RICE-PO: Turning Retrieval Interactions into Credit Signals for Reasoning Agents
Pith reviewed 2026-06-29 21:21 UTC · model grok-4.3
The pith
RICE-PO turns retrieval interactions into localized credit signals that train reasoning agents without a critic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
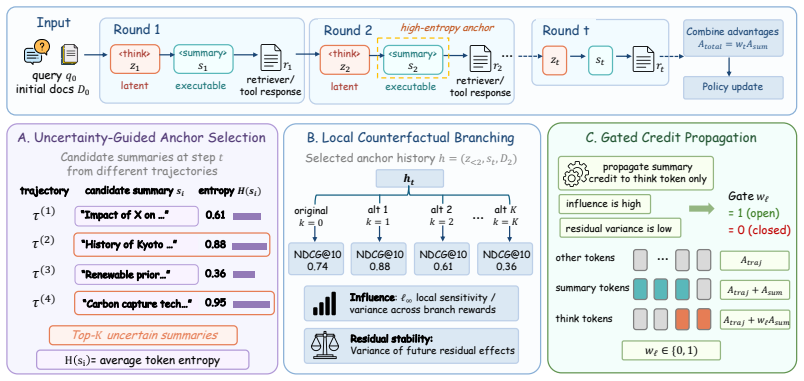
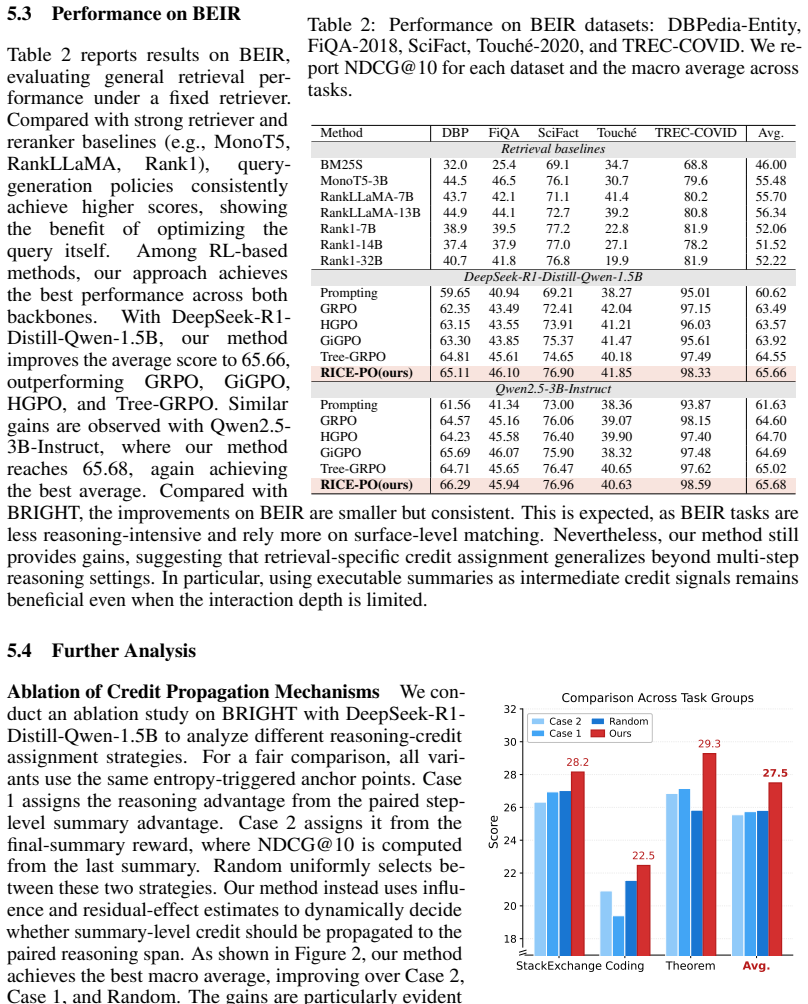
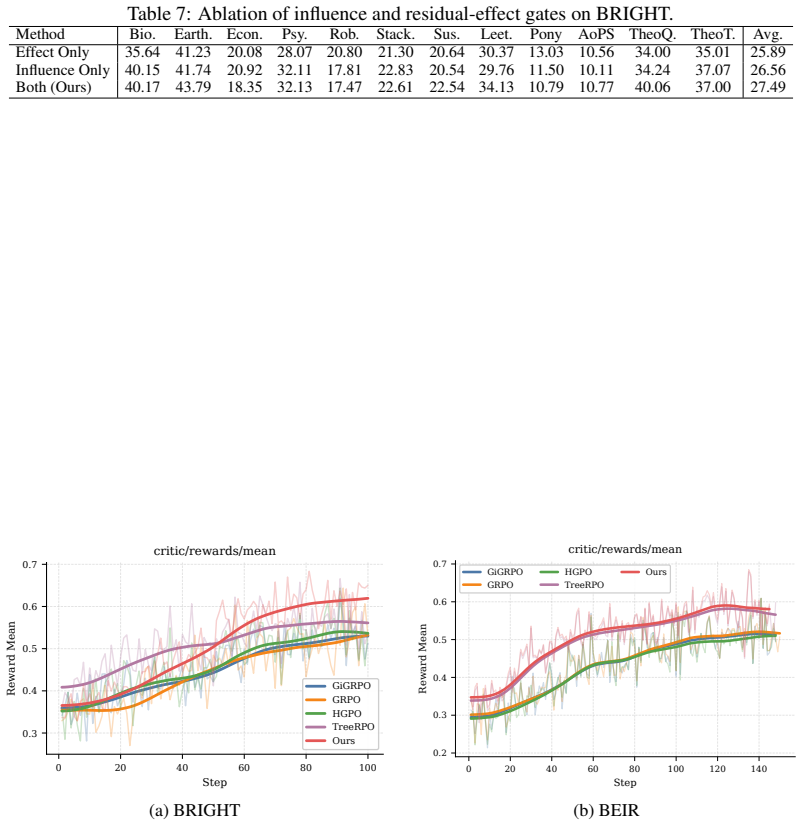
RICE-PO is a critic-free policy optimization framework that converts retrieval interactions into localized learning signals. It selects high-uncertainty executable actions as anchors, evaluates local counterfactual branches using retrieval metrics, and propagates credit to latent reasoning steps only when reasoning-to-action influence is strong and future residual effects remain stable. On BRIGHT and BEIR this produces consistent gains over prompt-based agents and group-based RL baselines under identical retriever settings.
What carries the argument
RICE-PO, a critic-free policy optimization method that anchors credit assignment on high-uncertainty executable actions and measures reasoning influence via local counterfactual retrieval evaluations.
If this is right
- Localized retrieval metrics can replace outcome-level rewards for training multi-step retrieval agents.
- Credit assignment becomes possible without training or maintaining a separate critic model.
- The same retriever can supply both evidence and training signals during agent optimization.
- Reasoning steps receive credit only when they demonstrably alter subsequent retrieval outcomes.
Where Pith is reading between the lines
- The same anchoring technique could be tested in other agent settings where some actions are directly scored by an environment.
- Longer interaction traces might require additional checks on residual stability beyond what the current method assumes.
- Interaction logs alone might reduce reliance on external reward models for reasoning agents.
Load-bearing premise
High-uncertainty executable actions serve as reliable anchors whose local counterfactual branches can measure the influence of prior reasoning while future residual effects stay stable.
What would settle it
Replace the uncertainty-based anchor selection with random actions and measure whether performance gains on BRIGHT and BEIR disappear or reverse.
Figures



read the original abstract
Retrieval is increasingly moving from one-shot matching toward interactive reasoning, where language agents iteratively inspect evidence, reformulate queries, and search again. Training such agents raises a credit-assignment challenge: executable actions such as queries or summaries can be directly evaluated by the retriever, while latent reasoning steps are not directly observable and only affect future executable actions. This asymmetry makes outcome-level reward assignment unreliable, as the same final reward may credit reasoning steps that did not actually shape retrieval success. We propose RICE-PO, a critic-free policy optimization framework that converts retrieval interactions into localized learning signals. RICE-PO selects high-uncertainty executable actions as anchors, evaluates local counterfactual branches using retrieval metrics, and propagates credit to latent reasoning steps only when reasoning-to-action influence is strong and future residual effects are stable. On BRIGHT and BEIR, RICE-PO consistently outperforms prompt-based agents and group-based RL baselines under the same retriever setting. These results show that the structure of agent-environment interaction itself can provide useful supervision for training reasoning-based retrieval agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RICE-PO, a critic-free policy optimization framework for training reasoning-based retrieval agents. It addresses credit assignment asymmetry by selecting high-uncertainty executable actions as anchors, evaluating local counterfactual branches via retrieval metrics, and propagating credit to latent reasoning steps only when reasoning-to-action influence is strong and future residual effects are stable. Empirical results claim consistent outperformance over prompt-based agents and group-based RL baselines on BRIGHT and BEIR under identical retriever settings.
Significance. If the results hold, the work shows that interaction structure itself can yield localized supervision signals without external critics, which could improve training efficiency for interactive retrieval agents. The localized counterfactual approach may have value in other agentic RL settings with sparse or delayed rewards.
minor comments (1)
- The abstract states that RICE-PO 'consistently outperforms' baselines but supplies no quantitative metrics, statistical tests, ablation results, or implementation details, making it impossible to assess whether the central empirical claim is supported.
Simulated Author's Rebuttal
We thank the referee for their time and for providing a concise summary of RICE-PO along with noting its potential significance for localized supervision in agentic RL. No specific major comments appear in the report, so we have nothing to address point-by-point. We are happy to supply additional details, ablations, or clarifications if the editor or referee requests them.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present RICE-PO as a framework that derives credit signals from external retrieval metrics applied to local counterfactual branches around high-uncertainty executable actions, with propagation conditioned on measurable reasoning-to-action influence and residual stability. No equations, parameter-fitting steps, or self-citations are shown that would reduce the central claims or predictions to inputs by construction. The outperformance on BRIGHT and BEIR is framed as an empirical consequence of using these interaction-derived signals rather than outcome-level rewards, with no indication that the method's results are tautological or forced by internal definitions. The derivation chain appears self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retrieval metrics provide valid local evaluations of counterfactual action branches
Reference graph
Works this paper leans on
-
[1]
Rader: Reasoning-aware dense retrieval models
Debrup Das, Sam O’Nuallain, and Razieh Rahimi. Rader: Reasoning-aware dense retrieval models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19981–20008, 2025
2025
-
[2]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuo He, Lang Feng, Qi Wei, Xin Cheng, Lei Feng, and Bo An. Hierarchy-of-groups policy optimization for long-horizon agentic tasks.arXiv preprint arXiv:2602.22817, 2026
-
[4]
Jiatan Huang, Zheyuan Zhang, Tianyi Ma, Mingchen Li, Yaning Zheng, Yanfang Ye, and Chuxu Zhang. Glen-bench: A graph-language based benchmark for nutritional health.arXiv preprint arXiv:2601.18106, 2026
-
[5]
EvolveRouter: Co-Evolving Routing and Prompt for Multi-Agent Question Answering
Jiatan Huang, Zheyuan Zhang, Kaiwen Shi, Yanfang Ye, and Chuxu Zhang. Evolver- outer: Co-evolving routing and prompt for multi-agent question answering.arXiv preprint arXiv:2604.05149, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Vitor Jeronymo, Roberto Lotufo, and Rodrigo Nogueira. Neuralmind-unicamp at 2022 trec neuclir: Large boring rerankers for cross-lingual retrieval.arXiv preprint arXiv:2303.16145, 2023
-
[7]
Tree search for llm agent reinforcement learning, 2026
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for llm agent reinforcement learning.arXiv preprint arXiv:2509.21240, 2025
-
[8]
Tree search for llm agent reinforcement learning
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for llm agent reinforcement learning. InInternational Conference on Learning Representations, 2026
2026
-
[9]
Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei Han. Deepretrieval: Hacking real search engines and retrievers with large language models via reinforcement learning.arXiv preprint arXiv:2503.00223, 2025
-
[10]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
A survey of recommendation systems: recommendation models, techniques, and application fields.Electronics, 11(1):141, 2022
Hyeyoung Ko, Suyeon Lee, Yoonseo Park, and Anna Choi. A survey of recommendation systems: recommendation models, techniques, and application fields.Electronics, 11(1):141, 2022
2022
-
[12]
Thinkqe: Query expansion via an evolving thinking process.arXiv preprint arXiv:2506.09260, 2025
Yibin Lei, Tao Shen, and Andrew Yates. Thinkqe: Query expansion via an evolving thinking process.arXiv preprint arXiv:2506.09260, 2025
-
[13]
Think then rewrite: Reasoning enhanced query rewriting for domain specific retrieval
Ang Li, Yufei Shi, Yuxuan Si, Yiquan Wu, Ming Cai, Xu Tan, Yi Wang, Changlong Sun, Xiaozhong Liu, and Kun Kuang. Think then rewrite: Reasoning enhanced query rewriting for domain specific retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 15045–15053, 2026
2026
-
[14]
Semantic structure based query graph prediction for question answering over knowledge graph
Mingchen Li and Shihao Ji. Semantic structure based query graph prediction for question answering over knowledge graph. InProceedings of the 29th International Conference on Computational Linguistics, pages 1569–1579, 2022
2022
-
[15]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438, 2025
2025
-
[16]
Conversational query rewriting with self-supervised learning
Hang Liu, Meng Chen, Youzheng Wu, Xiaodong He, and Bowen Zhou. Conversational query rewriting with self-supervised learning. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7628–7632. IEEE, 2021. 10
2021
-
[17]
Diver: A multi-stage approach for reasoning-intensive information retrieval
Meixiu Long, Duolin Sun, Dan Yang, Junjie Wang, Yue Shen, Jian Wang, Peng Wei, Jinjie Gu, and Jiahai Wang. Diver: A multi-stage approach for reasoning-intensive information retrieval. arXiv preprint arXiv:2508.07995, 2025
-
[18]
Fine-tuning llama for multi-stage text retrieval
Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2421–2425, 2024
2024
-
[19]
Fengran Mo, Kelong Mao, Yutao Zhu, Yihong Wu, Kaiyu Huang, and Jian-Yun Nie. Convgqr: Generative query reformulation for conversational search.arXiv preprint arXiv:2305.15645, 2023
-
[20]
Document expansion by query prediction.arXiv preprint arXiv:1904.08375,
Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho. Document expansion by query prediction.arXiv preprint arXiv:1904.08375, 2019
-
[21]
Tongsearch-qr: Reinforced query reasoning for retrieval.arXiv preprint arXiv:2506.11603, 2025
Xubo Qin, Jun Bai, Jiaqi Li, Zixia Jia, and Zilong Zheng. Tongsearch-qr: Reinforced query reasoning for retrieval.arXiv preprint arXiv:2506.11603, 2025
-
[22]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Modern information retrieval: A brief overview.IEEE Data Eng
Amit Singhal et al. Modern information retrieval: A brief overview.IEEE Data Eng. Bull., 24(4):35–43, 2001
2001
-
[25]
Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O
Hongjin Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han-yu Wang, Haisu Liu, Quan Shi, Zachary S Siegel, Michael Tang, et al. Bright: A realistic and challenging benchmark for reasoning-intensive retrieval.arXiv preprint arXiv:2407.12883, 2024
-
[26]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Query2doc: Query expansion with large language models
Liang Wang, Nan Yang, and Furu Wei. Query2doc: Query expansion with large language models.arXiv preprint arXiv:2303.07678, 2023
-
[28]
Rank1: Test-time compute for reranking in information retrieval,
Orion Weller, Kathryn Ricci, Eugene Yang, Andrew Yates, Dawn Lawrie, and Benjamin Van Durme. Rank1: Test-time compute for reranking in information retrieval.arXiv preprint arXiv:2502.18418, 2025
-
[29]
Tongyu Wen, Guanting Dong, and Zhicheng Dou. Smartsearch: Process reward-guided query refinement for search agents.arXiv preprint arXiv:2601.04888, 2026
-
[30]
Zeqiu Wu, Yi Luan, Hannah Rashkin, David Reitter, Hannaneh Hajishirzi, Mari Ostendorf, and Gaurav Singh Tomar. Conqrr: Conversational query rewriting for retrieval with reinforcement learning.arXiv preprint arXiv:2112.08558, 2021. A Technical appendices and supplementary material A.1 Implementation Since BRIGHT and BEIR are primarily designed for evaluati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.