Automatic Layer Selection for Hallucination Detection
Pith reviewed 2026-06-29 21:12 UTC · model grok-4.3
The pith
A new criterion using the first effective peak of intrinsic dimension selects optimal layers for detecting hallucinations in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
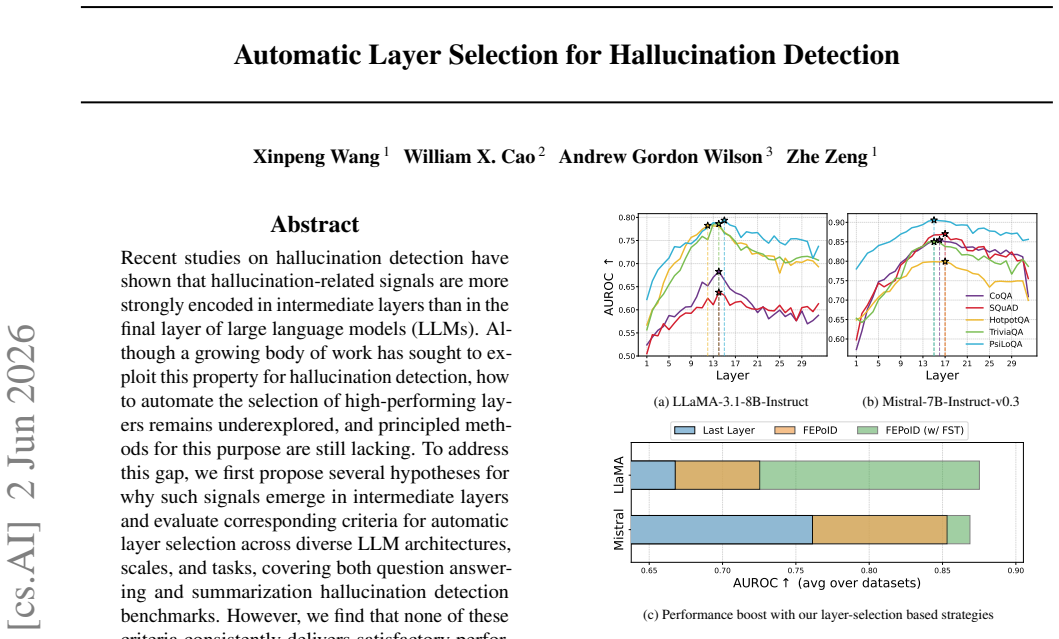
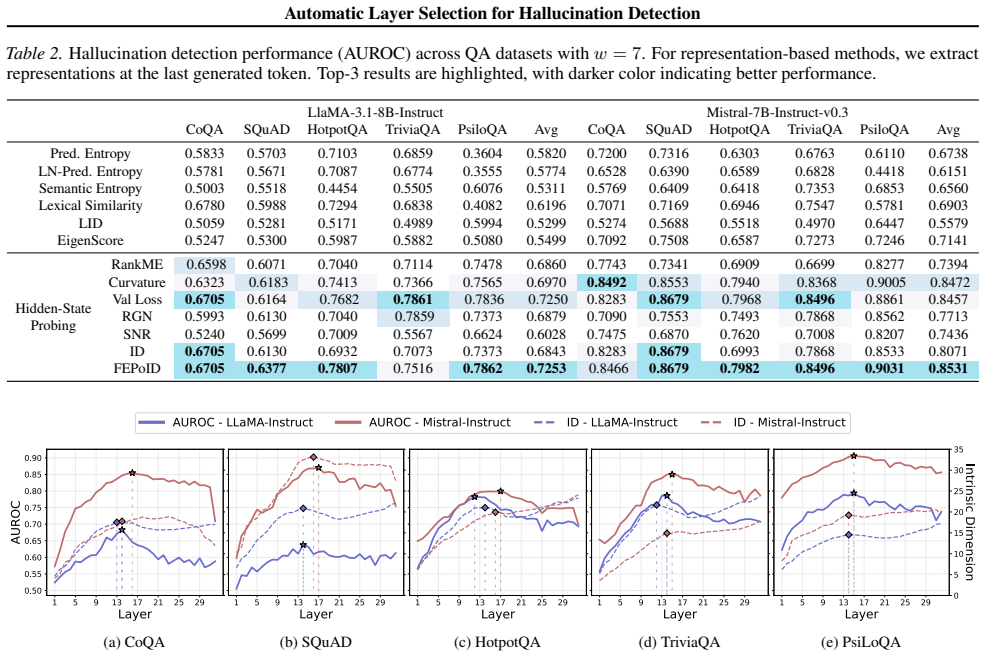
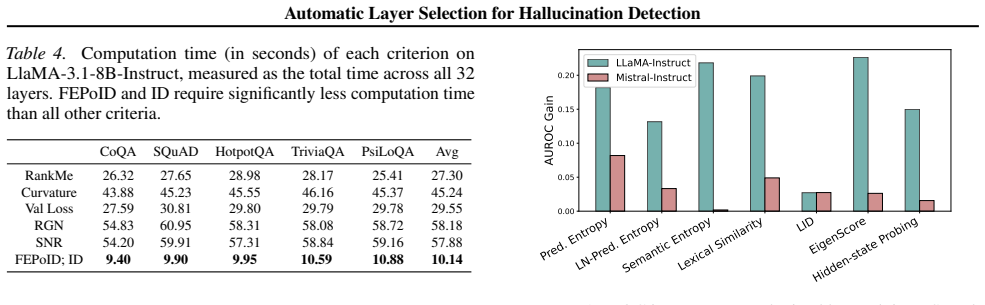
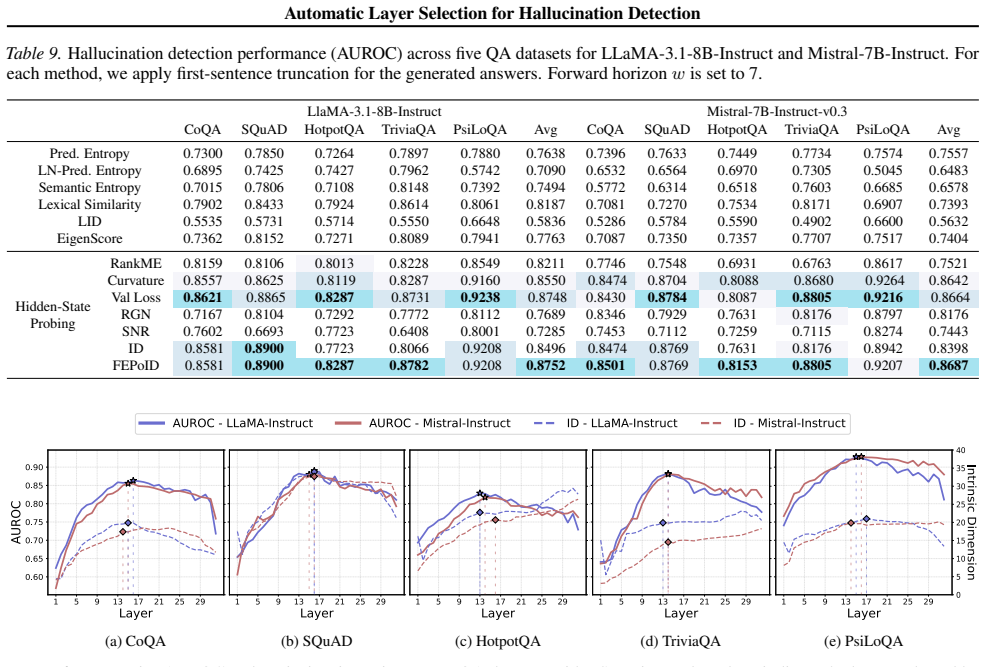
The paper claims that the First Effective Peak of Intrinsic Dimension (FEPoID) criterion consistently identifies optimal or near-optimal layers for hallucination detection across tested LLMs, tasks, and scales, outperforming both earlier selection criteria and standard detection baselines while remaining training-free and computationally cheap. A complementary truncation strategy applied during generation further amplifies the relevant signals and improves overall performance on the same benchmarks.
What carries the argument
The First Effective Peak of Intrinsic Dimension (FEPoID) criterion, which locates the earliest layer showing a clear rise in intrinsic dimension that aligns with hallucination-related information.
If this is right
- Layer selection for hallucination detection can be performed automatically across different LLM architectures without task-specific retraining.
- Detection accuracy on question-answering and summarization benchmarks rises when the selected layers are paired with the truncation strategy.
- The negligible overhead allows the method to be added to existing detection pipelines at almost no extra cost.
- The same selection logic may extend to other internal signals that appear more strongly in intermediate layers than in the output.
Where Pith is reading between the lines
- If FEPoID tracks information content more generally, it could help locate layers useful for other error-detection or interpretability tasks.
- Adopting this selection step might reduce reliance on hand-tuned layer choices in production safety systems that monitor LLM outputs.
- Testing FEPoID on models fine-tuned for specific domains could reveal whether the peak location shifts with training.
Load-bearing premise
The first effective peak of intrinsic dimension marks the layers that actually carry the hallucination signals rather than unrelated information.
What would settle it
A controlled test in which layers chosen by FEPoID produce detection accuracy no higher than layers chosen at random or by the final layer alone would falsify the central claim.
Figures


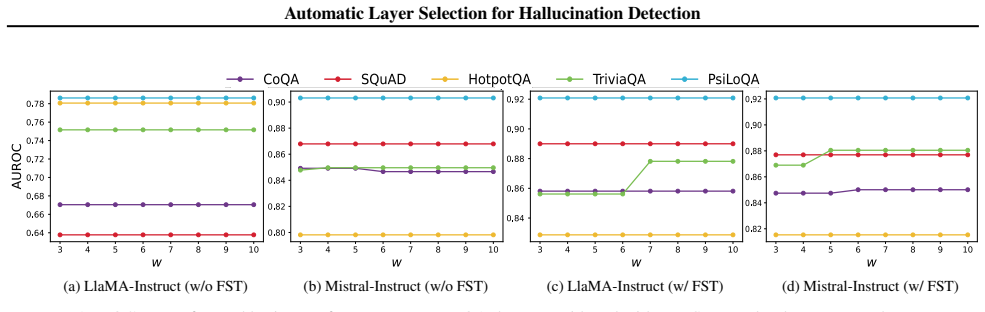
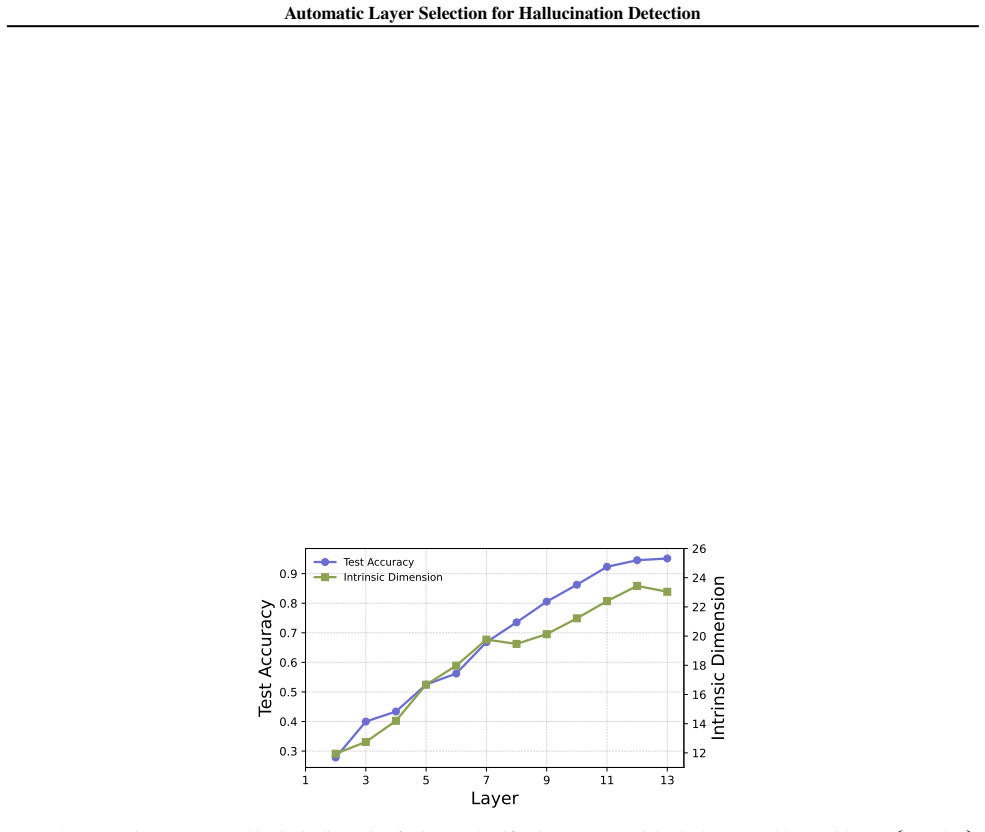
read the original abstract
Recent studies on hallucination detection have shown that hallucination-related signals are more strongly encoded in intermediate layers than in the final layer of large language models (LLMs). Although a growing body of work has sought to exploit this property for hallucination detection, how to automate the selection of high-performing layers remains underexplored, and principled methods for this purpose are still lacking. To address this gap, we first propose several hypotheses for why such signals emerge in intermediate layers and evaluate corresponding criteria for automatic layer selection across diverse LLM architectures, scales, and tasks, covering both question answering and summarization hallucination detection benchmarks. However, we find that none of these criteria consistently delivers satisfactory performance. We therefore propose a new selection criterion, First Effective Peak of Intrinsic Dimension (FEPoID), which consistently identify optimal or near-optimal layers and outperforms both the aforementioned criteria and existing hallucination detection baselines. FEPoID is training-free and incurs negligible computational overhead. In addition, we study the generation behaviors of LLMs and introduce a simple yet effective truncation strategy, which further amplifies hallucination-related signals and substantially improves overall detection performance. Code is publicly available at https://github.com/DesoloYw/Automatic-Layer-Selection-for-Hallucination-Detection.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates several hypothesis-driven criteria for automatically selecting intermediate layers in LLMs where hallucination signals are stronger, finds none consistent across architectures/scales/tasks in QA and summarization benchmarks, and introduces FEPoID (First Effective Peak of Intrinsic Dimension) as a new training-free criterion that empirically selects optimal or near-optimal layers and outperforms baselines. It also proposes a truncation strategy to amplify signals and reports public code release.
Significance. If the empirical results hold, FEPoID would provide a low-overhead, training-free method for layer selection that improves hallucination detection reliability. The public code release is a clear strength supporting reproducibility.
major comments (1)
- [Abstract / FEPoID introduction] Abstract and the section introducing FEPoID: after reporting that hypothesis-derived criteria fail to deliver consistent performance, the manuscript introduces FEPoID without a corresponding hypothesis or derivation explaining why the first effective peak of intrinsic dimension should mark layers encoding hallucination-related signals (unlike the prior criteria). The central claim therefore rests solely on empirical alignment with high detection performance on the tested models and tasks, raising the risk that success is specific to those setups rather than generally valid.
minor comments (1)
- [Abstract] Abstract: the claim of evaluation 'across diverse LLM architectures, scales, and tasks' would be clearer if the exact counts and identities of models/tasks were stated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comment.
read point-by-point responses
-
Referee: [Abstract / FEPoID introduction] Abstract and the section introducing FEPoID: after reporting that hypothesis-derived criteria fail to deliver consistent performance, the manuscript introduces FEPoID without a corresponding hypothesis or derivation explaining why the first effective peak of intrinsic dimension should mark layers encoding hallucination-related signals (unlike the prior criteria). The central claim therefore rests solely on empirical alignment with high detection performance on the tested models and tasks, raising the risk that success is specific to those setups rather than generally valid.
Authors: We agree that, unlike the initial hypothesis-driven criteria, FEPoID is introduced as an empirically identified criterion after those approaches failed to generalize. It was discovered by inspecting intrinsic-dimension profiles across layers once the earlier methods proved inconsistent. Our evaluation already spans multiple architectures, scales, and both QA and summarization tasks, which provides some evidence against narrow specificity. In revision we will add a short paragraph clarifying the empirical discovery process and offering a brief discussion of why intrinsic dimension may be relevant (e.g., as a measure of representational complexity that can shift at layers where output signals emerge). This constitutes a partial revision; the core contribution remains data-driven rather than theoretically derived. revision: partial
Circularity Check
No circularity detected; FEPoID introduced as empirical criterion after hypothesis tests fail
full rationale
The paper first proposes and evaluates several explicit hypotheses for layer signals (none consistent), then introduces FEPoID as a new training-free criterion based on the standard intrinsic dimension measure. No equations, definitions, or self-citations reduce the selection method to fitted inputs or prior results by construction. The central performance claim is presented as an empirical finding across tested models/tasks, with no load-bearing self-referential step or renaming of known results. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hallucination-related signals are more strongly encoded in intermediate layers than the final layer
- standard math Intrinsic dimension of activations can be computed reliably from model internals
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Ahdritz, G., Qin, T., Vyas, N., Barak, B., and Edelman, B. L. Distinguishing the knowable from the unknowable with language models. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org, 2024
2024
-
[3]
and Mitchell, T
Azaria, A. and Mitchell, T. The internal state of an llm knows when it’s lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 967--976, 2023
2023
-
[4]
M., Gorban, A
Bac, J., Mirkes, E. M., Gorban, A. N., Tyukin, I., and Zinovyev, A. Scikit-dimension: a python package for intrinsic dimension estimation. Entropy, 23 0 (10): 0 1368, 2021
2021
-
[5]
The intrinsic dimensionality of signal collections
Bennett, R. The intrinsic dimensionality of signal collections. IEEE Transactions on Information Theory, 15 0 (5): 0 517--525, 1969
1969
-
[6]
INSIDE : LLM s' internal states retain the power of hallucination detection
Chen, C., Liu, K., Chen, Z., Gu, Y., Wu, Y., Tao, M., Fu, Z., and Ye, J. INSIDE : LLM s' internal states retain the power of hallucination detection. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[7]
Emergence of a high-dimensional abstraction phase in language transformers
Cheng, E., Doimo, D., Kervadec, C., Macocco, I., Yu, L., Laio, A., and Baroni, M. Emergence of a high-dimensional abstraction phase in language transformers. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[8]
What you can cram into a single \ & ! \# * vector: Probing sentence embeddings for linguistic properties
Conneau, A., Kruszewski, G., Lample, G., Barrault, L., and Baroni, M. What you can cram into a single \ & ! \# * vector: Probing sentence embeddings for linguistic properties. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 2126--2136, 2018
2018
-
[9]
Cover, T. M. Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition. IEEE transactions on electronic computers, 0 (3): 0 326--334, 1965
1965
-
[10]
Estimating the intrinsic dimension of datasets by a minimal neighborhood information
Facco, E., d’Errico, M., Rodriguez, A., and Laio, A. Estimating the intrinsic dimension of datasets by a minimal neighborhood information. Scientific reports, 7 0 (1): 0 12140, 2017
2017
-
[11]
Detecting hallucinations in large language models using semantic entropy
Farquhar, S., Kossen, J., Kuhn, L., and Gal, Y. Detecting hallucinations in large language models using semantic entropy. Nature, 630 0 (8017): 0 625--630, 2024
2024
-
[12]
Fisher, R. A. The use of multiple measurements in taxonomic problems. Annals of eugenics, 7 0 (2): 0 179--188, 1936
1936
-
[13]
Rankme: Assessing the downstream performance of pretrained self-supervised representations by their rank
Garrido, Q., Balestriero, R., Najman, L., and Lecun, Y. Rankme: Assessing the downstream performance of pretrained self-supervised representations by their rank. In International conference on machine learning, pp.\ 10929--10974. PMLR, 2023
2023
-
[14]
Trueteacher: Learning factual consistency evaluation with large language models
Gekhman, Z., Herzig, J., Aharoni, R., Elkind, C., and Szpektor, I. Trueteacher: Learning factual consistency evaluation with large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 2053--2070, 2023
2023
-
[15]
Geometry-aware maximum likelihood estimation of intrinsic dimension
Gomtsyan, M., Mokrov, N., Panov, M., and Yanovich, Y. Geometry-aware maximum likelihood estimation of intrinsic dimension. In Asian Conference on Machine Learning, pp.\ 1126--1141. PMLR, 2019
2019
-
[16]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
and Fedorenko, E
Hosseini, E. and Fedorenko, E. Large language models implicitly learn to straighten neural sentence trajectories to construct a predictive representation of natural language. Advances in Neural Information Processing Systems, 36: 0 43918--43930, 2023
2023
-
[18]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43 0 (2): 0 1--55, 2025
2025
-
[19]
Janiak, D., Binkowski, J., Sawczyn, A., Gabrys, B., Shwartz-Ziv, R., and Kajdanowicz, T. J. The illusion of progress: Re-evaluating hallucination detection in LLM s. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 34728--34745, Suzhou, C...
-
[20]
LLM internal states reveal hallucination risk faced with a query
Ji, Z., Chen, D., Ishii, E., Cahyawijaya, S., Bang, Y., Wilie, B., and Fung, P. LLM internal states reveal hallucination risk faced with a query. In Belinkov, Y., Kim, N., Jumelet, J., Mohebbi, H., Mueller, A., and Chen, H. (eds.), Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp.\ 88--104, Miami, Florida...
-
[21]
Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7b, 2023
2023
-
[22]
Billion-scale similarity search with GPUs
Johnson, J., Douze, M., and J \'e gou, H. Billion-scale similarity search with GPUs . IEEE Transactions on Big Data, 7 0 (3): 0 535--547, 2019
2019
-
[23]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Joshi, M., Choi, E., Weld, D., and Zettlemoyer, L. T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension. In Barzilay, R. and Kan, M.-Y. (eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1601--1611, Vancouver, Canada, July 2017. Association fo...
-
[24]
NV -embed: Improved techniques for training LLM s as generalist embedding models
Lee, C., Roy, R., Xu, M., Raiman, J., Shoeybi, M., Catanzaro, B., and Ping, W. NV -embed: Improved techniques for training LLM s as generalist embedding models. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[25]
S., Tajwar, F., Kumar, A., Yao, H., Liang, P., and Finn, C
Lee, Y., Chen, A. S., Tajwar, F., Kumar, A., Yao, H., Liang, P., and Finn, C. Surgical fine-tuning improves adaptation to distribution shifts. In The Eleventh International Conference on Learning Representations, 2023
2023
-
[26]
and Bickel, P
Levina, E. and Bickel, P. Maximum likelihood estimation of intrinsic dimension. Advances in neural information processing systems, 17, 2004
2004
-
[27]
Making text embedders few-shot learners
Li, C., Qin, M., Xiao, S., Chen, J., Luo, K., Lian, D., Shao, Y., and Liu, Z. Making text embedders few-shot learners. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
Halueval: A large-scale hallucination evaluation benchmark for large language models
Li, J., Cheng, X., Zhao, X., Nie, J.-Y., and Wen, J.-R. Halueval: A large-scale hallucination evaluation benchmark for large language models. In Proceedings of the 2023 conference on empirical methods in natural language processing, pp.\ 6449--6464, 2023
2023
-
[29]
The dawn after the dark: An empirical study on factuality hallucination in large language models
Li, J., Chen, J., Ren, R., Cheng, X., Zhao, X., Nie, J.-Y., and Wen, J.-R. The dawn after the dark: An empirical study on factuality hallucination in large language models. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 10879--10899, ...
-
[30]
Generating with confidence: Uncertainty quantification for black-box large language models
Lin, Z., Trivedi, S., and Sun, J. Generating with confidence: Uncertainty quantification for black-box large language models. Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[31]
Uncertainty estimation and quantification for llms: A simple supervised approach, 2024
Liu, L., Pan, Y., Li, X., and Chen, G. Uncertainty estimation and quantification for llms: A simple supervised approach, 2024
2024
-
[32]
and Gales, M
Malinin, A. and Gales, M. Uncertainty estimation in autoregressive structured prediction. In International Conference on Learning Representations, 2021
2021
-
[33]
LLM s know more than they show: On the intrinsic representation of LLM hallucinations
Orgad, H., Toker, M., Gekhman, Z., Reichart, R., Szpektor, I., Kotek, H., and Belinkov, Y. LLM s know more than they show: On the intrinsic representation of LLM hallucinations. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[34]
SQ u AD : 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. SQ u AD : 100,000+ questions for machine comprehension of text. In Su, J., Duh, K., and Carreras, X. (eds.), Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp.\ 2383--2392, Austin, Texas, November 2016. Association for Computational Linguistics. doi:10.18653/v1/D16-1264
-
[35]
Measuring the intrinsic dimension of earth representations
Rao, A., Ru wurm, M., Klemmer, K., and Rolf, E. Measuring the intrinsic dimension of earth representations. arXiv preprint arXiv:2511.02101, 2025
-
[36]
Reddy, S., Chen, D., and Manning, C. D. C o QA : A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7: 0 249--266, 2019. doi:10.1162/tacl_a_00266
-
[37]
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of computational and applied mathematics, 20: 0 53--65, 1987
1987
-
[38]
and Vetterli, M
Roy, O. and Vetterli, M. The effective rank: A measure of effective dimensionality. In 2007 15th European signal processing conference, pp.\ 606--610. IEEE, 2007
2007
-
[39]
When models lie, we learn: Multilingual span-level hallucination detection with P silo QA
Rykov, E., Petrushina, K., Savkin, M., Olisov, V., Vazhentsev, A., Titova, K., Panchenko, A., Konovalov, V., and Belikova, J. When models lie, we learn: Multilingual span-level hallucination detection with P silo QA . In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.), Findings of the Association for Computational Linguistics: EMNLP...
-
[40]
J., and Manning, C
See, A., Liu, P. J., and Manning, C. D. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1073--1083, 2017
2017
-
[41]
Layer by Layer: Uncovering Hidden Representations in Language Models
Skean, O., Arefin, M. R., Zhao, D., Patel, N., Naghiyev, J., LeCun, Y., and Shwartz-Ziv, R. Layer by layer: Uncovering hidden representations in language models. arXiv preprint arXiv:2502.02013, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
The curious case of hallucinatory (un)answerability: Finding truths in the hidden states of over-confident large language models
Slobodkin, A., Goldman, O., Caciularu, A., Dagan, I., and Ravfogel, S. The curious case of hallucinatory (un)answerability: Finding truths in the hidden states of over-confident large language models. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[43]
M., Kotha, S., Fried, D., Neubig, G., and Raghunathan, A
Springer, J. M., Kotha, S., Fried, D., Neubig, G., and Raghunathan, A. Repetition improves language model embeddings. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[44]
Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s
Xiong, M., Hu, Z., Lu, X., LI, Y., Fu, J., He, J., and Hooi, B. Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[45]
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W., Salakhutdinov, R., and Manning, C. D. H otpot QA : A dataset for diverse, explainable multi-hop question answering. In Riloff, E., Chiang, D., Hockenmaier, J., and Tsujii, J. (eds.), Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp.\ 2369--2380, Brussels, Belgium...
-
[46]
Characterizing truthfulness in large language model generations with local intrinsic dimension
Yin, F., Srinivasa, J., and Chang, K.-W. Characterizing truthfulness in large language model generations with local intrinsic dimension. In Forty-first International Conference on Machine Learning, 2024
2024
-
[47]
Character-level convolutional networks for text classification
Zhang, X., Zhao, J., and LeCun, Y. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28, 2015
2015
-
[48]
Language models are universal embedders
Zhang, X., Li, Z., Zhang, Y., Long, D., Xie, P., Zhang, M., and Zhang, M. Language models are universal embedders. In Fei, H., Tu, K., Zhang, Y., Hu, X., Han, W., Jia, Z., Zheng, Z., Cao, Y., Zhang, M., Lu, W., Siddharth, N., vrelid, L., Xue, N., and Zhang, Y. (eds.), Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (X...
-
[49]
Navigating the grey area: How expressions of uncertainty and overconfidence affect language models
Zhou, K., Jurafsky, D., and Hashimoto, T. Navigating the grey area: How expressions of uncertainty and overconfidence affect language models. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 5506--5524, Singapore, December 2023. Association for Computational Linguis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.