ARBITER: Reasoning Trajectory Basins and Majority Vote Failures in Test-Time Sampling
Pith reviewed 2026-06-29 22:19 UTC · model grok-4.3
The pith
Language model test-time sampling trajectories form reasoning basins that cause majority vote to select the most popular answer rather than the correct one, and ARBITER recovers part of the gap using only the model's own samples and hidden
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
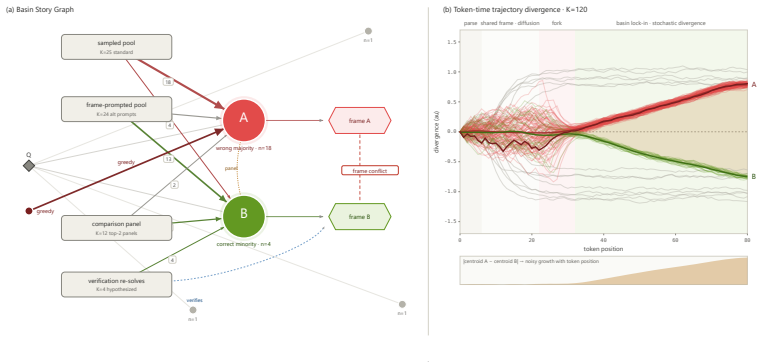
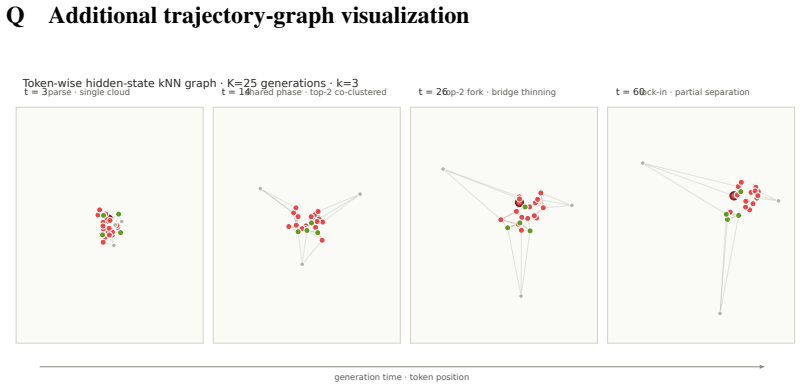
Reasoning trajectories concentrate into a small number of clusters, or reasoning basins, each defined by a normalized final answer and the solutions that reach it. A majority vote therefore selects the most stable basin rather than the most accurate one, which creates wrong-majority failures where the correct answer is present but outvoted. ARBITER models interactions between basins using only the base model's own sampled outputs, hidden states, and derived evidence. It applies conservative additive evidence on top of consensus rather than direct correction; in its parameter-free form it adds same-model evidence to the majority prior, while an extended form augments this with bounded residua
What carries the argument
Reasoning basins, clusters of trajectories sharing a normalized final answer and the solution paths leading to it; the mechanism explains why majority vote fails and supplies the structure that ARBITER uses to add conservative evidence.
If this is right
- ARBITER produces consistent accuracy gains on GSM8K, MMLU-HS-Math and related benchmarks across three model families.
- On Llama-3.1-8B MMLU-HS-Math the method lifts accuracy from the mid-78 percent range to the mid-82 percent range.
- The gains recover roughly 22 percent of the headroom visible to a same-pool top-2 oracle.
- Both the parameter-free ARBITER-Δ and the hidden-state-augmented ARBITER-Enc versions operate without external information or additional training.
- No net-negative accuracy cases appear across the reported model-benchmark combinations.
Where Pith is reading between the lines
- If reasoning basins remain stable when sampling parameters such as temperature change, ARBITER could be combined with temperature sweeps to enlarge the recoverable headroom.
- The same basin structure may appear in non-mathematical reasoning tasks, allowing the conservative-evidence approach to transfer without task-specific redesign.
- Hidden-state residuals that survive the bounded encoding step suggest that intermediate activations contain additional recoverable signals about trajectory quality beyond the final answer token.
- Scaling the sample pool size while keeping the same conservative addition rule would likely increase the fraction of oracle headroom that can be captured internally.
Load-bearing premise
Interactions between basins can be modeled using only the base model's sampled outputs, hidden states, and derived evidence, and conservative additive evidence on top of consensus will produce gains without net-negative effects on any benchmark.
What would settle it
A controlled experiment on one of the tested model families and math benchmarks in which ARBITER applied to the same sample pool produces lower accuracy than plain majority vote.
Figures
read the original abstract
When language models use test-time sampling, they generate multiple reasoning trajectories and select an answer by majority vote. We show that these trajectories are not independent: for a given question, they concentrate into a small number of clusters, or reasoning basins, each defined by a normalized final answer and the solutions that reach it. A majority vote therefore selects the most stable basin rather than the most accurate one, which creates wrong-majority failures where the correct answer is present but outvoted. We introduce ARBITER, a model-agnostic approach that models interactions between basins using only the base model's own sampled outputs, hidden states, and derived evidence. Most direct correction strategies fail; ARBITER instead uses conservative additive evidence on top of consensus. In its simplest parameter-free form, ARBITER-{\Delta} adds same-model evidence to the majority prior, while ARBITER-Enc augments this with bounded residual signals from hidden states over complete solutions. On GSM8K with Qwen3-4B, consensus over K=24 samples achieves around the mid-94% range, while a same-pool top-2 oracle reaches around the mid-96% range. ARBITER recovers a subset of these cases using zero external information. Across three model families and three math benchmarks, it yields consistent gains with no net-negative cases; for example, on Llama-3.1-8B MMLU-HS-Math, it improves accuracy from the mid-78% range to the mid-82% range, recovering about 22% of the available oracle headroom, indicating that this headroom can be partially recovered from the sample pool itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that test-time sampling trajectories in LLMs cluster into a small number of reasoning basins (defined by normalized final answers), causing majority vote to select the most populous rather than most accurate basin and producing wrong-majority failures. ARBITER is proposed as a model-agnostic correction that models basin interactions using only the base model's sampled outputs, hidden states, and derived evidence; its simplest form (ARBITER-Δ) is parameter-free and adds conservative same-model evidence to the majority prior, while ARBITER-Enc augments this with bounded residual signals from hidden states. Experiments across three model families and three math benchmarks report consistent accuracy gains with no net-negative cases, recovering a portion (e.g., ~22%) of same-pool oracle headroom (e.g., GSM8K Qwen3-4B consensus ~mid-94% to higher with ARBITER).
Significance. If the empirical results hold, the work is significant because it identifies a structural failure mode in the widely used majority-vote aggregation for test-time scaling and supplies a practical, zero-external-data remedy that operates entirely within the sample pool. The emphasis on conservative additive evidence and the parameter-free ARBITER-Δ variant are notable strengths that could translate to reproducible improvements in reasoning benchmarks without additional training or external verifiers.
major comments (2)
- [Abstract] Abstract: the reported ranges (mid-94% consensus, mid-96% oracle on GSM8K; mid-78% to mid-82% on Llama-3.1-8B MMLU-HS-Math) are given without exact accuracies, standard errors, or run counts, so the statistical reliability of the 'consistent gains with no net-negative cases' claim cannot be assessed from the provided summary.
- [Method] Method description (implied in abstract): the claim that ARBITER-Δ is strictly parameter-free and that ARBITER-Enc uses only 'bounded residual signals' requires an explicit statement of the basin-clustering procedure, the exact additive evidence formula, and confirmation that no test-set tuning occurs, because any hidden dependence on the same sample pool would undermine the 'recovers headroom from the sample pool itself' interpretation.
minor comments (2)
- [Abstract] The abstract uses approximate ranges ('mid-94% range') rather than precise percentages; replace with exact values and confidence intervals in the results section.
- [Method] Clarify the precise definition of 'normalized final answer' used to delineate basins and how hidden-state residuals are extracted and bounded.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, recognition of the structural failure mode in majority voting, and recommendation for minor revision. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported ranges (mid-94% consensus, mid-96% oracle on GSM8K; mid-78% to mid-82% on Llama-3.1-8B MMLU-HS-Math) are given without exact accuracies, standard errors, or run counts, so the statistical reliability of the 'consistent gains with no net-negative cases' claim cannot be assessed from the provided summary.
Authors: We agree that the abstract's use of ranges without exact figures, standard errors, or run counts limits assessment of statistical reliability. In the revised version we will replace the range phrasing with precise accuracy values (including standard errors where computed), state the number of runs, and retain the 'no net-negative cases' claim only with supporting per-benchmark details moved from the main text. revision: yes
-
Referee: [Method] Method description (implied in abstract): the claim that ARBITER-Δ is strictly parameter-free and that ARBITER-Enc uses only 'bounded residual signals' requires an explicit statement of the basin-clustering procedure, the exact additive evidence formula, and confirmation that no test-set tuning occurs, because any hidden dependence on the same sample pool would undermine the 'recovers headroom from the sample pool itself' interpretation.
Authors: We will add an explicit subsection detailing the basin-clustering procedure (normalized final-answer grouping), the exact additive-evidence formula used by ARBITER-Δ, and the bounded-residual construction for ARBITER-Enc. We will also insert a clear statement confirming that all signals are computed from the per-question sample pool alone, with no test-set tuning or external data, thereby preserving the internal-to-the-pool interpretation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents ARBITER as a parameter-free empirical method that operates exclusively on quantities already present in the base model's sample pool (outputs, hidden states, derived evidence). The central claims consist of direct experimental observations of accuracy gains across three model families and three benchmarks, with no net-negative cases and partial recovery of oracle headroom from the same pool. No equations, derivation steps, or self-citations appear in the abstract or described method that could reduce any prediction or result to a fitted input or self-definition by construction. The approach is explicitly described as adding conservative additive evidence on top of consensus rather than fitting parameters to the target metric. The derivation chain is therefore self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, S \'e bastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, James R. Lee, Yin Tat Lee, Yuanzhi Li, Weishung Liu, Caio C. T. Mendes, Anh Nguyen, Eric Price, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Xin Wang, Rachel Ward, Yue Wu, Dingli...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Jinkun Chen, Fengxiang Cheng, Sijia Han, and Vlado Keselj. ``I may not have articulated myself clearly'': Diagnosing dynamic instability in LLM reasoning at inference time. arXiv preprint arXiv:2602.02863, 2026. URL https://arxiv.org/abs/2602.02863
-
[3]
Universal self-consistency for large language model generation
Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. Universal self-consistency for large language model generation. arXiv preprint arXiv:2311.17311, 2023. URL https://arxiv.org/abs/2311.17311
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021. URL https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Can LLMs predict their own failures? self-awareness via internal circuits
Amirhosein Ghasemabadi and Di Niu. Can LLMs predict their own failures? self-awareness via internal circuits. arXiv preprint arXiv:2512.20578, 2025. URL https://arxiv.org/abs/2512.20578
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
A stitch in time saves nine: Proactive self-refinement for language models
Jinyi Han, Xinyi Wang, Haiquan Zhao, Tingyun Li, Zishang Jiang, Sihang Jiang, Jiaqing Liang, Xin Lin, Weikang Zhou, Zeye Sun, Fei Yu, and Yanghua Xiao. A stitch in time saves nine: Proactive self-refinement for language models. arXiv preprint arXiv:2508.12903, 2025. URL https://arxiv.org/abs/2508.12903
-
[8]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021 a . URL https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Advances in Neural Information Processing Systems, 2021 b . URL https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Large Language Models Cannot Self-Correct Reasoning Yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. In International Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2310.01798
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Semantic self-consistency: Enhancing language model reasoning via semantic weighting, 2024
Tim Knappe, Ryan Li, Ayush Chauhan, Kaylee Chhua, Kevin Zhu, and Sean O'Brien. Semantic self-consistency: Enhancing language model reasoning via semantic weighting, 2024. URL https://arxiv.org/abs/2410.07839
-
[12]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention . In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. URL https://arxiv.org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Mario S a s ko, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven Le Scao, Victor Sanh, Canwen Xu, Nicolas Patry, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugg...
-
[14]
Qintong Li, Leyang Cui, Xueliang Zhao, Lingpeng Kong, and Wei Bi. GSM -plus: A comprehensive benchmark for evaluating the robustness of LLM s as mathematical problem solvers. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2961--2984, Bangkok, Thailand, 2024. Association for Computa...
-
[15]
Entropy-gated branching for efficient test-time reasoning
Xianzhi Li, Ethan Callanan, Abdellah Ghassel, and Xiaodan Zhu. Entropy-gated branching for efficient test-time reasoning. arXiv preprint arXiv:2503.21961, 2025. URL https://arxiv.org/abs/2503.21961
-
[16]
CLUE : Non-parametric verification from experience via hidden-state clustering, 2025
Zhenwen Liang, Ruosen Li, Yujun Zhou, Linfeng Song, Dian Yu, Xinya Du, Haitao Mi, and Dong Yu. CLUE : Non-parametric verification from experience via hidden-state clustering, 2025. URL https://arxiv.org/abs/2510.01591
-
[17]
Zhixiang Liang, Beichen Huang, Zheng Wang, and Minjia Zhang. Hidden states as early signals: Step-level trace evaluation and pruning for efficient test-time scaling. arXiv preprint arXiv:2601.09093, 2026. URL https://arxiv.org/abs/2601.09093
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In International Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. In Advances in Neural Information Processing Sy...
2023
-
[20]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. GSM-Symbolic : Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229, 2024. URL https://arxiv.org/abs/2410.05229
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Jungsuk Oh and Jay-Yoon Lee. Latent self-consistency for reliable majority-set selection in short- and long-answer reasoning, 2025. URL https://arxiv.org/abs/2508.18395
-
[22]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas K\"opf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch : An imperative style, high-pe...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Internalizing LLM reasoning via discovery and replay of latent actions
Zhenning Shi, Yijia Zhu, Junhan Shi, Xun Zhang, Lei Wang, and Congcong Miao. Internalizing LLM reasoning via discovery and replay of latent actions. arXiv preprint arXiv:2602.04925, 2026. URL https://arxiv.org/abs/2602.04925
-
[24]
Narasimhan, and Shunyu Yao
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R. Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/1b44b878bb782e6954cd888628510e90-Abstract-Conference.html
2023
-
[25]
Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=4FWAwZtd2n
2025
-
[26]
Accurate failure prediction in agents does not imply effective failure prevention
Rakshith Vasudev, Melisa Russak, Dan Bikel, and Waseem Alshikh. Accurate failure prediction in agents does not imply effective failure prevention. arXiv preprint arXiv:2602.03338, 2026. URL https://arxiv.org/abs/2602.03338
-
[27]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations, 2023. URL https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, 2022. URL https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R \'e mi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the...
-
[30]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Small language models need strong verifiers to self-correct reasoning
Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, and Lu Wang. Small language models need strong verifiers to self-correct reasoning. In Findings of the Association for Computational Linguistics: ACL 2024, pages 15637--15653, Bangkok, Thailand, 2024. Association for Computational Linguistics. doi:10.18653/v1/2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.