Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
Pith reviewed 2026-06-29 23:06 UTC · model grok-4.3
The pith
GARD restores accurate 3D scene geometry by applying diffusion denoising directly inside the feature space of a feed-forward reconstructor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
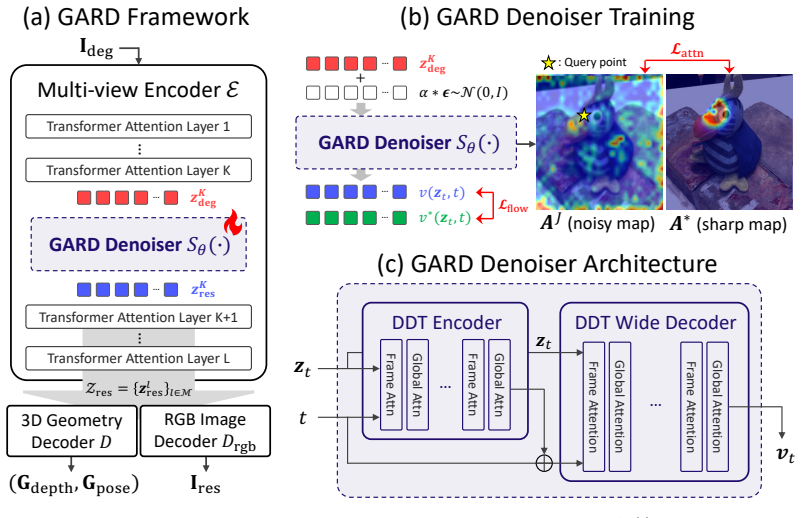
GARD performs diffusion-based multi-view restoration directly in the feature space of a feed-forward 3D reconstruction model. This design exploits the geometry-aware feature representations of the 3D reconstructor to effectively recover accurate scene geometry. An additional RGB image decoder enables simultaneous recovery of high-quality imagery from the refined representations.
What carries the argument
Diffusion process operating on geometry-aware features extracted by the base 3D reconstructor, which guides restoration without explicit degradation modeling.
If this is right
- Degraded multi-view inputs can yield accurate scene geometry after feature-space diffusion.
- The same refined features can produce restored high-quality RGB images via a decoder.
- No separate degradation model is required for the restoration step.
- The method improves robustness on benchmarks containing real-world image degradations such as DA3.
Where Pith is reading between the lines
- The same feature-space strategy might transfer to other feed-forward 3D models that produce geometry-aware representations.
- Operating in feature space could prove more efficient than pixel-space diffusion for tasks where geometry is the primary output.
- Downstream applications such as robotics or augmented reality that rely on multi-view reconstruction would gain practical robustness.
Load-bearing premise
The geometry-aware features already produced by the base 3D reconstruction model contain enough information to steer diffusion-based recovery of scene geometry under arbitrary real-world degradations.
What would settle it
Running the base 3D reconstructor with and without GARD on the same set of degraded multi-view images and finding no measurable improvement in reconstruction accuracy metrics would falsify the central claim.
Figures

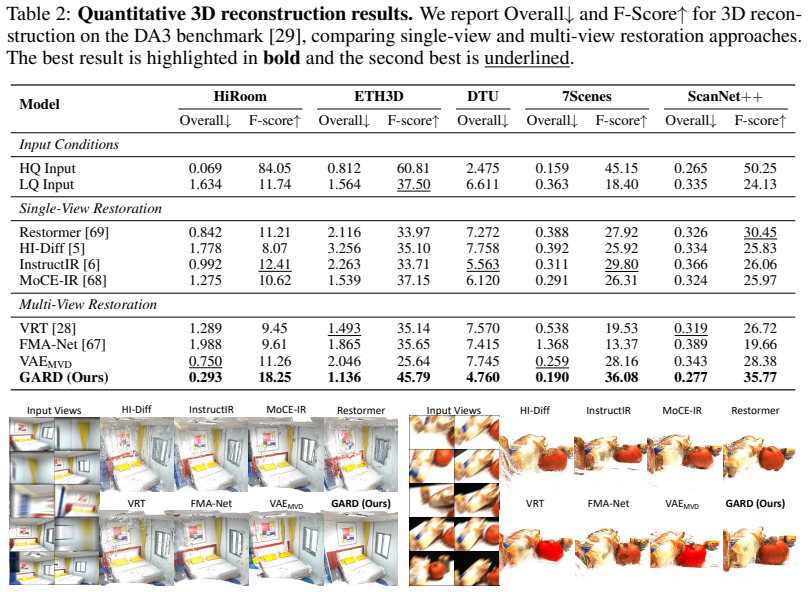
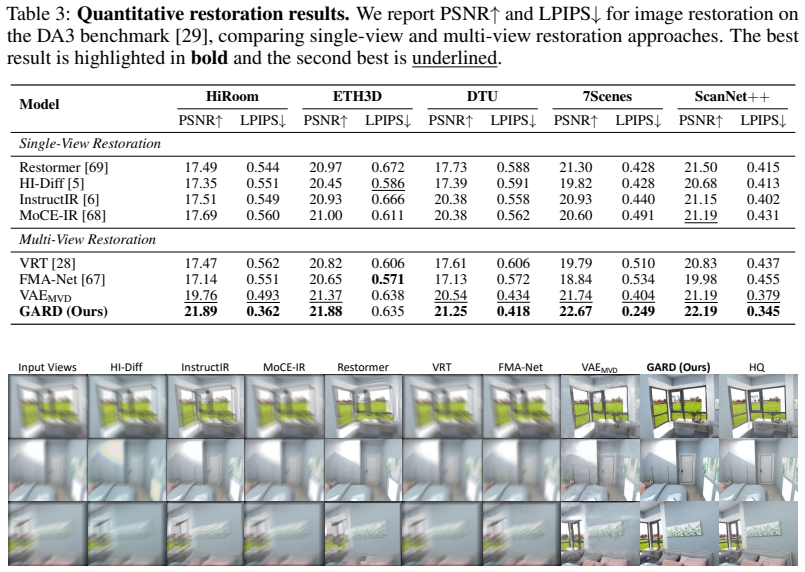





read the original abstract
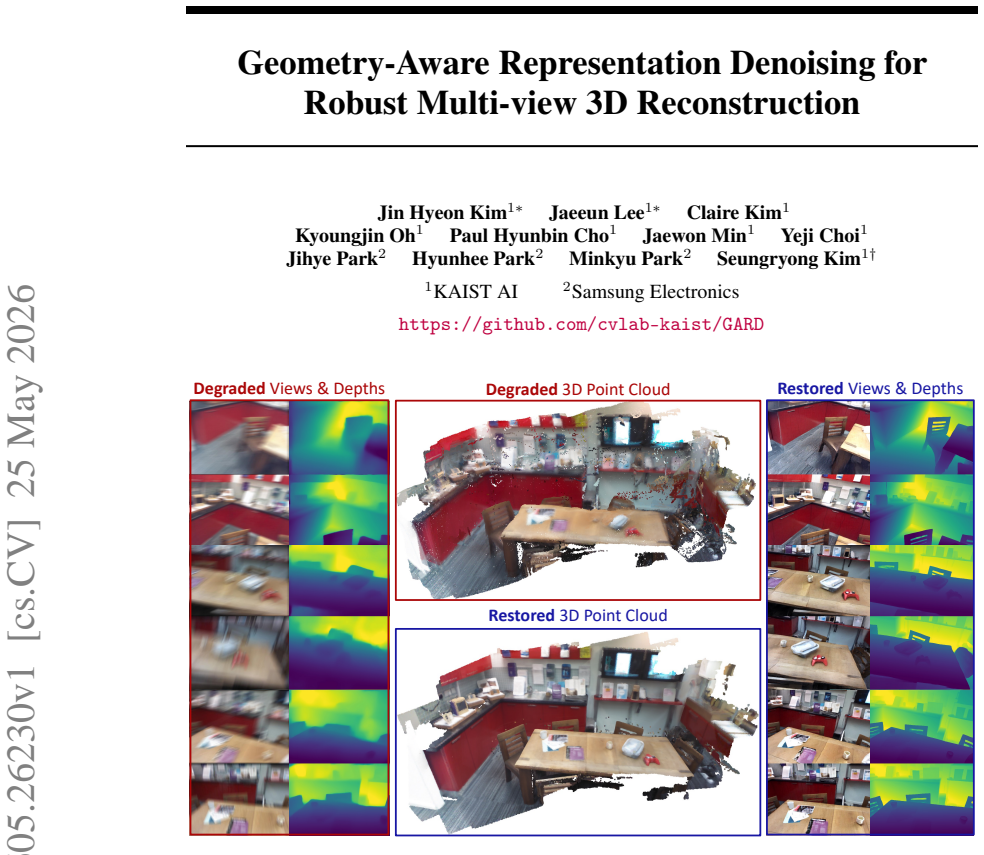
Multi-view 3D reconstruction has achieved remarkable progress with the advent of feed-forward 3D reconstruction models. However, these models are typically trained and evaluated under ideal, degradation-free imaging conditions, whereas real-world observations often contain degradations that differ significantly from such settings. Improving robustness for multi-view 3D reconstruction under degraded conditions therefore remains an important challenge. We present Geometry-Aware Representation Denoising (GARD), a novel framework that performs diffusion-based multi-view restoration directly in the feature space of a feed-forward 3D reconstruction model. This design exploits the geometry-aware feature representations of the 3D reconstructor to effectively recover accurate scene geometry. Furthermore, by employing an additional RGB image decoder, the refined representations can also be used to restore high-quality RGB images, thereby enabling the simultaneous recovery of 3D scene geometry and high-quality imagery. Comprehensive experiments on the Depth Anything 3 (DA3) benchmark demonstrate the effectiveness of the proposed GARD framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Geometry-Aware Representation Denoising (GARD), a framework that applies diffusion-based multi-view restoration directly in the feature space of a feed-forward 3D reconstruction model. It claims this exploits geometry-aware features to recover accurate scene geometry under real-world degradations, and that an additional RGB decoder enables simultaneous high-quality image restoration. The abstract states that comprehensive experiments on the Depth Anything 3 (DA3) benchmark demonstrate the framework's effectiveness.
Significance. If the central claim holds and is supported by rigorous quantitative evidence, the approach could offer a practical route to robust multi-view 3D reconstruction by avoiding explicit degradation modeling. The design choice to operate in the reconstructor's feature space is conceptually interesting and could generalize to other feed-forward models, but the current manuscript provides no data to evaluate whether the claimed gains materialize.
major comments (2)
- [Abstract] Abstract: the claim that 'comprehensive experiments on the DA3 benchmark demonstrate the effectiveness' is unsupported because the abstract (and visible manuscript) supplies no quantitative results, baselines, ablation studies, or error analysis. This absence makes the central claim unevaluable from the provided text.
- [Abstract / Method] Method description (implicit in abstract): the design assumes the base feed-forward 3D model's feature extractor, trained only on clean data, still yields usable geometry-aware representations on arbitrarily degraded inputs. No robustness training, explicit degradation model, or analysis of feature collapse under degradation is described, leaving the precondition for the diffusion process unsupported.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our manuscript. We address each major comment below and note the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'comprehensive experiments on the DA3 benchmark demonstrate the effectiveness' is unsupported because the abstract (and visible manuscript) supplies no quantitative results, baselines, ablation studies, or error analysis. This absence makes the central claim unevaluable from the provided text.
Authors: We agree that the abstract would benefit from explicit quantitative support to make the effectiveness claim directly evaluable. In the revised manuscript we will update the abstract to include representative metrics, such as PSNR/SSIM gains for image restoration and Chamfer distance or depth error reductions for 3D reconstruction relative to the base feed-forward model and other baselines on the DA3 benchmark. revision: yes
-
Referee: [Abstract / Method] Method description (implicit in abstract): the design assumes the base feed-forward 3D model's feature extractor, trained only on clean data, still yields usable geometry-aware representations on arbitrarily degraded inputs. No robustness training, explicit degradation model, or analysis of feature collapse under degradation is described, leaving the precondition for the diffusion process unsupported.
Authors: The diffusion model is trained end-to-end on feature pairs extracted by the frozen base model from clean versus synthetically degraded multi-view inputs; the denoising objective therefore learns to recover geometry-aware features directly from degraded observations without requiring the base extractor to be retrained or an explicit degradation model to be specified. We acknowledge that an analysis of feature degradation (e.g., cosine similarity or reconstruction error before/after diffusion across degradation types) is currently absent and would strengthen the manuscript. We will add this analysis, including visualizations of feature collapse, in the revision. revision: partial
Circularity Check
No circularity; method description introduces independent framework without self-referential reductions
full rationale
The provided abstract and context describe GARD as a novel framework that applies diffusion-based restoration directly in the feature space of an existing feed-forward 3D reconstruction model, exploiting its geometry-aware representations. No equations, parameter fittings, derivations, or self-citations are shown that would reduce any prediction or claim to its own inputs by construction. The design choice is presented as an exploitation of pre-existing model properties rather than a self-definitional loop, fitted-input prediction, or ansatz smuggled via citation. The central claim remains an architectural proposal whose validity depends on external empirical validation rather than internal reduction to the inputs themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feed-forward 3D reconstruction models produce geometry-aware feature representations that can be effectively denoised via diffusion to recover scene geometry.
Reference graph
Works this paper leans on
-
[1]
Large-scale data for multiple-view stereopsis.International Journal of Computer Vision, 120(2):153–168, 2016
Henrik Aanæs, Rasmus Ramsbøl Jensen, George V ogiatzis, Engin Tola, and Anders Bjorholm Dahl. Large-scale data for multiple-view stereopsis.International Journal of Computer Vision, 120(2):153–168, 2016
2016
-
[2]
Cross-view completion models are zero-shot correspondence estimators
Honggyu An, Jinhyeon Kim, Seonghoon Park, Jaewoo Jung, Jisang Han, Sunghwan Hong, and Seungryong Kim. Cross-view completion models are zero-shot correspondence estimators. arXiv preprint arXiv:2412.09072, 2024
-
[3]
Rgb cameras failures and their effects in autonomous driving applications.IEEE Transactions on Dependable and Secure Computing, 20(4):2731– 2745, 2022
Andrea Ceccarelli and Francesco Secci. Rgb cameras failures and their effects in autonomous driving applications.IEEE Transactions on Dependable and Secure Computing, 20(4):2731– 2745, 2022
2022
-
[4]
Lovif 2026 challenge on real-world all-in-one image restoration: Methods and results, 2026
Xiang Chen, Hao Li, Jiangxin Dong, Jinshan Pan, Xin Li, Xin He, Naiwei Chen, Shengyuan Li, Fengning Liu, Haoyi Lv, Haowei Peng, Yilian Zhong, Yuxiang Chen, Shibo Yin, Yushun Fang, Xilei Zhu, Yahui Wang, Chen Lu, Kaibin Chen, Xu Zhang, Xuhui Cao, Jiaqi Ma, Ziqi Wang, Shengkai Hu, Yuning Cui, Huan Zhang, Shi Chen, Bin Ren, Lefei Zhang, Guanglu Dong, Qiyao Z...
2026
-
[5]
Hierar- chical integration diffusion model for realistic image deblurring
Zheng Chen, Yulun Zhang, Liu Ding, Xia Bin, Jinjin Gu, Linghe Kong, and Xin Yuan. Hierar- chical integration diffusion model for realistic image deblurring. InNeurIPS, 2023
2023
-
[6]
Instructir: High-quality image restoration following human instructions
Marcos V Conde, Gregor Geigle, and Radu Timofte. Instructir: High-quality image restoration following human instructions. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[7]
maplab 2.0–a modular and multi-modal mapping framework.IEEE Robotics and Automation Letters, 8(2):520–527, 2022
Andrei Cramariuc, Lukas Bernreiter, Florian Tschopp, Marius Fehr, Victor Reijgwart, Juan Nieto, Roland Siegwart, and Cesar Cadena. maplab 2.0–a modular and multi-modal mapping framework.IEEE Robotics and Automation Letters, 8(2):520–527, 2022
2022
-
[8]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018
2018
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Dit4sr: Taming diffusion transformer for real-world image super-resolution
Zheng-Peng Duan, Jiawei Zhang, Xin Jin, Ziheng Zhang, Zheng Xiong, Dongqing Zou, Jimmy Ren, Chun-Le Guo, and Chongyi Li. Dit4sr: Taming diffusion transformer for real-world image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[11]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[12]
Towards internet-scale multi-view stereo
Yasutaka Furukawa, Brian Curless, Steven M Seitz, and Richard Szeliski. Towards internet-scale multi-view stereo. In2010 IEEE computer society conference on computer vision and pattern recognition, pages 1434–1441. IEEE, 2010
2010
-
[13]
Yasutaka Furukawa and Carlos Hernández.Multi-View Stereo: A Tutorial. 01 2015
2015
-
[14]
Jisang Han, Sunghwan Hong, Jaewoo Jung, Wooseok Jang, Honggyu An, Qianqian Wang, Seungryong Kim, and Chen Feng. Emergent outlier view rejection in visual geometry grounded transformers.arXiv preprint arXiv:2512.04012, 2025. 12
-
[15]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geometry in computer vision. Cambridge university press, 2003
2003
-
[16]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[17]
Wooseok Jang, Seonghu Jeon, Jisang Han, Jinhyeok Choi, Minkyung Kwon, Seungryong Kim, Saining Xie, and Sainan Liu. Repurposing geometric foundation models for multi-view diffusion.arXiv preprint arXiv:2603.22275, 2026
-
[18]
A survey on all-in-one image restoration: Taxonomy, evaluation and future trends.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(12):11892–11911, December 2025
Junjun Jiang, Zengyuan Zuo, Gang Wu, Kui Jiang, and Xianming Liu. A survey on all-in-one image restoration: Taxonomy, evaluation and future trends.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(12):11892–11911, December 2025
2025
-
[19]
Matrix: Mask track alignment for interaction-aware video generation, 2025
Siyoon Jin, Seongchan Kim, Dahyun Chung, Jaeho Lee, Hyunwook Choi, Jisu Nam, Jiy- oung Kim, and Seungryong Kim. Matrix: Mask track alignment for interaction-aware video generation, 2025
2025
-
[20]
Maciej Kilian, Varun Jampani, and Luke Zettlemoyer. Computational tradeoffs in image syn- thesis: Diffusion, masked-token, and next-token prediction.arXiv preprint arXiv:2405.13218, 2024
-
[21]
Unified diffusion transformer for high-fidelity text-aware image restoration, 2025
Jin Hyeon Kim, Paul Hyunbin Cho, Claire Kim, Jaewon Min, Jaeeun Lee, Jihye Park, Yeji Choi, and Seungryong Kim. Unified diffusion transformer for high-fidelity text-aware image restoration, 2025
2025
-
[22]
Real-time image de-blurring and image processing for a robotic vision system
Michael D Kim and Jun Ueda. Real-time image de-blurring and image processing for a robotic vision system. In2015 IEEE International Conference on Robotics and Automation (ICRA), pages 1899–1904. IEEE, 2015
1904
-
[23]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[24]
Amandeep Kumar and Vishal M Patel. Learning on the manifold: Unlocking standard diffusion transformers with representation encoders.arXiv preprint arXiv:2602.10099, 2026
-
[25]
Minkyung Kwon, Jinhyeok Choi, Jiho Park, Seonghu Jeon, Jinhyuk Jang, Junyoung Seo, Min- Seop Kwak, Jin-Hwa Kim, and Seungryong Kim. Cameo: Correspondence-attention alignment for multi-view diffusion models.arXiv preprint arXiv:2512.03045, 2025
-
[26]
Gyuseong Lee, Wooseok Jang, Jin Hyeon Kim, Jaewoo Jung, and Seungryong Kim. Do- main generalization using large pretrained models with mixture-of-adapters.arXiv preprint arXiv:2310.11031, 2023
-
[27]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[28]
Vrt: A video restoration transformer.IEEE Transactions on Image Processing, 33:2171–2182, 2024
Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, and Luc Van Gool. Vrt: A video restoration transformer.IEEE Transactions on Image Processing, 33:2171–2182, 2024
2024
-
[29]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Diffbir: Towards blind image restoration with generative diffusion prior, 2024
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Wanli Ouyang, Yu Qiao, and Chao Dong. Diffbir: Towards blind image restoration with generative diffusion prior, 2024
2024
-
[31]
Boosting visual recognition in real-world degradations via unsupervised feature enhancement module with deep channel prior.IEEE Transactions on Intelligent Vehicles, 2024
Zhanwen Liu, Yuhang Li, Yang Wang, Bolin Gao, Yisheng An, and Xiangmo Zhao. Boosting visual recognition in real-world degradations via unsupervised feature enhancement module with deep channel prior.IEEE Transactions on Intelligent Vehicles, 2024. 13
2024
-
[32]
Depth estimation from monocular images and sparse radar using deep ordinal regression network
Chen-Chou Lo and Patrick Vandewalle. Depth estimation from monocular images and sparse radar using deep ordinal regression network. In2021 IEEE International Conference on Image Processing (ICIP), pages 3343–3347, 2021
2021
-
[33]
Alexandra Malyugina, Yini Li, Joanne Lin, and Nantheera Anantrasirichai. Unsupervised methods for video quality improvement: a survey of restoration and enhancement techniques. arXiv preprint arXiv:2507.08375, 2025
-
[34]
Sir-diff: Sparse image sets restoration with multi-view diffusion model
Yucheng Mao, Boyang Wang, Nilesh Kulkarni, and Jeong Joon Park. Sir-diff: Sparse image sets restoration with multi-view diffusion model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21620–21630, 2025
2025
-
[35]
Text-aware image restoration with diffusion models
Jaewon Min, Jin Hyeon Kim, Paul Hyunbin Cho, Jaeeun Lee, Jihye Park, Minkyu Park, Sangpil Kim, Hyunhee Park, and Seungryong Kim. Text-aware image restoration with diffusion models. arXiv preprint arXiv:2506.09993, 2025
-
[36]
Deep multi-scale convolutional neural network for dynamic scene deblurring
Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3883–3891, 2017
2017
-
[37]
Deep multi-scale convolutional neural network for dynamic scene deblurring, 2018
Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring, 2018
2018
-
[38]
Emergent temporal correspondences from video diffusion transformers, 2025
Jisu Nam, Soowon Son, Dahyun Chung, Jiyoung Kim, Siyoon Jin, Junhwa Hur, and Seungryong Kim. Emergent temporal correspondences from video diffusion transformers, 2025
2025
-
[39]
Augmented reality based on estimation of defocusing and motion blurring from captured images
Bunyo Okumura, Masayuki Kanbara, and Naokazu Yokoya. Augmented reality based on estimation of defocusing and motion blurring from captured images. In2006 IEEE/ACM International Symposium on Mixed and Augmented Reality, pages 219–225. IEEE, 2006
2006
-
[40]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Visual geometry transformer in the wild: Distractor-free 3d reconstruction
Tianbo Pan, Xingyi Yang, Shizun Wang, and Xinchao Wang. Visual geometry transformer in the wild: Distractor-free 3d reconstruction
-
[42]
Handling motion-blur in 3d tracking and rendering for augmented reality.IEEE transactions on visualization and computer graphics, 18(9):1449–1459, 2011
Youngmin Park, Vincent Lepetit, and Woontack Woo. Handling motion-blur in 3d tracking and rendering for augmented reality.IEEE transactions on visualization and computer graphics, 18(9):1449–1459, 2011
2011
-
[43]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[44]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[45]
Real-world blur dataset for learning and benchmarking deblurring algorithms
Jaesung Rim, Haeyun Lee, Jucheol Won, and Sunghyun Cho. Real-world blur dataset for learning and benchmarking deblurring algorithms. InEuropean conference on computer vision, pages 184–201. Springer, 2020
2020
-
[46]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021
2021
-
[47]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[48]
Kimera: an open-source library for real-time metric-semantic localization and mapping
Antoni Rosinol, Marcus Abate, Yun Chang, and Luca Carlone. Kimera: an open-source library for real-time metric-semantic localization and mapping. In2020 IEEE international conference on robotics and automation (ICRA), pages 1689–1696. IEEE, 2020. 14
2020
-
[49]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[50]
Schonberger and Jan-Michael Frahm
Johannes L. Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
2016
-
[51]
A multi-view stereo benchmark with high-resolution images and multi-camera videos
Thomas Schops, Johannes L Schonberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3260–3269, 2017
2017
-
[52]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8922–8931, June 2021
2021
-
[53]
Masked depth modeling for spatial perception.arXiv preprint arXiv:[2601.17895], 2026
Bin Tan, Changjiang Sun, Xiage Qin, Hanat Adai, Zelin Fu, Tianxiang Zhou, Han Zhang, Yinghao Xu, Xing Zhu, Yujun Shen, and Nan Xue. Masked depth modeling for spatial perception.arXiv preprint arXiv:[2601.17895], 2026
-
[54]
A fast local descriptor for dense matching
Engin Tola, Vincent Lepetit, and Pascal Fua. A fast local descriptor for dense matching. In 2008 IEEE Conference on Computer Vision and Pattern Recognition, pages 1–8, 2008
2008
-
[55]
Shengbang Tong, Boyang Zheng, Ziteng Wang, Bingda Tang, Nanye Ma, Ellis Brown, Jihan Yang, Rob Fergus, Yann LeCun, and Saining Xie. Scaling text-to-image diffusion transformers with representation autoencoders.arXiv preprint arXiv:2601.16208, 2026
-
[56]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
An overview of autonomous vehicles sensors and their vulnerability to weather conditions.Sensors, 21(16):5397, 2021
Jorge Vargas, Suleiman Alsweiss, Onur Toker, Rahul Razdan, and Joshua Santos. An overview of autonomous vehicles sensors and their vulnerability to weather conditions.Sensors, 21(16):5397, 2021
2021
-
[58]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[59]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[60]
Ddt: Decoupled diffusion transformer
Shuai Wang, Zhi Tian, Weilin Huang, and Limin Wang. Ddt: Decoupled diffusion transformer. arXiv preprint arXiv:2504.05741, 2025
-
[61]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[62]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916. IEEE, 2020
2020
-
[63]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-Equivariant Visual Geometry Learning.arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Interactive real-time motion blur.The Visual Computer, 12(6):283–295, 1996
Matthias M Wloka and Robert C Zeleznik. Interactive real-time motion blur.The Visual Computer, 12(6):283–295, 1996. 15
1996
-
[65]
Reconstruction vs
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming optimiza- tion dilemma in latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15703–15712, 2025
2025
-
[66]
Scannet++: A high- fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high- fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
2023
-
[67]
Fma-net: Flow-guided dynamic filtering and iterative feature refinement with multi-attention for joint video super-resolution and deblurring
Geunhyuk Youk, Jihyong Oh, and Munchurl Kim. Fma-net: Flow-guided dynamic filtering and iterative feature refinement with multi-attention for joint video super-resolution and deblurring. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 44–55, June 2024
2024
-
[68]
Complexity experts are task-discriminative learners for any image restoration, 2024
Eduard Zamfir, Zongwei Wu, Nancy Mehta, Yuedong Tan, Danda Pani Paudel, Yulun Zhang, and Radu Timofte. Complexity experts are task-discriminative learners for any image restoration, 2024
2024
-
[69]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5728–5739, 2022
2022
-
[70]
Ffdnet: Toward a fast and flexible solution for CNN based image denoising.IEEE Transactions on Image Processing, 2018
Kai Zhang, Wangmeng Zuo, and Lei Zhang. Ffdnet: Toward a fast and flexible solution for CNN based image denoising.IEEE Transactions on Image Processing, 2018
2018
-
[71]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness.arXiv preprint arXiv:2409.18125, 2024
-
[73]
Springer International Publishing, Cham, 2018
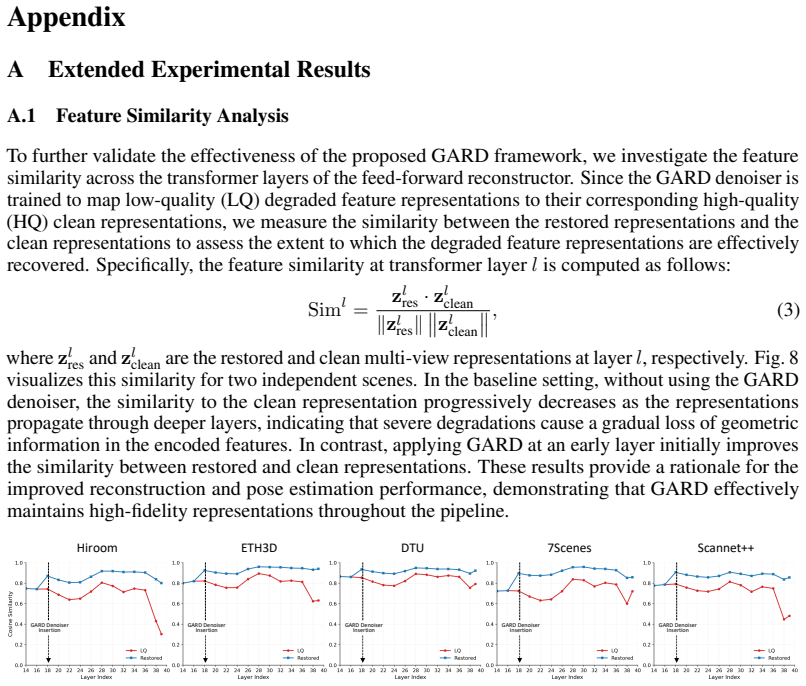
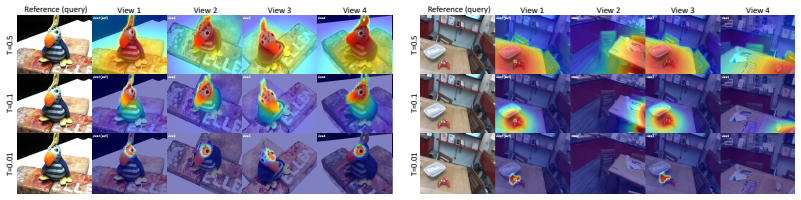
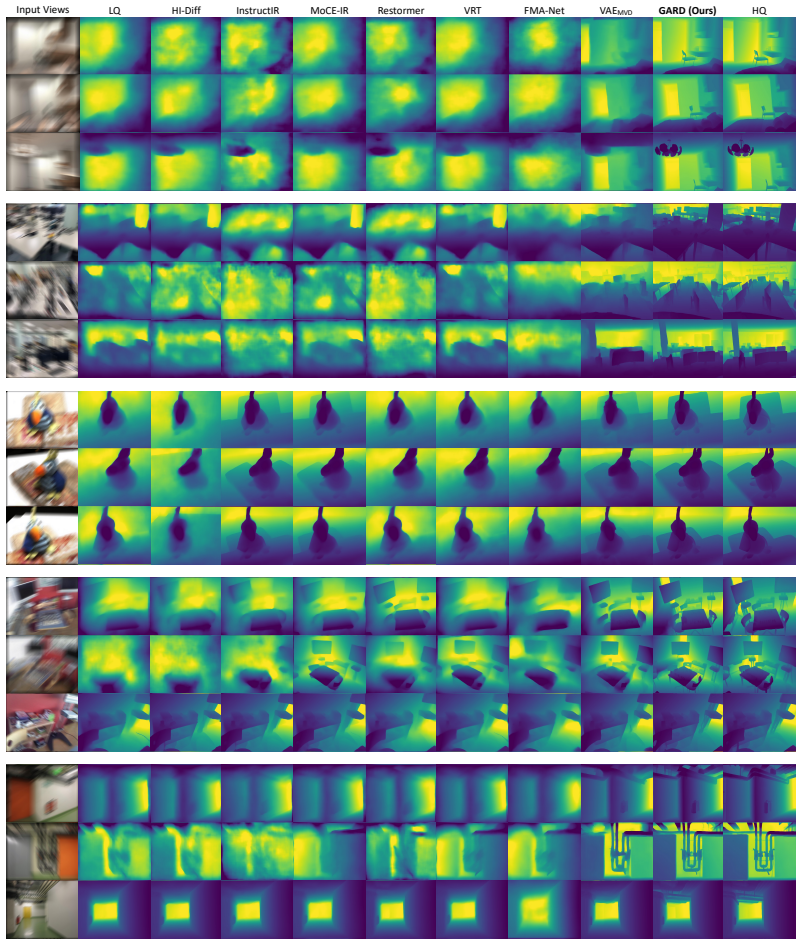
Wangmeng Zuo, Kai Zhang, and Lei Zhang.Convolutional Neural Networks for Image Denoising and Restoration, pages 93–123. Springer International Publishing, Cham, 2018. 16 Appendix A Extended Experimental Results A.1 Feature Similarity Analysis To further validate the effectiveness of the proposed GARD framework, we investigate the feature similarity across...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.