MULTISEISMO: A Multimodal Seismic Dataset and Model for Cross-Modal Seismic Understanding
Pith reviewed 2026-06-29 22:20 UTC · model grok-4.3
The pith
MultiSeismo dataset and SeisModal model show general multimodal models struggle with seismic time-series data while domain adaptations succeed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
General-purpose multimodal models encounter substantial difficulties when required to process time-series waveform data for seismic events, yet SeisModal, produced by augmenting Unified IO 2 with a specialized timeseries encoder and supervised training on the MISCE instruction set derived from MultiSeismo, attains superior results on a spectrum of seismic multimodal reasoning tasks that range from information retrieval to cross-modal analysis.
What carries the argument
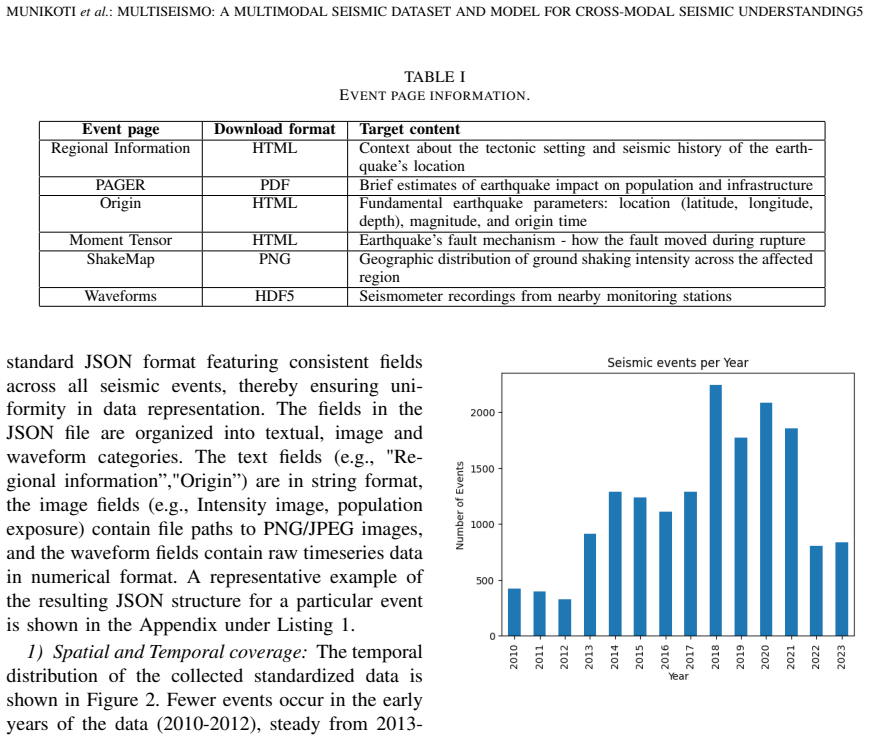
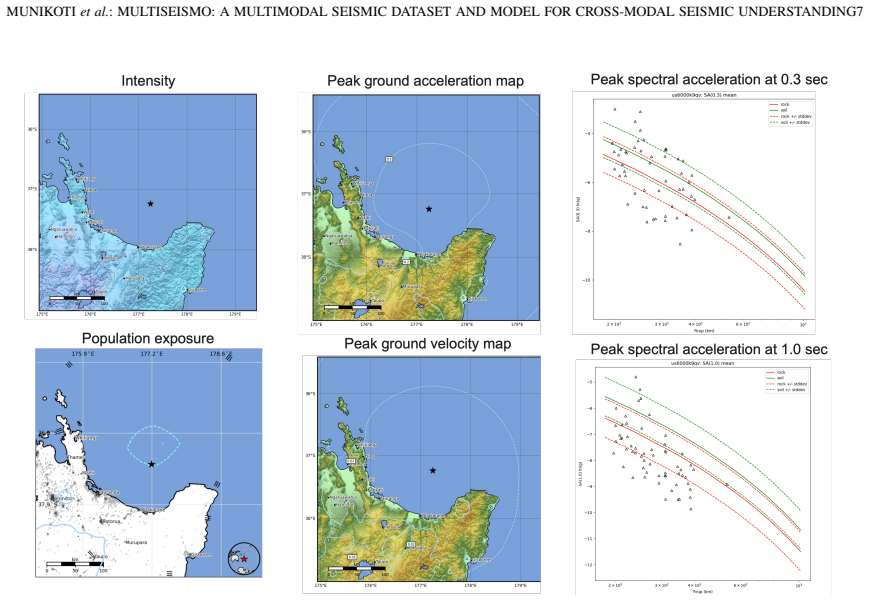
The MultiSeismo dataset, which packages waveform recordings, intensity maps, population exposure visualizations, and textual metadata for each event inside a uniform JSON structure, together with the MISCE instruction set that enables supervised fine-tuning of models on seismic reasoning.
If this is right
- General multimodal models will continue to underperform on scientific data that contains prominent time-series components unless they receive domain-specific encoders and training.
- SeisModal can be applied directly to tasks that require joint reasoning over seismic waveforms, geographic imagery, and event metadata.
- MultiSeismo supplies a concrete, reusable benchmark that future multimodal research in seismology can adopt for standardized evaluation.
- The pattern of inserting a timeseries encoder and performing targeted fine-tuning constitutes a repeatable route for adapting general models to other time-series-rich scientific domains.
Where Pith is reading between the lines
- If geographic or temporal biases exist in how the 13-year station records were chosen, the measured performance gap between general and domain-adapted models may shrink or reverse on differently sampled events.
- The same encoder-addition technique could be applied to other base multimodal models beyond the one tested here to check whether the gain is architecture-specific.
- Analogous multimodal instruction sets and datasets could be built for adjacent fields that combine time series with imagery and text, such as atmospheric or oceanographic monitoring.
Load-bearing premise
The MultiSeismo collection and MISCE instructions constitute an unbiased and representative benchmark that supports fair performance comparisons between unmodified general multimodal models and domain-adapted ones.
What would settle it
An experiment in which an unmodified general multimodal model, without any added timeseries encoder or MISCE fine-tuning, reaches accuracy scores equal to or higher than SeisModal across the MultiSeismo evaluation tasks would falsify the claim that domain-specific adaptations are required.
Figures
read the original abstract
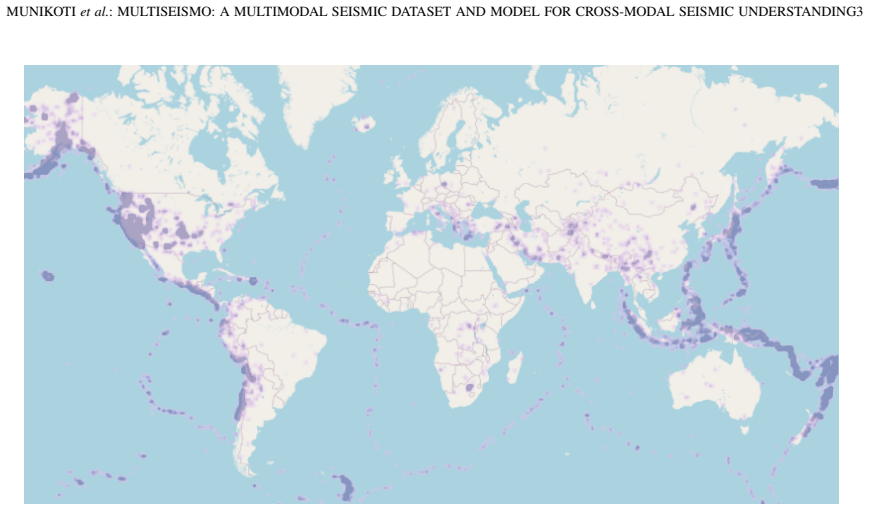
The application of generalist multimodal models (GMMs) to specialized scientific domains remains limited due to the scarcity of comprehensive domain-specific datasets that integrate multiple data modalities beyond text and images. In seismology, understanding earthquake phenomena requires the synthesis of timeseries waveform data, geographical imagery, and contextual metadata, a multimodal integration absent in existing seismic datasets. We present MultiSeismo, a large scale structured multimodal seismic dataset, comprising over 16K seismic events spanning 13 years (2010 to 2023) across diverse geographical regions. Each event data integrates waveform recordings from global station networks, intensity maps, population exposure visualizations, and a comprehensive textual description within a standardized JSON format. We additionally develop MISCE, a multimodal instruction set on top of raw data to enable supervised training and evaluation of GMMs on seismic reasoning tasks ranging from basic information retrieval to complex cross modal analysis. We leverage MISCE to finetune an existing multimodal model (Unified IO 2) enhanced with a specialized timeseries encoder, which yields SeisModal, the first domain specific multimodal model for comprehensive seismic analysis. Evaluation of state of the art multimodal models on MultiSeismo reveals significant challenges, particularly with time-series data processing for general purpose models, while demonstrating SeisModal's superior performance on seismic multimodal reasoning tasks. These results prove that MultiSeismo provides a rigorous benchmark for future multimodal research in seismology and validate the success of our domain specific architectural adaptations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MultiSeismo, a multimodal seismic dataset of over 16K events (2010-2023) integrating waveform recordings, intensity maps, population visualizations, and textual descriptions in JSON format, along with the MISCE instruction set for supervised training and evaluation on tasks from information retrieval to cross-modal analysis. The authors fine-tune Unified IO 2 augmented with a timeseries encoder to produce SeisModal and claim that evaluations reveal significant challenges for general multimodal models (especially time-series processing) while SeisModal achieves superior performance on seismic multimodal reasoning, establishing MultiSeismo as a rigorous benchmark.
Significance. If the dataset proves representative and the performance claims are backed by quantitative metrics and baselines, the work would supply a valuable new resource for multimodal AI in seismology, filling a gap in domain-specific multimodal datasets and illustrating the benefits of targeted architectural adaptations for time-series data.
major comments (2)
- [Dataset construction] Dataset construction section: no event selection criteria, sampling strategy, or comparison against reference catalogs (USGS/ISC) are provided to confirm absence of systematic biases in magnitude, location, station coverage, or intensity; this directly undermines the claim that MultiSeismo enables fair comparison of generalist versus domain-adapted models.
- [Evaluation] Evaluation section: the abstract and manuscript supply no quantitative metrics, baseline comparisons, evaluation protocols, or error analysis to support assertions of SeisModal superiority and general-model challenges; without these the central performance claims cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate the suggested revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: no event selection criteria, sampling strategy, or comparison against reference catalogs (USGS/ISC) are provided to confirm absence of systematic biases in magnitude, location, station coverage, or intensity; this directly undermines the claim that MultiSeismo enables fair comparison of generalist versus domain-adapted models.
Authors: We agree that the manuscript currently lacks explicit details on these aspects of dataset construction. In the revised version, we will add a dedicated subsection that specifies the event selection criteria (including magnitude thresholds and regional coverage), the sampling strategy used to assemble the 16K events from 2010-2023, and direct statistical comparisons against USGS and ISC reference catalogs for magnitude, location, station coverage, and intensity distributions. These additions will support the representativeness claim and enable fair model comparisons. revision: yes
-
Referee: [Evaluation] Evaluation section: the abstract and manuscript supply no quantitative metrics, baseline comparisons, evaluation protocols, or error analysis to support assertions of SeisModal superiority and general-model challenges; without these the central performance claims cannot be assessed.
Authors: We acknowledge that the current manuscript provides only summary statements about evaluation outcomes without the supporting quantitative details. In the revision, we will expand the evaluation section to report specific metrics (e.g., accuracy and F1 scores across MISCE tasks), explicit baseline comparisons (including unmodified Unified IO 2 and other multimodal models), full evaluation protocols and data splits, and an error analysis focused on time-series processing difficulties. This will allow proper assessment of the performance claims. revision: yes
Circularity Check
No circularity: new dataset and model introduced without self-referential reductions
full rationale
The paper presents a newly collected MultiSeismo dataset of 16K events and the derived MISCE instruction set, then finetunes Unified IO 2 into SeisModal for evaluation on the same data. No equations, fitted parameters, or predictions are defined in terms of themselves; no self-citations are invoked as load-bearing uniqueness theorems or ansatzes; the central benchmark claim rests on external data collection rather than renaming or re-deriving prior author results. The derivation chain is therefore self-contained against the new artifacts.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generalist multimodal ai: A review of architectures, challenges and opportunities,
S. Munikoti, I. Stewart, S. Horawalavithana, H. Kvinge, T. Emerson, S. Thompson, and K. Pazdernik, “Generalist multimodal ai: A review of architectures, challenges and opportunities,”Neurocomputing, p. 132933, 2026
2026
-
[2]
Seisbenchâ ˘AˇTa toolbox for machine learning in seismology,
J. Woollam, J. Münchmeyer, F. Tilmann, A. Rietbrock, D. Lange, T. Bornstein, T. Diehl, C. Giunchi, F. Haslinger, D. Jozinovi ´cet al., “Seisbenchâ ˘AˇTa toolbox for machine learning in seismology,”Seismological Society of America, vol. 93, no. 3, pp. 1695–1709, 2022
2022
-
[3]
Stanford earthquake dataset (stead): A global data set of seismic signals for ai,
S. M. Mousavi, Y . Sheng, W. Zhu, and G. C. Beroza, “Stanford earthquake dataset (stead): A global data set of seismic signals for ai,”IEEE Access, 2019
2019
-
[4]
X. Wang, F. Liu, R. Su, Z. Wang, L. Fang, L. Zhou, L. Bai, and W. Ouyang, “SeisMoLLM: Advancing seismic monitoring via cross-modal transfer with pre-trained large language model,”arXiv preprint arXiv:2502.19960, 2025
-
[5]
ShakeMap: Near real-time maps of earthquake shaking,
U.S. Geological Survey, “ShakeMap: Near real-time maps of earthquake shaking,” https://earthquake.usgs.gov/data/ shakemap/, 2025, accessed: November 26, 2025
2025
-
[6]
Unified-io 2: Scaling au- toregressive multimodal models with vision language audio and action,
J. Lu, C. Clark, S. Lee, Z. Zhang, S. Khosla, R. Marten, D. Hoiem, and A. Kembhavi, “Unified-io 2: Scaling au- toregressive multimodal models with vision language audio and action,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 439–26 455. MUNIKOTIet al.: MULTISEISMO: A MULTIMODAL SEISMIC DATASET AND MOD...
2024
-
[7]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V . Chaudhary, C. Chenet al., “Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of- loras,”arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Instance–the italian seismic dataset for machine learning,
A. Michelini, S. Cianetti, S. Gaviano, C. Giunchi, D. Jozi- novi´c, and V . Lauciani, “Instance–the italian seismic dataset for machine learning,”Earth System Science Data, vol. 13, no. 12, pp. 5509–5544, 2021
2021
-
[9]
National earthquake information center systems overview and integration,
M. R. Guy, J. M. Patton, J. Fee, M. Hearne, E. Mar- tinez, D. Ketchum, C. Worden, V . Quitoriano, E. Hunter, G. Smoczyket al., “National earthquake information center systems overview and integration,” US Geological Survey, Tech. Rep., 2015
2015
-
[10]
Which picker fits my data? a quanti- tative evaluation of deep learning based seismic pickers,
J. Münchmeyer, J. Woollam, A. Rietbrock, F. Tilmann, D. Lange, T. Bornstein, T. Diehl, C. Giunchi, F. Haslinger, D. Jozinovi ´cet al., “Which picker fits my data? a quanti- tative evaluation of deep learning based seismic pickers,” Journal of Geophysical Research: Solid Earth, vol. 127, no. 1, p. e2021JB023499, 2022
2022
-
[11]
Loc- flow: An end-to-end machine learning-based high-precision earthquake location workflow,
M. Zhang, M. Liu, T. Feng, R. Wang, and W. Zhu, “Loc- flow: An end-to-end machine learning-based high-precision earthquake location workflow,”Seismological Society of America, vol. 93, no. 5, pp. 2426–2438, 2022
2022
-
[12]
Seismic arrival-time picking on distributed acoustic sens- ing data using semi-supervised learning,
W. Zhu, E. Biondi, J. Li, J. Yin, Z. E. Ross, and Z. Zhan, “Seismic arrival-time picking on distributed acoustic sens- ing data using semi-supervised learning,”Nature Commu- nications, vol. 14, no. 1, p. 8192, 2023
2023
-
[13]
Gemini and physical world: large language models can estimate the intensity of earthquake shaking from multimodal social media posts,
S. M. Mousavi, M. Stogaitis, T. Gadh, R. M. Allen, A. Barski, R. Bosch, P. Robertson, Y . Cho, N. Thiru- verahan, and A. Raj, “Gemini and physical world: large language models can estimate the intensity of earthquake shaking from multimodal social media posts,”Geophysical Journal International, vol. 240, no. 2, pp. 1281–1294, 2025
2025
-
[14]
Onellm: one framework to align all modalities with language. arxiv,
J. Han, K. Gong, Y . Zhang, J. Wang, K. Zhang, D. Lin, Y . Qiao, P. Gao, and X. Yue, “Onellm: one framework to align all modalities with language. arxiv,”Preprint posted online on December, vol. 6, 2023
2023
-
[15]
Next-gpt: Any-to-any multimodal llm,
S. Wu, H. Fei, L. Qu, W. Ji, and T.-S. Chua, “Next-gpt: Any-to-any multimodal llm,” inForty-first International Conference on Machine Learning, 2024
2024
-
[16]
M3SciQA: A multi-modal multi-document scientific QA benchmark for evaluating foundation models,
C. Li, Z. Shangguan, Y . Zhao, D. Li, Y . Liu, and A. Cohan, “M3SciQA: A multi-modal multi-document scientific QA benchmark for evaluating foundation models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, p...
2024
-
[17]
Learn to explain: Multimodal reasoning via thought chains for sci- ence question answering,
P. Lu, S. Mishra, T. Xia, L. Qiu, K.-W. Chang, S.-C. Zhu, O. Tafjord, P. Clark, and A. Kalyan, “Learn to explain: Multimodal reasoning via thought chains for sci- ence question answering,”Advances in Neural Information Processing Systems, vol. 35, pp. 2507–2521, 2022
2022
-
[18]
Multimodal large language models for medicine: A comprehensive survey,
J. Ye and H. Tang, “Multimodal large language models for medicine: A comprehensive survey,”arXiv preprint arXiv:2504.21051, 2025
-
[19]
J. Audenaert, M. Bowles, B. M. Boyd, D. Chemaly, B. Cherinka, I. Ciuc ˘a, M. Cranmer, A. Do, M. Grayling, E. E. Hayeset al., “The multimodal universe: enabling large-scale machine learning with 100tb of astronomical scientific data,”arXiv preprint arXiv:2412.02527, 2024
-
[20]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Panet al., “Time-llm: Time series forecasting by reprogramming large language models,”arXiv preprint arXiv:2310.01728, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Time-vlm: Exploring multimodal vision-language models for augmented time series forecasting, 2025
S. Zhong, W. Ruan, M. Jin, H. Li, Q. Wen, and Y . Liang, “Time-vlm: Exploring multimodal vision-language models for augmented time series forecasting,”arXiv preprint arXiv:2502.04395, 2025
-
[22]
Plots unlock time-series un- derstanding in multimodal models,
M. Daswani, M. M. Bellaiche, M. Wilson, D. Ivanov, M. Papkov, E. Schnider, J. Tang, K. Lamerigts, G. Botea, M. A. Sanchezet al., “Plots unlock time-series un- derstanding in multimodal models,”arXiv preprint arXiv:2410.02637, 2024
-
[23]
Wilber3: Interactive event search and data retrieval,
IRIS Data Management Center, “Wilber3: Interactive event search and data retrieval,” https://ds.iris.edu/wilber3/find_ event, 2025, accessed: November 26, 2025
2025
-
[24]
Chronos: Learning the language of time series,
A. F. Ansari, L. Stella, A. C. Turkmen, X. Zhang, P. Mer- cado, H. Shen, O. Shchur, S. S. Rangapuram, S. P. Arango, S. Kapooret al., “Chronos: Learning the language of time series,”Transactions on Machine Learning Research, 2024
2024
-
[25]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” inInternational conference on ma- chine learning. PmLR, 2021, pp. 8748–8763
2021
-
[26]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 15 180–15 190. MUNIKOTIet al.: MULTISEISMO: A MULTIMODAL SEISMIC DATASET AND MODEL FOR CROSS-MODAL SEISMIC UNDERSTANDING13 APPEN...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.