OmniGF: A Dual-Branch Vision-Language Framework for Unified Gaze Following
Pith reviewed 2026-06-29 18:57 UTC · model grok-4.3
The pith
OmniGF adapts vision-language models with a dual-branch setup to output both exact gaze locations and semantic social reasoning in one pass for multiple people.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
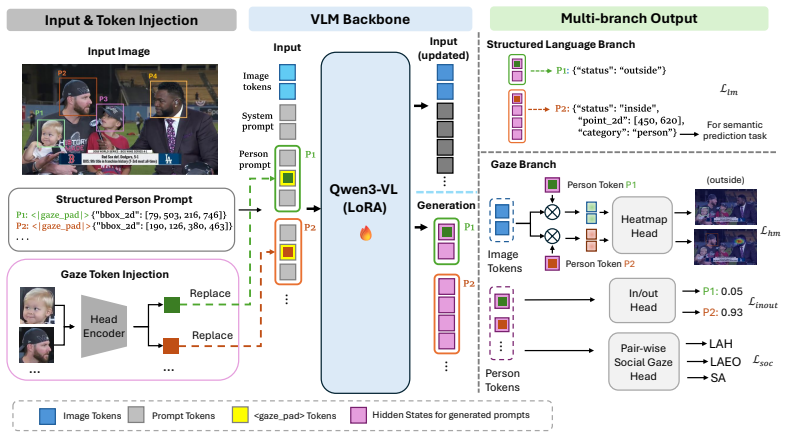
By combining a structured language branch for discrete reasoning states with a continuous spatial branch that supervises the VLM's dense hidden representations using gaze target heatmaps, and by augmenting inputs with head embeddings from cropped images, the framework unifies precise spatial gaze target estimation, semantic gaze prediction, and complex social gaze reasoning while processing all individuals simultaneously.
What carries the argument
Dual-branch decoding strategy that generates discrete language states in one branch while directly extracting and supervising continuous spatial information from the VLM's dense hidden states, grounded by simultaneous head embeddings for multi-person input.
If this is right
- The same model produces both coordinate heatmaps and textual explanations of gaze intent without task-specific retraining.
- Multi-person scenes are processed in a single forward pass rather than repeated per head.
- Performance improves on standard gaze following benchmarks that mix localization and higher-level understanding.
Where Pith is reading between the lines
- The approach could be tested on video sequences to see if the same branches support temporal gaze tracking without new architecture changes.
- If the spatial branch works, similar hidden-state supervision might be applied to other continuous outputs like hand keypoints or object boundaries inside VLMs.
- Scene understanding systems could replace separate gaze and captioning modules with one unified network, reducing total compute at inference time.
Load-bearing premise
That supervising the VLM hidden states with high-resolution heatmaps will deliver spatial precision beyond what text generation allows, and that head embeddings from cropped images will supply enough cues for all people at once.
What would settle it
Run the model on a held-out multi-person scene dataset with complex social interactions and measure whether its combined spatial error plus semantic accuracy falls below that of separate specialized gaze and reasoning models.
Figures



read the original abstract
Understanding human gaze behavior is essential for complex scene comprehension and human-computer interaction. Traditional gaze following models are typically restricted to pure spatial localization, lacking the high-level capacity to reason about semantic targets or complex social contexts. Furthermore, these models often process individuals sequentially, requiring redundant computations over the same scene image for multi-person inference. While recent Vision-Language Models (VLMs) offer the exceptional semantic reasoning needed to address gaze-related semantic tasks, their reliance on discrete text generation inherently limits precision in continuous spatial tasks like gaze localization. To bridge this gap, we propose OmniGF, a unified vision-language framework that adapts foundational VLMs for highly scalable multi-person gaze reasoning. The model adopts a dual-branch decoding strategy: a structured language branch generates discrete reasoning states, while a continuous spatial branch directly taps into the VLM's dense hidden states. Supervising these extracted representations with high-resolution gaze target heatmaps effectively overcomes the spatial bottleneck of text-only coordinate generation. Furthermore, to explicitly ground the model in multi-person scenes, we augment the input with head embeddings encoded from cropped head images, providing fine-grained appearance and orientation cues for all individuals simultaneously. By modeling all individuals and leveraging the strong semantic capability of VLMs, OmniGF seamlessly integrates precise spatial gaze target estimation, semantic gaze prediction, and complex social gaze reasoning. Extensive experiments demonstrate that our framework establishes new state-of-the-art performance across multiple standard benchmarks. Code is available at https://github.com/cvlab-stonybrook/omnigf.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniGF, a dual-branch vision-language framework adapting VLMs for unified multi-person gaze following. It uses a language branch for discrete semantic and social reasoning states and a continuous spatial branch that extracts dense hidden states from the VLM, supervised by high-resolution gaze target heatmaps to address text-generation spatial limits. Input augmentation with head embeddings from cropped images enables simultaneous multi-person processing. The work claims this integrates precise spatial estimation, semantic prediction, and complex social reasoning, achieving new state-of-the-art results on standard benchmarks, with code released.
Significance. If the dual-branch supervision and multi-person augmentation deliver the claimed spatial precision and unified reasoning without redundancy, the framework could meaningfully extend VLMs beyond discrete text outputs to continuous spatial tasks in gaze following and social scene understanding. The explicit release of code at https://github.com/cvlab-stonybrook/omnigf is a clear strength for reproducibility.
major comments (3)
- [Abstract] Abstract: the central claim that 'Supervising these extracted representations with high-resolution gaze target heatmaps effectively overcomes the spatial bottleneck of text-only coordinate generation' is load-bearing for the unified framework but is stated without any equations for the spatial branch loss, details on how dense hidden states are extracted and aligned to heatmaps, or ablation results quantifying the precision gain.
- [Abstract] Abstract: the claim that head embeddings 'providing fine-grained appearance and orientation cues for all individuals simultaneously' enables scalable multi-person inference without redundant computation is unsupported by any description of the embedding fusion mechanism, computational complexity analysis, or comparison to sequential per-person baselines.
- [Abstract] Abstract: the assertion of 'new state-of-the-art performance across multiple standard benchmarks' is presented without any quantitative metrics, baseline comparisons, or error analysis, preventing verification of whether the dual-branch design supports the performance claims.
minor comments (1)
- [Abstract] The abstract refers to 'structured language branch generates discrete reasoning states' without clarifying what the discrete states consist of or how they interface with the spatial branch.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each point below by referencing details from the full manuscript and indicate where revisions will be made to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Supervising these extracted representations with high-resolution gaze target heatmaps effectively overcomes the spatial bottleneck of text-only coordinate generation' is load-bearing for the unified framework but is stated without any equations for the spatial branch loss, details on how dense hidden states are extracted and aligned to heatmaps, or ablation results quantifying the precision gain.
Authors: The abstract is concise by design, but the full manuscript details the continuous spatial branch in Section 3.2, including the loss function (Equation 4) that supervises dense hidden states extracted from the VLM with high-resolution gaze target heatmaps. Extraction and alignment procedures are described in Section 3.1. Ablation studies quantifying the precision gains from this supervision appear in Table 5. We will revise the abstract to include a brief reference to the loss and supervision approach along with a pointer to the relevant sections. revision: yes
-
Referee: [Abstract] Abstract: the claim that head embeddings 'providing fine-grained appearance and orientation cues for all individuals simultaneously' enables scalable multi-person inference without redundant computation is unsupported by any description of the embedding fusion mechanism, computational complexity analysis, or comparison to sequential per-person baselines.
Authors: The head embedding augmentation, fusion mechanism, and input integration for simultaneous multi-person processing are described in Section 3.3. Computational complexity analysis and comparisons against sequential per-person baselines are provided in Section 4.3 and Table 3. We agree the abstract could better signal these elements and will revise it to include a short clause on the fusion and efficiency benefits with a reference to the main text. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'new state-of-the-art performance across multiple standard benchmarks' is presented without any quantitative metrics, baseline comparisons, or error analysis, preventing verification of whether the dual-branch design supports the performance claims.
Authors: The full manuscript reports the quantitative results, baseline comparisons, and error analysis supporting the SOTA claims in Tables 1 and 2 plus Section 4.1. To make the abstract self-contained for quick verification, we will revise it to include key metrics (e.g., accuracy improvements on GazeFollow and VideoAttentionTarget) while retaining the overall claim. revision: yes
Circularity Check
No circularity in derivation; method is architectural proposal with external supervision
full rationale
The paper describes a dual-branch VLM adaptation (language branch + continuous spatial branch tapping hidden states, plus head embedding augmentation) and claims the supervision with gaze heatmaps overcomes spatial limits. This is presented as a design choice and empirical result rather than a derivation that reduces to its own inputs by construction. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described chain. The approach builds on existing VLMs with added components; results are benchmark-driven, not forced by internal redefinition. This matches the default non-circular case for model-proposal papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs possess dense hidden states that can be directly supervised for continuous spatial tasks such as gaze heatmaps.
Reference graph
Works this paper leans on
-
[1]
Combining dynamic head pose–gaze mapping with the robot conversational state for attention recognition in human–robot interactions,
S. Sheikhi and J.-M. Odobez, “Combining dynamic head pose–gaze mapping with the robot conversational state for attention recognition in human–robot interactions,”Pattern Recognition Letters, vol. 66, pp. 81–90, 2015
2015
-
[2]
Social eye gaze in human-robot interaction: a review,
H. Admoni and B. Scassellati, “Social eye gaze in human-robot interaction: a review,”Journal of Human- Robot Interaction, vol. 6, no. 1, pp. 25–63, 2017
2017
-
[3]
Human gaze following for human- robot interaction,
A. Saran, S. Majumdar, E. S. Short, A. Thomaz, and S. Niekum, “Human gaze following for human- robot interaction,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 8615–8621, IEEE, 2018
2018
-
[4]
Look both ways: Self-supervising driver gaze estimation and road scene saliency,
I. Kasahara, S. Stent, and H. S. Park, “Look both ways: Self-supervising driver gaze estimation and road scene saliency,” inEuropean Conference on Computer Vision, pp. 126–142, Springer, 2022
2022
-
[5]
Dynamics of driver’s gaze: Explorations in behavior modeling and maneuver prediction,
S. Martin, S. V ora, K. Yuen, and M. M. Trivedi, “Dynamics of driver’s gaze: Explorations in behavior modeling and maneuver prediction,”IEEE Transactions on Intelligent Vehicles, vol. 3, no. 2, pp. 141–150, 2018
2018
-
[6]
A gaze model improves autonomous driving,
C. Liu, Y . Chen, L. Tai, H. Ye, M. Liu, and B. E. Shi, “A gaze model improves autonomous driving,” in Proceedings of the 11th ACM symposium on eye tracking research & applications, pp. 1–5, 2019
2019
-
[7]
The eyes have it: the neuroethology, function and evolution of social gaze,
N. J. Emery, “The eyes have it: the neuroethology, function and evolution of social gaze,”Neuroscience & biobehavioral reviews, vol. 24, no. 6, pp. 581–604, 2000
2000
-
[8]
Tracking gaze and visual focus of attention of people involved in social interaction,
B. Massé, S. Ba, and R. Horaud, “Tracking gaze and visual focus of attention of people involved in social interaction,”IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 11, pp. 2711–2724, 2017
2017
-
[9]
Atypical eye contact in autism: Models, mechanisms and development,
A. Senju and M. H. Johnson, “Atypical eye contact in autism: Models, mechanisms and development,” Neuroscience & Biobehavioral Reviews, vol. 33, no. 8, pp. 1204–1214, 2009
2009
-
[10]
Computer vision in autism spectrum disorder research: a systematic review of published studies from 2009 to 2019,
R. A. J. De Belen, T. Bednarz, A. Sowmya, and D. Del Favero, “Computer vision in autism spectrum disorder research: a systematic review of published studies from 2009 to 2019,”Translational psychiatry, vol. 10, no. 1, p. 333, 2020
2009
-
[11]
Where are they looking?,
A. Recasens, A. Khosla, C. V ondrick, and A. Torralba, “Where are they looking?,” inAdvances in Neural Information Processing Systems(C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, eds.), vol. 28, Curran Associates, Inc., 2015
2015
-
[12]
Detecting attended visual targets in video,
E. Chong, Y . Wang, N. Ruiz, and J. M. Rehg, “Detecting attended visual targets in video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5396–5406, 2020
2020
-
[13]
Dual attention guided gaze target detection in the wild,
Y . Fang, J. Tang, W. Shen, W. Shen, X. Gu, L. Song, and G. Zhai, “Dual attention guided gaze target detection in the wild,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11390–11399, 2021
2021
-
[14]
A modular multimodal architecture for gaze target prediction: Application to privacy-sensitive settings,
A. Gupta, S. Tafasca, and J.-M. Odobez, “A modular multimodal architecture for gaze target prediction: Application to privacy-sensitive settings,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 5041–5050, 2022
2022
-
[15]
Sharingan: A transformer architecture for multi-person gaze following,
S. Tafasca, A. Gupta, and J.-M. Odobez, “Sharingan: A transformer architecture for multi-person gaze following,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2008–2017, 2024
2008
-
[16]
Gaze-lle: Gaze target estimation via large-scale learned encoders,
F. Ryan, A. Bati, S. Lee, D. Bolya, J. Hoffman, and J. M. Rehg, “Gaze-lle: Gaze target estimation via large-scale learned encoders,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 28874–28884, 2025
2025
-
[17]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
K. Chen, Z. Zhang, W. Zeng, R. Zhang, F. Zhu, and R. Zhao, “Shikra: Unleashing multimodal LLM’s referential dialogue magic,”arXiv preprint arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Bošnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puigcerver...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Grounded language-image pre-training,
L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y . Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwang, K.-W. Chang, and J. Gao, “Grounded language-image pre-training,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[20]
GazeVLM: A vision-language model for multi-task gaze understanding,
A. M. Mathew, H. Hermassi, T. Khalid, and A. A. Khan, “GazeVLM: A vision-language model for multi-task gaze understanding,”arXiv preprint arXiv:2511.06348, 2025
-
[21]
VL4Gaze: Unleashing vision-language models for gaze following,
S. Wang, C. Cui, Y . Huang, H. J. Chang, and Y . Cheng, “VL4Gaze: Unleashing vision-language models for gaze following,”arXiv preprint arXiv:2512.20735, 2025
-
[22]
Connecting gaze, scene, and attention: Generalized attention estimation via joint modeling of gaze and scene saliency,
E. Chong, N. Ruiz, Y . Wang, Y . Zhang, A. Rozga, and J. M. Rehg, “Connecting gaze, scene, and attention: Generalized attention estimation via joint modeling of gaze and scene saliency,” inProceedings of the European Conference on Computer Vision, pp. 383–398, 2018
2018
-
[23]
Believe it or not, we know what you are looking at!,
D. Lian, Z. Yu, and S. Gao, “Believe it or not, we know what you are looking at!,” inProceedings of the Asian Conference on Computer Vision, pp. 35–50, Springer, 2018
2018
-
[24]
Escnet: Gaze target detection with the understanding of 3d scenes,
J. Bao, B. Liu, and J. Yu, “Escnet: Gaze target detection with the understanding of 3d scenes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14126–14135, June 2022
2022
-
[25]
Patch-level gaze distribution prediction for gaze following,
Q. Miao, M. Hoai, and D. Samaras, “Patch-level gaze distribution prediction for gaze following,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 880–889, 2023
2023
-
[26]
We know where they are looking at from the rgb-d camera: Gaze following in 3d,
Z. Hu, D. Yang, S. Cheng, L. Zhou, S. Wu, and J. Liu, “We know where they are looking at from the rgb-d camera: Gaze following in 3d,”IEEE Transactions on Instrumentation and Measurement, vol. 71, pp. 1–14, 2022
2022
-
[27]
Depth-aware gaze-following via auxiliary networks for robotics,
T. Jin, Q. Yu, S. Zhu, Z. Lin, J. Ren, Y . Zhou, and W. Song, “Depth-aware gaze-following via auxiliary networks for robotics,”Engineering Applications of Artificial Intelligence, vol. 113, p. 104924, 2022
2022
-
[28]
Childplay: A new benchmark for understanding children’s gaze behaviour,
S. Tafasca, A. Gupta, and J.-M. Odobez, “Childplay: A new benchmark for understanding children’s gaze behaviour,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 20935– 20946, 2023
2023
-
[29]
Gaze target detection by merging human attention and activity cues,
Y . Yang, Y . Yin, and F. Lu, “Gaze target detection by merging human attention and activity cues,” in Proceedings of AAAI Conference on Artificial Intelligence, vol. 38, pp. 6585–6593, 2024
2024
-
[30]
Multimae: Multi-modal multi-task masked au- toencoders,
R. Bachmann, D. Mizrahi, A. Atanov, and A. Zamir, “Multimae: Multi-modal multi-task masked au- toencoders,” inProceedings of the European Conference on Computer Vision, pp. 348–367, Springer, 2022
2022
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby,et al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
End-to-end human-gaze-target detection with transformers,
D. Tu, X. Min, H. Duan, G. Guo, G. Zhai, and W. Shen, “End-to-end human-gaze-target detection with transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2192–2200, IEEE, 2022
2022
-
[33]
Object-aware gaze target detection,
F. Tonini, N. Dall’Asen, C. Beyan, and E. Ricci, “Object-aware gaze target detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 21860–21869, 2023
2023
-
[34]
Joint gaze-location and gaze-object detection,
D. Tu, W. Shen, W. Sun, X. Min, and G. Zhai, “Joint gaze-location and gaze-object detection,”arXiv preprint arXiv:2308.13857, 2023
-
[35]
Multi-modal gaze following in conversational scenarios,
Y . Hou, Z. Zhang, N. Horanyi, J. Moon, Y . Cheng, and H. J. Chang, “Multi-modal gaze following in conversational scenarios,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 1186–1195, 2024
2024
-
[36]
Multi-view gaze target estimation,
Q. Miao, V . R. Golani, J. Xu, P. P. Dutta, M. Hoai, and D. Samaras, “Multi-view gaze target estimation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5371–5381, 2025
2025
-
[37]
Toward semantic gaze target detection,
S. Tafasca, A. Gupta, V . Bros, and J.-M. Odobez, “Toward semantic gaze target detection,”Advances in neural information processing systems, vol. 37, pp. 121422–121448, 2024
2024
-
[38]
MTGS: A novel framework for multi-person temporal gaze following and social gaze prediction,
A. Gupta, S. Tafasca, A. Farkhondeh, P. Vuillecard, and J. marc Odobez, “MTGS: A novel framework for multi-person temporal gaze following and social gaze prediction,” inAdvances in Neural Information Processing Systems, 2024. 11
2024
-
[39]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[40]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-VL: A ver- satile vision-language model for understanding, localization, text reading, and beyond,”arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge,et al., “Qwen2-vl: Enhanc- ing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge,et al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
GLaMM: Pixel grounding large multimodal model,
H. Rasheed, M. Maaz, S. Shaji, A. Shaker, S. Khan, H. Cholakkal, R. M. Anwer, E. Xing, M.-H. Yang, and F. S. Khan, “GLaMM: Pixel grounding large multimodal model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024
2024
-
[44]
LISA: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y . Chen, Y . Li, Y . Yuan, S. Liu, and J. Jia, “LISA: Reasoning segmentation via large language model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9579–9589, June 2024
2024
-
[45]
Exploring the zero-shot capabilities of vision-language models for improving gaze following,
A. Gupta, P. Vuillecard, A. Farkhondeh, and J.-M. Odobez, “Exploring the zero-shot capabilities of vision-language models for improving gaze following,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2024
2024
-
[46]
Diffusion-refined VQA annotations for semi-supervised gaze following,
Q. Miao, A. Graikos, J. Zhang, S. Mondal, M. Hoai, and D. Samaras, “Diffusion-refined VQA annotations for semi-supervised gaze following,” inEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[47]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 770–778, 2016
2016
-
[48]
Gaze360: Physically unconstrained gaze estimation in the wild,
P. Kellnhofer, A. Recasens, S. Stent, W. Matusik, and A. Torralba, “Gaze360: Physically unconstrained gaze estimation in the wild,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6912–6921, 2019
2019
-
[49]
Inferring shared attention in social scene videos,
L. Fan, Y . Chen, P. Wei, W. Wang, and S.-C. Zhu, “Inferring shared attention in social scene videos,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6460–6468, 2018
2018
-
[50]
Laeo-net: revisiting people looking at each other in videos,
M. J. Marin-Jimenez, V . Kalogeiton, P. Medina-Suarez, and A. Zisserman, “Laeo-net: revisiting people looking at each other in videos,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 3477–3485, 2019
2019
-
[51]
Multi-person gaze-following with numerical coordinate regression,
T. Jin, Z. Lin, S. Zhu, W. Wang, and S. Hu, “Multi-person gaze-following with numerical coordinate regression,” in2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), pp. 01–08, IEEE, 2021. 12 A System Prompts To effectively guide the Vision-Language Model (VLM) backbone to generate structured reasoning states, we u...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.