AutoDFT: A Closed-Loop Multi-Agent Framework for Autonomous DFT Calculations
Pith reviewed 2026-06-29 21:45 UTC · model grok-4.3
The pith
AutoDFT embeds LLM agents in a closed loop to plan, execute, monitor, and repair DFT calculations at every stage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
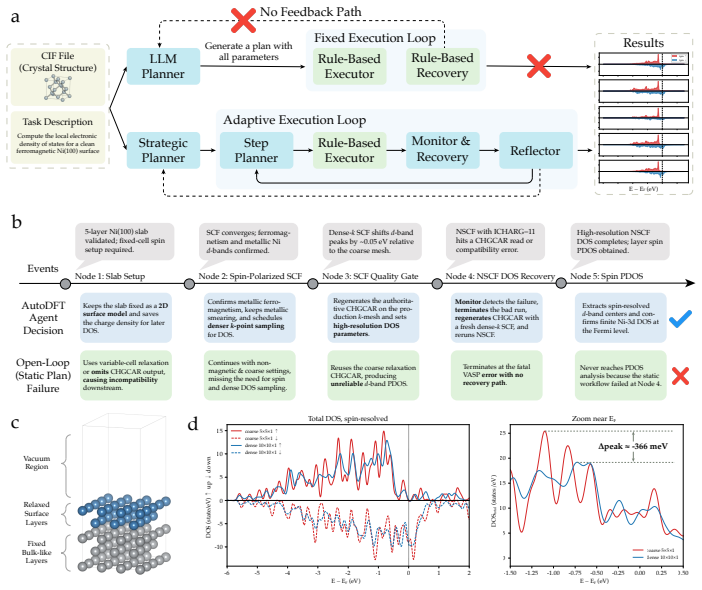
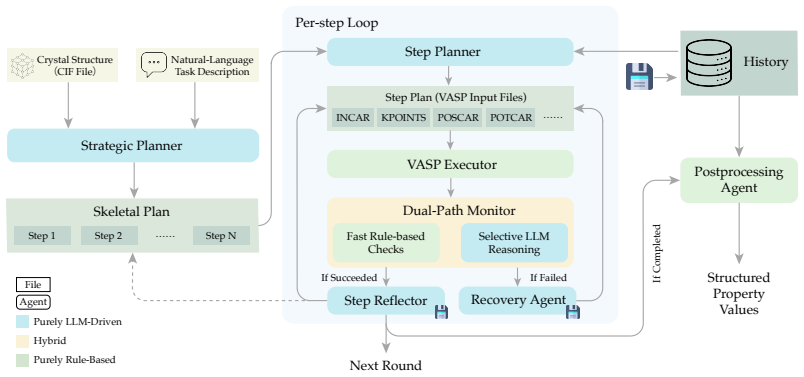
AutoDFT places LLM reasoning inside every stage of the DFT lifecycle: a strategic planner produces a skeletal plan of step objectives, a step planner generates numerical parameters just in time from preceding results, and a monitor-recover-reflect cycle diagnoses failures, repairs them, and revises the plan when the evidence justifies it. On VASPBench spanning 34 tasks and 9 DFT calculation types the system reaches 94.1 percent task-level success with GPT-5.2; on established materials databases it yields quantitatively reliable predictions for electronic, magnetic, and energetic properties.
What carries the argument
The closed-loop multi-agent framework that interleaves a strategic planner, a just-in-time step planner, and a monitor-recover-reflect cycle so the system can adapt after each calculation result.
Load-bearing premise
LLM agents can correctly diagnose DFT convergence failures or unexpected physics and generate valid repairs or plan revisions without introducing new errors or requiring expert human intervention in the majority of cases.
What would settle it
Run AutoDFT on a fresh collection of materials where convergence repeatedly fails or unexpected band structures appear, and check whether the recovery cycle produces valid corrected calculations without human edits more often than it introduces new errors or loops.
Figures
read the original abstract
Density functional theory (DFT) serves as the basis for computational discovery in materials science and chemistry, yet each calculation demands extensive human effort: adjusting algorithms when convergence stalls, revising plans when unexpected physics emerges, and inserting steps as intermediate results reshape the problem. Existing LLM-based agents automate only the initial planning stage, producing a full execution plan upfront and leaving all subsequent adaptation to hand-crafted rules. As a result, these workflows remain fragile, do not generalize well beyond pre-planned scenarios, and often require expert intervention when failures or unexpected intermediate results require changes to the calculation path. Here, we introduce AutoDFT, a closed-loop multi-agent framework that embeds LLM reasoning into every stage of the DFT lifecycle, where a strategic planner produces a skeletal plan of step objectives; a step planner generates numerical parameters just in time from preceding results; and a monitor-recover-reflect cycle diagnoses failures, repairs them, and revises the plan when the evidence justifies it. We demonstrate both breadth and depth: breadth on VASPBench, a purpose-built benchmark spanning 34 tasks and 9 DFT calculation types, where AutoDFT achieves 94.1% task-level success with GPT-5.2; and depth on established materials databases, where AutoDFT produces quantitatively reliable property predictions across electronic, magnetic, and energetic properties. By closing the loop between planning and execution, AutoDFT enables experimentalists without deep computational expertise to obtain reliable first-principles results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AutoDFT, a closed-loop multi-agent LLM framework for autonomous DFT calculations. A strategic planner generates a skeletal plan of step objectives; a step planner produces numerical parameters just-in-time based on prior results; and a monitor-recover-reflect cycle diagnoses convergence failures or unexpected physics, repairs parameters or revises the plan, and reflects on outcomes. Evaluation claims include 94.1% task-level success on VASPBench (34 tasks, 9 DFT calculation types) using GPT-5.2, plus quantitatively reliable predictions of electronic, magnetic, and energetic properties on established materials databases, enabling non-experts to obtain first-principles results without extensive intervention.
Significance. If the evaluation protocol, recovery accuracy, and reliability metrics are shown to be robust, the work could meaningfully advance automation of DFT workflows in materials science by addressing the fragility of upfront-planning approaches. The purpose-built VASPBench and closed-loop design are positive elements that target a practical bottleneck. No machine-checked proofs or open reproducible code are described.
major comments (2)
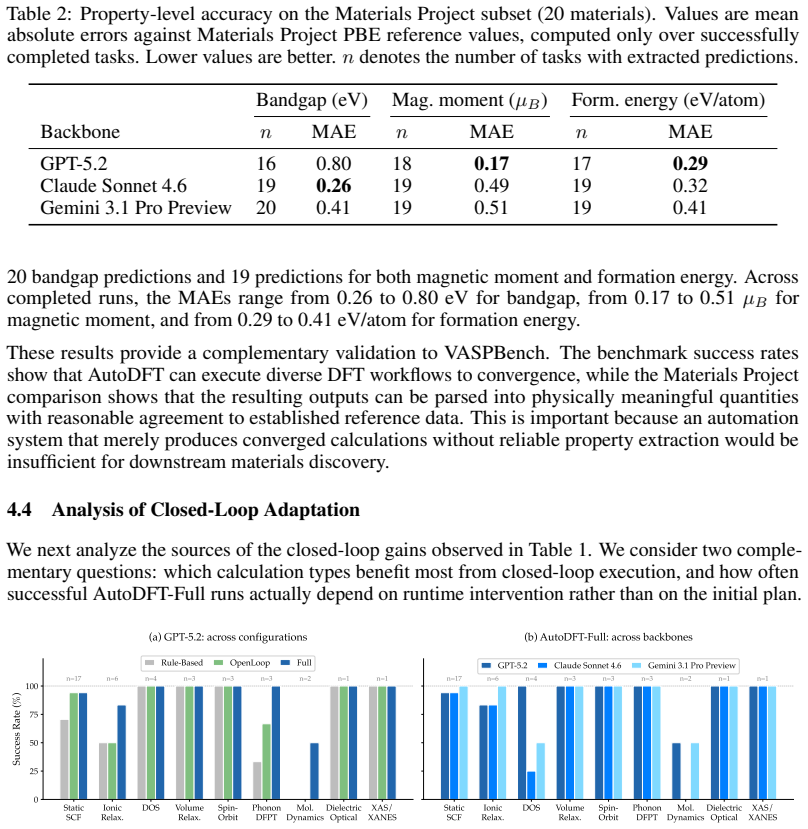
- [§4 (VASPBench results)] §4 (VASPBench results): The headline 94.1% task-level success rate is reported without any breakdown of how often the monitor-recover-reflect cycle was invoked, what fraction of recoveries succeeded, or the rate at which the LLM misdiagnosed issues (e.g., confusing k-point sampling with convergence-parameter problems). This information is load-bearing for the central claim that the framework generalizes beyond pre-planned scenarios and eliminates expert intervention.
- [Abstract and §5 (property predictions)] Abstract and §5 (property predictions): The assertion of 'quantitatively reliable property predictions' across electronic, magnetic, and energetic properties supplies no evaluation metrics, baselines, statistical tests, or definition of 'quantitatively reliable.' Without these, the depth claim cannot be assessed and is central to the manuscript's contribution.
minor comments (2)
- [Methods] Clarify whether 'GPT-5.2' denotes a released model or an internal variant, and state the exact model identifier and temperature settings used in all experiments.
- [Figure 1] Ensure workflow diagrams explicitly label the interfaces between the strategic planner, step planner, and monitor-recover-reflect modules.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive report. The two major comments identify important gaps in the evaluation details that we agree need to be addressed to strengthen the manuscript. We respond to each point below and will incorporate the requested information in the revised version.
read point-by-point responses
-
Referee: [§4 (VASPBench results)] §4 (VASPBench results): The headline 94.1% task-level success rate is reported without any breakdown of how often the monitor-recover-reflect cycle was invoked, what fraction of recoveries succeeded, or the rate at which the LLM misdiagnosed issues (e.g., confusing k-point sampling with convergence-parameter problems). This information is load-bearing for the central claim that the framework generalizes beyond pre-planned scenarios and eliminates expert intervention.
Authors: We agree that a breakdown of monitor-recover-reflect invocations, recovery success rates, and misdiagnosis instances is necessary to support the central claims. The current manuscript reports only the aggregate 94.1% task-level success rate on VASPBench without these details. In the revision we will add to §4 a quantitative analysis of cycle invocations across the 34 tasks, the fraction of successful recoveries, and any observed misdiagnoses (with examples), thereby clarifying the contribution of the closed-loop mechanism. revision: yes
-
Referee: [Abstract and §5 (property predictions)] Abstract and §5 (property predictions): The assertion of 'quantitatively reliable property predictions' across electronic, magnetic, and energetic properties supplies no evaluation metrics, baselines, statistical tests, or definition of 'quantitatively reliable.' Without these, the depth claim cannot be assessed and is central to the manuscript's contribution.
Authors: We acknowledge that the manuscript does not supply the quantitative metrics, baselines, or statistical tests needed to substantiate the claim of quantitatively reliable property predictions. The abstract and §5 currently use the phrase without supporting numbers or comparisons. In the revision we will expand both sections to report specific metrics (e.g., MAE/RMSE against reference values from the databases), include appropriate baselines and statistical tests, and provide an explicit definition of the term in this context. revision: yes
Circularity Check
No circularity: engineering framework with no derivation chain or equations
full rationale
The paper presents an LLM-based multi-agent system for automating DFT workflows. No mathematical derivations, fitted parameters, predictions from equations, or self-referential definitions are present. Claims rest on empirical benchmark results (94.1% success on VASPBench) rather than any closed logical loop or self-citation that reduces a result to its inputs by construction. This is a standard non-finding for applied engineering papers without theoretical derivation steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
System Card: Claude Sonnet 4.6
Anthropic. System Card: Claude Sonnet 4.6. Technical report, Anthropic, Feb 2026
2026
-
[2]
Autonomous chemical research with large language models.Nature, 2023
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 2023
2023
-
[3]
Hart, Michal Jahnatek, Roman V
Stefano Curtarolo, Wahyu Setyawan, Gus L.W. Hart, Michal Jahnatek, Roman V . Chepulskii, Richard H. Taylor, Shidong Wang, Junkai Xue, Kesong Yang, Ohad Levy, Michael J. Mehl, Harold T. Stokes, Denis O. Demchenko, and Dane Morgan. AFLOW: An automatic framework for high-throughput materials discovery.Computational Materials Science, 2012
2012
-
[4]
The high-throughput highway to computational materials design.Nature Materials, 2013
Stefano Curtarolo, Gus LW Hart, Marco Buongiorno Nardelli, Natalio Mingo, Stefano Sanvito, and Ohad Levy. The high-throughput highway to computational materials design.Nature Materials, 2013
2013
-
[5]
Mining experi- mental data from materials science literature with large language models: an evaluation study
Luca Foppiano, Guillaume Lambard, Toshiyuki Amagasa, and Masashi Ishii. Mining experi- mental data from materials science literature with large language models: an evaluation study. Science and Technology of Advanced Materials: Methods, 2024
2024
-
[6]
Ganose, Hrushikesh Sahasrabuddhe, Mark Asta, Kevin Beck, Tathagata Biswas, Alexander Bonkowski, Joana Bustamante, Xin Chen, Yuan Chiang, Daryl C
Alex M. Ganose, Hrushikesh Sahasrabuddhe, Mark Asta, Kevin Beck, Tathagata Biswas, Alexander Bonkowski, Joana Bustamante, Xin Chen, Yuan Chiang, Daryl C. Chrzan, Jacob Clary, Orion A. Cohen, Christina Ertural, Max C. Gallant, Janine George, Sophie Gerits, Rhys E. A. Goodall, Rishabh D. Guha, Geoffroy Hautier, Matthew Horton, T. J. Inizan, Aaron D. Kaplan,...
2025
-
[7]
Alireza Ghafarollahi and Markus J. Buehler. Automating alloy design and discovery with physics-aware multimodal multiagent ai.Proceedings of the National Academy of Sciences, 2025
2025
-
[8]
Gemini 3.1 ProModel Card
Google DeepMind. Gemini 3.1 ProModel Card. Technical report, Google DeepMind, Feb 2026
2026
-
[9]
Mat- Seek: An automated knowledge-driven framework for materials research
Jianguo Huang, Yuhao Lu, Yanchen Deng, Chendong Zhao, Penghui Yang, Zhonghan Zhang, Yixuan Li, Yushan Xiao, Cuntai Guan, Bijun Tang, Xinrun Wang, Zheng Liu, and Bo An. Mat- Seek: An automated knowledge-driven framework for materials research. InAI for Accelerated Materials Design Workshop at ICLR 2026, 2026
2026
-
[10]
Anubhav Jain, Shyue Ping Ong, Geoffroy Hautier, Wei Chen, William Davidson Richards, Stephen Dacek, Shreyas Cholia, Dan Gunter, David Skinner, Gerbrand Ceder, and Kristin A. Persson. Commentary: The materials project: A materials genome approach to accelerating materials innovation.APL Materials, 2013
2013
-
[11]
Anubhav Jain, Shyue Ping Ong, Wei Chen, Bharat Medasani, Xiaohui Qu, Michael Kocher, Miriam Brafman, Guido Petretto, Gian-Marco Rignanese, Geoffroy Hautier, Daniel Gunter, and Kristin A. Persson. FireWorks: a dynamic workflow system designed for high-throughput applications.Concurrency and Computation: Practice and Experience, 2015
2015
-
[12]
Kresse and J
G. Kresse and J. Furthmüller. Efficient iterative schemes for ab initio total-energy calculations using a plane-wave basis set.Physical Review B, 1996
1996
-
[13]
Adam Lahouari, Jutta Rogal, and Mark E Tuckerman. Automated machine learning pipeline: Large language models-assisted automated data set generation for training machine-learned interatomic potentials.Journal of Chemical Theory and Computation, 2025. 10
2025
-
[14]
Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu, and Oriol Vinyals
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushm...
2022
-
[15]
V ASPilot: MCP-facilitated multi-agent intelligence for autonomous V ASP simulations.Chinese Physics B, 2025
Jiaxuan Liu, Tiannian Zhu, Caiyuan Ye, Zhong Fang, Hongming Weng, and Quansheng Wu. V ASPilot: MCP-facilitated multi-agent intelligence for autonomous V ASP simulations.Chinese Physics B, 2025
2025
-
[16]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. Augmenting large language models with chemistry tools.Nature machine intelli- gence, 2024
2024
-
[17]
Two-dimensional materials from high-throughput computational exfoliation of experimentally known compounds.Nature Nanotechnology, 2018
Nicolas Mounet, Marco Gibertini, Philippe Schwaller, Davide Campi, Andrius Merkys, Antimo Marrazzo, Thibault Sohier, Ivano Eligio Castelli, Andrea Cepellotti, Giovanni Pizzi, and Nicola Marzari. Two-dimensional materials from high-throughput computational exfoliation of experimentally known compounds.Nature Nanotechnology, 2018
2018
-
[18]
LLM-prop: predicting the properties of crystalline materials using large language models.npj Computational Materials, 2025
Andre Niyongabo Rubungo, Craig Arnold, Barry P Rand, and Adji Bousso Dieng. LLM-prop: predicting the properties of crystalline materials using large language models.npj Computational Materials, 2025
2025
-
[19]
Towards the computational design of solid catalysts.Nature Chemistry, 2009
Jens Kehlet Nørskov, Thomas Bligaard, Jan Rossmeisl, and Claus Hviid Christensen. Towards the computational design of solid catalysts.Nature Chemistry, 2009
2009
-
[20]
Update to GPT-5 System Card: GPT-5.2
OpenAI. Update to GPT-5 System Card: GPT-5.2. Technical report, OpenAI, Dec 2025
2025
-
[21]
AiiDA: automated interactive infrastructure and database for computational science.Computa- tional Materials Science, 2016
Giovanni Pizzi, Andrea Cepellotti, Riccardo Sabatini, Nicola Marzari, and Boris Kozinsky. AiiDA: automated interactive infrastructure and database for computational science.Computa- tional Materials Science, 2016
2016
-
[22]
Re- flexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[23]
Computational understanding of Li-ion batteries.npj Computational Materials, 2016
Alexander Urban, Dong-Hwa Seo, and Gerbrand Ceder. Computational understanding of Li-ion batteries.npj Computational Materials, 2016
2016
-
[24]
These are the most-cited research papers of all time.Nature, 2025
Richard Van Noorden. These are the most-cited research papers of all time.Nature, 2025
2025
-
[25]
V ASPKIT: A user-friendly interface facilitating high-throughput computing and analysis using V ASP code.Computer Physics Communications, 2021
Vei Wang, Nan Xu, Jin-Cheng Liu, Gang Tang, and Wen-Tong Geng. V ASPKIT: A user-friendly interface facilitating high-throughput computing and analysis using V ASP code.Computer Physics Communications, 2021
2021
-
[26]
Ziqi Wang, Hongshuo Huang, Hancheng Zhao, Changwen Xu, Shang Zhu, Jan Janssen, and Venkatasubramanian Viswanathan. DREAMS: Density functional theory based research engine for agentic materials simulation.arXiv preprint arXiv:2507.14267, 2025
-
[27]
AutoGen: Enabling next-gen LLM applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024
2024
-
[28]
ProteinMCP: An agentic ai framework for autonomous protein engineering.Protein Science, 2026
Xiaopeng Xu, Chenjie Feng, Chao Zha, Wenjia He, Maolin He, Bin Xiao, and Xin Gao. ProteinMCP: An agentic ai framework for autonomous protein engineering.Protein Science, 2026
2026
-
[29]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InProceedings of the International Conference on Learning Representations, 2023
2023
-
[30]
Autonomous Agents for Scientific Discovery: Orchestrating Scientists, Language, Code, and Physics
Lianhao Zhou, Hongyi Ling, Cong Fu, Yepeng Huang, Michael Sun, Wendi Yu, Xiaoxuan Wang, Xiner Li, Xingyu Su, Junkai Zhang, et al. Autonomous agents for scientific discovery: Orchestrating scientists, language, code, and physics.arXiv preprint arXiv:2510.09901, 2025. 11 Appendix Table of Contents A Notation and System Scope 13 A.1 Glossary of DFT, V ASP, a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
E F F I C I E N C Y : Each step must advance the c a l c u l a t i o n toward the goal . Do NOT include pure validation , verification , integrity - check , or c h e c k p o i n t steps that run a VASP c a l c u l a t i o n solely to confirm outputs are p a r s e a b l e . Sanity checks belong as s u c c e s s _ c r i t e r i a within c o m p u t a t i o ...
-
[32]
If a w or kf low re qui re s c a l c u l a t i o n s at m ul tip le s t r u c t u r e s ( e
SINGLE - S T R U C T U R E E X E C U T I O N : The e x e c u t i o n engine runs exactly ONE VASP c a l c u l a t i o n per step . If a w or kf low re qui re s c a l c u l a t i o n s at m ul tip le s t r u c t u r e s ( e . g . , EOS fitting with N volume points ) , each volume point must be its own step . When only the e q u i l i b r i u m volume is ne...
-
[33]
e s t a b l i s h a b ase li ne
NO R E D U N D A N T SINGLE - POINTS : Do not add a p r e l i m i n a r y single - point c a l c u l a t i o n before a r e l a x a t i o n just to " e s t a b l i s h a b ase li ne " -- the first ionic step of the r e l a x a t i o n already p ro vi des this i n f o r m a t i o n . COMPUTE BUDGET A W A R E N E S S : - Each VASP step has a hard wall - tim...
-
[34]
skip if not needed
C O N D I T I O N A L STEPS ARE USUALLY E XE CU TE D : the o r c h e s t r a t o r does not have a robust " skip if not needed " check for free - form ‘ condition ’ strings , so any step in cl ud ed in the plan should be e xp ect ed to a ct ua lly run . Prefer leaving o pt io nal r e f i n e m e n t steps out of the plan e nt ir el y and letting the r e f...
-
[35]
What is the e l e c t r o n i c s t r u c t u r e of this m at er ia l ? Metal , semiconductor , or i n s u l a t o r ?
-
[36]
ISMEAR =1 or 2 ( Methfessel - Paxton / Fermi ) is des ig ne d for metals
Check ISMEAR in the current INCAR . ISMEAR =1 or 2 ( Methfessel - Paxton / Fermi ) is des ig ne d for metals . Using it on a s e m i c o n d u c t o r or i n s u l a t o r can produce u n p h y s i c a l l y large entropy c o n t r i b u t i o n s and po sit iv e total en er gi es . If the mat er ia l is NOT a metal , ISMEAR should be 0 ( Ga uss ia n sm e...
-
[37]
Check for atomic ov er la ps : are any i n t e r a t o m i c d i s t a n c e s < 1.5 A ng str om ? If so , the geo me tr y itself is u n p h y s i c a l and must be fixed ( scale or perturb POSCAR ) before cha ng in g INCAR
-
[38]
incar " OR
Only after ruling out g eo me try issues and sm ear in g mi sm at ch should you adjust c o n v e r g e n c e p a r a m e t e r s ( ALGO , AMIX , NELM , etc .) . Prompt 9: Reasoning Recovery user prompt template. K n o w l e d g e base : { V A S P _ K N O W L E D G E _ B A S E } Re co ve ry context : { r e c o v e r y _ c o n t e x t as JSON -- c on ta ins...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.