2025. Practical Federated Learning without a Server. InProceedings of the 5th Workshop on Machine Learning and Systems. 1–11
2025
-
[10]
Mauro Franceschelli, Alessandro Giua, and Carla Seatzu. 2009. Consensus on the average on arbitrary strongly connected digraphs based on broadcast gossip algorithms.IFAC Proceedings Volumes42, 20 (2009), 66–71
2009
-
[11]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[12]
Eunjeong Jeong and Marios Kountouris. 2025. DRACO: Decentralized Asynchro- nous Federated Learning Over Row-Stochastic Wireless Networks.IEEE Open Journal of the Communications Society6 (2025), 4818–4839. doi:10.1109/OJCOMS. 2025.3574098
-
[13]
Zhifeng Jiang, Wei Wang, Bo Li, and Qiang Yang. 2022. Towards efficient syn- chronous federated training: A survey on system optimization strategies.IEEE Transactions on Big Data9, 2 (2022), 437–454
2022
-
[14]
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebas- tian Stich, and Ananda Theertha Suresh. 2020. Scaffold: Stochastic controlled averaging for federated learning. InInternational conference on machine learning. PMLR, 5132–5143
2020
-
[15]
Kempe, A
D. Kempe, A. Dobra, and J. Gehrke. 2003. Gossip-based computation of aggregate information. In44th Annual IEEE Symposium on Foundations of Computer Science,
2003
-
[16]
Proceedings.482–491. doi:10.1109/SFCS.2003.1238221
-
[17]
Minsu Kim, Walid Saad, Merouane Debbah, and Choong S Hong. 2024. SpaFL: Communication-efficient federated learning with sparse models and low compu- tational overhead.Advances in Neural Information Processing Systems37 (2024), 86500–86527
2024
-
[18]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[19]
Anusha Lalitha, Shubhanshu Shekhar, Tara Javidi, and Farinaz Koushanfar. 2018. Fully decentralized federated learning. InThird workshop on bayesian deep learn- ing (NeurIPS), Vol. 12
2018
-
[20]
Natalie Lang, Alejandro Cohen, and Nir Shlezinger. 2024. Stragglers-aware low- latency synchronous federated learning via layer-wise model updates.IEEE Transactions on Communications(2024)
2024
-
[21]
Yann Le and Xuan Yang. 2015. Tiny imagenet visual recognition challenge.CS 231N7, 7 (2015), 3
2015
-
[22]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. Gradient- based learning applied to document recognition.Proc. IEEE86, 11 (1998), 2278– 2324
1998
-
[23]
He Li, Kaoru Ota, and Mianxiong Dong. 2018. Learning IoT in Edge: Deep Learning for the Internet of Things with Edge Computing.IEEE Network32, 1 (2018), 96–101. doi:10.1109/MNET.2018.1700202
-
[24]
Qinbin Li, Zeyi Wen, Zhaomin Wu, Sixu Hu, Naibo Wang, Yuan Li, Xu Liu, and Bingsheng He. 2023. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection.IEEE Transactions on Knowledge and Data Engineering35, 4 (2023), 3347–3366. doi:10.1109/TKDE.2021.3124599
-
[25]
Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. 2020. On the Convergence of FedAvg on Non-IID Data. InInternational Conference on Learning Representations
2020
-
[26]
Zhiwei Li, Yiqiu Li, Binbin Lin, Zhongming Jin, and Weizhong Zhang. 2024. Low precision local training is enough for federated learning.Advances in Neural Information Processing Systems37 (2024), 90160–90197
2024
-
[27]
Yunming Liao, Yang Xu, Hongli Xu, Min Chen, Lun Wang, and Chunming Qiao
-
[28]
IEEE/ACM Transactions on Networking(2024)
Asynchronous decentralized federated learning for heterogeneous devices. IEEE/ACM Transactions on Networking(2024)
2024
-
[29]
Ji Liu, Tianshi Che, Yang Zhou, Ruoming Jin, Huaiyu Dai, Dejing Dou, and Patrick Valduriez. 2024. Aedfl: efficient asynchronous decentralized federated learning with heterogeneous devices. InProceedings of the 2024 SIAM International Conference on Data Mining (SDM). SIAM, 833–841
2024
-
[30]
Ji Liu, Juncheng Jia, Tianshi Che, Chao Huo, Jiaxiang Ren, Yang Zhou, Huaiyu Dai, and Dejing Dou. 2024. Fedasmu: Efficient asynchronous federated learning with dynamic staleness-aware model update. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 13900–13908
2024
-
[31]
Qi Liu, Bo Yang, Zhaojian Wang, Dafeng Zhu, Xinyi Wang, Kai Ma, and Xinping Guan. 2022. Asynchronous decentralized federated learning for collaborative fault diagnosis of PV stations.IEEE Transactions on Network Science and Engineering9, 3 (2022), 1680–1696
2022
-
[32]
Tao Liu, Zhi Wang, Hui He, Wei Shi, Liangliang Lin, Ran An, and Chenhao Li
-
[33]
KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Bai et al
Efficient and secure federated learning for financial applications.Applied Sciences13, 10 (2023), 5877. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Bai et al
2023
-
[34]
Qianpiao Ma, Jianchun Liu, Qingmin Jia, Xiaomao Zhou, Yujiao Hu, and Renchao Xie. 2024. Dynamic Staleness Control for Asynchronous Federated Learning in Decentralized Topology. InInternational Conference on Wireless Artificial Intelli- gent Computing Systems and Applications. Springer, 99–117
2024
-
[35]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep net- works from decentralized data. InArtificial intelligence and statistics. PMLR, 1273–1282
2017
-
[36]
Fahad Razaque Mughal, Jingsha He, Bhagwan Das, Fayaz Ali Dharejo, Nafei Zhu, Surbhi Bhatia Khan, and Saeed Alzahrani. 2024. Adaptive federated learning for resource-constrained IoT devices through edge intelligence and multi-edge clustering.Scientific Reports14, 1 (2024), 28746
2024
-
[37]
2023.𝐴2𝐶𝑖𝐷 2: Accelerating Asynchronous Communication in Decentralized Deep Learning.Advances in Neural Information Processing Systems36 (2023), 47451–47474
Adel Nabli, Eugene Belilovsky, and Edouard Oyallon. 2023.𝐴2𝐶𝑖𝐷 2: Accelerating Asynchronous Communication in Decentralized Deep Learning.Advances in Neural Information Processing Systems36 (2023), 47451–47474
2023
-
[38]
Angelia Nedić and Alex Olshevsky. 2014. Distributed optimization over time- varying directed graphs.IEEE Trans. Automat. Control60, 3 (2014), 601–615
2014
-
[39]
John Nguyen, Kshitiz Malik, Hongyuan Zhan, Ashkan Yousefpour, Mike Rabbat, Mani Malek, and Dzmitry Huba. 2022. Federated learning with buffered asyn- chronous aggregation. InInternational conference on artificial intelligence and statistics. PMLR, 3581–3607
2022
-
[40]
Mario E Rivero-Angeles, Izlian Y Orea-Flores, Andrés Lucas-Bravo, Iclia Villordo- Jiménez, Miguel F Mata-Rivera, Luis A Macedo Santiago, and Mónica L Morales- Varela. 2022. Data Dissemination Performance in P2P-Based Vehicular Commu- nications for Smart City Environments.Wireless Communications and Mobile Computing2022, 1 (2022), 7202412
2022
-
[41]
Tao Sun, Dongsheng Li, and Bao Wang. 2023. Decentralized Federated Averaging. IEEE Transactions on Pattern Analysis and Machine Intelligence45, 4 (2023), 4289–
2023
-
[42]
doi:10.1109/TPAMI.2022.3196503
-
[43]
Yujia Wang, Yuanpu Cao, Jingcheng Wu, Ruoyu Chen, and Jinghui Chen. 2024. TACKLING THE DATA HETEROGENEITY IN ASYNCHRONOUS FEDERATED LEARNING WITH CACHED UPDATE CALIBRATION. In12th International Conference on Learning Representations, ICLR 2024
2024
-
[44]
Chuhan Wu, Fangzhao Wu, Lingjuan Lyu, Yongfeng Huang, and Xing Xie. 2022. Communication-efficient federated learning via knowledge distillation.Nature communications13, 1 (2022), 2032
2022
-
[45]
Liangqi Yuan, Ziran Wang, Lichao Sun, Philip S Yu, and Christopher G Brinton
-
[46]
Decentralized federated learning: A survey and perspective.IEEE Internet of Things Journal11, 21 (2024), 34617–34638
2024
-
[47]
Shahryar Zehtabi, Dong-Jun Han, Rohit Parasnis, Seyyedali Hosseinalipour, and Christopher G Brinton. 2025. Decentralized Sporadic Federated Learning: A Unified Algorithmic Framework with Convergence Guarantees. InICLR. On the Push-Based Asynchronous Federated Learning: A Bias-Correction Aggregation Approach KDD ’26, August 09–13, 2026, Jeju Island, Republ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.