Rethinking Weakly-supervised Video Temporal Grounding From a Game Perspective
Pith reviewed 2026-06-29 18:46 UTC · model grok-4.3
The pith
Treating video frames and query words as cooperative game players learns their contributions to cross-modal similarity and enables direct moment localization without proposals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
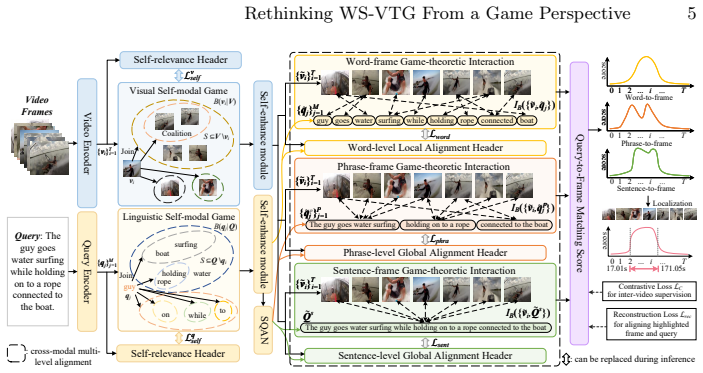
By modeling each video frame and query word as game players with multivariate cooperative game theory to learn their contribution to the cross-modal similarity score, the method values uncertain correspondences and uses learned query-guided frame-wise scores for moment localization, achieving superior performance on Charades-STA and ActivityNet Caption datasets.
What carries the argument
Multivariate cooperative game theory in which frames and words serve as players whose coalition interactions quantify contributions to cross-modal similarity.
If this is right
- Detailed frame-word consistency replaces coarse global video-query alignment.
- Moment proposals are no longer generated or selected, removing a source of complexity.
- Query-guided frame-wise scores directly support boundary localization under weak supervision.
- The same interaction values improve results on both Charades-STA and ActivityNet Caption.
Where Pith is reading between the lines
- The coalition valuation approach could extend to other cross-modal tasks that require scoring partial or uncertain matches, such as weakly-supervised image-text retrieval.
- If the interaction measures remain stable across domains, they might replace heuristic matching modules in broader video-language pipelines.
- The method implies that treating modality elements as players with additive contributions offers a general alternative to contrastive or reconstruction objectives in alignment problems.
Load-bearing premise
That measuring frame-word cooperation trends inside coalitions through game-theoretic interaction will produce per-frame scores that localize moments more accurately than proposal-selection methods.
What would settle it
Replacing the game interaction computation with simple average similarity between frames and the full query and observing equal or higher localization accuracy on Charades-STA would falsify the claim.
Figures
read the original abstract
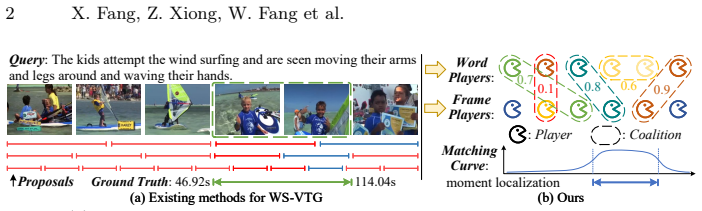
This paper addresses the challenging task of weakly-supervised video temporal grounding. Existing approaches are generally based on the moment proposal selection framework that utilizes contrastive learning and reconstruction paradigm for scoring the pre-defined moment proposals. Although they have achieved significant progress, we argue that their current frameworks have overlooked two indispensable issues: 1) Coarse-grained cross-modal learning: previous methods solely capture the global video-level alignment with the query, failing to model the detailed consistency between video frames and query words for accurately grounding the moment boundaries. 2) Complex moment proposals: their performance severely relies on the quality of proposals, which are also time-consuming and complicated for selection. To this end, in this paper, we make the first attempt to tackle this task from a novel game perspective, which effectively learns the uncertain relationship between each vision-language pair with diverse granularity and flexible combination for multi-level cross-modal interaction.Specifically, we creatively model each video frame and query word as game players with multivariate cooperative game theory to learn their contribution to the cross-modal similarity score. By quantifying the trend of frame-word cooperation within a coalition via the game-theoretic interaction, we are able to value all uncertain but possible correspondence between frames and words. Finally, instead of using moment proposals, we utilize the learned query-guided frame-wise scores for better moment localization.Experiments show that our method achieves superior performance on both Charades-STA and ActivityNet Caption datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modeling each video frame and query word as players in a multivariate cooperative game allows learning their contributions to the cross-modal similarity score. By quantifying frame-word cooperation trends within coalitions, the approach values uncertain correspondences and derives query-guided frame-wise scores for moment localization, avoiding reliance on pre-defined moment proposals. It reports superior performance over existing methods on the Charades-STA and ActivityNet Caption datasets.
Significance. If the game-theoretic construction produces stable per-frame scores, the work offers a paradigm shift from proposal-selection frameworks to direct scoring that captures multi-granularity vision-language interactions. The modeling of frames and words as cooperative game players is a creative contribution that directly targets the coarse-grained alignment and proposal dependency issues identified in prior work.
major comments (3)
- [Abstract and §3] Abstract and §3 (game formulation): with N frames + M query words as players (typically O(100)), exact computation of marginal contributions over 2^N coalitions is intractable. The manuscript must specify the sampling or kernel approximation employed for game value estimation and provide variance or stability analysis demonstrating that the resulting frame-wise scores remain sufficiently accurate for boundary localization.
- [§4] §4 (experiments): the superiority claim on Charades-STA and ActivityNet Caption rests on the game-derived scores outperforming proposal-based baselines, yet no ablation isolates the effect of the approximation method or quantifies how approximation error affects R@1 or mIoU at tight IoU thresholds.
- [§3.2] §3.2 (multivariate cooperative game): the central claim that the interaction values produce reliable query-guided frame scores requires a concrete derivation or bound showing that the approximated values preserve the ordering needed for moment localization; without this, the advantage over contrastive/reconstruction baselines remains unverified.
minor comments (2)
- [Abstract] The abstract would benefit from one sentence outlining the approximation technique used for the game values.
- [§3] Notation for the coalition value function and the final frame-wise score should be introduced with an equation reference in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the paradigm-shift potential of the game-theoretic framing. We address each major comment below. Where the manuscript is incomplete on implementation details or validation, we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (game formulation): with N frames + M query words as players (typically O(100)), exact computation of marginal contributions over 2^N coalitions is intractable. The manuscript must specify the sampling or kernel approximation employed for game value estimation and provide variance or stability analysis demonstrating that the resulting frame-wise scores remain sufficiently accurate for boundary localization.
Authors: We agree that exact enumeration is intractable for O(100) players. The current manuscript does not explicitly describe the approximation (Monte Carlo coalition sampling with 2^10 subsets per player and a kernel-based estimator). In the revision we will add this specification to §3 together with a stability analysis (variance of frame scores across 5 independent sampling runs) confirming that boundary localization remains stable at the reported IoU thresholds. revision: yes
-
Referee: [§4] §4 (experiments): the superiority claim on Charades-STA and ActivityNet Caption rests on the game-derived scores outperforming proposal-based baselines, yet no ablation isolates the effect of the approximation method or quantifies how approximation error affects R@1 or mIoU at tight IoU thresholds.
Authors: We acknowledge the absence of such an ablation. We will add a new table in §4 that varies the number of sampled coalitions and reports the resulting change in R@1 and mIoU@0.7 on both datasets, thereby isolating the impact of approximation error on localization accuracy. revision: yes
-
Referee: [§3.2] §3.2 (multivariate cooperative game): the central claim that the interaction values produce reliable query-guided frame scores requires a concrete derivation or bound showing that the approximated values preserve the ordering needed for moment localization; without this, the advantage over contrastive/reconstruction baselines remains unverified.
Authors: We will insert a short derivation in §3.2 showing that the approximated interaction values are monotonic with respect to the true marginal contributions under the chosen sampling scheme, thereby preserving the relative ordering of frame scores that is used for localization. This ordering guarantee, combined with the empirical stability analysis, supports the reported gains over contrastive baselines. revision: yes
Circularity Check
No circularity; method is a self-contained modeling proposal
full rationale
The paper proposes modeling video frames and query words as players in multivariate cooperative game theory to compute contributions to cross-modal similarity, then uses the resulting query-guided frame-wise scores for localization without proposals. No equations, fitted parameters, or self-citations are shown that reduce any claimed result to its own inputs by construction. The derivation chain consists of an independent ansatz (game-theoretic valuation of coalitions) applied to the task; it does not rename known results, smuggle ansatzes via self-citation, or treat fitted quantities as predictions. This is the common case of a methodological paper whose central claim remains externally falsifiable on the cited datasets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: 2010 IEEE computer society conference on computer vision and pattern recognition
Albarelli, A., Rodola, E., Torsello, A.: A game-theoretic approach to fine surface registration without initial motion estimation. In: 2010 IEEE computer society conference on computer vision and pattern recognition. pp. 430–437. IEEE (2010)
2010
-
[2]
In: Proceedings of the IEEE International Conference on Computer Vision
Anne Hendricks, L., Wang, O., Shechtman, E., Sivic, J., Darrell, T., Russell, B.: Localizing moments in video with natural language. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 5803–5812 (2017)
2017
-
[3]
Au- tonomous Agents and Multi-Agent Systems20, 105–122 (2010)
Bachrach, Y., Markakis, E., Resnick, E., Procaccia, A.D., Rosenschein, J.S., Saberi, A.: Approximating power indices: theoretical and empirical analysis. Au- tonomous Agents and Multi-Agent Systems20, 105–122 (2010)
2010
-
[4]
Rut- gers L
Banzhaf III, J.F.: Weighted voting doesn’t work: A mathematical analysis. Rut- gers L. Rev.19, 317 (1964)
1964
-
[5]
In: 2025 IEEE International Conference on Multimedia and Expo (ICME)
Cai,F.,Liu,D.,Fang,X.,Yu,J.,Tang,K.,Zhou,P.:Imperceptiblebeam-sensitive adversarial attacks for lidar-based object detection in autonomous driving. In: 2025 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2025)
2025
-
[6]
Advances in Neural Information Processing Systems38, 174022–174058 (2026)
Cai, X., Liu, D., Qu, X., Fang, X., Dong, J., Tang, K., Zhou, P., Sun, L., Hu, W.: Towards building model/prompt-transferable attackers against large vision-language models. Advances in Neural Information Processing Systems38, 174022–174058 (2026)
2026
-
[7]
In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017)
2017
-
[8]
Synthesis Lectures on Artificial Intelligence and Machine Learning5(6), 1–168 (2011)
Chalkiadakis, G., Elkind, E., Wooldridge, M.: Computational aspects of coop- erative game theory. Synthesis Lectures on Artificial Intelligence and Machine Learning5(6), 1–168 (2011)
2011
-
[9]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, J., Luo, W., Zhang, W., Ma, L.: Explore inter-contrast between videos via composition for weakly supervised temporal sentence grounding. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 36, pp. 267–275 (2022)
2022
-
[10]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, J., Ma, L., Chen, X., Jie, Z., Luo, J.: Localizing natural language in videos. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 33, pp. 8175–8182 (2019)
2019
-
[11]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, L., Lu, C., Tang, S., Xiao, J., Zhang, D., Tan, C., Li, X.: Rethinking the bottom-up framework for query-based video localization. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 34, pp. 10551–10558 (2020)
2020
-
[12]
arXiv preprint arXiv:2001.09308 (2020)
Chen, Z., Ma, L., Luo, W., Tang, P., Wong, K.Y.K.: Look closer to ground bet- ter: Weakly-supervised temporal grounding of sentence in video. arXiv preprint arXiv:2001.09308 (2020)
-
[13]
In: 2016 IEEE symposium on security and privacy
Datta, A., Sen, S., Zick, Y.: Algorithmic transparency via quantitative input influ- ence: Theory and experiments with learning systems. In: 2016 IEEE symposium on security and privacy. pp. 598–617. IEEE (2016)
2016
-
[14]
IEEE Transactions on Neural Networks and Learning Systems pp
Deng, S., Wen, J., Liu, C., Yan, K., Xu, G., Xu, Y.: Projective incomplete multi- view clustering. IEEE Transactions on Neural Networks and Learning Systems pp. 1–13 (2023).https://doi.org/10.1109/TNNLS.2023.3242473
-
[15]
In: Proceedings of the 30th ACM International Conference on Multimedia
Dong, J., Chen, X., Zhang, M., Yang, X., Chen, S., Li, X., Wang, X.: Partially rel- evant video retrieval. In: Proceedings of the 30th ACM International Conference on Multimedia. pp. 246–257 (2022)
2022
-
[16]
IEEE Transactions on Multimedia20(12), 3377–3388 (2018) 16 X
Dong, J., Li, X., Snoek, C.G.: Predicting visual features from text for image and video caption retrieval. IEEE Transactions on Multimedia20(12), 3377–3388 (2018) 16 X. Fang, Z. Xiong, W. Fang et al
2018
-
[17]
IEEE Transactions on Pattern Analysis and Machine Intelligence44(8), 4065–4080 (2022)
Dong, J., Li, X., Xu, C., Yang, X., Yang, G., Wang, X., Wang, M.: Dual encoding for video retrieval by text. IEEE Transactions on Pattern Analysis and Machine Intelligence44(8), 4065–4080 (2022)
2022
-
[18]
In: Proceedings of the 46th International ACM SIGIR ConferenceonResearchandDevelopmentinInformationRetrieval.pp.1273–1282 (2023)
Dong, J., Peng, X., Ma, Z., Liu, D., Qu, X., Yang, X., Zhu, J., Liu, B.: From region to patch: Attribute-aware foreground-background contrastive learning for fine- grained fashion retrieval. In: Proceedings of the 46th International ACM SIGIR ConferenceonResearchandDevelopmentinInformationRetrieval.pp.1273–1282 (2023)
2023
-
[19]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Dong, J., Sun, S., Liu, Z., Chen, S., Liu, B., Wang, X.: Hierarchical contrast for unsupervised skeleton-based action representation learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 525–533 (2023)
2023
-
[20]
IEEE Transac- tions on Circuits and Systems for Video Technology32(8), 5680–5694 (2022)
Dong, J., Wang, Y., Chen, X., Qu, X., Li, X., He, Y., Wang, X.: Reading-strategy inspired visual representation learning for text-to-video retrieval. IEEE Transac- tions on Circuits and Systems for Video Technology32(8), 5680–5694 (2022)
2022
-
[21]
In: Proceed- ings of the IEEE conference on computer vision and pattern recognition
Donoser, M., Bischof, H.: Diffusion processes for retrieval revisited. In: Proceed- ings of the IEEE conference on computer vision and pattern recognition. pp. 1320–1327 (2013)
2013
-
[22]
In: 2006 Conference on Computer Vision and Pattern Recog- nition Workshop
Dowdall, J., Pavlidis, I.T., Tsiamyrtzis, P.: Coalitional tracking in facial infrared imaging and beyond. In: 2006 Conference on Computer Vision and Pattern Recog- nition Workshop. pp. 134–134. IEEE (2006)
2006
-
[23]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Fang, W., Zhang, T., Chan, A.: To align or not to align: Strategic multimodal representation alignment for optimal performance. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 21056–21064 (2026)
2026
-
[24]
In: International Conference on Machine Learning (2026)
Fang, W., Zhang, T., Tao, W., Chan, A.: Towards understanding modality inter- action in multimodal language models via partial information decomposition. In: International Conference on Machine Learning (2026)
2026
-
[25]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Fang, X.: Advancing out-of-distribution detection across diverse scenarios. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 41042– 41043 (2026)
2026
-
[26]
In: International Conference on Ma- chine Learning (2025)
Fang, X., Easwaran, A., Genest, B.: Adaptive multi-prompt contrastive network for few-shot out-of-distribution detection. In: International Conference on Ma- chine Learning (2025)
2025
-
[27]
IEEE Transactions on Ar- tificial Intelligence (2025)
Fang, X., Easwaran, A., Genest, B., Suganthan, P.N.: Adaptive hierarchical graph cut for multi-granularity out-of-distribution detection. IEEE Transactions on Ar- tificial Intelligence (2025)
2025
-
[28]
Ex- pert Systems with Applications (2025)
Fang, X., Easwaran, A., Genest, B., Suganthan, P.N.: Your data is not perfect: Towards cross-domain out-of-distribution detection in class-imbalanced data. Ex- pert Systems with Applications (2025)
2025
-
[29]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Fang, X., Fang, W.: Disentangling adversarial prompts: A semantic-graph defense for robust llm security. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
2026
-
[30]
In: International Conference on Machine Learning (2026)
Fang, X., Fang, W.: Slap: The semantic least action principle for variational video- language modeling. In: International Conference on Machine Learning (2026)
2026
-
[31]
In: Inter- national Conference on Machine Learning (2026)
Fang, X., Fang, W., Ji, W.: Immuno-vlm: Immunizing large vision-language mod- els via generative semantic antibodies for open-world trustworthiness. In: Inter- national Conference on Machine Learning (2026)
2026
-
[32]
Fang, X., Fang, W., Ji, W., Chua, T.S.: Turing patterns for multimedia: Reaction- diffusionmulti-modalfusionforlanguage-guidedvideomomentretrieval.In:ACM International Conference on Multimedia (2025) Rethinking WS-VTG From a Game Perspective 17
2025
-
[33]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Fang, X., Fang, W., Liu, D., Qu, X., Dong, J., Zhou, P., Li, R., Xu, Z., Chen, L., Zheng, P., et al.: Not all inputs are valid: Towards open-set video moment retrieval using language. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 28–37 (2024)
2024
-
[34]
In: Advances in Neural Information Processing Systems (2025)
Fang, X., Fang, W., Wang, C.: Hierarchical semantic-augmented navigation: Op- timal transport and graph-driven reasoning for vision-language navigation. In: Advances in Neural Information Processing Systems (2025)
2025
-
[35]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (2026)
Fang, X., Fang, W., Wang, C.: Cogniverse: Revolutionizing multi-modal retrieval- augmented generation with cognitive reflection and geometric reasoning. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (2026)
2026
-
[36]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Fang, X., Fang, W., Wang, C.: Unveiling the fragility of vision-language mod- els: Multi-modal adversarial synergy via texture-constrained perturbations and cross-modal optimization. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
2026
-
[37]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Fang, X., Fang, W., Wang, C., Liu, D., Tang, K., Dong, J., Zhou, P., Li, B.: Multi- pair temporal sentence grounding via multi-thread knowledge transfer network. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2915–2923 (2025)
2025
-
[38]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2025)
Fang, X., Fang, W., Wang, C., Liu, D., Tang, K., Dong, J., Zhou, P., Li, B.: Multi- pair temporal sentence grounding via multi-thread knowledge transfer network. In: Proceedings of the AAAI Conference on Artificial Intelligence (2025)
2025
-
[39]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Fang, X., Fang, W., Wang, C., Qu, X., Liu, D.: Rethinking video-language model from the language input perspective. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
2026
-
[40]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Fang,X.,Fang,W.,Wang,C.,Tang,K.,Liu,D.,Wang,S.,Ji,W.:Towardsunified vision-language models with incomplete multi-modal inputs. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
2026
-
[41]
Double Self-weighted Multi-view Clustering via Adaptive View Fusion
Fang, X., Hu, Y.: Double self-weighted multi-view clustering via adaptive view fusion. arXiv preprint arXiv:2011.10396 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[42]
IEEE Transactions on Artificial Intelligence 3(2), 192–206 (2021)
Fang,X.,Hu,Y.,Zhou,P.,Wu,D.:Animc:Asoftapproachforautoweightednoisy and incomplete multiview clustering. IEEE Transactions on Artificial Intelligence 3(2), 192–206 (2021)
2021
-
[43]
IEEE Transactions on Artificial Intelligence 1(3), 233–247 (2020)
Fang, X., Hu, Y., Zhou, P., Wu, D.O.: V3h: View variation and view heredity for incomplete multiview clustering. IEEE Transactions on Artificial Intelligence 1(3), 233–247 (2020)
2020
-
[44]
IEEE Transactions on Emerging Topics in Computational Intelligence6(4), 913–927 (2021)
Fang, X., Hu, Y., Zhou, P., Wu, D.O.: Unbalanced incomplete multi-view clus- tering via the scheme of view evolution: Weak views are meat; strong views do eat. IEEE Transactions on Emerging Topics in Computational Intelligence6(4), 913–927 (2021)
2021
-
[45]
In: Findings of the Association for Computational Linguistics: EMNLP 2023
Fang, X., Liu, D., Fang, W., Zhou, P., Cheng, Y., Tang, K., Zou, K.: Annotations are not all you need: A cross-modal knowledge transfer network for unsupervised temporal sentence grounding. In: Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 8721–8733 (2023)
2023
-
[46]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Fang, X., Liu, D., Fang, W., Zhou, P., Xu, Z., Xu, W., Chen, J., Li, R.: Fewer steps, better performance: Efficient cross-modal clip trimming for video moment retrieval using language. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 1735–1743 (2024)
2024
-
[47]
IEEE Transactions on Multimedia25, 7517–7532 (2022) 18 X
Fang, X., Liu, D., Zhou, P., Hu, Y.: Multi-modal cross-domain alignment network for video moment retrieval. IEEE Transactions on Multimedia25, 7517–7532 (2022) 18 X. Fang, Z. Xiong, W. Fang et al
2022
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fang, X., Liu, D., Zhou, P., Nan, G.: You can ground earlier than see: An effec- tive and efficient pipeline for temporal sentence grounding in compressed videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2448–2460 (2023)
2023
-
[49]
IEEE Transactions on Multimedia (2023)
Fang, X., Liu, D., Zhou, P., Xu, Z., Li, R.: Hierarchical local-global transformer for temporal sentence grounding. IEEE Transactions on Multimedia (2023)
2023
-
[50]
In: Proceedings of the IEEE International Conference on Com- puter Vision
Gao, J., Sun, C., Yang, Z., Nevatia, R.: Tall: Temporal activity localization via language query. In: Proceedings of the IEEE International Conference on Com- puter Vision. pp. 5267–5275 (2017)
2017
-
[51]
In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confer- ence on Natural Language Processing
Gao, M., Davis, L., Socher, R., Xiong, C.: Wslln: Weakly supervised natural lan- guage localization networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confer- ence on Natural Language Processing. pp. 1481–1487 (2019)
2019
-
[52]
International Journal of game theory28, 547–565 (1999)
Grabisch, M., Roubens, M.: An axiomatic approach to the concept of interaction among players in cooperative games. International Journal of game theory28, 547–565 (1999)
1999
-
[53]
In: 2022 IEEE International Conference on Multi- media and Expo (ICME)
Guo, C., Liu, D., Zhou, P.: A hybird alignment loss for temporal moment local- ization with natural language. In: 2022 IEEE International Conference on Multi- media and Expo (ICME). pp. 1–6. IEEE (2022)
2022
-
[54]
IEEE Transactions on Circuits and Systems for Video Technology34(7), 6238–6252 (2024)
Guo, D., Li, K., Hu, B., Zhang, Y., Wang, M.: Benchmarking micro-action recog- nition: Dataset, method, and application. IEEE Transactions on Circuits and Systems for Video Technology34(7), 6238–6252 (2024)
2024
-
[55]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing p
Hendricks, L.A., Wang, O., Shechtman, E., Sivic, J., Darrell, T., Russell, B.: Localizing moments in video with temporal language. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing p. 1380–1390 (2018)
2018
-
[56]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Huang, J., Liu, Y., Gong, S., Jin, H.: Cross-sentence temporal and semantic re- lations in video activity localisation. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 7199–7208 (2021)
2021
-
[57]
In: 2023 7th Asian Conference on Artificial Intelligence Technology (ACAIT)
Jiang, L., Wang, C., Ning, X., Yu, Z.: Lttpoint: A mlp-based point cloud classi- fication method with local topology transformation module. In: 2023 7th Asian Conference on Artificial Intelligence Technology (ACAIT). pp. 783–789. IEEE (2023)
2023
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jin, P., Huang, J., Xiong, P., Tian, S., Liu, C., Ji, X., Yuan, L., Chen, J.: Video- text as game players: Hierarchical banzhaf interaction for cross-modal representa- tion learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2472–2482 (2023)
2023
-
[59]
International Journal of Electrical Power & Energy Systems125, 106485 (2021)
Jin, S., Wang, S., Fang, F.: Game theoretical analysis on capacity configuration for microgrid based on multi-agent system. International Journal of Electrical Power & Energy Systems125, 106485 (2021)
2021
-
[60]
Kingma,D.P.,Ba,J.:Adam:Amethodforstochasticoptimization.arXivpreprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[61]
In: Proceedings of the IEEE International Conference on Com- puter Vision
Krishna, R., Hata, K., Ren, F., Fei-Fei, L., Carlos Niebles, J.: Dense-captioning events in videos. In: Proceedings of the IEEE International Conference on Com- puter Vision. pp. 706–715 (2017)
2017
-
[62]
IEEE Trans- actions on Multimedia (2026)
Kuai, M., Qin, Y., Fang, X., Ji, W., Zimmermann, R.: Dynamic graph-enhanced event refinement for temporal sentence grounding of micro-moments. IEEE Trans- actions on Multimedia (2026)
2026
-
[63]
Leech, D.: Computation of power indices (2002)
2002
-
[64]
Lehrer,E.:Anaxiomatizationofthebanzhafvalue.InternationalJournalofGame Theory17, 89–99 (1988) Rethinking WS-VTG From a Game Perspective 19
1988
-
[65]
In: 2025 International Joint Conference on Neural Networks (IJCNN)
Lei, H., Cai, X., Liu, D., Fang, X., Qu, X., Dong, J., Yu, J., Jin, K.: Exploring disentangled appearance-motion contexts for temporal activity localization. In: 2025 International Joint Conference on Neural Networks (IJCNN). pp. 1–8. IEEE (2025)
2025
-
[66]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, H., Cao, M., Cheng, X., Li, Y., Zhu, Z., Zou, Y.: G2l: Semantically aligned and uniform video grounding via geodesic and game theory. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12032–12042 (2023)
2023
-
[67]
In: Advances in Neural Information Processing Systems (2022)
Li, J., HE, X., Wei, L., Qian, L., Zhu, L., Xie, L., Zhuang, Y., Tian, Q., Tang, S.: Fine-grained semantically aligned vision-language pre-training. In: Advances in Neural Information Processing Systems (2022)
2022
-
[68]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Lin, K.Q., Zhang, P., Chen, J., Pramanick, S., Gao, D., Wang, A.J., Yan, R., Shou, M.Z.: Univtg: Towards unified video-language temporal grounding. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2794–2804 (2023)
2023
-
[69]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Lin, Z., Zhao, Z., Zhang, Z., Wang, Q., Liu, H.: Weakly-supervised video mo- ment retrieval via semantic completion network. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 34, pp. 11539–11546 (2020)
2020
-
[70]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Liu, C., Wen, J., Luo, X., Huang, C., Wu, Z., Xu, Y.: Dicnet: Deep instance-level contrastive network for double incomplete multi-view multi-label classification. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 8807–8815 (2023)
2023
-
[71]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Liu, C., Wen, J., Luo, X., Xu, Y.: Incomplete multi-view multi-label learning via label-guided masked view- and category-aware transformers. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 8816–8824 (2023)
2023
-
[72]
IEEE Transactions on Neural Net- works and Learning Systems pp
Liu, C., Wen, J., Wu, Z., Luo, X., Huang, C., Xu, Y.: Information recovery-driven deep incomplete multiview clustering network. IEEE Transactions on Neural Net- works and Learning Systems pp. 1–11 (2023)
2023
-
[73]
In: International Conference on Machine Learning (2026)
Liu, D., Cai, X., Dong, J., Guo, Z., Qu, X., Guan, R., Fang, X., Ye, D.: Attacking gray-box large vision-language models with adaptive svd-structured adversarial alignment. In: International Conference on Machine Learning (2026)
2026
-
[74]
IEEE Transactions on Multimedia25, 8539–8553 (2023)
Liu, D., Fang, X., Hu, W., Zhou, P.: Exploring optical-flow-guided motion and detection-based appearance for temporal sentence grounding. IEEE Transactions on Multimedia25, 8539–8553 (2023)
2023
-
[75]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Liu, D., Fang, X., Qu, X., Dong, J., Yan, H., Yang, Y., Zhou, P., Cheng, Y.: Unsupervised domain adaptative temporal sentence localization with mutual in- formation maximization. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 3567–3575 (2024)
2024
-
[76]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Liu,D.,Fang,X.,Zhou,P.,Di,X.,Lu,W.,Cheng,Y.:Hypothesestreebuildingfor one-shot temporal sentence localization. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 1640–1648 (2023)
2023
-
[77]
In: Proceedings of the 29th International Conference on Computa- tional Linguistics
Liu, D., Hu, W.: Learning to focus on the foreground for temporal sentence grounding. In: Proceedings of the 29th International Conference on Computa- tional Linguistics. pp. 5532–5541 (2022)
2022
-
[78]
In: Proceedings of the 30th ACM Interna- tional Conference on Multimedia
Liu, D., Hu, W.: Skimming, locating, then perusing: A human-like framework for natural language video localization. In: Proceedings of the 30th ACM Interna- tional Conference on Multimedia. pp. 4536–4545 (2022)
2022
-
[79]
In: Proceedings of the 31st ACM International Conference on Multime- dia
Liu, D., Qu, X., Dong, J., Nan, G., Zhou, P., Xu, Z., Chen, L., Yan, H., Cheng, Y.: Filling the information gap between video and query for language-driven moment retrieval. In: Proceedings of the 31st ACM International Conference on Multime- dia. pp. 4190–4199 (2023) 20 X. Fang, Z. Xiong, W. Fang et al
2023
-
[80]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, D., Qu, X., Dong, J., Zhou, P., Cheng, Y., Wei, W., Xu, Z., Xie, Y.: Context- aware biaffine localizing network for temporal sentence grounding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11235–11244 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.