Max-Window Scale Estimation for Near-Lossless HiF8 W8A8 Quantization-Aware Training
Pith reviewed 2026-06-29 23:00 UTC · model grok-4.3
The pith
A 64-step max-window for Delayed Tensor Scaling combined with BF16 warmup enables HiF8 W8A8 QAT with benchmark drops below 0.6 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
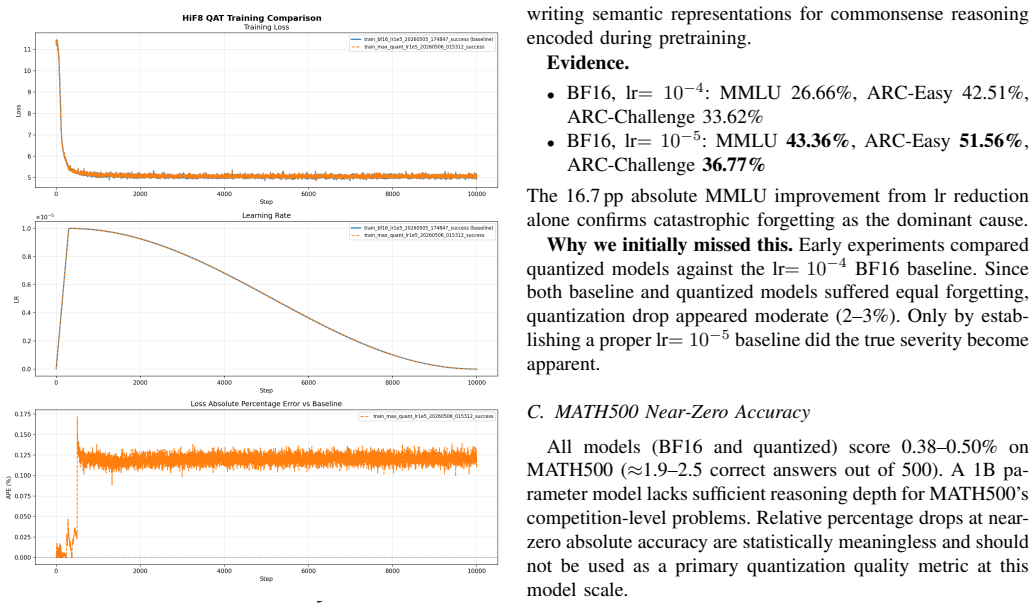
The authors establish through eight controlled experiments that amax saturation and catastrophic forgetting are orthogonal failure modes in HiF8 W8A8 QAT; amax saturation is corrected by a conservative max-algorithm DTS strategy over a 64-step history window, and forgetting is mitigated by a 500-step BF16 warmup followed by QAT at learning rate 10 to the minus 5, together yielding 0.43 percent MMLU drop, 0.58 percent HellaSwag drop, 0.22 percent ARC-Challenge drop, and 0.11 percent training loss APE over 10,000 steps versus a matched BF16 baseline.
What carries the argument
Delayed Tensor Scaling (DTS) with a conservative max-algorithm over a 64-step history window for scale estimation to prevent amax saturation.
If this is right
- Amax saturation and catastrophic forgetting act as independent failure modes that each require their own mitigation.
- Both the 64-step max-window DTS and the 500-step BF16 warmup are necessary to reach the reported benchmark performance.
- The final configuration keeps absolute percentage error in training loss to 0.11 percent across 10,000 steps.
- The approach limits accuracy drops to 0.43 percent on MMLU, 0.58 percent on HellaSwag, and 0.22 percent on ARC-Challenge relative to BF16.
Where Pith is reading between the lines
- The 64-step history window length may need adjustment when moving to models of different sizes or training regimes.
- The same scale-history strategy could be tested on other low-bit floating-point formats beyond HiF8.
- Repeating the controlled experiments on a different architecture would test whether the failure modes remain orthogonal.
Load-bearing premise
The eight controlled experiments on OpenPangu-Embedded-1B fully separate amax saturation from catastrophic forgetting without interference from model architecture, data, or other variables.
What would settle it
Retraining the same model with the 64-step max-window DTS and BF16 warmup but measuring an MMLU drop larger than 1 percent would falsify the near-lossless claim.
Figures

read the original abstract
Quantization-aware training (QAT) with low-bit floating-point formats enables efficient LLM deployment, yet introduces subtle failure modes invisible to standard training metrics. We present a systematic study of HiF8 W8A8 QAT for OpenPangu-Embedded-1B through the lens of Delayed Tensor Scaling (DTS). Across eight controlled experiments, we identify and disentangle two orthogonal failure modes: (i)amax saturation, where delayed scale estimates silently corrupt knowledge-sensitive representations via forward-pass clipping, and (ii)catastrophic forgetting, where an aggressive learning rate overwrites pretrained commonsense knowledge independently of quantization. Neither is detectable from training loss alone. We address amax saturation with a conservative max-algorithm DTS strategy over a 64-step history window, and mitigate forgetting via a 500-step BF16 warmup followed by QAT at lr=10^{-5}. Both fixes are necessary and sufficient: our final configuration achieves 0.43% MMLU drop, 0.58% HellaSwag drop, and 0.22% ARC-Challenge drop versus a matched BF16 baseline, with a training loss APE of only 0.11% over 10,000 steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a study of HiF8 W8A8 quantization-aware training (QAT) on OpenPangu-Embedded-1B using Delayed Tensor Scaling (DTS). It identifies two failure modes—amax saturation via forward-pass clipping and catastrophic forgetting from aggressive learning rates—neither visible in training loss. The authors propose a conservative 64-step max-window DTS strategy and a 500-step BF16 warmup followed by QAT at lr=1e-5. Across eight controlled experiments, they claim these fixes are necessary and jointly sufficient, yielding 0.43% MMLU, 0.58% HellaSwag, and 0.22% ARC-Challenge drops versus a matched BF16 baseline with 0.11% training loss APE over 10k steps.
Significance. If the results hold, the work supplies concrete, reproducible hyperparameters for mitigating subtle QAT failure modes in low-bit floating-point formats. The emphasis on controlled experiments that separate effects not captured by loss is a strength, as is the explicit reporting of the 64-step window, 500-step warmup, and 1e-5 learning rate.
major comments (2)
- [Abstract] Abstract: the reported benchmark drops (0.43% MMLU, 0.58% HellaSwag, 0.22% ARC-Challenge) are presented without error bars, run-to-run variance, or statistical significance tests. This undermines the central claim that the configuration is 'near-lossless,' because the small deltas cannot be evaluated against baseline variability.
- [Across eight controlled experiments] Across eight controlled experiments: the claim that amax saturation and catastrophic forgetting are orthogonal, and that the two fixes are each necessary and jointly sufficient, depends on the experiments cleanly isolating the effects. With all runs performed on a single 1B model and no reported interaction analysis or design matrix, confounding (e.g., warmup altering activations that feed the 64-step max-window) cannot be ruled out.
minor comments (2)
- [Abstract] The acronym APE is used without expansion on first appearance.
- A table summarizing the eight experiments, their factor combinations, and per-condition benchmark deltas would improve clarity of the 2x2 or 2x4 design.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported benchmark drops (0.43% MMLU, 0.58% HellaSwag, 0.22% ARC-Challenge) are presented without error bars, run-to-run variance, or statistical significance tests. This undermines the central claim that the configuration is 'near-lossless,' because the small deltas cannot be evaluated against baseline variability.
Authors: We agree that the absence of error bars or variance estimates limits the strength of the 'near-lossless' claim for such small deltas. Our experiments used single runs per configuration owing to the substantial compute required for 10k-step QAT on the 1B model. In revision we will update the abstract and results to explicitly note that the deltas are from single runs, qualify the 'near-lossless' phrasing, and highlight the consistency observed across the eight controlled experiments as supporting evidence. revision: yes
-
Referee: [Across eight controlled experiments] Across eight controlled experiments: the claim that amax saturation and catastrophic forgetting are orthogonal, and that the two fixes are each necessary and jointly sufficient, depends on the experiments cleanly isolating the effects. With all runs performed on a single 1B model and no reported interaction analysis or design matrix, confounding (e.g., warmup altering activations that feed the 64-step max-window) cannot be ruled out.
Authors: The eight experiments were constructed as targeted ablations that vary one factor at a time while holding others fixed, which is how we established necessity and joint sufficiency. We acknowledge that a full factorial design with explicit interaction terms on multiple models would more rigorously exclude confounding. In revision we will add a limitations paragraph discussing the single-model scope and the possibility of unexamined interactions. revision: partial
- Providing run-to-run variance or statistical significance tests would require additional independent training runs that are not feasible within current compute resources.
Circularity Check
Empirical study with no derivation chain or self-referential predictions
full rationale
This is a purely experimental paper reporting benchmark outcomes from eight controlled runs on OpenPangu-Embedded-1B. The abstract and provided text contain no equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations. Claims about orthogonality of failure modes and sufficiency of fixes are grounded in the observed deltas from the experiments themselves, which are external benchmarks rather than reductions to the paper's own inputs. No circular steps exist.
Axiom & Free-Parameter Ledger
free parameters (3)
- 64-step history window
- 500-step BF16 warmup
- QAT learning rate 1e-5
axioms (1)
- domain assumption The two failure modes (amax saturation and catastrophic forgetting) are orthogonal and can be addressed independently.
Reference graph
Works this paper leans on
-
[1]
HiFloat8: A New 8-bit Floating Point Format for Deep Learning,
[HiFloat8 team], “HiFloat8: A New 8-bit Floating Point Format for Deep Learning,” 2025
2025
-
[2]
OpenPangu-Embedded-1B,
[OpenPangu team], “OpenPangu-Embedded-1B,” 2025
2025
-
[3]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale,
H. Penedo et al., “The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale,” 2024
2024
-
[4]
LLM.int8(): 8- bit Matrix Multiplication for Transformers at Scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “LLM.int8(): 8- bit Matrix Multiplication for Transformers at Scale,” inProc. NeurIPS, 2022
2022
-
[5]
GPTQ: Accurate Post-Training Quantization for Generative Pretrained Transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate Post-Training Quantization for Generative Pretrained Transformers,” in Proc. ICLR, 2023
2023
-
[6]
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models,” inProc. ICML, 2023
2023
-
[7]
AWQ: Activation-aware Weight Quantization for LLM Compression and Ac- celeration,
J. Lin, J. Tang, H. Tang, S. Yang, X. Dang, and S. Han, “AWQ: Activation-aware Weight Quantization for LLM Compression and Ac- celeration,” inProc. MLSys, 2024
2024
-
[8]
P. Micikevicius et al., “FP8 Formats for Deep Learning,”arXiv preprint arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
FP8-LM: Training FP8 Large Language Models,
H. Peng, K. Wu, Y . Wei et al., “FP8-LM: Training FP8 Large Language Models,”arXiv preprint arXiv:2310.18313, 2023
-
[10]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation,” arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[11]
Examining Forgetting in Continual Pre-training of Aligned Large Language Models,
C.-A. Li and H.-Y . Chen, “Examining Forgetting in Continual Pre-training of Aligned Large Language Models,”arXiv preprint arXiv:2401.03129, 2024
-
[12]
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Y . Luo, Z. Yang, F. Meng, Y . Li, J. Zhou, and Y . Zhang, “An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning,”arXiv preprint arXiv:2308.08747, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal,
J. Huang et al., “Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal,” inProc. ACL, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.