Closing the Loop in Teleoperation: Episode-Level Data Quality Assessment and Feedback for High-Quality Demonstration Collection
Pith reviewed 2026-06-29 21:06 UTC · model grok-4.3
The pith
Immediate post-episode feedback from task progress and robot telemetry helps novice operators produce higher-quality demonstrations faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
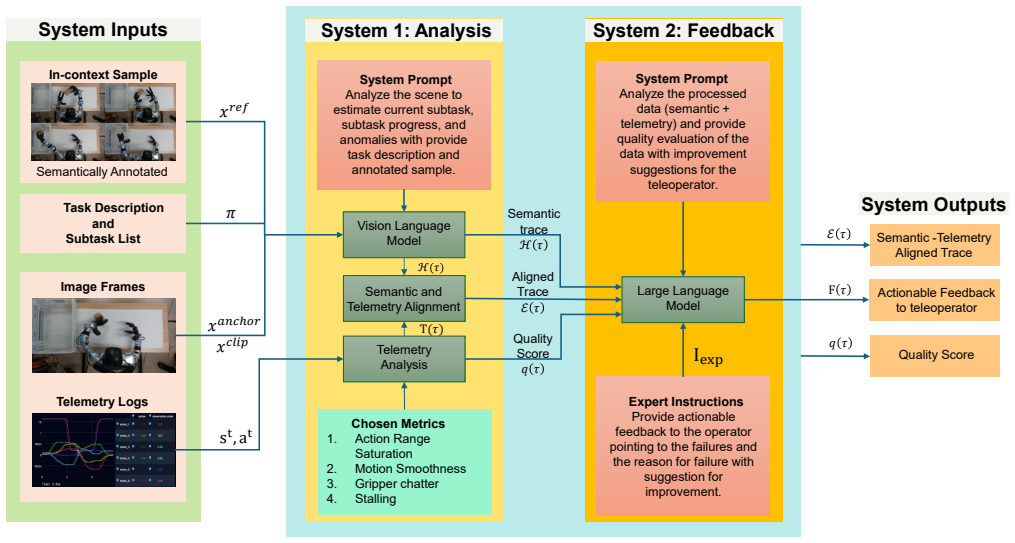
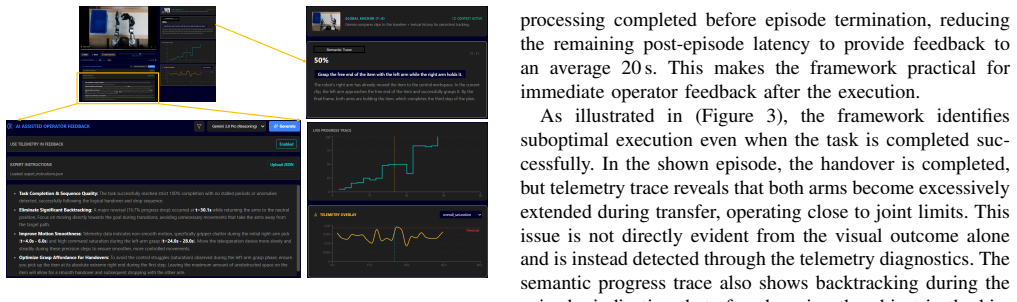
The DQAF framework closes the loop in teleoperation by extracting quality signals from semantic task progress and robot telemetry, converting them into actionable natural-language feedback that identifies why an episode is suboptimal and what behaviors to correct, enabling novice operators to reach higher-quality demonstrations sooner than with success-or-failure signals alone.
What carries the argument
The DQAF framework, which processes semantic task progress and robot telemetry to produce episode-level quality assessments and natural-language feedback on suboptimality.
If this is right
- Novice operators who receive the automated feedback reach higher-quality demonstrations in fewer episodes than those who do not.
- The framework produces rejection reasons and improvement suggestions comparable to those from a human reviewer during dataset curation.
- Providing explanatory rather than binary feedback reduces the number of task-successful but inefficient episodes collected for robot learning.
- Immediate post-episode guidance accelerates the rate at which demonstration quality improves across multiple manipulation tasks.
Where Pith is reading between the lines
- The same signal extraction approach could be applied to automatically score and prioritize episodes before they enter large training datasets.
- Integrating the feedback into a real-time display during the episode rather than only after completion might produce even faster quality gains.
- The quality signals could serve as weights or filters when mixing teleoperated data with other sources in imitation learning pipelines.
Load-bearing premise
The chosen signals of sub-task progress, motion smoothness, stalls, and kinematic limits are sufficient to identify behaviors that affect downstream robot learning performance.
What would settle it
A controlled comparison in which robots trained on demonstrations collected with the feedback system show no improvement or slower improvement in task performance than robots trained on demonstrations collected without the feedback.
Figures


read the original abstract
Industrial automation is at a pivotal moment, as Physical AI is driving a transition from rigid, hand-engineered automation systems toward more flexible and adaptive systems. This shift has created a growing demand for large-scale, real-world robot demonstration data, making teleoperation an increasingly important mechanism for data collection. However, high-quality teleoperated demonstrations remain difficult to obtain in practice, as novice operators often produce episodes that are task-successful but suboptimal for downstream use due to inefficient motion, repeated corrections, or operation near robot joint limits. We present a Data Quality Assessment and Feedback (DQAF) framework that closes the loop in teleoperation by providing immediate post-episode feedback grounded in semantic task progress and robot telemetry. The framework extracts quality relevant signals such as sub-task progress, motion smoothness, stalls, kinematic limits and converts them into structured quality assessments and actionable natural-language feedback. Unlike binary success or failure feedback, the proposed system explains why an episode is suboptimal and highlights specific behaviors to correct in the next trial. We evaluate the framework through a diagnostic validation study and a pilot user study. In the validation study, the system is compared with a human reviewer during dataset curation, producing rejection reasons and actionable feedback for improvement. In the pilot study with three novice operators across two manipulation tasks, the operator who received the systems immediate, automated post-episode feedback improved faster than those who did not, producing higher-quality demonstrations sooner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Data Quality Assessment and Feedback (DQAF) framework for teleoperated robot demonstration collection. The framework analyzes episodes using signals like sub-task progress, motion smoothness, stalls, and kinematic limits derived from semantic task progress and robot telemetry to generate structured quality assessments and natural-language feedback. It is evaluated in a diagnostic validation study against human reviewers and a pilot user study with three novice operators on two manipulation tasks, where the operator receiving immediate automated feedback reportedly improved faster in producing higher-quality demonstrations.
Significance. If validated more robustly, the DQAF framework could significantly improve the efficiency of collecting high-quality teleoperation data for robot learning by providing actionable, episode-level feedback beyond binary success signals. This addresses a practical bottleneck in scaling Physical AI systems. The multi-signal approach grounded in both task semantics and telemetry is a positive aspect, though the current pilot study limits the strength of the empirical claims.
major comments (2)
- [Pilot User Study] Pilot User Study section: The central empirical claim—that the operator receiving DQAF feedback improved faster than the two without—is based on N=3 novice operators across two tasks. No baseline skill assessment, randomization procedure, or statistical tests are reported, rendering the observed difference indistinguishable from individual operator variability. This undermines the attribution of faster improvement to the feedback system.
- [Evaluation] Evaluation section: The abstract and evaluation sections provide no quantitative metrics, effect sizes, or validation of the quality signals against downstream policy learning performance, despite the framework's goal of producing demonstrations better suited for robot learning.
minor comments (1)
- [Abstract] The abstract mentions 'producing higher-quality demonstrations sooner' but supplies no specific metrics or timelines to support this.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our pilot work. We address each major comment below and will revise the manuscript accordingly to better contextualize the empirical results.
read point-by-point responses
-
Referee: [Pilot User Study] Pilot User Study section: The central empirical claim—that the operator receiving DQAF feedback improved faster than the two without—is based on N=3 novice operators across two tasks. No baseline skill assessment, randomization procedure, or statistical tests are reported, rendering the observed difference indistinguishable from individual operator variability. This undermines the attribution of faster improvement to the feedback system.
Authors: We agree that the pilot user study (N=3) lacks baseline assessments, randomization, and statistical analysis, making it impossible to attribute differences solely to the feedback. The manuscript already frames this as a pilot study intended to demonstrate feasibility rather than provide conclusive evidence. We will revise the Pilot User Study section and abstract to explicitly state these limitations, remove any implication of causal attribution, and emphasize that results are suggestive only. This addresses the concern without requiring new data collection. revision: yes
-
Referee: [Evaluation] Evaluation section: The abstract and evaluation sections provide no quantitative metrics, effect sizes, or validation of the quality signals against downstream policy learning performance, despite the framework's goal of producing demonstrations better suited for robot learning.
Authors: The current evaluation prioritizes direct validation of the quality signals against human reviewers (diagnostic study) and observable operator improvement (pilot). We acknowledge the absence of quantitative metrics, effect sizes, or downstream policy learning validation, which is a genuine limitation given the stated goal. We will add a dedicated Limitations and Future Work subsection that explicitly notes this gap and outlines planned experiments to measure impact on learned policies (e.g., success rates and sample efficiency). No new experiments can be added at this stage, but the revision will strengthen the framing. revision: partial
Circularity Check
No circularity: descriptive framework and empirical pilot with no derivations or self-referential predictions
full rationale
The paper introduces a DQAF framework for post-episode feedback based on semantic task progress and robot telemetry signals (sub-task progress, motion smoothness, stalls, kinematic limits). It reports a diagnostic validation study and a pilot user study with N=3 operators. No equations, fitted parameters, predictions, or derivation chains appear in the abstract or described content. Central claims rest on observed performance differences in the pilot, not on any reduction to inputs by construction, self-citation load-bearing premises, or renamed known results. The work is self-contained as an applied system description plus small-scale empirical evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim et al., “OpenVLA: An Open-Source Vision-Language- Action Model,” arXiv preprint arXiv:2406.09246, 2024.https:// arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, Johan, et al. ”Gr00t n1: An open foundation model for generalist humanoid robots.” arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black et al., “π 0: A Vision-Language-Action Flow Model for Gen- eral Robot Control,” arXiv:2410.24164, 2024.https://arxiv. org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence et al., “π 0.5: A Vision-Language-Action Model with Open-World Generalization,” arXiv:2504.16054, 2025.https: //arxiv.org/abs/2504.16054
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Li, Haozhuo, Yuchen Cui, and Dorsa Sadigh. ”How to train your robots? the impact of demonstration modality on imitation learning.” 2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025.https://arxiv.org/abs/2503.07017
-
[7]
How Can Everyday Users Efficiently Teach Robots by Demonstration?,
M. Sakr et al., “How Can Everyday Users Efficiently Teach Robots by Demonstration?,”ACM Transactions on Human-Robot Interaction, vol. 14, no. 4, pp. 1–22, 2025.https://arxiv.org/abs/2310. 13083
2025
-
[8]
Aoki, Jun, and Shunki Itadera. ”A User Study on the Suitability of Teleoperation Interfaces for Primitive Manipulation Tasks.” arXiv preprint arXiv:2603.00020 (2026).https://arxiv.org/abs/ 2603.00020
-
[9]
DataMIL: Selecting Data for Robot Imitation Learning with Datamodels
H. Tugal et al., “Operator Expertise in Bilateral Teleoperation,”Elec- tronics, 2025.https://arxiv.org/html/2505.09603v1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Orthographic Vision-based Interface for Robot Arm Teleoperation,
W. Uddin et al., “Orthographic Vision-based Interface for Robot Arm Teleoperation,” 2018.https://robin-lab.cs.utexas.edu/ datamodels4imitation/
2018
-
[11]
Teleoperation and Visualization Interfaces for Remote Intervention in Space,
P. Kazanzides et al., “Teleoperation and Visualization Interfaces for Remote Intervention in Space,” NASA NTRS, 2021.https:// openreview.net/forum?id=AcTsKglDdh
2021
-
[12]
Akgun, Baris, et al. ”Trajectories and keyframes for kinesthetic teaching: A human-robot interaction perspective.” Proceedings of the seventh annual ACM/IEEE international conference on Human-Robot Interaction. 2012
2012
-
[13]
Fang, Haonan, et al. ”Effects of interface design and spatial abil- ity on teleoperation cognitive load and task performance.” Dis- plays 87 (2025): 102977.https://www.sciencedirect.com/ science/article/abs/pii/S0141938225000149
2025
-
[14]
Learning to Look Around: Enhancing Teleopera- tion with a Human-like Actuated Neck,
B. Sen et al., “Learning to Look Around: Enhancing Teleopera- tion with a Human-like Actuated Neck,” arXiv, 2024.https:// github.com/UT-Austin-RobIn/datamodels4imitation
2024
-
[15]
RoboTurk: A Crowdsourcing Platform for Robotic Skill Learning through Imitation,
A. Mandlekar et al., “RoboTurk: A Crowdsourcing Platform for Robotic Skill Learning through Imitation,” CoRL, 2018
2018
-
[16]
BridgeData V2: A Dataset for Robot Learn- ing at Scale,
H. Walke et al., “BridgeData V2: A Dataset for Robot Learn- ing at Scale,” arXiv, 2023.https://nvlpubs.nist.gov/ nistpubs/ir/2021/NIST.IR.8345.pdf
2023
-
[17]
SCIZOR: Self-Supervised Data Curation for Large-Scale Imitation Learning,
Y . Zhang et al., “SCIZOR: Self-Supervised Data Curation for Large-Scale Imitation Learning,” ICRA, 2026.https: //rail-berkeley.github.io/bridgedata/
2026
-
[18]
CUPID: Curating Data Your Robot Loves with Influence Functions,
C. Agia et al., “CUPID: Curating Data Your Robot Loves with Influence Functions,” CoRL, 2025.https://ntrs.nasa.gov/ api/citations/20210018087/downloads/Kazanzides_ Frontiers_Final.pdf
-
[19]
DataMIL: Selecting Data for Robot Imitation Learn- ing with Datamodels,
S. Dass et al., “DataMIL: Selecting Data for Robot Imitation Learn- ing with Datamodels,” ICLR, 2026.https://2026.ieee-icra. org/program/competitions/
2026
-
[20]
RoboTurk: A Crowdsourcing Platform for Robotic Skill Learning through Imitation
HuggingFace, “One-click Robot Data Curation for Higher Quality Datasets,” 2025.https://arxiv.org/abs/1811.02790
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
User Interface Interventions for Improving Robot Learning from Demonstration
Phaijit, Ornnalin et al. “User Interface Interventions for Improving Robot Learning from Demonstration.” Proceedings of the 11th Inter- national Conference on Human-Agent Interaction (2023): n. pag
2023
-
[22]
Antony Chacon, Muhammad Bilal, Qiushi Zhou, and Wafa Johal
Jiahao Chen, D. Antony Chacon, Muhammad Bilal, Qiushi Zhou, and Wafa Johal. 2025. Mr.LfD: A Mixed Reality Interface for Robot Learning from Demonstration. In Proceedings of the 36th Australasian Conference on Human-Computer Interaction (OzCHI ’24). Associ- ation for Computing Machinery, New York, NY , USA, 275–285. https://doi.org/10.1145/3726986.3727004
-
[23]
Dall’Alba, Diego & Boriero, Fabrizio. (2025). Towards an intuitive industrial teaching interface for collaborative robots: gamepad tele- operation vs. kinesthetic teaching. The International Journal of Ad- vanced Manufacturing Technology. 138. 1505-1522. 10.1007/s00170- 025-15657-x.https://link.springer.com/article/10. 1007/s00170-025-15657-x
-
[24]
Understanding and Mitigating Network Latency Effects on Teleoperated Robots with Extended Reality,
Z. Zhang et al., “Understanding and Mitigating Network Latency Effects on Teleoperated Robots with Extended Reality,” arXiv, 2025.https://sites.google.com/view/ diffusion-meets-dagger
2025
-
[25]
Learning Differentiable Reachability Maps for Optimization-based Humanoid Motion Generation,
M. Murooka et al., “Learning Differentiable Reachability Maps for Optimization-based Humanoid Motion Generation,” arXiv, 2025.https://github.com/unitreerobotics/xr_ teleoperate
2025
-
[26]
Sensitivity of Smoothness Measures to Movement Duration, Amplitude, and Arrests,
N. Hogan and D. Sternad, “Sensitivity of Smoothness Measures to Movement Duration, Amplitude, and Arrests,”Journal of Motor Behavior, vol. 41, no. 6, pp. 529–534, 2009. doi:10.3200/35-09-004- RC
-
[27]
M. Sakr, H. F. M. Van der Loos, D. Kulic, and E. Croft, “Consistency Matters: Defining Demonstration Data Quality Metrics in Robot Learning from Demonstration,” arXiv:2412.14309, 2025
-
[28]
Forge: Teleoperation Telemetry Quality Metrics,
A. Tigunait, “Forge: Teleoperation Telemetry Quality Metrics,” GitHub repository, 2024.https://github.com/arpitg1304/forge
2024
-
[29]
Unitree Robotics, ”XR-Teleoperate: An Open-Source Teleopera- tion Framework and Data Collection Toolkit for Embodied In- telligence”, 2024.https://github.com/unitreerobotics/ xr_teleoperate
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.