Benchmarking Convolutional, Transformer, Hybrid, and Vision Language Models for Multi Disease Retinal Screening
Pith reviewed 2026-06-29 22:38 UTC · model grok-4.3
The pith
Attention-based and hybrid models lead in multi-disease retinal screening on RFMiD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
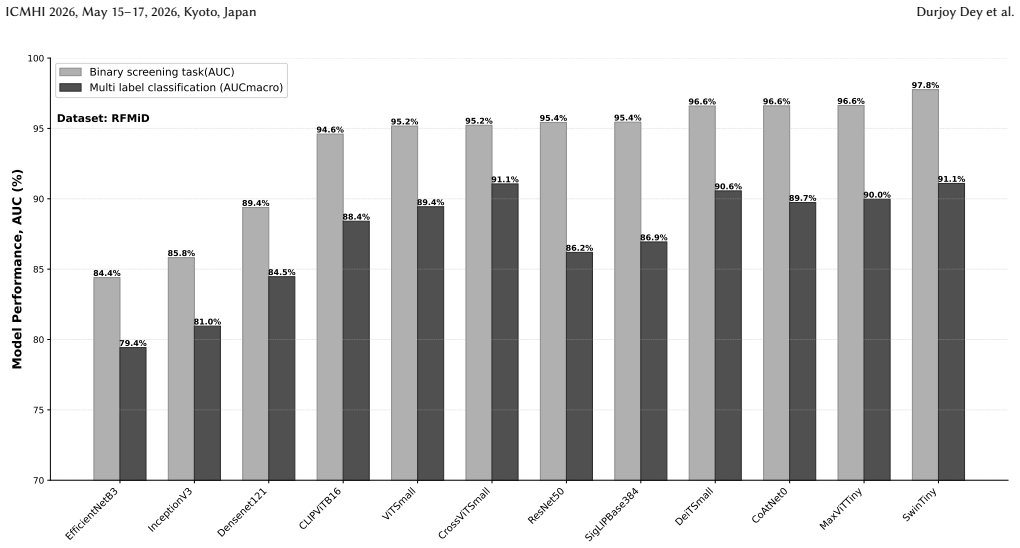
On the RFMiD dataset, every architecture achieves AUC above 84% for binary retinal disease screening, but attention-based models perform best; SwinTiny together with the hybrid CoAtNet0 and MaxViTTiny models produce the strongest binary screening results and also improve macro and micro F1 in the 28-class multi-label task, while vision-language models including CLIP ViT-B/16 and SigLIP-Base384 stay competitive with CNN baselines yet do not exceed the best transformer and hybrid backbones; external validation on Messidor-2 for referable diabetic retinopathy yields AUCs ranging from 66.8% to 84.7% with hybrid and transformer models again showing strong performance.
What carries the argument
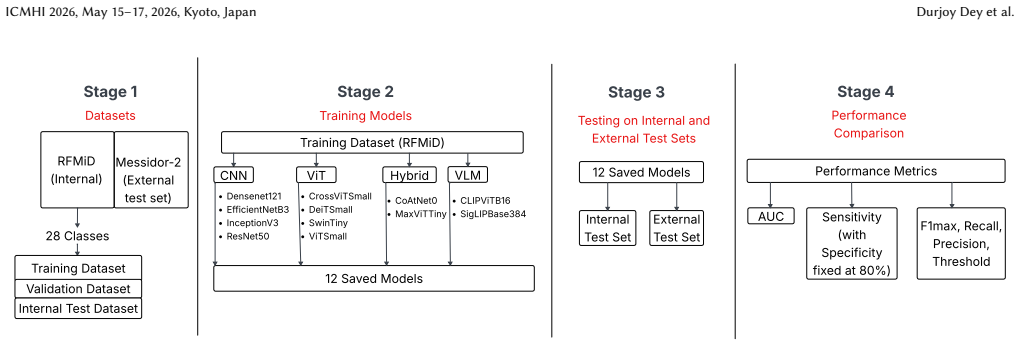
Standardized training, calibration, and evaluation protocol applied uniformly to twelve models across four families on RFMiD binary and multi-label tasks.
If this is right
- All twelve architectures achieve AUC above 84% for binary screening of any retinal disease.
- SwinTiny and the hybrid CoAtNet0 and MaxViTTiny models lead binary screening and raise both macro and micro F1 in the multi-label setting.
- Vision-language models match CNN baselines but do not surpass the top transformer and hybrid backbones.
- External validation on Messidor-2 produces AUC values from 66.8% to 84.7% for referable diabetic retinopathy.
- The results supply a reproducible reference for model selection in multi-disease retinal screening.
Where Pith is reading between the lines
- Clinics developing screening tools may favor hybrid and transformer backbones when domain shift is expected.
- The performance spread across families suggests attention mechanisms help capture patterns across multiple co-occurring diseases.
- Future work could test whether the same ranking holds on additional fundus datasets or with patient-level rather than image-level labels.
- The gap between internal and external AUCs indicates that robustness to domain shift remains an open requirement for deployment.
Load-bearing premise
The standardized training, calibration, and evaluation protocols produce an unbiased comparison across model families without hidden differences in hyperparameter tuning, data augmentation, or implementation details.
What would settle it
A replication that applies the identical protocols yet finds a CNN or vision-language model outperforming SwinTiny, CoAtNet0, and MaxViTTiny on RFMiD binary or multi-label metrics would falsify the reported performance ordering.
Figures
read the original abstract
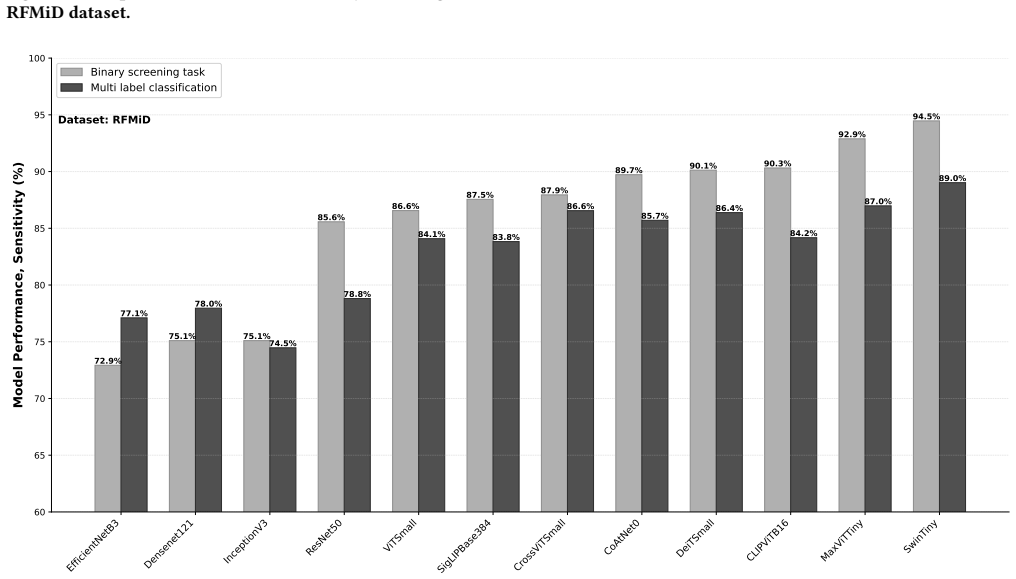
Modern deep learning offers powerful tools for automated retinal screening, but it remains unclear how different visual model families compare in realistic multi-disease settings and under domain shift. In this work, we benchmark twelve architectures across four model families: convolutional neural networks, vision transformers, hybrid CNN-transformer backbones, and vision-language models, using the Retinal Fundus Multi-disease Image Dataset (RFMiD). We evaluate two tasks: binary screening for any retinal disease and multi-label classification across 28 disease classes. Using standardized training, calibration, and evaluation protocols, we report AUC, F1, precision, recall, and sensitivity at a clinically relevant operating point with specificity near 80%. On RFMiD, all architectures perform well on binary screening, with AUC above 84%, but attention-based models perform best. SwinTiny and the hybrid CoAtNet0 and MaxViTTiny models achieve the strongest binary screening results and improve macro and micro F1 in the multi-label setting. Vision-language models, including CLIP ViT-B/16 and SigLIP-Base384, are competitive with CNN baselines but do not surpass the best transformer and hybrid backbones. In external validation on Messidor-2 for referable diabetic retinopathy, AUC ranges from 66.8% to 84.7%, with hybrid and transformer models again showing strong performance. These results provide a reproducible reference for model selection in multi-disease retinal screening and guide future automated screening tools for clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks twelve architectures from four families (CNNs, vision transformers, hybrids, VLMs) on the RFMiD dataset for binary screening (any retinal disease) and multi-label classification across 28 classes, plus external validation on Messidor-2 for referable diabetic retinopathy. Using claimed standardized protocols, it reports AUC >84% for all models on binary screening with attention-based models (SwinTiny, CoAtNet0, MaxViTTiny) strongest, VLMs competitive with CNNs but not superior, and Messidor-2 AUCs from 66.8% to 84.7%.
Significance. If the protocols prove architecture-neutral, the work supplies a useful empirical reference for model selection in multi-disease retinal screening and highlights potential advantages of transformer/hybrid backbones. The external validation component adds modest value for assessing domain shift.
major comments (2)
- [Abstract and Methods] Abstract and Methods section: The central claim that attention-based models outperform others rests on the assertion of 'standardized training, calibration, and evaluation protocols' applied uniformly. However, no details are supplied on hyperparameter selection (e.g., learning rates, schedulers, batch sizes), data augmentation pipelines, or whether per-family tuning was performed. Different families have distinct optimization requirements; without evidence of equal search effort, the reported ranking (SwinTiny/CoAtNet0/MaxViTTiny best) cannot be verified as architecture-driven rather than implementation-driven.
- [Results] Results section: No statistical tests, confidence intervals, or error bars are mentioned for the AUC/F1 rankings or the claim that 'attention-based models perform best.' Given the low-confidence soundness assessment and absence of these, the performance ordering on RFMiD binary and multi-label tasks lacks the quantitative support needed to substantiate the model-family conclusions.
minor comments (1)
- [Methods] The abstract states results at a high level but the manuscript should include explicit data-split descriptions, class imbalance handling, and calibration method (e.g., temperature scaling) to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our benchmarking study. We address each major comment below, clarifying our approach and indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods section: The central claim that attention-based models outperform others rests on the assertion of 'standardized training, calibration, and evaluation protocols' applied uniformly. However, no details are supplied on hyperparameter selection (e.g., learning rates, schedulers, batch sizes), data augmentation pipelines, or whether per-family tuning was performed. Different families have distinct optimization requirements; without evidence of equal search effort, the reported ranking (SwinTiny/CoAtNet0/MaxViTTiny best) cannot be verified as architecture-driven rather than implementation-driven.
Authors: We agree that explicit details on the training protocols strengthen the manuscript. Our study applied identical hyperparameters, data augmentation pipelines, and optimization settings to all twelve models with no per-family hyperparameter search, ensuring the comparison is architecture-driven under a single standardized protocol. We will revise the Methods section to list the specific learning rates, schedulers, batch sizes, and augmentations used. revision: yes
-
Referee: [Results] Results section: No statistical tests, confidence intervals, or error bars are mentioned for the AUC/F1 rankings or the claim that 'attention-based models perform best.' Given the low-confidence soundness assessment and absence of these, the performance ordering on RFMiD binary and multi-label tasks lacks the quantitative support needed to substantiate the model-family conclusions.
Authors: We recognize that statistical support improves the robustness of the reported rankings. The original manuscript presents point estimates; in revision we will add bootstrap confidence intervals for AUC and F1 scores along with pairwise statistical comparisons (e.g., DeLong tests) where feasible to quantify the ordering. revision: yes
Circularity Check
Purely empirical benchmarking with no derivations or self-referential predictions
full rationale
This is a standard empirical comparison paper that trains and evaluates twelve fixed architectures on RFMiD (binary and multi-label) and Messidor-2, reporting AUC/F1/sensitivity at fixed operating points. No equations, fitted parameters, uniqueness theorems, or ansatzes appear; all claims are direct experimental outcomes under a single described protocol. The standardization assumption is a methodological choice open to external replication or criticism but does not create circularity by construction. No load-bearing self-citations or reductions of predictions to inputs exist.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standardized training, calibration, and evaluation protocols produce unbiased comparisons across model families
Reference graph
Works this paper leans on
-
[1]
Andreas Abou Taha, Sebastian Dinesen, Anna Stage Vergmann, and Jakob Graus- lund. 2024. Present and Future Screening Programs for Diabetic Retinopathy: A Narrative Review.International Journal of Retina and Vitreous10, 14 (2024). doi:10.1186/s40942-024-00534-8 Retrieved November 28, 2025
-
[2]
Mohamed Akil, Yaroub Elloumi, and Rostom Kachouri. 2021. Detection of retinal abnormalities in fundus image using CNN deep learning networks.State of the Art in Neural Networks and their Applications(2021). https://api.semanticscholar. org/CorpusID:219027739
2021
-
[3]
Lawrence Carin and Michael J. Pencina. 2018. On Deep Learning for Medical Image Analysis.JAMA320, 11 (2018), 1192–1193. doi:10.1001/jama.2018.13316
-
[4]
H. P. Chan, Ravi K. Samala, Lubomir M. Hadjiiski, and C. Zhou. 2020. Deep Learning in Medical Image Analysis. InAdvances in Experimental Medicine and Biology. Advances in Experimental Medicine and Biology, Vol. 1213. Springer, 3–21. doi:10.1007/978-3-030-33128-3_1 PMCID: PMC7442218
-
[5]
Chun-Fu Richard Chen, Quanfu Fan, and Rameswar Panda. 2021. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 347–356. doi:10.1109/ICCV48922.2021.00041
-
[6]
Joon Yul Choi, Tae Keun Yoo, Jeong Seo, Jiyong Kwak, Terry Um, and Tyler Rim. 2017. Multi-categorical deep learning neural network to classify retinal images: A pilot study employing small database.PLOS ONE12 (11 2017), e0187336. doi:10.1371/journal.pone.0187336
-
[7]
Le, and Mingxing Tan
Zihang Dai, Hanxiao Liu, Quoc V. Le, and Mingxing Tan. 2021. CoAtNet: marrying convolution and attention for all data sizes(NIPS ’21). Curran Associates Inc., Red Hook, NY, USA, Article 303, 13 pages
2021
-
[8]
Etienne Decencière, Xiwei Zhang, Guy Cazuguel, Bruno Laï, Béatrice Cochener, Caroline Trone, Patrick Gain, Jean-Claude Klein, Kristina Dewitte, Gabrielle Molinari, Mathieu Chavent-Fix, Guillaume Bron, Florian Trombert-Paviot, Zineb Laamari-Maleke, Jean-Pierre Massin, Ali Ouedraogo, Romuald Déléchelle, and François Rétout. 2014. Feedback on a publicly dist...
2014
-
[9]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInterna- tional Conference on Learning Representations. https:...
2021
-
[10]
Tom Fawcett. 2006. An introduction to ROC analysis.Pattern Recognition Letters 27, 8 (2006), 861–874. doi:10.1016/j.patrec.2005.10.010
-
[11]
Jocelyn Hui Lin Goh, Elroy Ang, Sahana Srinivasan, Xiaofeng Lei, Johnathan Loh, Ten Cheer Quek, Cancan Xue, Xinxing Xu, Yong Liu, Ching-Yu Cheng, Jagath C. Rajapakse, and Yih-Chung Tham. 2024. Comparative Analysis of Vision Transformers and Conventional Convolutional Neural Networks in Detecting Referable Diabetic Retinopathy.Ophthalmology Science4, 6 (20...
-
[12]
Balla Goutam, Mohammad Farukh Hashmi, Zong Woo Geem, and Neeraj Dhanraj Bokde. 2022. A Comprehensive Review of Deep Learning Strategies in Retinal Disease Diagnosis Using Fundus Images.IEEE Access10 (2022), 57796–57823. doi:10.1109/ACCESS.2022.3178372
-
[13]
Varun Gulshan, Lily Peng, Marc Coram, Martin C. Stumpe, Derek Wu, Arunacha- lam Narayanaswamy, Subhashini Venugopalan, Kasumi Widner, Tom Madams, Jorge Cuadros, Ruiyu Kim, Rajiv Raman, Philip C. Nelson, Jessica L. Mega, and Dale R. Webster. 2016. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundu...
-
[14]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770–778. doi:10.1109/CVPR.2016.90
-
[15]
Weinberger
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger
-
[16]
Densely Connected Convolutional Networks. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2261–2269. doi:10.1109/CVPR. 2017.243
-
[17]
Seunghoon Lee, Seunghyun Lee, and Byung Cheol Song. 2022. Improving Vision Transformers to Learn Small-Size Dataset From Scratch.IEEE Access10 (2022), 123212–123224. doi:10.1109/ACCESS.2022.3224044
-
[18]
Online learning: A comprehensive survey
Justis I. Lim, Aleksandra V. Rachitskaya, John A. Hallak, Sohaib Gholami, and M. Nazmul Alam. 2024. Artificial Intelligence for Retinal Diseases.Asia-Pacific Journal of Ophthalmology (Philadelphia, Pa.)13, 4 (2024), 100096. doi:10.1016/j. apjo.2024.100096
work page doi:10.1016/j 2024
-
[19]
L. B. Lisha and S. V. N. S. R. 2025. Retinal image based disease classification using hybrid deep architecture with improved image features.International Ophthalmology45 (2025), 324. doi:10.1007/s10792-025-03660-w
-
[20]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In2021 IEEE/CVF International Conference on Computer Vision (ICCV). 9992–10002. doi:10.1109/ICCV48922.2021.00986
-
[21]
Stewart Muchuchuti and Serestina Viriri. 2023. Retinal Disease Detection Using Deep Learning Techniques: A Comprehensive Review.Journal of Imaging9, 4 (2023), 84. doi:10.3390/jimaging9040084
-
[22]
World Health Organization. 2023. Blindness and vision impairment. Fact sheet. https://www.who.int/news-room/fact-sheets/detail/blindness-and-visual- impairment World Health Organization. Retrieved November 28, 2025
2023
-
[23]
Samiksha Pachade, Prasanna Porwal, Dhanshree Thulkar, Manesh Kokare, Girish Deshmukh, Vivek Sahasrabuddhe, Luca Giancardo, Gwenole Quellec, and Fabrice Meriaudeau. 2021. Retinal Fundus Multi-Disease Image Dataset (RFMiD): A Dataset for Multi-Disease Detection Research.Data6 (02 2021), 14. doi:10.3390/ data6020014
2021
-
[24]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gre- gory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Rai- son, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, ...
2019
-
[25]
David M. W. Powers. 2011. Evaluation: From Precision, Recall and F-measure to ROC, Informedness, Markedness and Correlation.Journal of Machine Learning Technologies2, 1 (2011), 37–63
2011
-
[26]
Gwenolé Quellec, Mathieu Lamard, Pierre-Henri Conze, Pascale Massin, and Béatrice Cochener. 2020. Automatic detection of rare pathologies in fundus photographs using few-shot learning.Medical Image Analysis61 (2020), 101660. doi:10.1016/j.media.2020.101660
-
[27]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning. https://api.semanticscholar.org/CorpusID:231591445
2021
-
[28]
Francesco Sacchini, Stefano Mancin, Giovanni Cangelosi, Sara Morales Palomares, Gabriele Caggianelli, Francesco Gravante, and Fabio Petrelli. 2025. The role of artificial intelligence in diabetic retinopathy screening in type 1 diabetes: A systematic review.Journal of Diabetes and its Complications39, 10 (2025), 109139. doi:10.1016/j.jdiacomp.2025.109139
-
[29]
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and ZB Wojna
-
[30]
doi:10.1109/ CVPR.2016.308
Rethinking the Inception Architecture for Computer Vision. doi:10.1109/ CVPR.2016.308
2016
-
[31]
Mingxing Tan and Quoc Le. 2019. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 6105–
2019
-
[32]
https://proceedings.mlr.press/v97/tan19a.html
-
[33]
Daniel Shu Wei Ting, Carol Yim lui Cheung, Gilbert Lim, Gavin Siew Wei Tan, Nguyen Duc Quang, Alfred Tau Liang Gan, Haslina Hamzah, Renata García-Franco, Ian Yew San Yeo, Shu Yen Lee, Edmund Yick Mun Wong, Charu- mathi Sabanayagam, Mani Baskaran, Farah Ibrahim, Ngiap Chuan Tan, Eric An- drew Finkelstein, Ecosse Luc Lamoureux, Ian Y Wong, Neil M. Bressler,...
-
[34]
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. 2021. Training data-efficient image transformers and distillation through attention. InProceedings of the 38th International Confer- ence on Machine Learning (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, ...
2021
-
[35]
Zhengzhong Tu, Hossein Talebi, Han Zhang, Fengyang Zhang, Yinxiao Zhang, Peyman Milanfar Li, Xiu Yang, Feng Yang, Bo Dai, Deqing Sun, and et al. 2022. MaxViT: Multi-axis Vision Transformer. InComputer Vision – ECCV 2022 (Lecture Notes in Computer Science, Vol. 13684), Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner...
-
[36]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid Loss for Language Image Pre-Training. In2023 IEEE/CVF International Conference on Computer Vision (ICCV). 11941–11952. doi:10.1109/ICCV51070. 2023.01100 ICMHI 2026, May 15–17, 2026, Kyoto, Japan Durjoy Dey et al
-
[37]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. 2024. Vision-Language Models for Vision Tasks: A Survey.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 8 (2024), 5625–5644. doi:10.1109/TPAMI.2024.3369699
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.