Unified Neural Scaling Laws
Pith reviewed 2026-06-29 22:54 UTC · model grok-4.3
The pith
A single functional form accurately models and extrapolates neural network scaling as model parameters, data size, training steps, inference steps, compute and hyperparameters all vary together.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
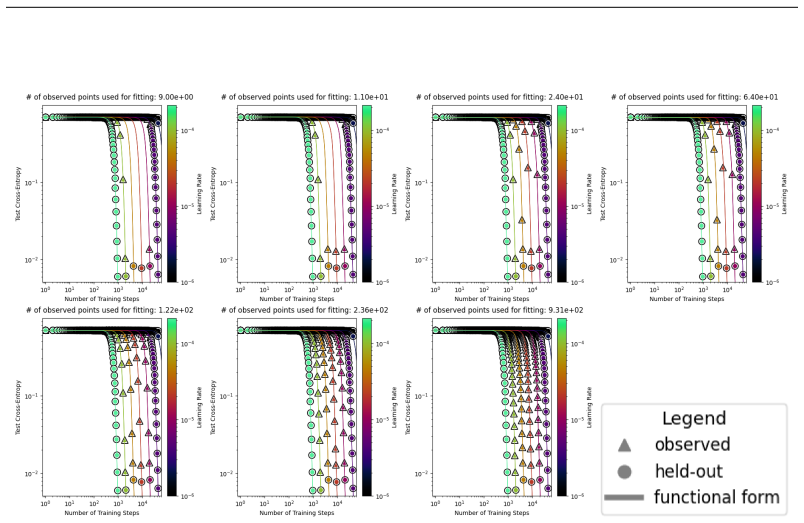
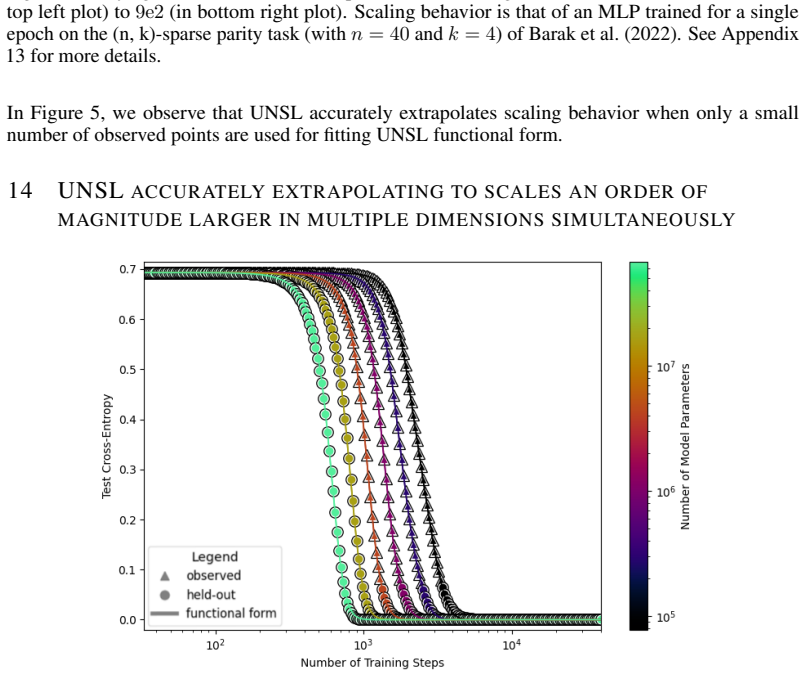
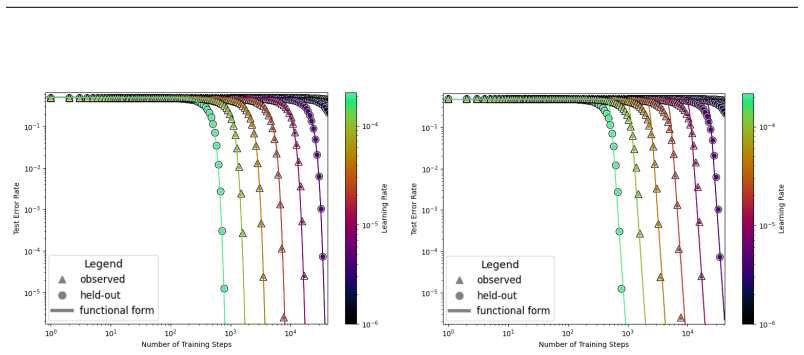
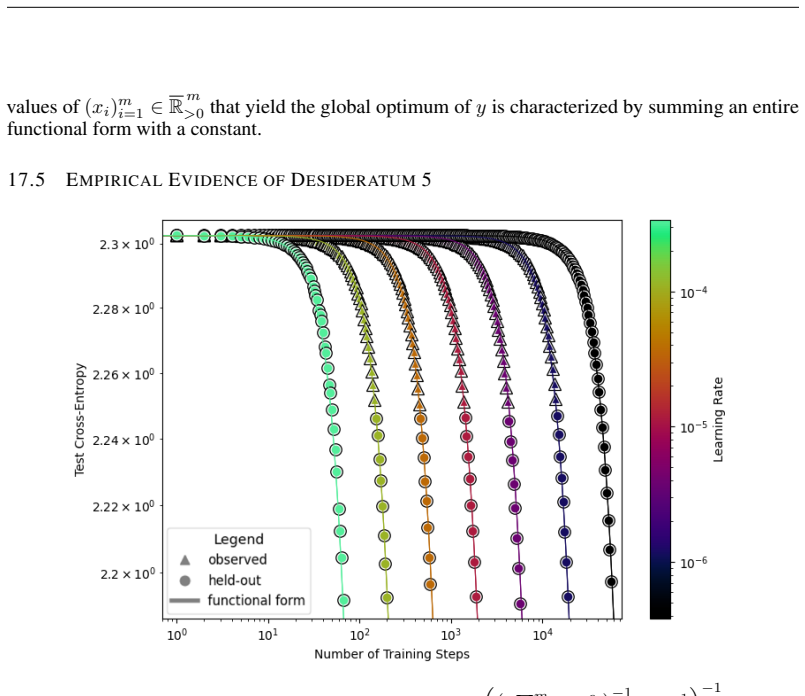
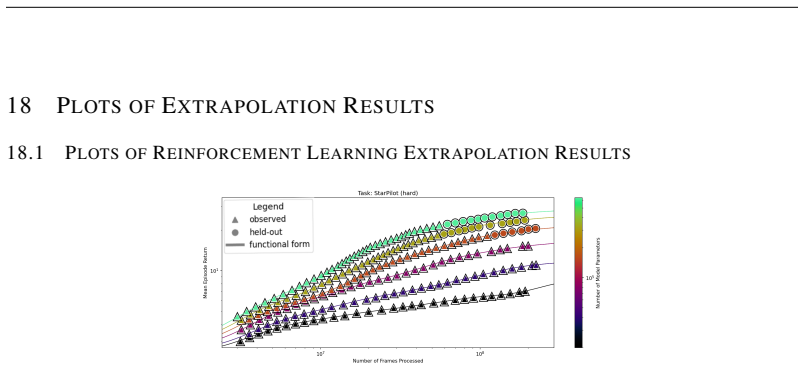
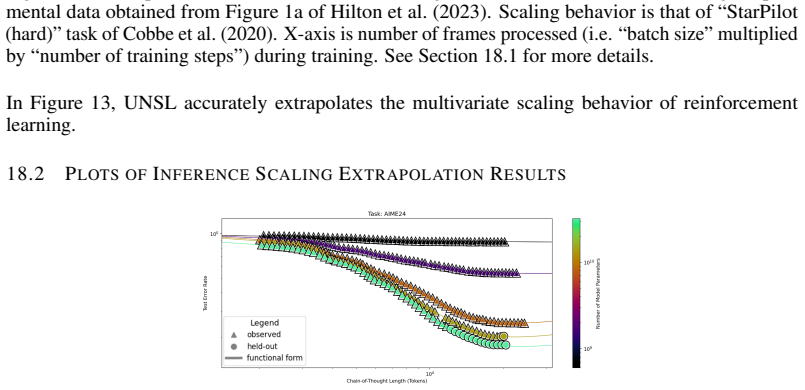
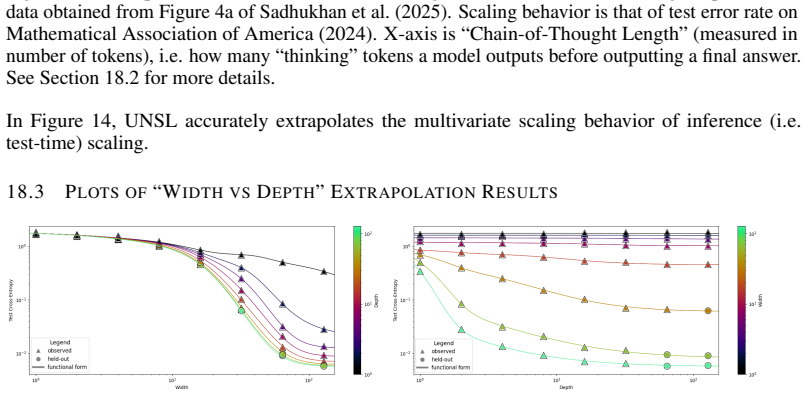
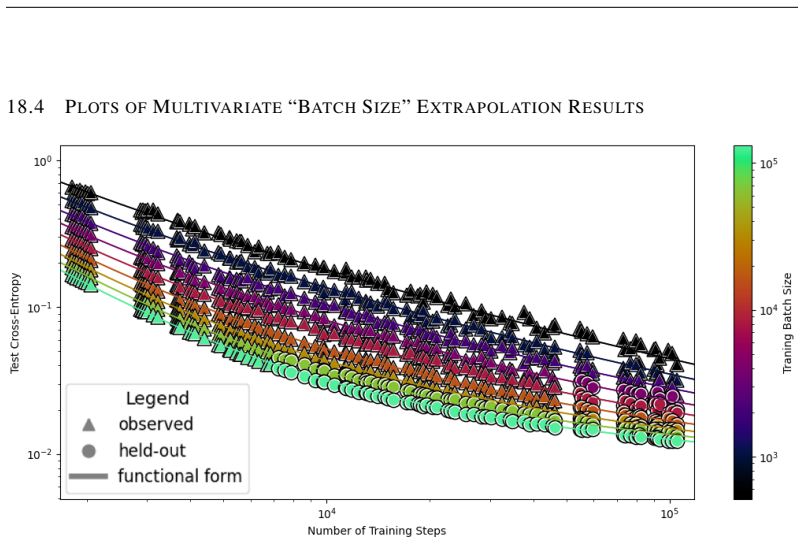
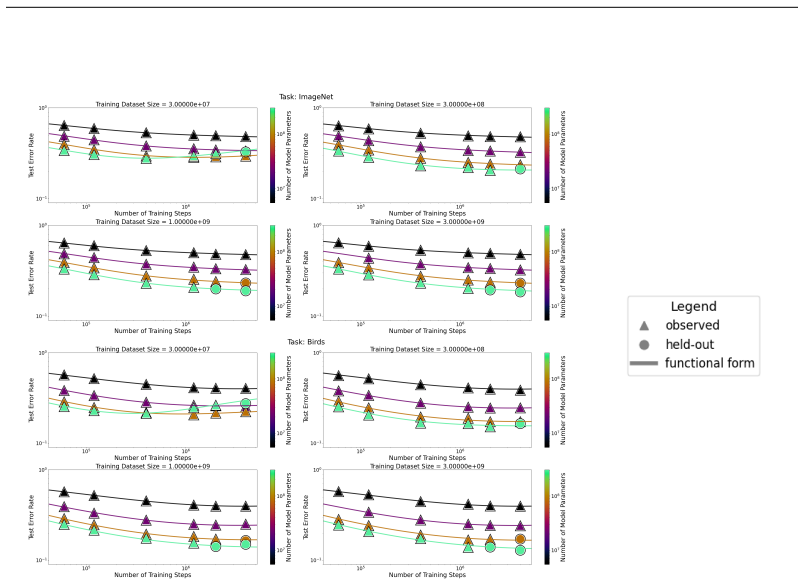
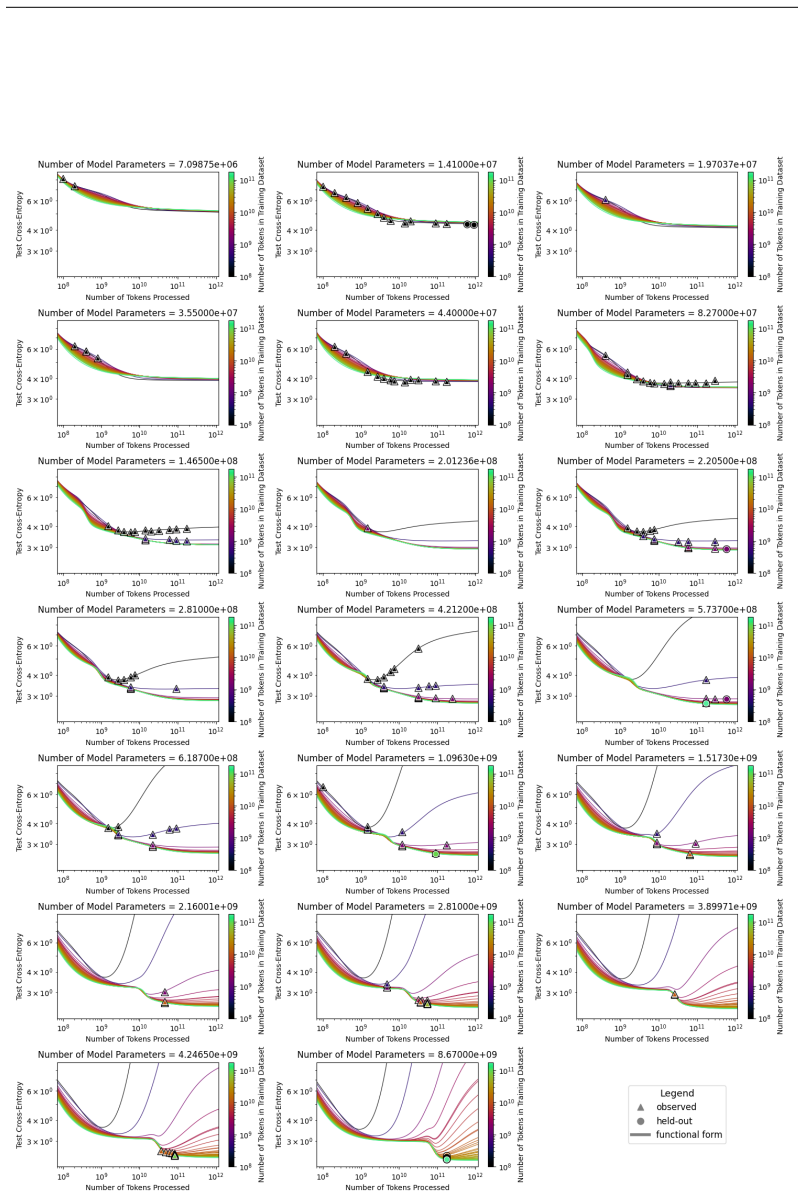
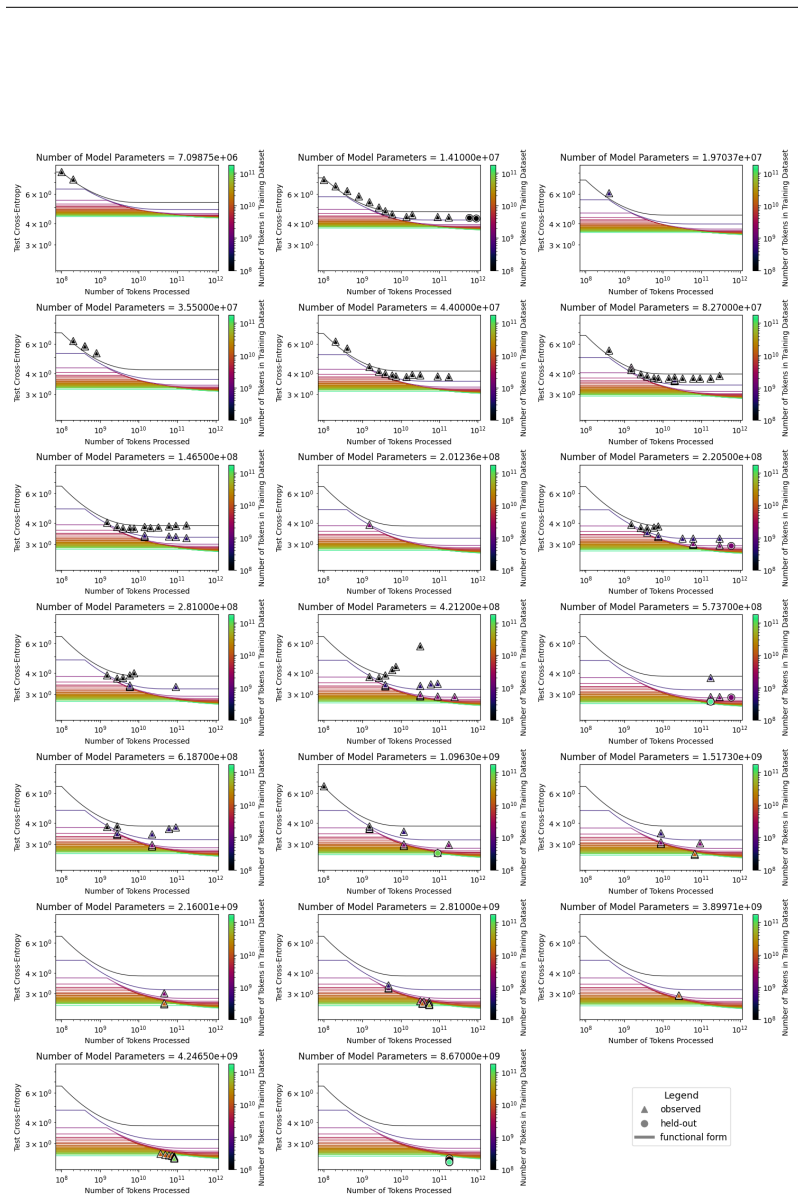
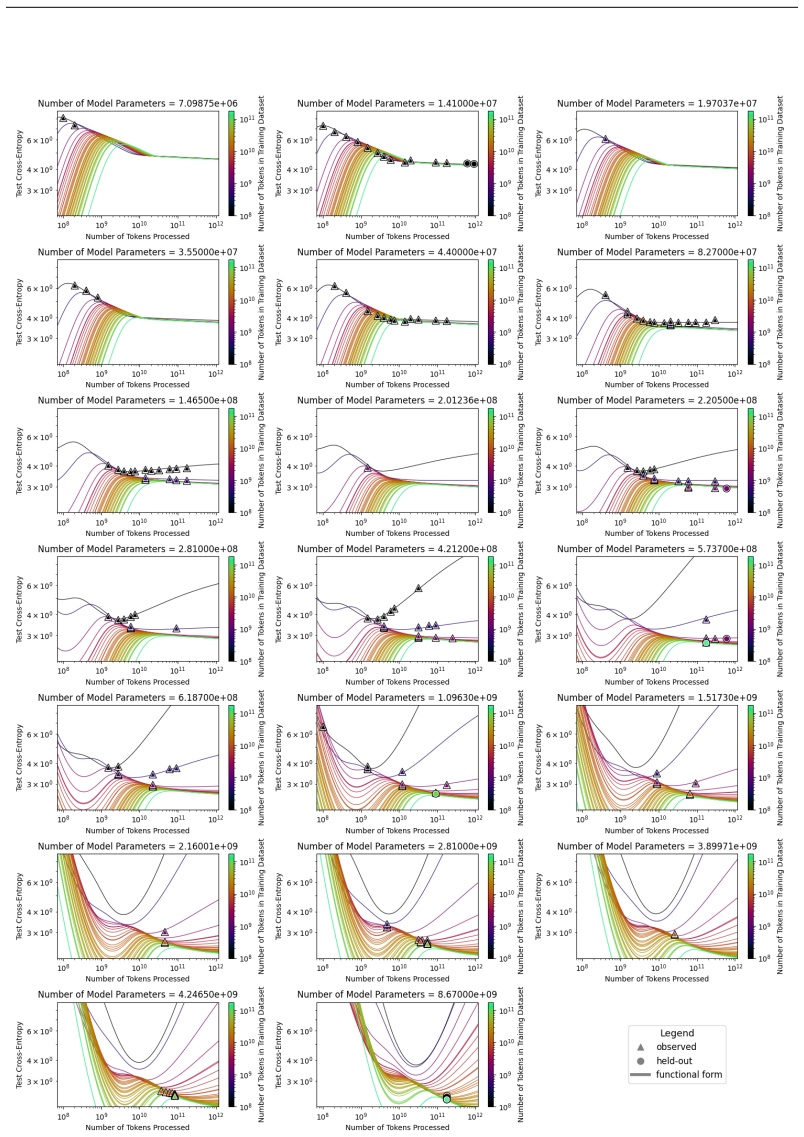
The authors introduce the Unified Neural Scaling Law (UNSL) as a functional form that models how an evaluation metric varies when the number of model parameters, training dataset size, number of training steps, number of inference steps, amount of compute, and various hyperparameters are all changed at once. This form is shown to accurately fit observed scaling behavior and to extrapolate to unseen larger values for diverse architectures on a range of tasks in vision, language, math, and reinforcement learning, outperforming other functional forms on extrapolation accuracy.
What carries the argument
The UNSL functional form, an expression that combines scaling terms for each dimension into one joint model without separate adjustments per architecture or task.
If this is right
- Performance forecasts become possible when several variables such as model size and dataset size change together rather than one at a time.
- The same expression applies without modification to vision, language, math and reinforcement learning tasks.
- Hyperparameter scaling effects are incorporated directly into the unified prediction.
- Compute budget planning can use the form to compare outcomes across different combinations of training length and model scale.
- Extrapolation error decreases relative to earlier scaling expressions on the tested set of tasks.
Where Pith is reading between the lines
- If the form holds, scaling behavior may share an underlying structure that is largely independent of task domain.
- Training runs could be optimized by solving for the combination of dimensions that reaches a target performance at lowest cost.
- The approach might be tested on multimodal or new architecture families to check whether the unification extends further.
- Accurate multi-dimensional laws could reduce the need for exhaustive hyperparameter sweeps at large scales.
Load-bearing premise
A single functional form can simultaneously capture scaling across model parameters, dataset size, training steps, inference steps, compute, and hyperparameters without architecture- or task-specific adjustments.
What would settle it
Measuring actual performance on a held-out large-scale task or architecture at higher combined values of multiple dimensions and finding that UNSL extrapolations deviate substantially from the measured values while prior forms do not.
Figures
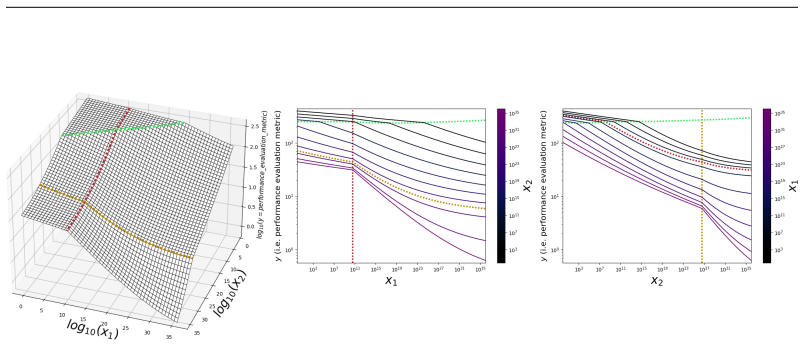
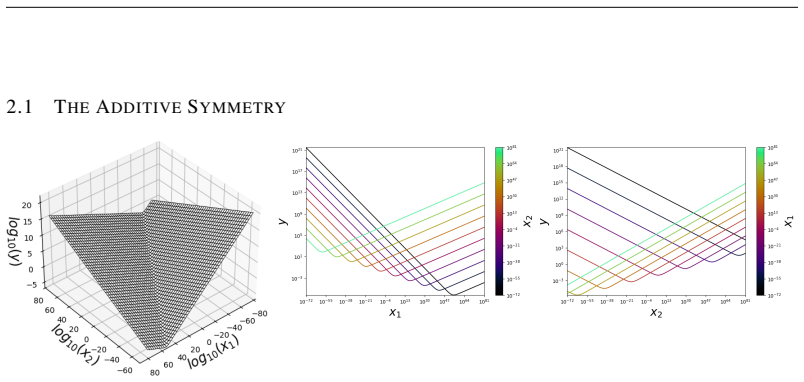
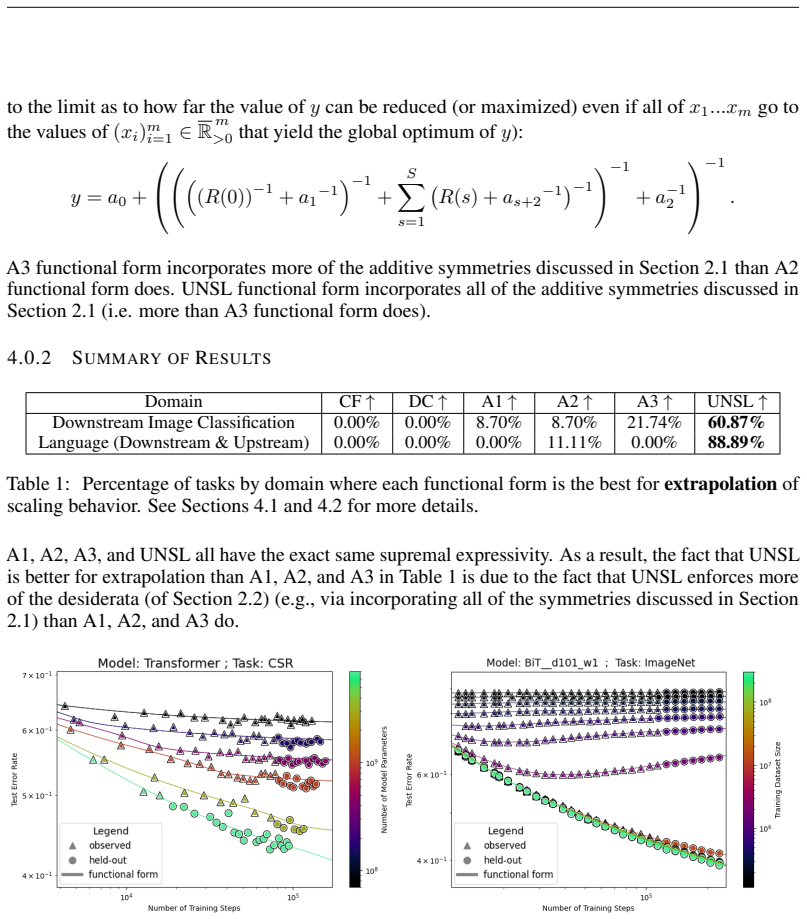
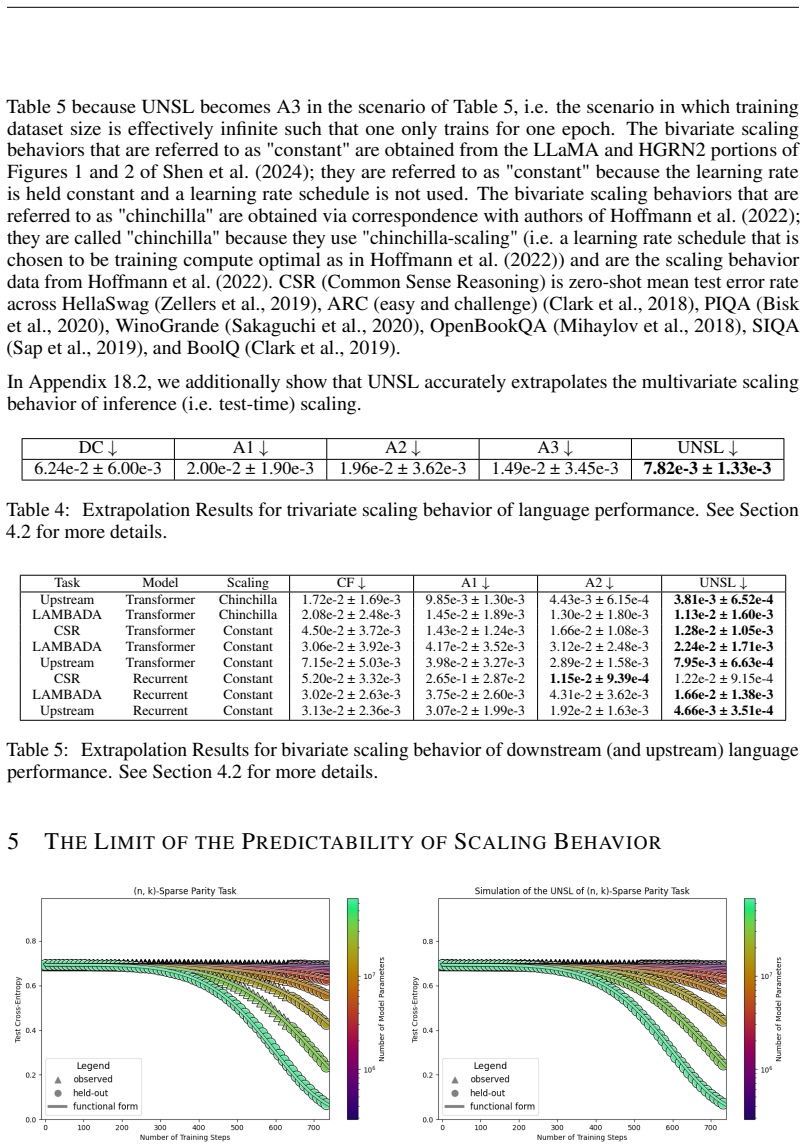
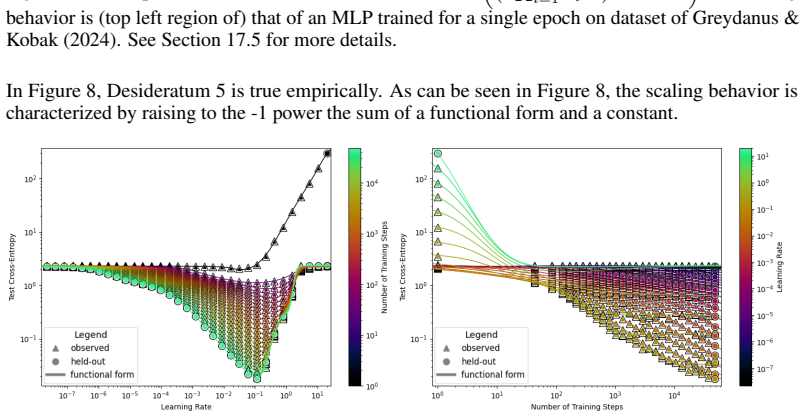
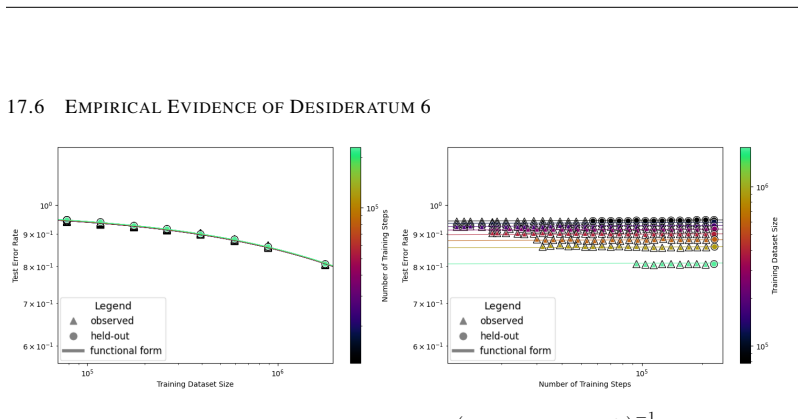
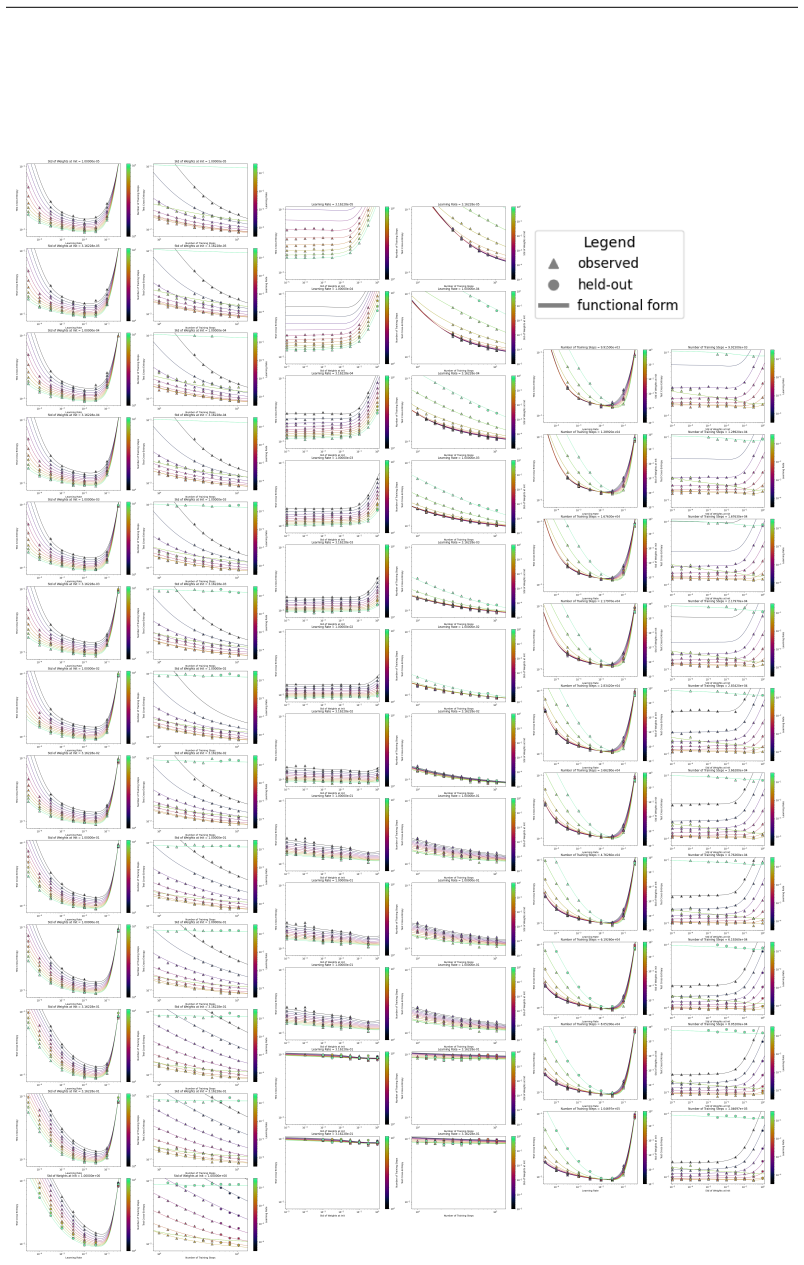
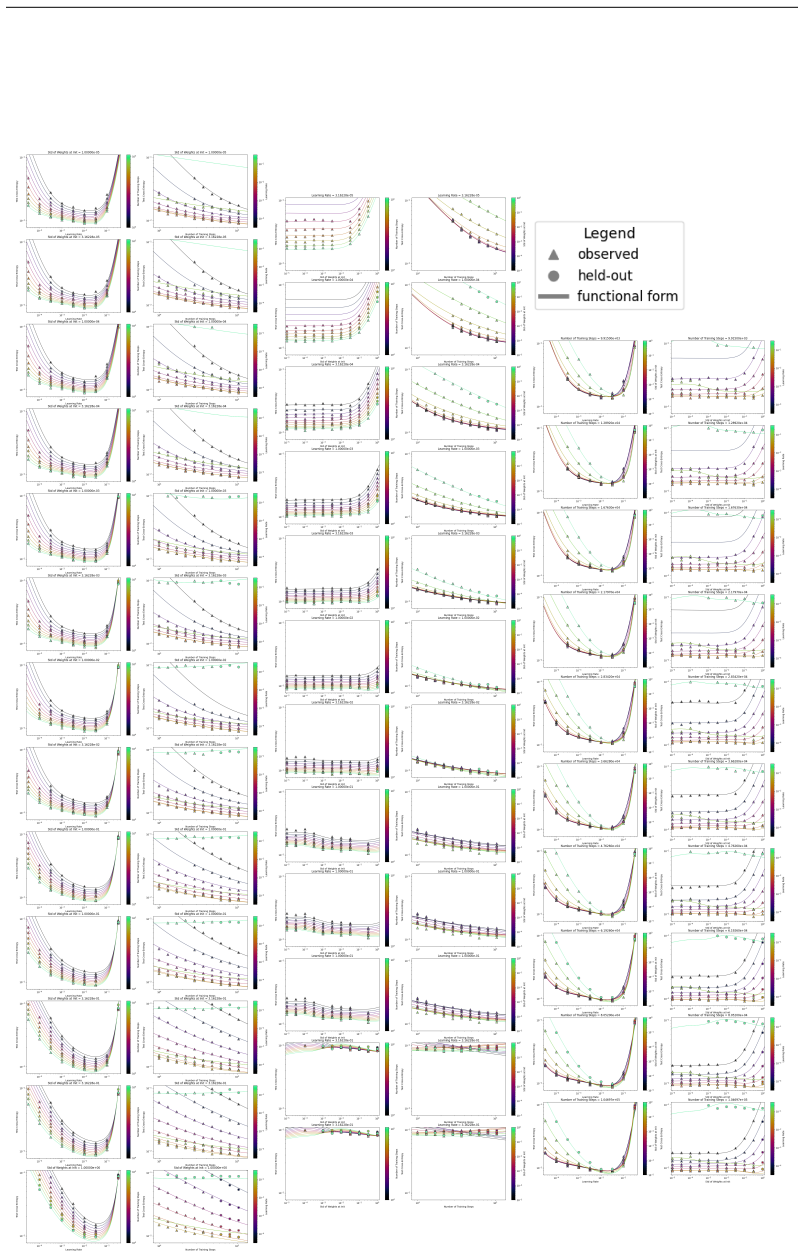
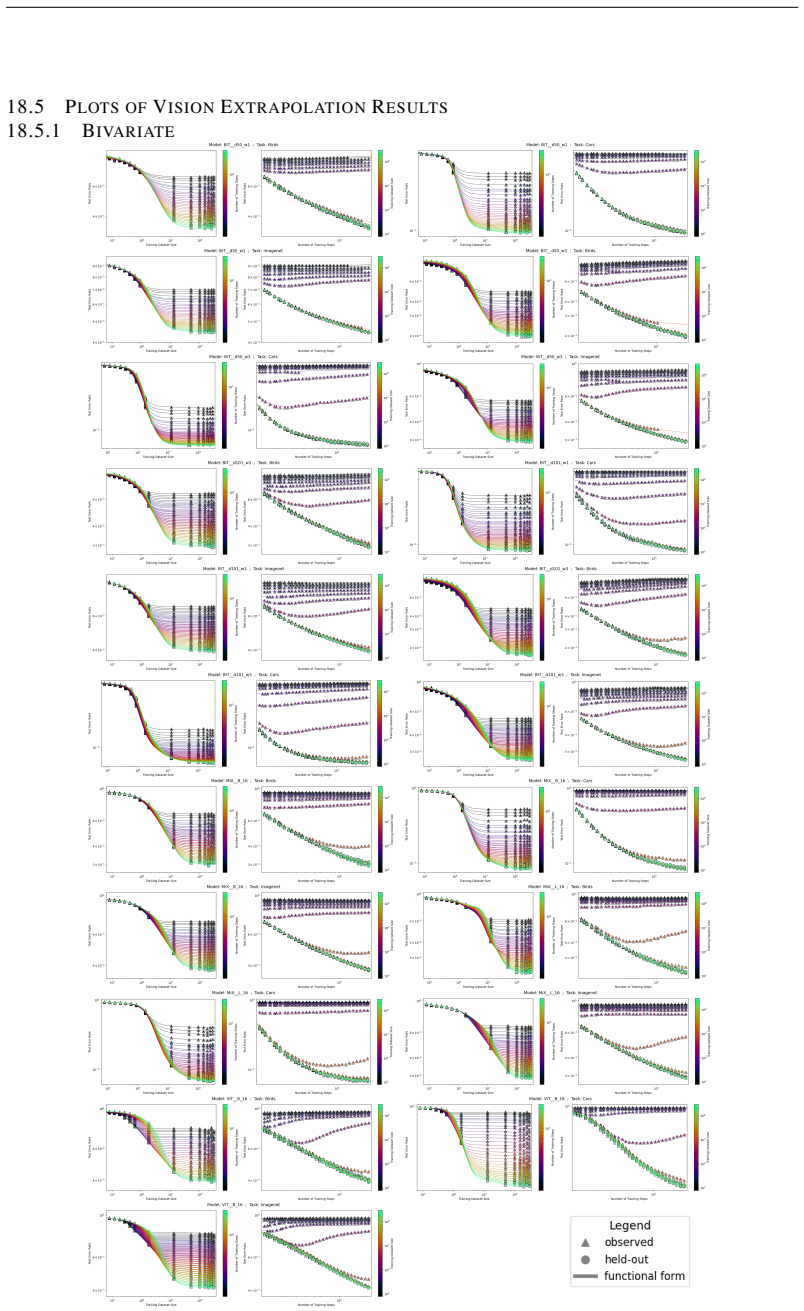

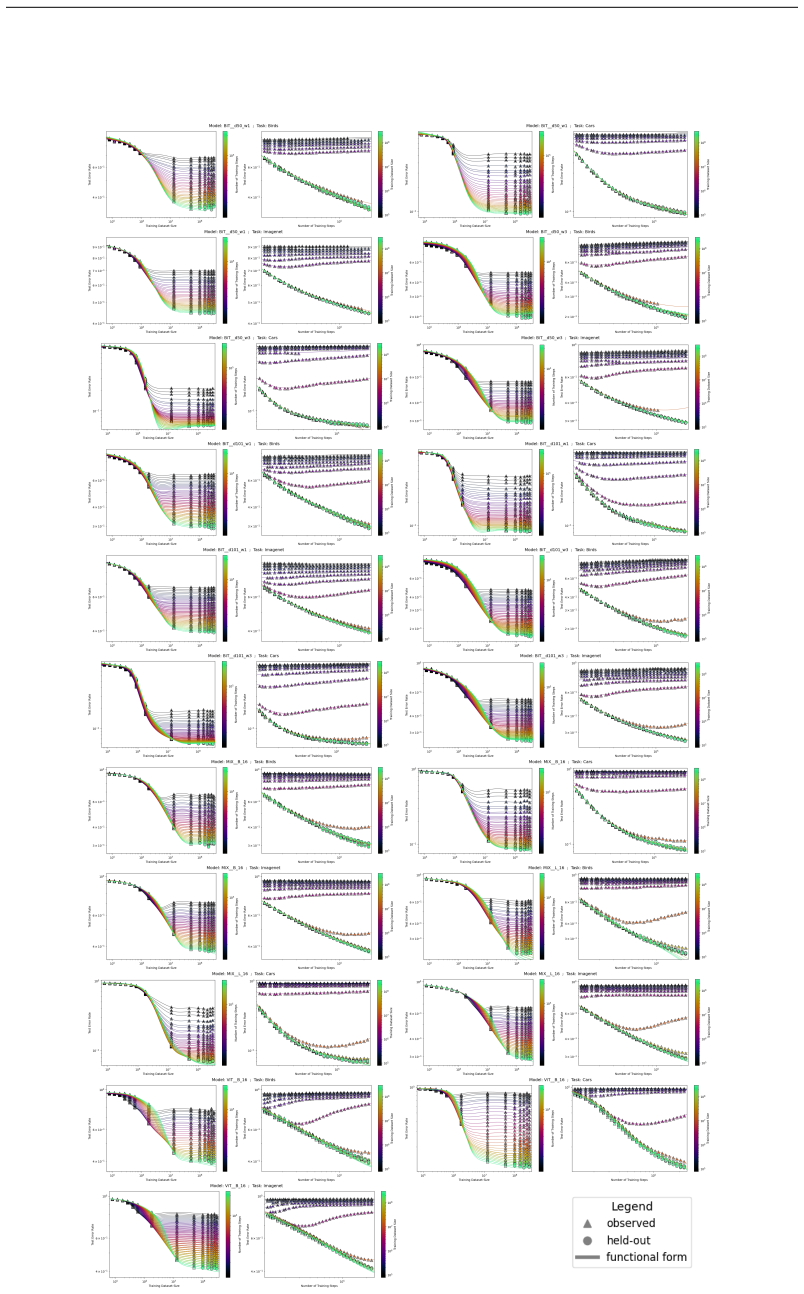
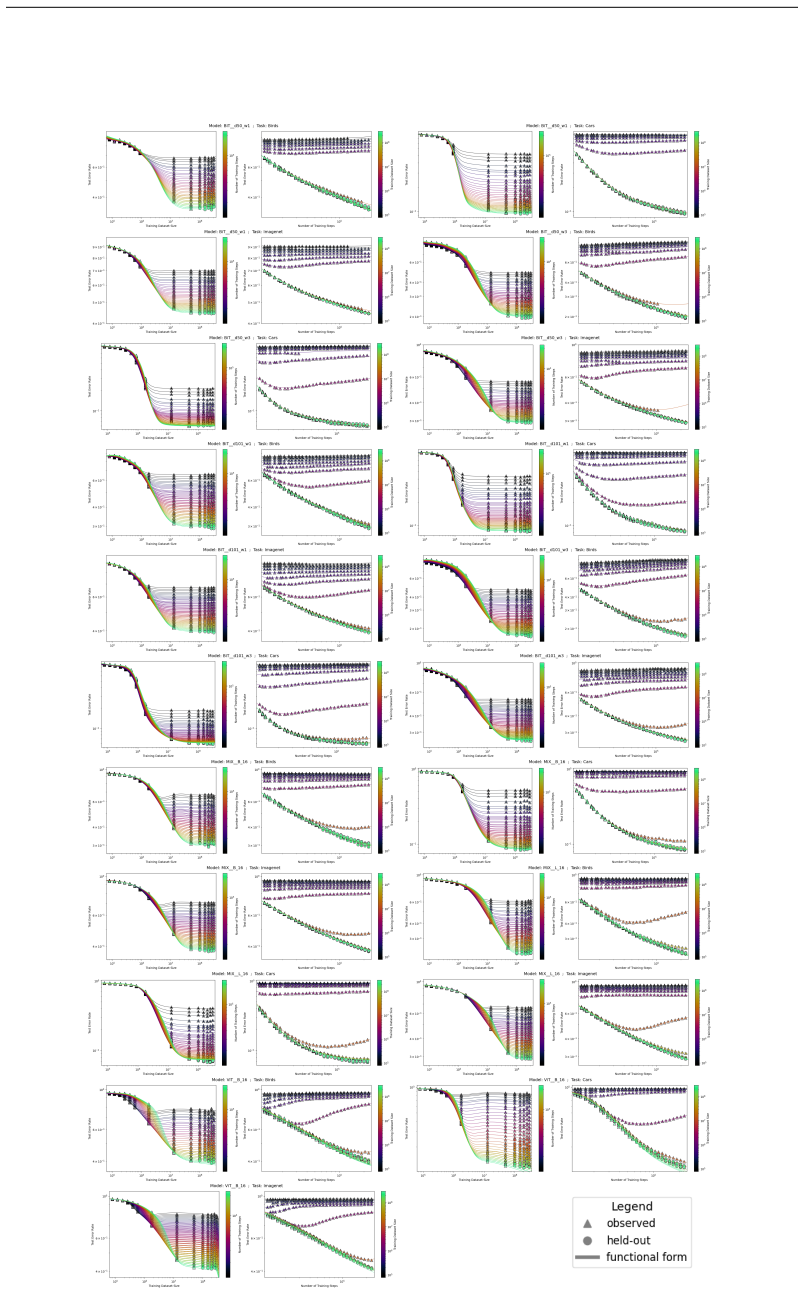
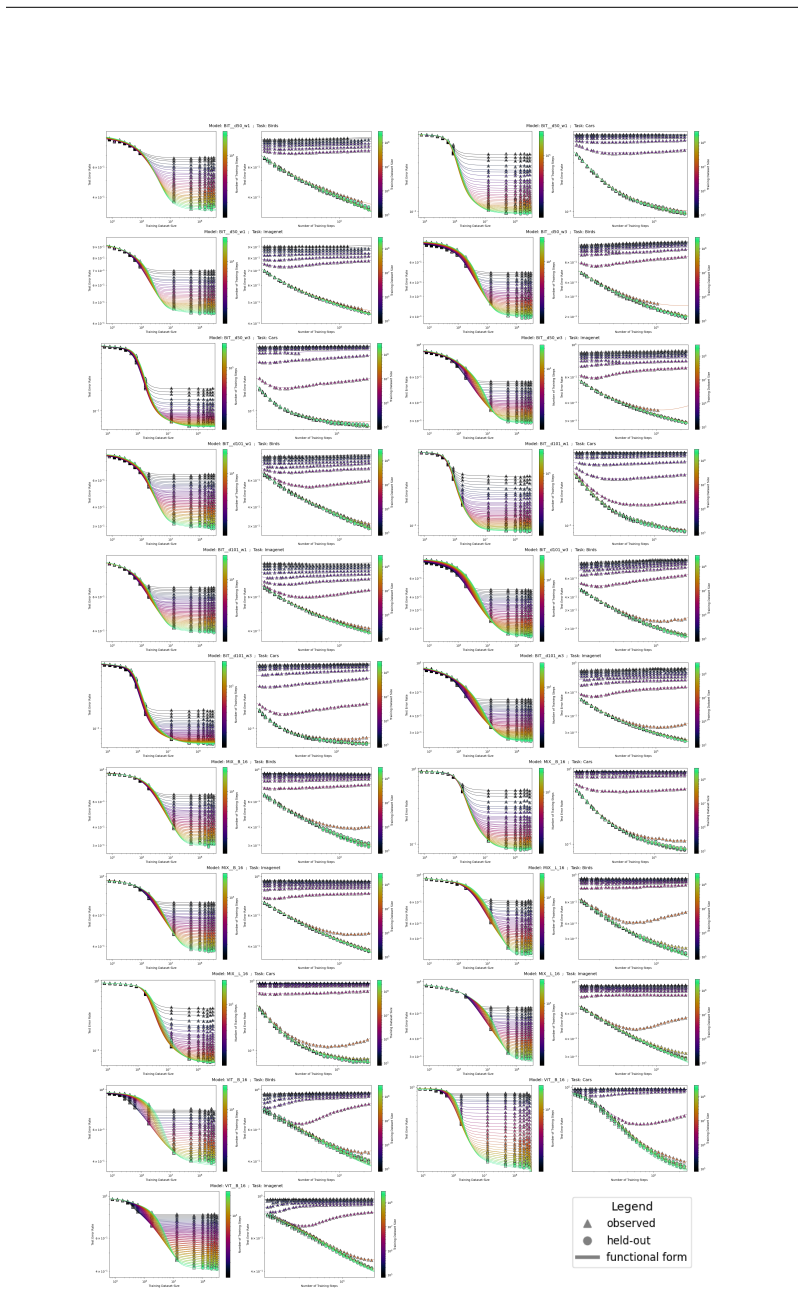
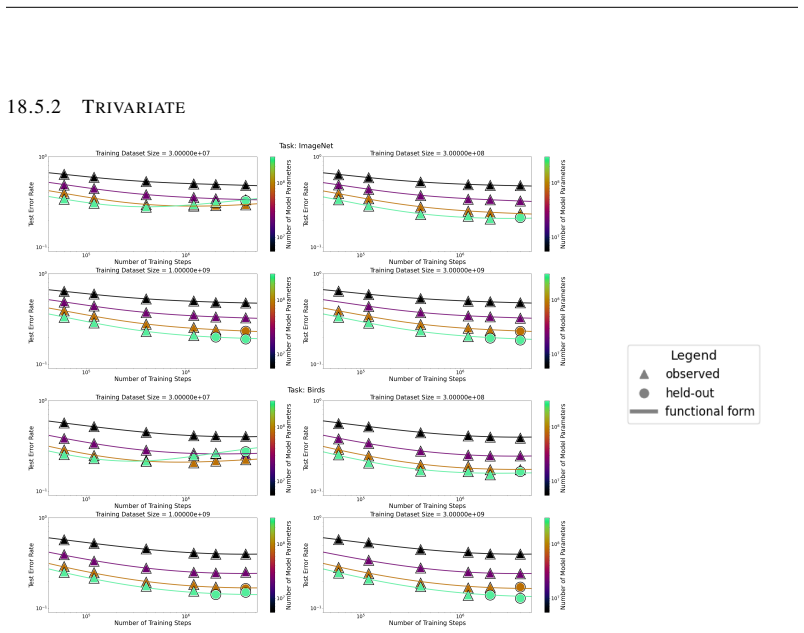
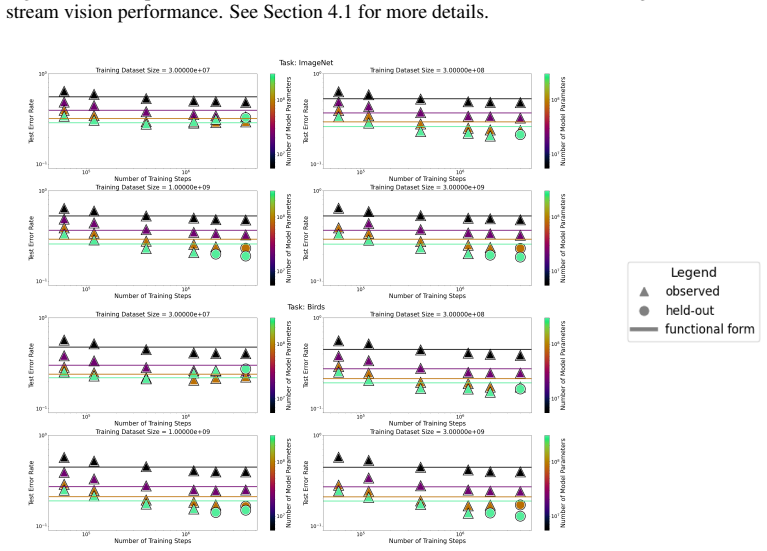
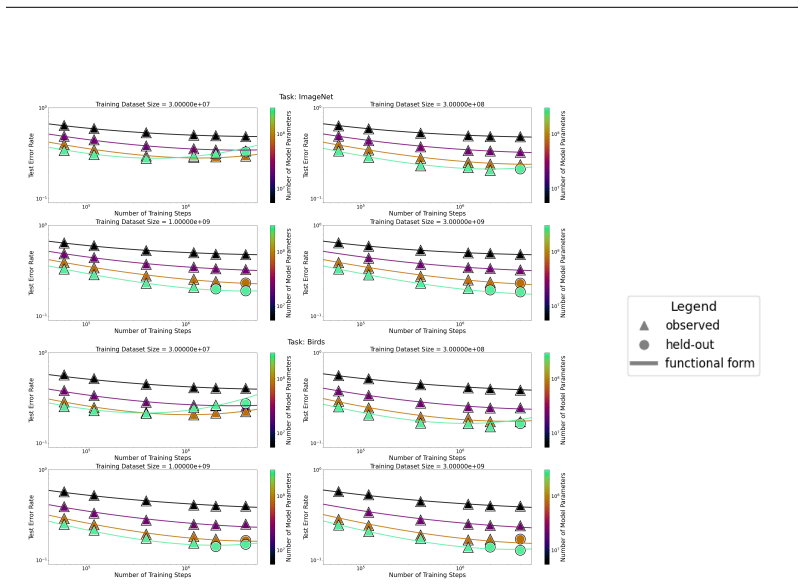
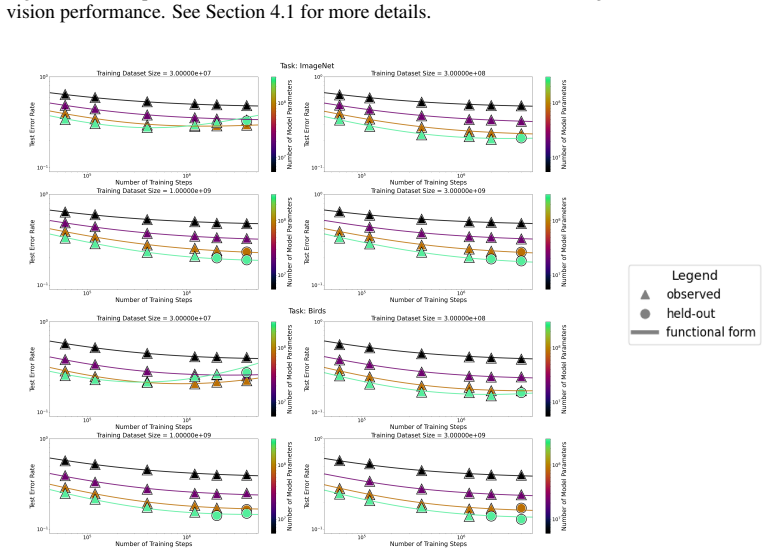
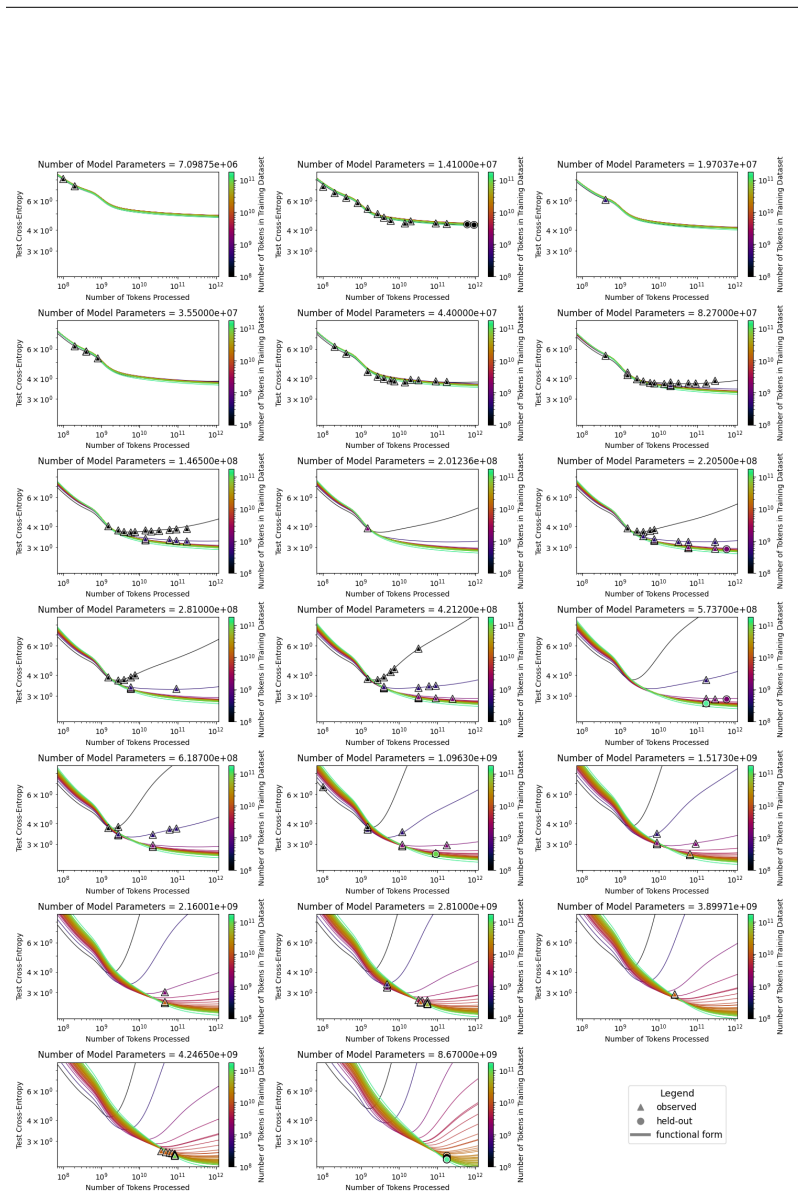
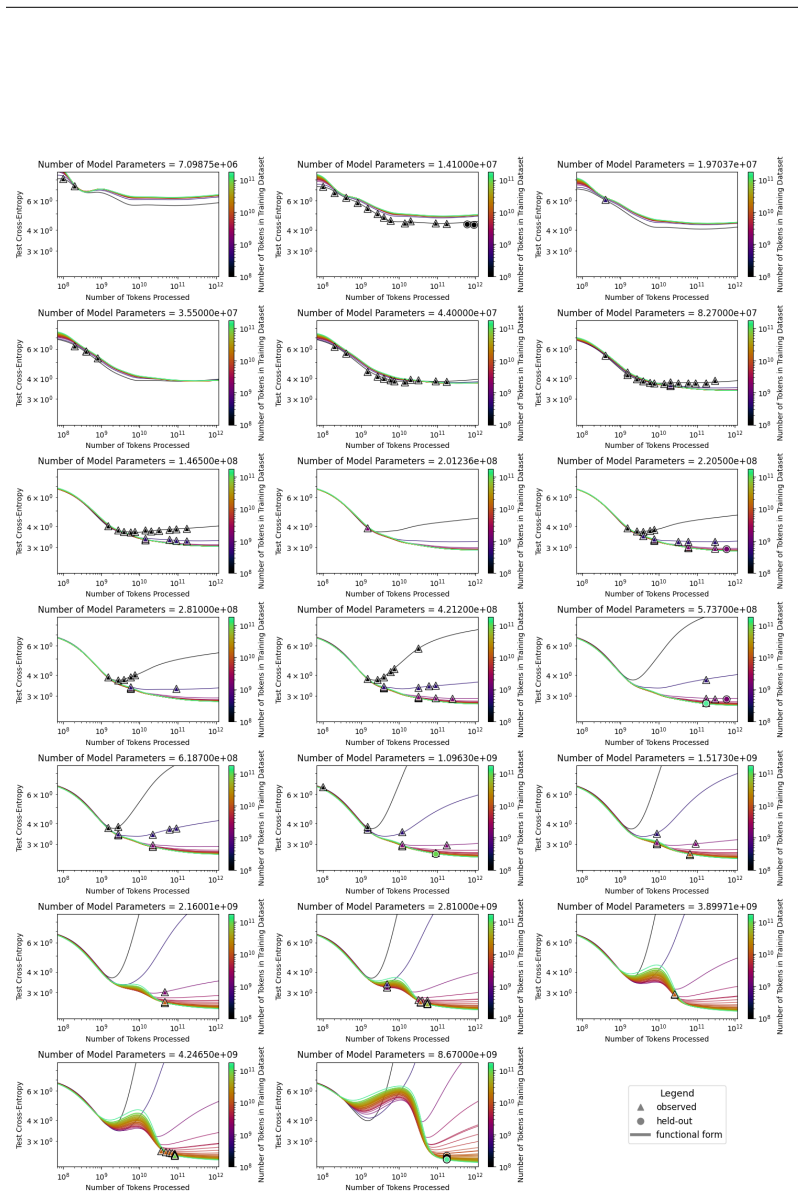
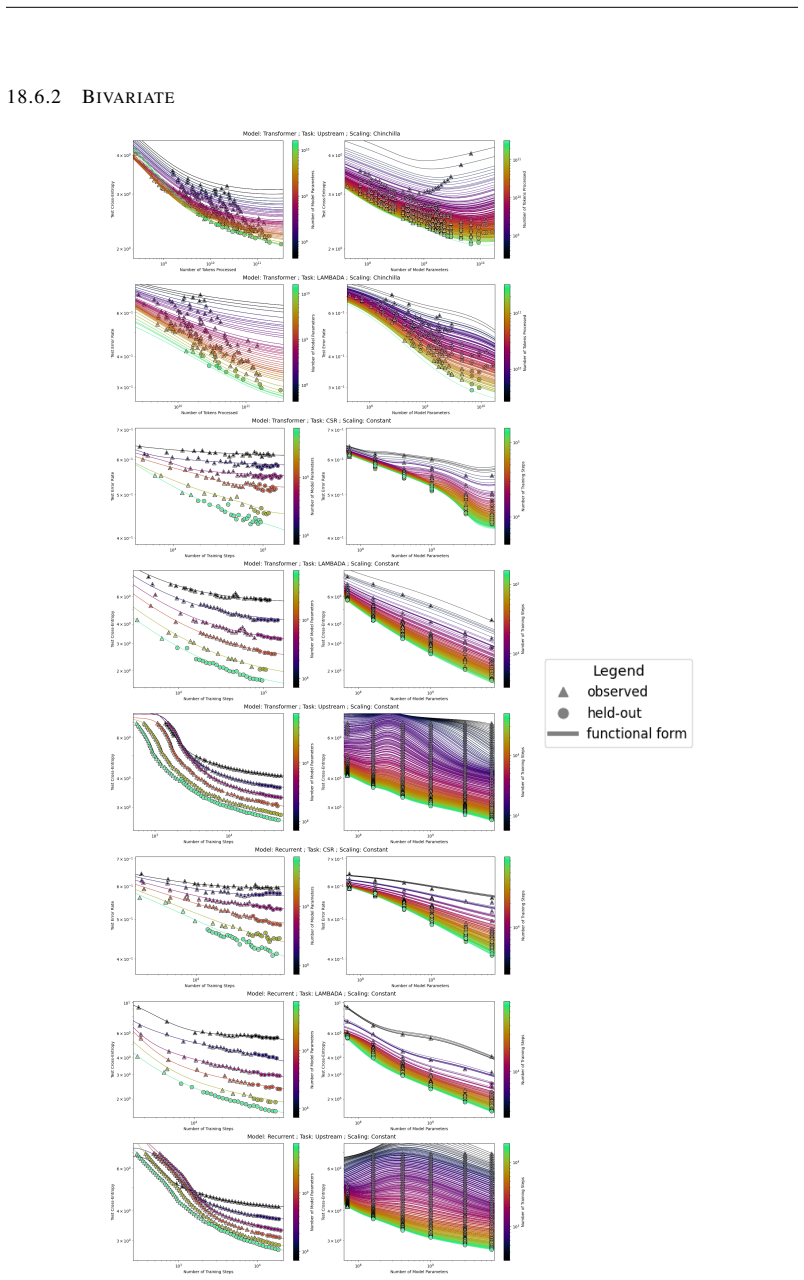
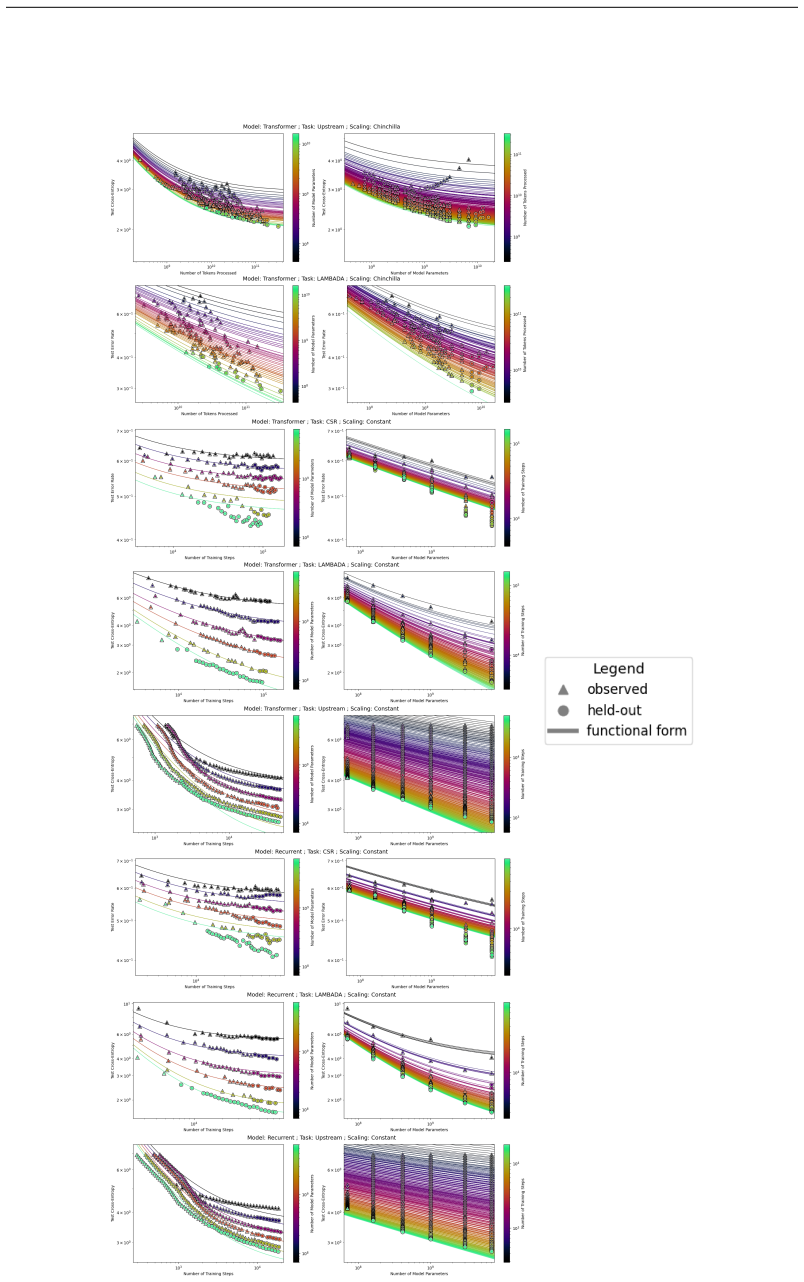
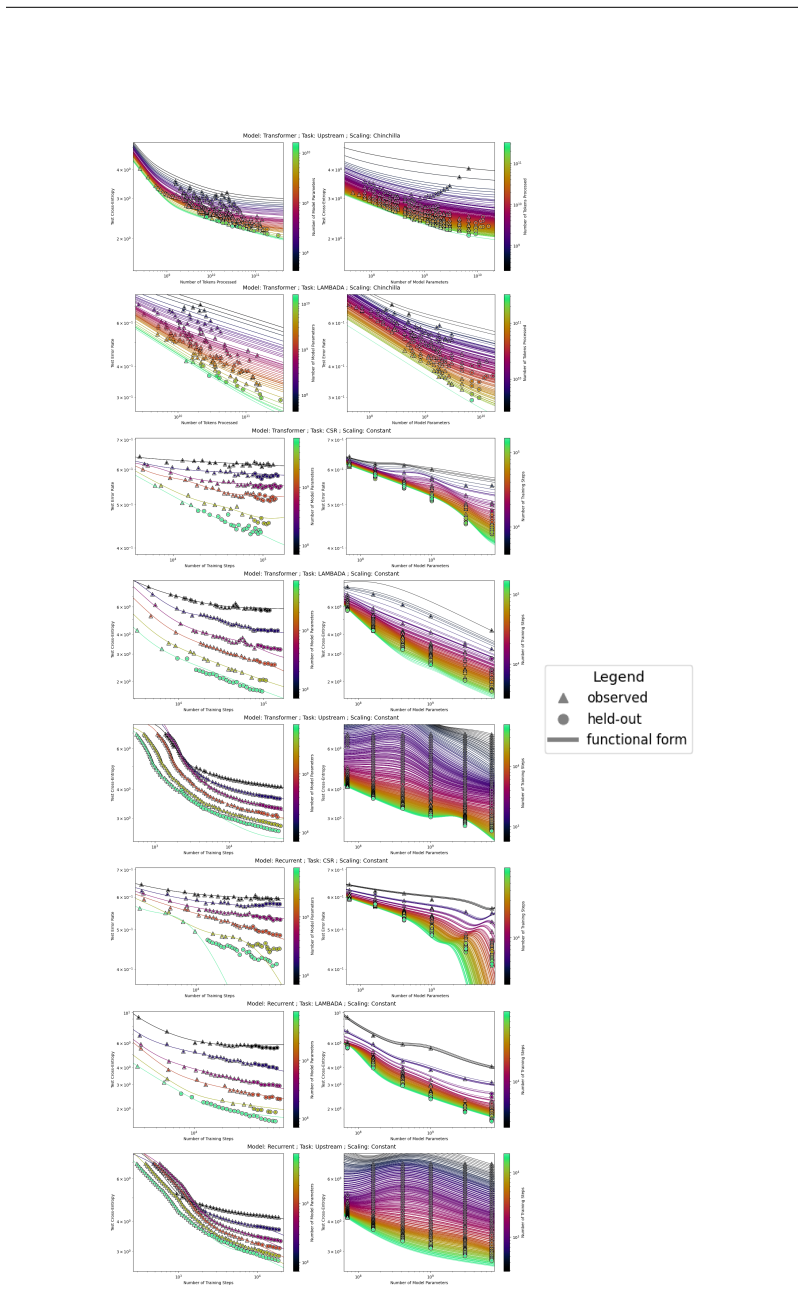
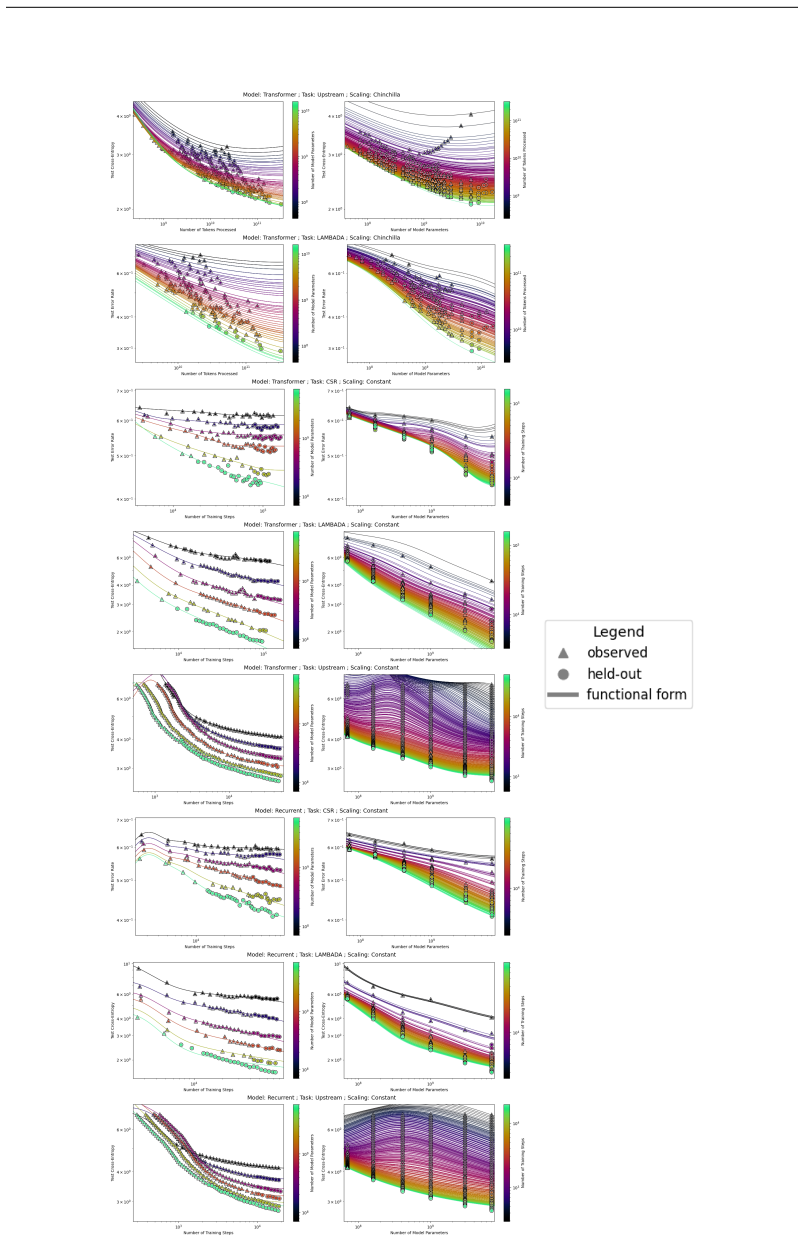
read the original abstract
We present a functional form (that we refer to as a Unified Neural Scaling Law (UNSL)) that accurately models and extrapolates the scaling behaviors of deep neural networks as multiple dimensions all vary simultaneously (i.e. how the evaluation metric of interest varies as one simultaneously varies the number of model parameters, training dataset size, number of training steps, number of inference steps, amount of compute, and various hyperparameters) for various architectures and for each of various tasks within a varied set of upstream and downstream tasks. This set includes large-scale vision, language, math, and reinforcement learning. When compared to other functional forms for neural scaling, this functional form yields extrapolations of scaling behavior that are considerably more accurate on this set.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a Unified Neural Scaling Law (UNSL) functional form claimed to accurately model and extrapolate the scaling behaviors of deep neural networks as multiple dimensions vary simultaneously (model parameters, dataset size, training steps, inference steps, compute, and hyperparameters) for various architectures and tasks across large-scale vision, language, math, and reinforcement learning, both upstream and downstream. It asserts that this form yields considerably more accurate extrapolations than other functional forms for neural scaling.
Significance. If the central claim holds with a fixed algebraic structure across cases, this would be a significant contribution to neural scaling laws research, offering a practical tool for predicting performance across diverse settings and reducing the need for exhaustive experimentation. The unification across multiple dimensions and task types, if demonstrated without per-case structural modifications, would strengthen the result beyond existing scaling laws that often require separate forms per regime.
major comments (3)
- [Abstract] Abstract: The claim that a single functional form simultaneously captures scaling across all listed dimensions and tasks for multiple architectures is load-bearing for the unification result, yet the abstract supplies no equation, no fitting procedure, and no cross-task consistency check; the full manuscript must demonstrate that the algebraic structure itself remains identical (rather than merely reusing the same variable names with different coefficients or added terms).
- [Functional form and experiments sections] Functional form and experiments sections: To support the claim of superior extrapolation accuracy, the paper must report the exact UNSL equation, the validation protocol (including how extrapolations are tested against held-out data), error bars on all reported metrics, and explicit data exclusion rules; without these, the asserted accuracy advantage cannot be verified or reproduced.
- [Cross-architecture/task analysis] Cross-architecture/task analysis: The manuscript must provide explicit evidence (e.g., a table or section comparing fitted forms) that no architecture- or task-specific functional pieces are introduced; if any such modifications are needed to achieve the reported fits, the unification claim is undermined even if separate coefficient sets are used per case.
minor comments (1)
- [Abstract] Abstract: Consider adding a one-sentence description of the UNSL functional form or a key quantitative result to make the contribution more immediately accessible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to improve clarity where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that a single functional form simultaneously captures scaling across all listed dimensions and tasks for multiple architectures is load-bearing for the unification result, yet the abstract supplies no equation, no fitting procedure, and no cross-task consistency check; the full manuscript must demonstrate that the algebraic structure itself remains identical (rather than merely reusing the same variable names with different coefficients or added terms).
Authors: We agree the abstract benefits from including the equation. The revised abstract now states the UNSL form explicitly. Sections 3 and 4 of the manuscript already detail the identical algebraic structure (same equation used for all cases), the fitting procedure, and cross-task consistency via shared structure with per-case coefficients only. revision: yes
-
Referee: [Functional form and experiments sections] Functional form and experiments sections: To support the claim of superior extrapolation accuracy, the paper must report the exact UNSL equation, the validation protocol (including how extrapolations are tested against held-out data), error bars on all reported metrics, and explicit data exclusion rules; without these, the asserted accuracy advantage cannot be verified or reproduced.
Authors: Equation (1) gives the exact UNSL form. Section 5 describes the validation protocol with held-out extrapolation tests. We have added error bars to all metrics and explicit data exclusion rules in the revised experiments section to support reproducibility. revision: yes
-
Referee: [Cross-architecture/task analysis] Cross-architecture/task analysis: The manuscript must provide explicit evidence (e.g., a table or section comparing fitted forms) that no architecture- or task-specific functional pieces are introduced; if any such modifications are needed to achieve the reported fits, the unification claim is undermined even if separate coefficient sets are used per case.
Authors: Section 6 and Table 4 already supply the requested comparison, showing the same algebraic structure is used across all architectures and tasks with no added terms or modifications—only coefficients change. This directly supports the unification claim without per-case structural changes. revision: no
Circularity Check
No derivation chain or equations visible; circularity not detectable
full rationale
The provided manuscript text consists only of the abstract, which describes a Unified Neural Scaling Law functional form and its claimed accuracy but supplies neither the explicit functional form, any equations, fitting procedure, derivation steps, nor self-citations. Without mathematical content or a claimed derivation chain to inspect, no load-bearing reductions to inputs by construction, fitted predictions, or self-citation patterns can be identified. The default finding of no significant circularity therefore applies, as the paper is self-contained against external benchmarks only in the sense that nothing is presented to evaluate.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Revisiting neural scaling laws in language and vision
Ibrahim Mansour I Alabdulmohsin, Behnam Neyshabur, and Xiaohua Zhai. Revisiting neural scaling laws in language and vision. InNeurIPS 2022,
2022
-
[2]
ISSN 2835-8856. Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.arXiv preprint arXiv:2102.06701,
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
URL https://github.com/ google-deepmind/kfac-jax. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[4]
URL https://arxiv. org/abs/2210.14891. Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolog...
-
[5]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. InInternational conference on machine learning, pp. 2048–2056. PMLR,
2048
-
[6]
Mathematics of Control, Signals and Systems , author =
doi: 10.1007/BF02551274. Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee,
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: Training ImageNet in 1 hour.arXiv preprint arXiv:1706.02677,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, Chris Hallacy, Benjamin Mann, Alec Radford, Aditya Ramesh, Nick Ryder, Daniel M. Ziegler, John Schulman, Dario Amodei, and Sam Mc- Candlish. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010.14701,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer. arXiv preprint arXiv:2102.01293,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep Learning Scaling is Predictable, Empirically.arXiv e-prints, art. arXiv:1712.00409, December
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Scaling laws for single-agent reinforcement learning
Jacob Hilton, Jie Tang, and John Schulman. Scaling laws for single-agent reinforcement learning. arXiv preprint arXiv:2301.13442,
-
[13]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
doi: 10.1016/0893-6080(91)90009-T. Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. InLearning and Intelligent Optimization (LION), pp. 507–523. Springer,
-
[15]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling Laws for Neural Language Models.arXiv e-prints, art. arXiv:2001.08361, January
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[16]
doi: 10.1016/S0893-6080(05)80131-5. Hao Li, Yang Zou, Ying Wang, Orchid Majumder, Yusheng Xie, R. Manmatha, Ashwin Swaminathan, Zhuowen Tu, Stefano Ermon, and Stefano Soatto. On the scalability of diffusion-based text-to- image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9400–9409,
-
[17]
Scaling laws for diffusion transformers.arXiv preprint arXiv:2410.08184,
Zhengyang Liang, Hao He, Ceyuan Yang, and Bo Dai. Scaling laws for diffusion transformers.arXiv preprint arXiv:2410.08184,
-
[18]
An Empirical Model of Large-Batch Training
Accessed: 2025-10-05. Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training.arXiv preprint arXiv:1812.06162,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2381–2391,
2018
-
[20]
Scaling Data-Constrained Language Models
Niklas Muennighoff, Alexander M Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models. arXiv preprint arXiv:2305.16264,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Deep double descent: Where bigger models and more data hurt.arXiv preprint arXiv:1912.02292,
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: Where bigger models and more data hurt.arXiv preprint arXiv:1912.02292,
-
[22]
Scaling laws for a multi-agent reinforcement learning model
Oren Neumann and Claudius Gros. Scaling laws for a multi-agent reinforcement learning model. arXiv preprint arXiv:2210.00849,
-
[23]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Gen- eralization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
URL http://arxiv. org/abs/1909.12673. Ranajoy Sadhukhan, Zhuoming Chen, Haizhong Zheng, Yang Zhou, Emma Strubell, and Beidi Chen. Kinetics: Rethinking test-time scaling laws.arXiv preprint arXiv:2506.05333,
-
[26]
Scaling laws for linear complexity language models.arXiv preprint arXiv:2406.16690,
Xuyang Shen, Dong Li, Ruitao Leng, Zhen Qin, Weigao Sun, and Yiran Zhong. Scaling laws for linear complexity language models.arXiv preprint arXiv:2406.16690,
-
[27]
Don't Decay the Learning Rate, Increase the Batch Size
Samuel L. Smith, Pieter-Jan Kindermans, Chris Ying, and Quoc V . Le. Don’t decay the learning rate, increase the batch size.arXiv preprint arXiv:1711.00489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Freeze-Thaw Bayesian Optimization
URL http://www. incompleteideas.net/IncIdeas/BitterLesson.html. Kevin Swersky, Jasper Snoek, and Ryan Prescott Adams. Freeze-thaw Bayesian optimization.arXiv preprint arXiv:1406.3896,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Greg Yang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor programs V: Tuning large neural networks via zero-shot hyperparameter transfer.arXiv preprint arXiv:2203.03466,
-
[30]
Large Batch Training of Convolutional Networks
Yang You, Igor Gitman, and Boris Ginsburg. Large batch training of convolutional networks.arXiv preprint arXiv:1708.03888,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer
URLhttps://arxiv.org/abs/2106.04560. Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12104–12113,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.