Personalizing Embodied Multimodal Large Language Model Agents over Long-term User Interactions
Pith reviewed 2026-06-29 21:16 UTC · model grok-4.3
The pith
Embodied MLLM agents personalize tasks by retrieving from a multimodal knowledge graph of accumulated user interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
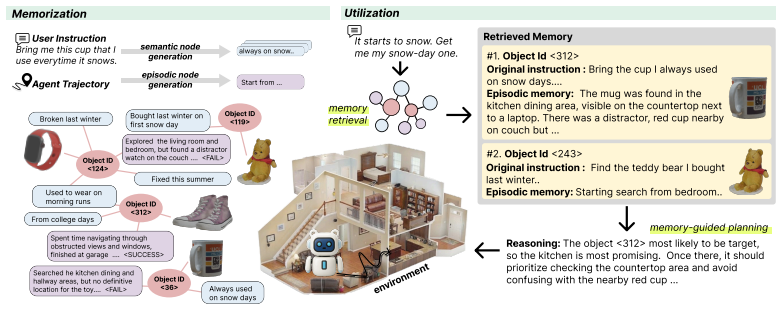
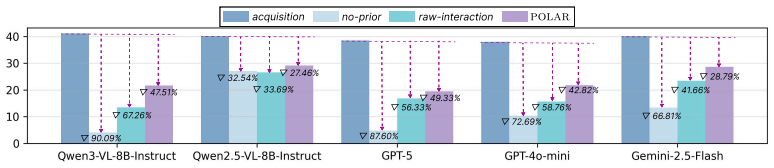
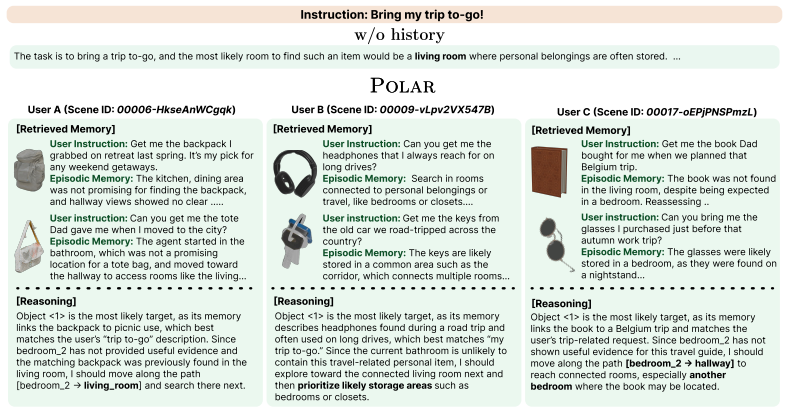
POLAR organizes prior interactions into a multimodal knowledge graph that captures semantic memory for personalized context and visual concepts, and episodic memory for embodied experiences such as agent trajectories. To execute embodied tasks, POLAR retrieves relevant memories to interpret the current request and guide task execution, producing consistent performance improvements across MLLM backbones, with larger gains when agents must reason across multiple interactions, perform multi-hop inference, or track updates in user-specific context over time.
What carries the argument
A multimodal knowledge graph that stores semantic memory for personalized context and visual concepts together with episodic memory for trajectories, then retrieves entries to interpret requests and direct execution.
If this is right
- Agents achieve higher success rates on tasks whose intended targets are specified only implicitly through prior interactions.
- Performance gains appear across multiple different MLLM backbones when memory retrieval is added.
- Reasoning that spans several past sessions or requires multi-hop inference benefits most from the accumulated memories.
- Tracking updates in user-specific context over time becomes more reliable with the episodic and semantic stores.
Where Pith is reading between the lines
- The separation of semantic and episodic memory types may prove useful for other agent systems that must balance factual user preferences against action histories.
- If retrieval quality holds, the same graph structure could reduce redundant exploration of known preferences in repeated physical environments.
- Longer interaction histories could be handled by scaling the same retrieval process rather than retraining the underlying MLLM each time.
Load-bearing premise
The multimodal knowledge graph can reliably retrieve and integrate relevant memories without introducing errors or hallucinations that degrade task execution.
What would settle it
A controlled test in which agents using the memory mechanism show no gain or increased errors on multi-interaction reasoning tasks compared with agents lacking retrieval would falsify the central performance claim.
Figures



read the original abstract
Multimodal large language model (MLLM)-based embodied agents have shown strong potential for solving complex tasks in physical environments. However, personalized assistance requires more than following generic instruction or recognizing object categories. In real-world scenarios, the intended target is often specified only implicitly through prior interactions, requiring agents to leverage personalized context accumulated over time. In this work, we propose POLAR, a multiomodal memory-augmented framework for personalized embodied agents over long-term user interactions. POLAR organizes prior interactions into a multimodal knowledge graph that captures semantic memory for personalized context and visual concepts, and episodic memory for embodied experiences such as agent trajectories. To execute embodied tasks, POLAR retrieves relevant memories to interpret the current request and guide task execution. We evaluate POLAR across multiple MLLM backbones and diverse evaluation scenarios to study the role of memory in long-term personalization. Results show that the proposed memory mechanism consistently improves performance by enabling more effective use of information accumulated over prior interactions. The gains are especially pronounced when the agents are required to reason across multiple interactions, perform multi-hop inference, or tracking updates in user-specific context over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces POLAR, a multimodal memory-augmented framework for personalized embodied MLLM agents. Prior interactions are organized into a multimodal knowledge graph capturing semantic memory (personalized context and visual concepts) and episodic memory (embodied experiences such as trajectories). Relevant memories are retrieved to interpret user requests and guide task execution. Evaluation across multiple MLLM backbones and diverse scenarios reports that the memory mechanism yields consistent performance gains, with larger benefits on tasks requiring reasoning across multiple interactions, multi-hop inference, or tracking updates in user-specific context.
Significance. If the empirical results are robustly supported by detailed quantitative evaluation, the work would address a practically important limitation in current embodied MLLM agents—the lack of long-term personalized memory—potentially enabling more effective real-world assistance that accumulates user-specific context over time.
major comments (2)
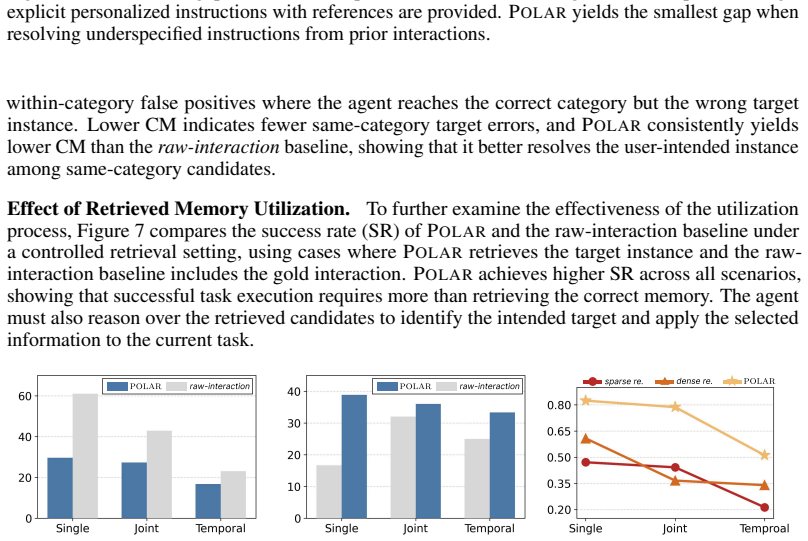
- [Abstract / Evaluation] Abstract and evaluation description: the central claim of 'consistent improvements' and 'especially pronounced' gains on multi-interaction reasoning is presented without any quantitative numbers, error bars, baseline comparisons, or description of memory-retrieval implementation and metrics. This absence leaves the load-bearing empirical support for the framework unassessable from the provided text.
- [Evaluation] The weakest assumption noted in the stress-test (reliable multimodal KG retrieval without net-negative hallucinations or errors) receives no supporting ablation, retrieval-precision metrics, or failure-case analysis in the reported scenarios, which is required to substantiate that the observed gains are attributable to the memory mechanism rather than other factors.
minor comments (1)
- [Abstract] The abstract uses 'multiomodal' (typo for 'multimodal'); this should be corrected for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on our manuscript. We address each major comment below, clarifying the empirical support in the full paper while committing to revisions that make key claims and supporting analyses more explicit and assessable from the abstract and evaluation overview.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the central claim of 'consistent improvements' and 'especially pronounced' gains on multi-interaction reasoning is presented without any quantitative numbers, error bars, baseline comparisons, or description of memory-retrieval implementation and metrics. This absence leaves the load-bearing empirical support for the framework unassessable from the provided text.
Authors: We agree that the abstract and high-level evaluation description would benefit from explicit quantitative anchors to allow immediate assessment of the claims. The full manuscript contains detailed tables reporting performance across multiple MLLM backbones, with metrics such as success rates, multi-hop reasoning accuracy, and comparisons against memory-ablated baselines, including standard deviations over repeated trials. To address the concern directly, we will revise the abstract to incorporate representative quantitative results (e.g., average improvement margins and larger gains on multi-interaction tasks) along with a concise statement of the retrieval implementation and primary metrics used. This change will make the empirical support transparent without altering the manuscript's core findings. revision: yes
-
Referee: [Evaluation] The weakest assumption noted in the stress-test (reliable multimodal KG retrieval without net-negative hallucinations or errors) receives no supporting ablation, retrieval-precision metrics, or failure-case analysis in the reported scenarios, which is required to substantiate that the observed gains are attributable to the memory mechanism rather than other factors.
Authors: We acknowledge the importance of isolating the contribution of the memory-retrieval component. The manuscript's stress-test section explicitly flags reliable KG retrieval as a key assumption, yet the current version does not provide dedicated retrieval-precision metrics, component ablations, or systematic failure-case breakdowns. In the revision, we will add an ablation study removing or degrading the retrieval module, report precision/recall figures for semantic and episodic memory retrieval on the evaluation scenarios, and include a qualitative analysis of failure cases involving potential hallucinations or retrieval errors. These additions will strengthen the attribution of performance gains to the memory mechanism. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes POLAR, a multimodal memory-augmented framework that builds a knowledge graph from prior interactions and retrieves memories for task execution. All claims rest on empirical evaluation across MLLM backbones and scenarios, with no equations, parameter fits, derivation steps, or load-bearing self-citations present in the text. The central result (memory improves multi-interaction reasoning) is measured directly against baselines rather than defined into existence or imported via author-overlapping uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Embodiedgpt: Vision-language pre-training via embodied chain of thought.Advances in Neural Information Processing Systems, 36:25081–25094, 2023
Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought.Advances in Neural Information Processing Systems, 36:25081–25094, 2023
2023
-
[5]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[7]
From multimodal llms to generalist embodied agents: Methods and lessons
Andrew Szot, Bogdan Mazoure, Omar Attia, Aleksei Timofeev, Harsh Agrawal, Devon Hjelm, Zhe Gan, Zsolt Kira, and Alexander Toshev. From multimodal llms to generalist embodied agents: Methods and lessons. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10644–10655, 2025
2025
-
[8]
Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, et al. Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11142–11152, 2025
2025
-
[9]
A personalized household assistive robot that learns and creates new breakfast options through human-robot interaction
Ali Ayub, Chrystopher L Nehaniv, and Kerstin Dautenhahn. A personalized household assistive robot that learns and creates new breakfast options through human-robot interaction. In2023 32nd IEEE International Conference on Robot and Human Interactive Communication (RO- MAN), pages 2387–2393. IEEE, 2023
2023
-
[10]
Grounding multimodal llms to embodied agents that ask for help with reinforcement learning
Ram Ramrakhya, Matthew Chang, Xavier Puig, Ruta Desai, Zsolt Kira, and Roozbeh Mottaghi. Grounding multimodal llms to embodied agents that ask for help with reinforcement learning. arXiv preprint arXiv:2504.00907, 2025
-
[11]
Imaginenav: Prompting vision- language models as embodied navigator through scene imagination
Xinxin Zhao, Wenzhe Cai, Likun Tang, and Teng Wang. Imaginenav: Prompting vision- language models as embodied navigator through scene imagination. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[12]
Think, act, and ask: Open-world interac- tive personalized robot navigation
Yinpei Dai, Run Peng, Sikai Li, and Joyce Chai. Think, act, and ask: Open-world interac- tive personalized robot navigation. In2024 IEEE international conference on robotics and automation (ICRA), pages 3296–3303. IEEE, 2024
2024
-
[13]
Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms
Yanyuan Qiao, Wenqi Lyu, Hui Wang, Zixu Wang, Zerui Li, Yuan Zhang, Mingkui Tan, and Qi Wu. Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6710–6717. IEEE, 2025
2025
-
[14]
Shen Tan, Dong Zhou, Xiangyu Shao, Junqiao Wang, and Guanghui Sun. Language-conditioned open-vocabulary mobile manipulation with pretrained models.arXiv preprint arXiv:2507.17379, 2025
-
[15]
Affordance rag: Hierar- chical multimodal retrieval with affordance-aware embodied memory for mobile manipulation
Ryosuke Korekata, Quanting Xie, Yonatan Bisk, and Komei Sugiura. Affordance rag: Hierar- chical multimodal retrieval with affordance-aware embodied memory for mobile manipulation. IEEE Robotics and Automation Letters, 11(3):2706–2713, 2026
2026
-
[16]
Bring My Cup! Personalizing Vision-Language-Action Models with Visual Attentive Prompting
Sangoh Lee, Sangwoo Mo, and Wook-Shin Han. Bring my cup! personalizing vision-language- action models with visual attentive prompting.arXiv preprint arXiv:2512.20014, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Instance-aware exploration- verification-exploitation for instance imagegoal navigation
Xiaohan Lei, Min Wang, Wengang Zhou, Li Li, and Houqiang Li. Instance-aware exploration- verification-exploitation for instance imagegoal navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16329–16339, 2024
2024
-
[18]
Personalized instance-based navigation toward user-specific objects in realistic environments
Luca Barsellotti, Roberto Bigazzi, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Personalized instance-based navigation toward user-specific objects in realistic environments. Advances in Neural Information Processing Systems, 37:11228–11250, 2024. 10
2024
-
[19]
Collaborative instance object navigation: Leveraging uncertainty-awareness to minimize human-agent dialogues
Francesco Taioli, Edoardo Zorzi, Gianni Franchi, Alberto Castellini, Alessandro Farinelli, Marco Cristani, and Yiming Wang. Collaborative instance object navigation: Leveraging uncertainty-awareness to minimize human-agent dialogues. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18781–18792, 2025
2025
-
[20]
Navbench: Probing multimodal large language models for embodied navigation
Yanyuan Qiao, Haodong Hong, Wenqi Lyu, Dong An, Siqi Zhang, Yutong Xie, Xinyu Wang, and Qi Wu. Navbench: Probing multimodal large language models for embodied navigation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[21]
MMPB: It’s time for multi-modal personalization
Jaeik Kim, Woojin Kim, Woohyeon Park, and Jaeyoung Do. MMPB: It’s time for multi-modal personalization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026
2026
-
[22]
Mmrc: A large-scale benchmark for understanding multimodal large language model in real-world conversation
Haochen Xue, Feilong Tang, Ming Hu, Yexin Liu, Qidong Huang, Yulong Li, Chengzhi Liu, Zhongxing Xu, Chong Zhang, Chun-Mei Feng, et al. Mmrc: A large-scale benchmark for understanding multimodal large language model in real-world conversation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),...
2025
-
[23]
Yuanchen Bei, Tianxin Wei, Xuying Ning, Yanjun Zhao, Zhining Liu, Xiao Lin, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. Mem-gallery: Benchmarking multimodal long-term conversational memory for mllm agents.arXiv preprint arXiv:2601.03515, 2026
-
[24]
Dannong Xu, Zhongyu Yang, Jun Chen, Yingfang Yuan, Ming Hu, Lei Sun, Luc Van Gool, Danda Pani Paudel, and Chun-Mei Feng. Multihaystack: Benchmarking multimodal retrieval and reasoning over 40k images, videos, and documents.arXiv preprint arXiv:2603.05697, 2026
-
[25]
Baochen Fu, Yuntao Du, Cheng Chang, Baihao Jin, Wenzhi Deng, Muhao Xu, Hongmei Yan, Weiye Song, and Yi Wan. Mmku-bench: A multimodal update benchmark for diverse visual knowledge.arXiv preprint arXiv:2603.15117, 2026
-
[26]
Episodic and semantic memory.Organization of memory, 1(381-403):1, 1972
Endel Tulving et al. Episodic and semantic memory.Organization of memory, 1(381-403):1, 1972
1972
-
[27]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR, 2022
2022
-
[29]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Escapebench: Pushing language models to think outside the box.arXiv e-prints, pages arXiv–2412, 2024
Cheng Qian, Peixuan Han, Qinyu Luo, Bingxiang He, Xiusi Chen, Yuji Zhang, Hongyi Du, Jiarui Yao, Xiaocheng Yang, Denghui Zhang, et al. Escapebench: Pushing language models to think outside the box.arXiv e-prints, pages arXiv–2412, 2024
2024
-
[31]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Robot behavior-tree-based task generation with large language models
Yue Cao and CS Lee. Robot behavior-tree-based task generation with large language models. arXiv preprint arXiv:2302.12927, 2023
-
[33]
Navgpt: Explicit reasoning in vision-and-language navigation with large language models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7641–7649, 2024. 11
2024
-
[34]
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. Progprompt: Generating situated robot task plans using large language models.arXiv preprint arXiv:2209.11302, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Vineet Bhat, Ali Umut Kaypak, Prashanth Krishnamurthy, Ramesh Karri, and Farshad Khorrami. Grounding llms for robot task planning using closed-loop state feedback.arXiv preprint arXiv:2402.08546, 2024
-
[36]
Language models as zero-shot trajectory generators.IEEE Robotics and Automation Letters, 9(7):6728–6735, 2024
Teyun Kwon, Norman Di Palo, and Edward Johns. Language models as zero-shot trajectory generators.IEEE Robotics and Automation Letters, 9(7):6728–6735, 2024
2024
-
[37]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International conference on robotics and automation (ICRA), pages 9493–9500. IEEE, 2023
2023
-
[38]
Guangran Cheng, Chuheng Zhang, Wenzhe Cai, Li Zhao, Changyin Sun, and Jiang Bian. Empowering large language models on robotic manipulation with affordance prompting.arXiv preprint arXiv:2404.11027, 2024
-
[39]
Mapgpt: an autonomous framework for mapping by integrating large language model and cartographic tools.Cartography and Geographic Information Science, 51(6):717–743, 2024
Yifan Zhang, Zhengting He, Jingxuan Li, Jianfeng Lin, Qingfeng Guan, and Wenhao Yu. Mapgpt: an autonomous framework for mapping by integrating large language model and cartographic tools.Cartography and Geographic Information Science, 51(6):717–743, 2024
2024
-
[40]
Vision-and- language navigation with analogical textual descriptions in llms
Yue Zhang, Tianyi Ma, Zun Wang, Yanyuan Qiao, and Parisa Kordjamshidi. Vision-and- language navigation with analogical textual descriptions in llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15028–15036, 2025
2025
-
[41]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Large language models for orchestrating bimanual robots
Kun Chu, Xufeng Zhao, Cornelius Weber, Mengdi Li, Wenhao Lu, and Stefan Wermter. Large language models for orchestrating bimanual robots. In2024 IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids), pages 328–334. IEEE, 2024
2024
-
[43]
Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, and Tong Zhang. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. InForty-second International Conference on Machine Learning, 2025
2025
-
[44]
Anxing Xiao, Nuwan Janaka, Tianrun Hu, Anshul Gupta, Kaixin Li, Cunjun Yu, and David Hsu. Robi butler: Multimodal remote interaction with a household robot assistant.arXiv preprint arXiv:2409.20548, 2024
-
[45]
Flame: Learning to navigate with multimodal llm in urban environments
Yunzhe Xu, Yiyuan Pan, Zhe Liu, and Hesheng Wang. Flame: Learning to navigate with multimodal llm in urban environments. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9005–9013, 2025
2025
-
[46]
Zhenliang Zhang, Yuxi Wang, Hongzhao Xie, Shiyun Zhao, Mingyuan Liu, Yujie Lu, Xinyi He, Zhenku Cheng, and Yujia Peng. Evaluating multimodal large language models with daily composite tasks in home environments.arXiv preprint arXiv:2509.17425, 2025
-
[47]
Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, and Gao Huang. Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024
2024
-
[48]
Yo’llava: Your personalized language and vision assistant.Advances in Neural Information Processing Systems, 37:40913–40951, 2024
Thao Nguyen, Haotian Liu, Yuheng Li, Mu Cai, Utkarsh Ojha, and Yong Jae Lee. Yo’llava: Your personalized language and vision assistant.Advances in Neural Information Processing Systems, 37:40913–40951, 2024. 12
2024
-
[49]
Myvlm: Personalizing vlms for user-specific queries
Yuval Alaluf, Elad Richardson, Sergey Tulyakov, Kfir Aberman, and Daniel Cohen-Or. Myvlm: Personalizing vlms for user-specific queries. InEuropean Conference on Computer Vision, pages 73–91. Springer, 2024
2024
-
[50]
RePIC: Reinforced post-training for personalizing multi-modal language models
Yeongtak Oh, Dohyun Chung, Juhyeon Shin, Sangha Park, Johan Barthelemy, Jisoo Mok, and Sungroh Yoon. RePIC: Reinforced post-training for personalizing multi-modal language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[51]
Rap: Retrieval- augmented personalization for multimodal large language models
Haoran Hao, Jiaming Han, Changsheng Li, Yu-Feng Li, and Xiangyu Yue. Rap: Retrieval- augmented personalization for multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14538–14548, 2025
2025
-
[52]
Training- free personalization via retrieval and reasoning on fingerprints
Deepayan Das, Davide Talon, Yiming Wang, Massimiliano Mancini, and Elisa Ricci. Training- free personalization via retrieval and reasoning on fingerprints. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9683–9692, 2025
2025
-
[53]
Filippo Ziliotto, Jelin Raphael Akkara, Alessandro Daniele, Lamberto Ballan, Luciano Serafini, and Tommaso Campari. Personal: Towards a comprehensive benchmark for personalized embodied agents.arXiv preprint arXiv:2509.19843, 2025
-
[54]
Hongcheng Wang, Jinyu Zhu, and Hao Dong. User-centric object navigation: A benchmark with integrated user habits for personalized embodied object search.arXiv preprint arXiv:2602.06459, 2026
-
[55]
A survey on the memory mechanism of large language model-based agents
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems, 43(6):1–47, 2025
2025
-
[56]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonza- lez. Memgpt: towards llms as operating systems. 2023
2023
-
[57]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Memory os of ai agent
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972– 25981, 2025
2025
-
[59]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents.arXiv preprint arXiv:2601.01885, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory
Lin Long, Yichen He, Wentao Ye, Yiyuan Pan, Yuan Lin, Hang Li, Junbo Zhao, and Wei Li. Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[61]
MemVerse: Multimodal Memory for Lifelong Learning Agents
Junming Liu, Yifei Sun, Weihua Cheng, Haodong Lei, Yirong Chen, Licheng Wen, Xuemeng Yang, Daocheng Fu, Pinlong Cai, Nianchen Deng, et al. Memverse: Multimodal memory for lifelong learning agents.arXiv preprint arXiv:2512.03627, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Dense x retrieval: What retrieval granularity should we use? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15159–15177, 2024
Tong Chen, Hongwei Wang, Sihao Chen, Wenhao Yu, Kaixin Ma, Xinran Zhao, Hongming Zhang, and Dong Yu. Dense x retrieval: What retrieval granularity should we use? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15159–15177, 2024
2024
-
[63]
Exploratory memory-augmented LLM agent via hybrid on- and off-policy optimization
Zeyuan Liu, Jeonghye Kim, Xufang Luo, Dongsheng Li, and Yuqing Yang. Exploratory memory-augmented LLM agent via hybrid on- and off-policy optimization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[64]
M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. InFindings of the association for computational linguistics: ACL 2024, pages 2318–2335, 2024. 13
2024
-
[65]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in neural information processing systems, 37:5285–5307, 2024
Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in neural information processing systems, 37:5285–5307, 2024
2024
-
[66]
Habitat 3.0: A co-habitat for humans, avatars and robots, 2023
Xavi Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Ruslan Partsey, Jimmy Yang, Ruta Desai, Alexander William Clegg, Michal Hlavac, Tiffany Min, Theo Gervet, Vladimír V ondruš, Vincent-Pierre Berges, John Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakr- ishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara Rai...
2023
-
[67]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[68]
Embodied agents meet personalization: Investigating challenges and solutions through the lens of memory utilization
Taeyoon Kwon, Dongwook Choi, Hyojun Kim, Sunghwan Kim, Seungjun Moon, Beong woo Kwak, Kuan-Hao Huang, and Jinyoung Yeo. Embodied agents meet personalization: Investigating challenges and solutions through the lens of memory utilization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[69]
On Evaluation of Embodied Navigation Agents
Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, Vladlen Koltun, Jana Kosecka, Jitendra Malik, Roozbeh Mottaghi, Manolis Savva, et al. On evaluation of embodied navigation agents.arXiv preprint arXiv:1807.06757, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[70]
Now Publishers Inc, 2009
Stephen Robertson and Hugo Zaragoza.The probabilistic relevance framework: BM25 and beyond, volume 4. Now Publishers Inc, 2009
2009
-
[71]
Junyu Feng, Binxiao Xu, Jiayi Chen, Mengyu Dai, Cenyang Wu, Haodong Li, Bohan Zeng, Yunliu Xie, Hao Liang, Ming Lu, et al. M2a: Multimodal memory agent with dual-layer hybrid memory for long-term personalized interactions.arXiv preprint arXiv:2602.07624, 2026. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.