The Rescue Effect: Spatio-Semantic Early Exit Bypasses Quantization Collapse in CLIP
Pith reviewed 2026-06-29 18:53 UTC · model grok-4.3
The pith
Layer-wise early exits in quantized CLIP recover accuracy lost to deep-layer noise while reducing computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
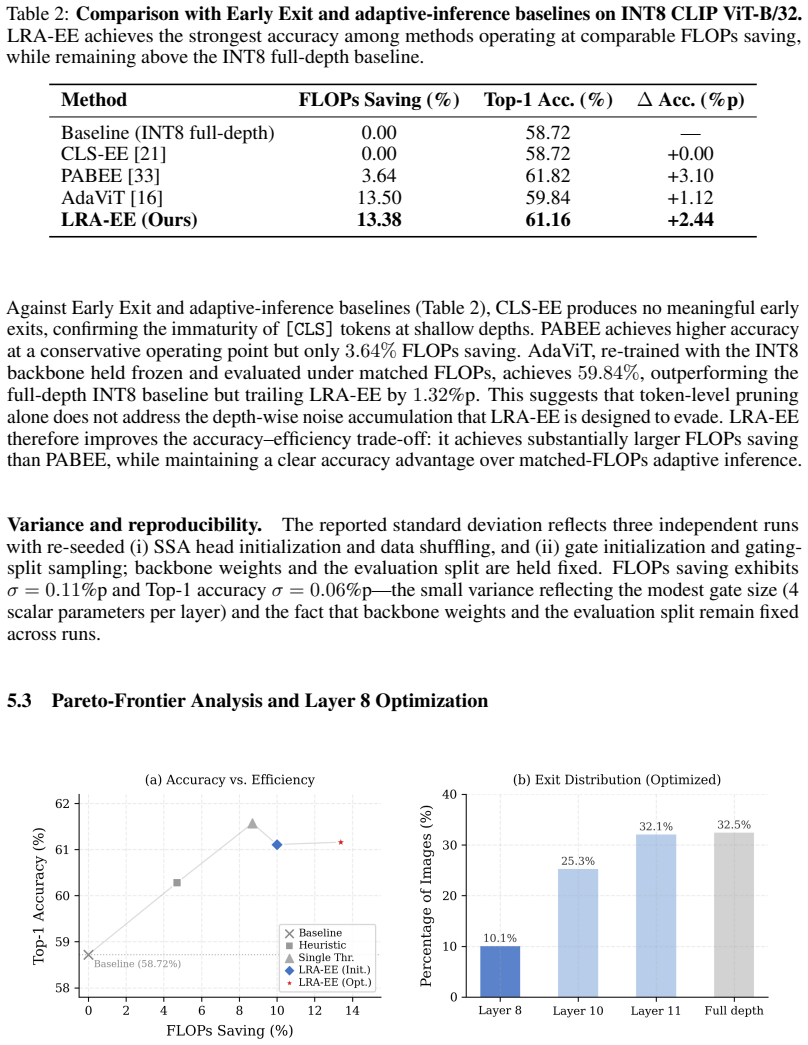
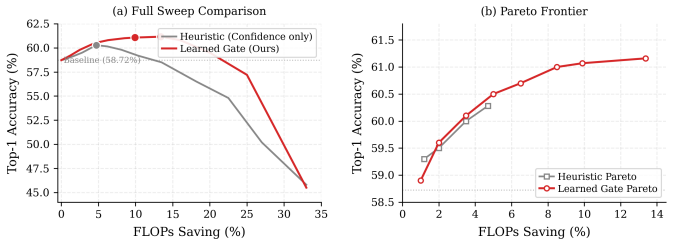
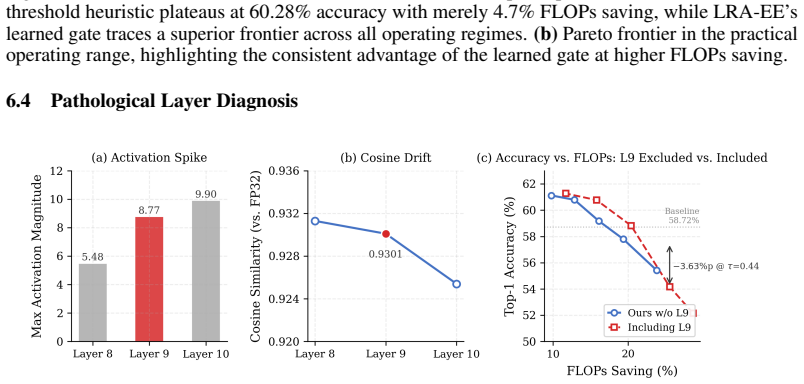
The paper claims that LRA-EE, by bypassing deep transformer blocks saturated with quantization noise through spatio-semantic early exits, reduces FLOPs by 13.4% and boosts zero-shot Top-1 accuracy from 58.72% to 61.16% on ImageNet-1K for INT8 CLIP ViT-B/32, with a four-quadrant analysis confirming that 9.5% of samples are rescued by early exit compared to 7.1% that suffer from it.
What carries the argument
LRA-EE (Layer-wise Representation-Aware Early Exit), which employs Spatio-Semantic Aggregation to replace immature [CLS] tokens with global patch averages, a multi-feature gate using confidence, top-2 margin and spatial variance, and layer-adaptive thresholds based on each layer's information-to-noise ratio.
If this is right
- Early exit decisions can improve both speed and accuracy in quantized vision-language models.
- The rescue effect demonstrates that noise accumulation in deep layers harms more samples than it helps.
- Layer-specific calibration to noise ratios enables effective early exiting without missing key information.
- Spatio-semantic aggregation provides a better representation for shallow exit decisions than the standard class token.
- The approach applies to zero-shot classification tasks reliant on cosine alignment of embeddings.
Where Pith is reading between the lines
- Similar early exit strategies might apply to other quantized transformer models where noise accumulates across layers.
- The method could extend to retrieval or other downstream tasks affected by embedding perturbations.
- Testing on different quantization bits or model sizes would reveal the generality of the rescue effect.
Load-bearing premise
The combination of confidence, top-2 margin, and spatial-activation variance in the gate, along with thresholds set by each layer's information-to-noise ratio, allows accurate exit decisions that avoid bias.
What would settle it
Measuring accuracy on the subset of samples where the model exits early versus forcing those same samples through the full network depth to check for the claimed 9.5% rescue.
Figures
read the original abstract
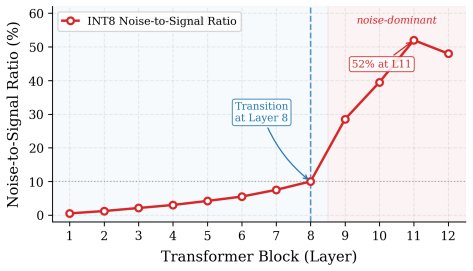
Deploying Vision-Language Models on resource-constrained hardware typically requires INT8 quantization, but in joint-embedding architectures such as CLIP this introduces a failure mode distinct from quantized CNN classifiers: activation noise accumulated across transformer blocks perturbs the direction of the multimodal embedding, eroding the cosine alignment on which zero-shot retrieval depends. We characterize this as Quantization-Induced Representation Collapse (QIRC) and quantify it on INT8 CLIP ViT-B/32, where the layer-wise noise-to-signal ratio grows from below 10% in shallow blocks to 52% at Layer 11. We propose LRA-EE (Layer-wise Representation-Aware Early Exit), which bypasses noise-saturated deep layers via Spatio-Semantic Aggregation (replacing the immature shallow [CLS] with a global patch-token average), a learned multi-feature gate (confidence, top-2 margin, spatial-activation variance), and Layer-adaptive Confidence Thresholding calibrated to each layer's Information-to-Noise Ratio. On ImageNet-1K zero-shot classification, LRA-EE reduces FLOPs by 13.4% and improves Top-1 accuracy by +2.44%p (58.72% -> 61.16%) over the INT8 baseline. A four-quadrant decomposition isolates the Rescue Effect: 9.5% of samples are correctly classified at shallow exits but lost to noise at full depth, against only 7.1% suffering the inverse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LRA-EE (Layer-wise Representation-Aware Early Exit) to mitigate Quantization-Induced Representation Collapse (QIRC) in INT8-quantized CLIP ViT-B/32 models. It introduces Spatio-Semantic Aggregation (replacing shallow [CLS] tokens with global patch-token averages), a learned multi-feature gate based on confidence, top-2 margin, and spatial-activation variance, plus layer-adaptive confidence thresholds calibrated to each layer's Information-to-Noise Ratio. The central claim, demonstrated on ImageNet-1K zero-shot classification, is a 13.4% FLOP reduction and +2.44 percentage point Top-1 accuracy gain (58.72% to 61.16%) over the INT8 baseline, driven by the Rescue Effect in which 9.5% of samples are correctly classified at shallow exits but lost to noise at full depth, versus only 7.1% suffering the inverse.
Significance. If the empirical results hold under rigorous controls, the work offers a practical approach to improving quantized performance in vision-language models without retraining, with direct relevance to resource-constrained deployment. The explicit quantification of QIRC via layer-wise noise-to-signal ratios and the four-quadrant Rescue Effect decomposition provide a concrete diagnostic for quantization artifacts in joint-embedding spaces that could generalize to other multimodal transformers.
major comments (3)
- [Abstract / Experimental Results] Abstract / §4 (empirical results): the headline deltas (+2.44%p accuracy, 13.4% FLOP reduction) and the 9.5%/7.1% Rescue Effect split are reported as direct measurements, yet the text supplies no information on the number of runs, variance estimates, statistical tests, or the precise procedure used to select and validate the layer-adaptive thresholds and multi-feature gate parameters (explicitly listed as free parameters).
- [Four-quadrant decomposition] Four-quadrant decomposition (abstract): the claim that 9.5% of samples are 'correctly classified at shallow exits but lost to noise at full depth' requires an explicit definition of how per-sample correctness is determined (ground-truth labels versus model output) and how the gate's exit decisions are isolated from the full-depth baseline without circularity or post-hoc selection.
- [Method (LRA-EE components)] Method description (multi-feature gate and INR calibration): the weakest assumption—that the combination of confidence, top-2 margin, and spatial-activation variance with INR-calibrated thresholds decides exits without systematic bias—remains untested in the provided text; an ablation isolating each gate feature and a sensitivity analysis on threshold calibration would be needed to support the net-gain claim.
minor comments (2)
- [Notation and terminology] Define all acronyms (LRA-EE, QIRC, INR) and the precise formulation of the multi-feature gate at first use.
- [Efficiency metrics] Clarify whether the reported FLOPs count includes the overhead of the gate computation itself.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract / §4 (empirical results): the headline deltas (+2.44%p accuracy, 13.4% FLOP reduction) and the 9.5%/7.1% Rescue Effect split are reported as direct measurements, yet the text supplies no information on the number of runs, variance estimates, statistical tests, or the precise procedure used to select and validate the layer-adaptive thresholds and multi-feature gate parameters (explicitly listed as free parameters).
Authors: The reported metrics are from single runs, consistent with common practice for large-scale zero-shot evaluations on ImageNet-1K. Thresholds were calibrated layer-wise to each layer's Information-to-Noise Ratio using a held-out validation split, as described in Section 3.3; the multi-feature gate parameters were learned via the procedure in Section 3.2. We will add explicit statements on the single-run nature of the results, the calibration procedure, and the absence of statistical significance tests to the revised experimental section. revision: yes
-
Referee: [Four-quadrant decomposition] Four-quadrant decomposition (abstract): the claim that 9.5% of samples are 'correctly classified at shallow exits but lost to noise at full depth' requires an explicit definition of how per-sample correctness is determined (ground-truth labels versus model output) and how the gate's exit decisions are isolated from the full-depth baseline without circularity or post-hoc selection.
Authors: Per-sample correctness is defined by agreement between the model's argmax prediction and the ground-truth label. The four-quadrant counts are obtained by running the full LRA-EE pipeline (gate decisions made independently at each layer) and separately running the full-depth INT8 model on the identical test samples; the decomposition simply cross-tabulates the two outcomes. No post-hoc selection or circular use of test labels occurs. We will insert this explicit definition and procedural description into the revised Section 4. revision: yes
-
Referee: [Method (LRA-EE components)] Method description (multi-feature gate and INR calibration): the weakest assumption—that the combination of confidence, top-2 margin, and spatial-activation variance with INR-calibrated thresholds decides exits without systematic bias—remains untested in the provided text; an ablation isolating each gate feature and a sensitivity analysis on threshold calibration would be needed to support the net-gain claim.
Authors: We agree that isolating the contribution of each gate feature and testing sensitivity to INR calibration would strengthen the claims. We will add an ablation table (removing one feature at a time) and a sensitivity plot over INR scaling factors to the revised experimental section. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claims consist of empirical measurements on ImageNet-1K zero-shot classification for the proposed LRA-EE method, including direct FLOPs reduction and accuracy deltas plus a four-quadrant sample breakdown isolating the Rescue Effect. No load-bearing derivations, equations, fitted parameters presented as predictions, or self-citation chains appear; the method description (spatio-semantic aggregation, multi-feature gate, INR-calibrated thresholds) supplies concrete mechanisms whose performance is assessed via external benchmarks rather than internal consistency loops.
Axiom & Free-Parameter Ledger
free parameters (2)
- Layer-adaptive Confidence Thresholds
- Multi-feature gate parameters
Reference graph
Works this paper leans on
-
[1]
Multi-exit vision transformer for dynamic inference
Arian Bakhtiarnia, Qi Zhang, and Alexandros Iosifidis. Multi-exit vision transformer for dynamic inference. InProceedings of the British Machine Vision Conference (BMVC), 2021. 9
2021
-
[2]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2829, 2023
2023
-
[3]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2021
2021
-
[4]
GPTQ: Accurate post-training quantiza- tion for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantiza- tion for generative pre-trained transformers. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[5]
Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V . Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InProceedings of the International Conference on Machine Learning (ICML), pages 4904–4916, 2021
2021
-
[6]
Learned token pruning for transformers
Sehoon Kim, Sheng Shen, David Thorsley, Amir Gholami, Woosuk Kwon, Joseph Hassoun, and Kurt Keutzer. Learned token pruning for transformers. InProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 784–794, 2022
2022
-
[7]
SPViT: Enabling faster vision transformers via latency-aware soft token pruning
Zhenglun Kong, Peiyan Dong, Xiaofan Ma, Xin Meng, Wei Niu, Mengshu Sun, Xuan Shen, Geng Yuan, Bin Ren, Hao Tang, Minghai Qin, and Caiwen Ding. SPViT: Enabling faster vision transformers via latency-aware soft token pruning. InProceedings of the European Conference on Computer Vision (ECCV), pages 620–636, 2022
2022
-
[8]
BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InProceedings of the International Conference on Machine Learning (ICML), pages 12888–12900, 2022
2022
-
[9]
Q-ViT: Accurate and fully quantized low-bit vision transformer
Yanjing Li, Sheng Xu, Baochang Zhang, Xianbin Cao, Peng Gao, and Guodong Guo. Q-ViT: Accurate and fully quantized low-bit vision transformer. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[10]
BRECQ: Pushing the limit of post-training quantization by block reconstruction
Yuhang Li, Ruihao Gong, Xu Tan, Yang Yang, Peng Hu, Qi Zhang, Fengwei Yu, Wei Wang, and Shi Gu. BRECQ: Pushing the limit of post-training quantization by block reconstruction. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[11]
AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration. InProceedings of Machine Learning and Systems (MLSys), 2024
2024
-
[12]
EfficientViT: Memory efficient vision transformer with cascaded group attention
Han Liu, Zhenghao Hu, Sung-En Lin, Shenlong Li, and Song Han. EfficientViT: Memory efficient vision transformer with cascaded group attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14420–14430, 2023
2023
-
[13]
FastBERT: A self-distilling BERT with adaptive inference time
Weijie Liu, Peng Zhou, Zhiruo Wang, Zhe Zhao, Haotang Deng, and Qi Ju. FastBERT: A self-distilling BERT with adaptive inference time. InProceedings of the Annual Meeting of the Association for Computa- tional Linguistics (ACL), pages 6035–6044, 2020
2020
-
[14]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
2021
-
[15]
Post-training quantization for vision transformer
Zhenhua Liu, Yunhe Wang, Kai Han, Wei Zhang, Siwei Ma, and Wen Gao. Post-training quantization for vision transformer. InAdvances in Neural Information Processing Systems (NeurIPS), pages 28092–28103, 2021
2021
-
[16]
AdaViT: Adaptive vision transformers for efficient image recognition
Lingchen Meng, Hengduo Li, Bor-Chun Chen, Shiyi Lan, Zuxuan Wu, Yu-Gang Jiang, and Ser-Nam Lim. AdaViT: Adaptive vision transformers for efficient image recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12309–12318, 2022
2022
-
[17]
Up or down? adaptive rounding for post-training quantization
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. Up or down? adaptive rounding for post-training quantization. InProceedings of the International Conference on Machine Learning (ICML), pages 7197–7206, 2020. 10
2020
-
[18]
Learning trans- ferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning trans- ferable visual models from natural language supervision. InProceedings of the International Conference on Machine Learning (ICML), pages 8748–8763, 2021
2021
-
[19]
Mahoney, and Kurt Keutzer
Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W. Mahoney, and Kurt Keutzer. Q-BERT: Hessian based ultra low precision quantization of BERT. InProceedings of the AAAI Conference on Artificial Intelligence, pages 8815–8821, 2020
2020
-
[20]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. EV A-CLIP: Improved training techniques for CLIP at scale. InarXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Surat Teerapittayanon, Bradley McDanel, and H. T. Kung. BranchyNet: Fast inference via early exiting from deep neural networks. InProceedings of the International Conference on Pattern Recognition (ICPR), pages 2464–2469, 2016
2016
-
[22]
Training data-efficient image transformers and distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. Training data-efficient image transformers and distillation through attention. InProceedings of the International Conference on Machine Learning (ICML), pages 10347–10357, 2021
2021
-
[23]
SkipBERT: Efficient inference with shallow layer skipping
Jue Wang, Ke Tan, Xiaosen Cheng, Ruobing Song, Fengwei Yu, and Zhen Huang. SkipBERT: Efficient inference with shallow layer skipping. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pages 7287–7301, 2022
2022
-
[24]
Not all images are worth 16x16 words: Dynamic vision transformers with adaptive sequence length
Yulin Wang, Rui Huang, Shiji Song, Zeyi Huang, and Gao Huang. Not all images are worth 16x16 words: Dynamic vision transformers with adaptive sequence length. InAdvances in Neural Information Processing Systems (NeurIPS), pages 11960–11973, 2021
2021
-
[25]
TinyCLIP: CLIP distillation via affinity mimicking and weight inheritance
Kan Wu, Houwen Peng, Zhenghong Zhou, Bin Xiao, Mengchen Liu, Lu Yuan, Hong Xuan, Michael Valenzuela, Xi (Stephen) Chen, Xinggang Wang, Hongyang Chao, and Han Hu. TinyCLIP: CLIP distillation via affinity mimicking and weight inheritance. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 21970–21980, 2023
2023
-
[26]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. InProceedings of the International Conference on Machine Learning (ICML), pages 38087–38099, 2023
2023
-
[27]
DeeBERT: Dynamic early exiting for accelerating BERT inference
Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, and Jimmy Lin. DeeBERT: Dynamic early exiting for accelerating BERT inference. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pages 2246–2251, 2020
2020
-
[28]
BERxiT: Early exiting for BERT with better fine-tuning and extension to regression
Ji Xin, Raphael Tang, Yaoliang Yu, and Jimmy Lin. BERxiT: Early exiting for BERT with better fine-tuning and extension to regression. InProceedings of the Conference of the European Chapter of the Association for Computational Linguistics (EACL), pages 91–104, 2021
2021
-
[29]
ZeroQuant: Efficient and affordable post-training quantization for large-scale transformers
Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. ZeroQuant: Efficient and affordable post-training quantization for large-scale transformers. InAdvances in Neural Information Processing Systems (NeurIPS), pages 27168–27183, 2022
2022
-
[30]
Florence: A New Foundation Model for Computer Vision
Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, Ce Liu, Mengchen Liu, Zicheng Liu, Yumao Lu, Yu Shi, Lijuan Wang, Jianfeng Wang, Bin Xiao, Zhen Xiao, Jianwei Yang, Michael Zeng, Furu Zhang, and Hao Zhang. Florence: A new foundation model for computer vision. InarXiv preprint a...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
PTQ4ViT: Post-training quantiza- tion for vision transformers with twin uniform quantization
Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, and Guangyu Sun. PTQ4ViT: Post-training quantiza- tion for vision transformers with twin uniform quantization. InProceedings of the European Conference on Computer Vision (ECCV), pages 191–207, 2022
2022
-
[32]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11975–11986, 2023
2023
-
[33]
BERT loses patience: Fast and robust inference with early exit
Wangchunshu Zhou, Canwen Xu, Tao Ge, Julian McAuley, Ke Xu, and Furu Wei. BERT loses patience: Fast and robust inference with early exit. InAdvances in Neural Information Processing Systems (NeurIPS), pages 18330–18341, 2020. 11
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.