Towards Error-Free EHRs: Reasoning-Intensive Consistency Verification Between Clinical Notes and Structured Tables in Electronic Health Records
Pith reviewed 2026-06-29 18:31 UTC · model grok-4.3
The pith
EHR-Inspector verifies consistency between clinical notes and structured tables using reasoning rather than surface matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
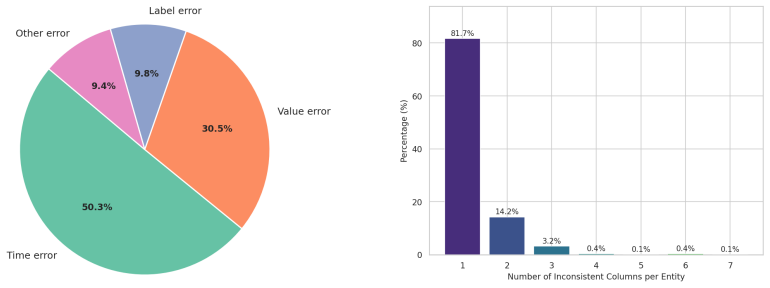
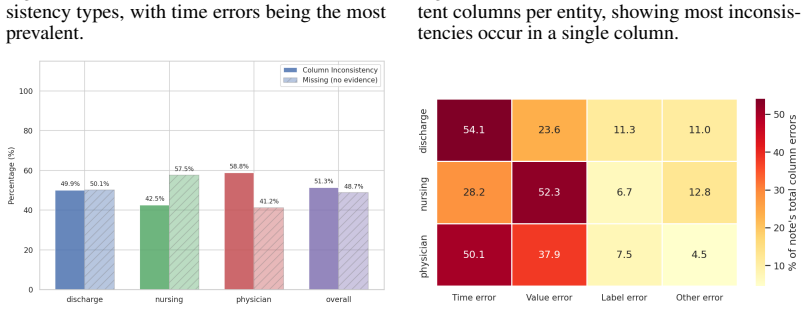
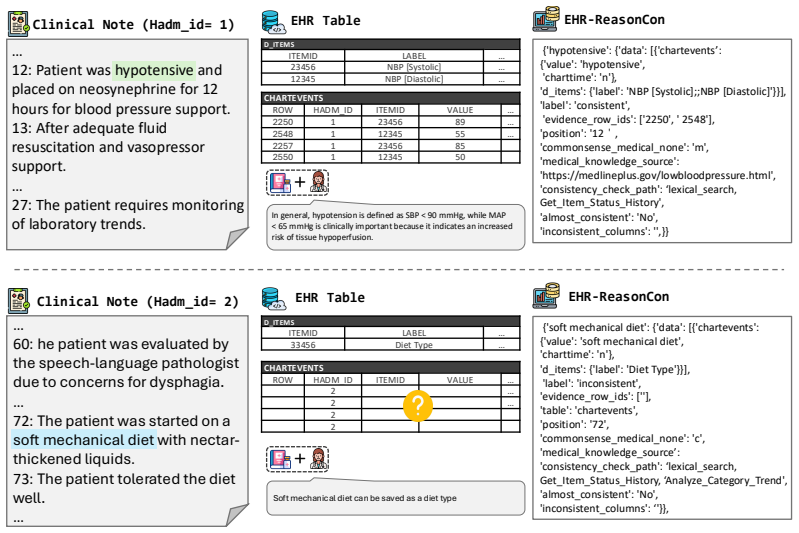
The authors create the EHR-ReasonCon benchmark with 8,048 entities from MIMIC-III clinical notes, annotated via expert-guided protocol with table-exploration tools, and demonstrate that their EHR-Inspector framework, which segments notes, extracts anchor entities and temporal references, and applies table tools for verification, achieves state-of-the-art performance on expert-validated LLM-as-a-judge metrics under harsh and lenient criteria across multiple model backbones.
What carries the argument
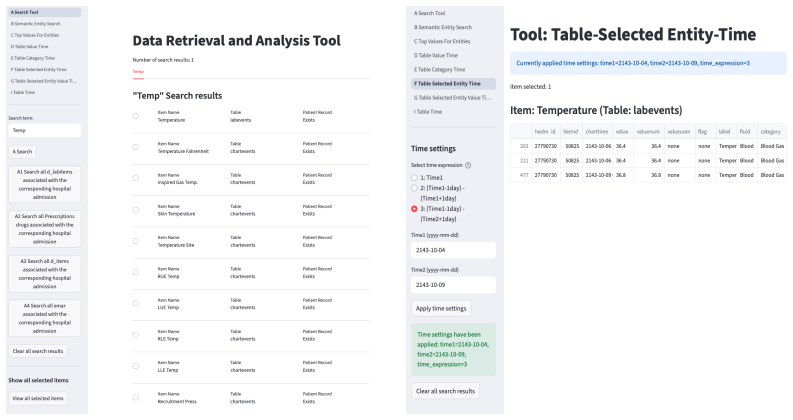
EHR-Inspector, an LLM-based framework that segments clinical notes, extracts anchor entities and temporal references, then uses table-exploration tools to verify consistency against structured tables.
If this is right
- Consistency verification can capture clinical interpretation and temporal changes beyond numeric matching.
- EHR-Inspector works across different LLM backbones with improved performance.
- Analyses show effectiveness of individual components like segmentation and entity extraction.
- Results differ from human verification in specific ways, suggesting areas for improvement.
Where Pith is reading between the lines
- Deploying such systems in hospitals could reduce documentation errors that affect patient care.
- The benchmark could be extended to other EHR systems beyond MIMIC-III to test generalizability.
- Integrating this with real-time EHR updates might prevent inconsistencies as they occur.
Load-bearing premise
The expert-guided annotation protocol supported by specialized table-exploration tools ensures systematic evidence retrieval and reliable consistency assessment for producing high-quality ground-truth labels.
What would settle it
A test on a new EHR dataset where EHR-Inspector fails to outperform simple matching methods or shows low agreement with human experts on consistency labels.
Figures
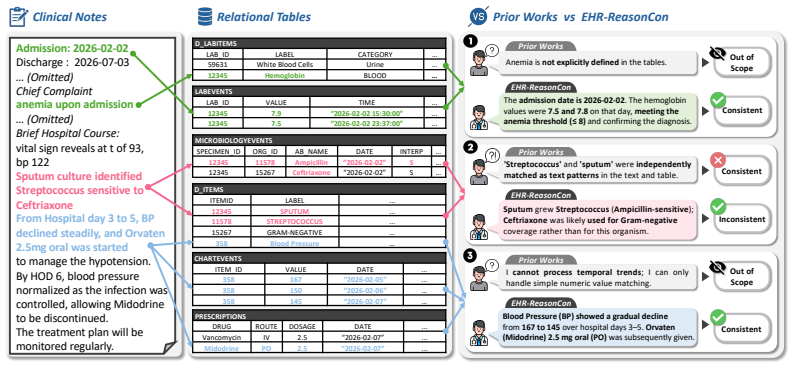
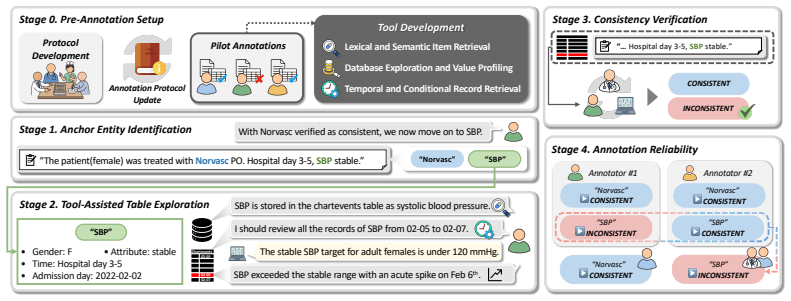
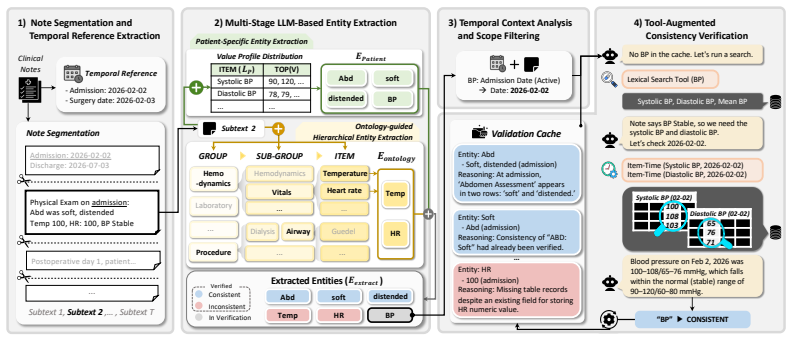
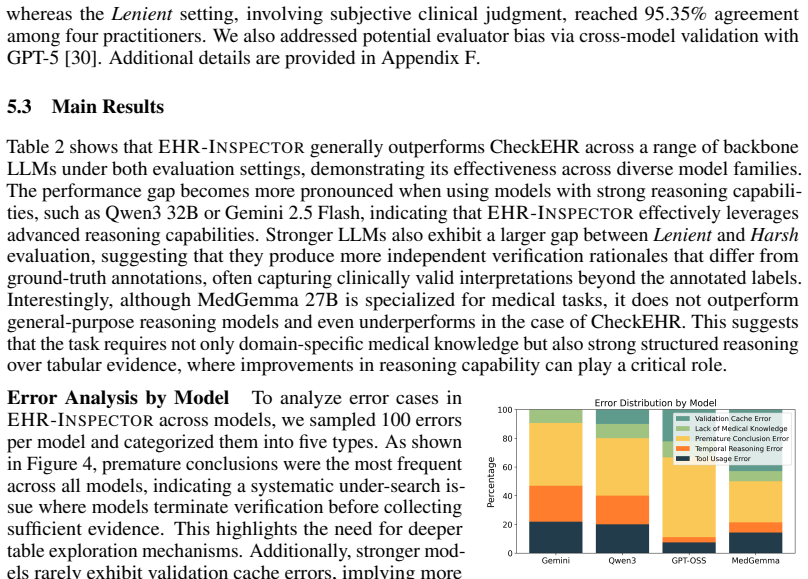
















read the original abstract
Data consistency between unstructured clinical notes and structured tables in Electronic Health Records (EHRs) is essential for patient safety and clinical decision-making. However, existing work on note-table consistency verification mainly relies on surface-level matching of numeric values or simple events. Such approaches fail to capture the reasoning underlying real-world EHR documentation, including clinical interpretation, event relations, and temporal changes. To address this gap, we introduce EHR-ReasonCon, a reasoning-intensive benchmark for note-table consistency verification. Built on MIMIC-III with expert-guided annotations, it comprises 8,048 entities derived from clinical notes and provides high-quality ground-truth labels. The annotation protocol is supported by specialized table-exploration tools to ensure systematic evidence retrieval and reliable consistency assessment. We also propose EHR-Inspector, an LLM-based framework that segments notes, extracts anchor entities and temporal references, and uses table-exploration tools to verify consistency against structured tables. Evaluated using expert-validated LLM-as-a-judge metrics under harsh and lenient criteria, EHR-Inspector achieves state-of-the-art performance across multiple model backbones. Analyses further demonstrate the effectiveness of its components and highlight differences from human verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EHR-ReasonCon, a reasoning-intensive benchmark for verifying consistency between unstructured clinical notes and structured tables in EHRs, constructed from MIMIC-III with 8,048 entities and expert-guided annotations supported by table-exploration tools. It proposes EHR-Inspector, an LLM-based framework that segments notes, extracts anchor entities and temporal references, and applies table-exploration tools for verification. The work claims that EHR-Inspector achieves state-of-the-art performance across multiple model backbones when evaluated with expert-validated LLM-as-a-judge metrics under harsh and lenient criteria, and provides analyses of component effectiveness and differences from human verification.
Significance. If the central claims hold, the work fills a gap between surface-level numeric matching and reasoning-intensive consistency checks in EHRs, which has direct relevance to patient safety. The creation of a dedicated benchmark with 8,048 entities and the modular LLM framework represent concrete contributions that could support future evaluation of medical reasoning capabilities in LLMs.
major comments (2)
- [Abstract] Abstract: The assertion that the expert-guided annotation protocol with table-exploration tools 'ensures systematic evidence retrieval and reliable consistency assessment' for producing 'high-quality ground-truth labels' supplies no quantitative safeguards (inter-annotator agreement, number of experts per item, disagreement resolution procedure, or independent blind validation). This is load-bearing for the SOTA claim because label noise in temporal or interpretive cases would affect all backbone comparisons equally.
- [Abstract] Abstract: The SOTA performance claim is stated without any numeric results, baseline comparisons, ablation values, or error analysis, preventing assessment of effect size or robustness; the central empirical claim therefore cannot be evaluated from the provided description.
minor comments (1)
- The abstract would be strengthened by including at least one key performance number (e.g., accuracy or F1 under harsh criteria) to ground the SOTA statement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We will revise the abstract to include additional concrete details on the annotation protocol and key empirical results, while preserving the high-level nature of the summary.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the expert-guided annotation protocol with table-exploration tools 'ensures systematic evidence retrieval and reliable consistency assessment' for producing 'high-quality ground-truth labels' supplies no quantitative safeguards (inter-annotator agreement, number of experts per item, disagreement resolution procedure, or independent blind validation). This is load-bearing for the SOTA claim because label noise in temporal or interpretive cases would affect all backbone comparisons equally.
Authors: We agree that the abstract would be strengthened by referencing available quantitative or procedural details on annotation quality. In the revised version, we will expand the abstract to note the number of experts, the disagreement resolution procedure, and the role of the table-exploration tools in systematic evidence retrieval. The full manuscript already describes the expert-guided protocol in the methods; we will ensure these elements are highlighted in the abstract to better support the reliability of the ground-truth labels without overstating unmeasured metrics such as inter-annotator agreement. revision: yes
-
Referee: [Abstract] Abstract: The SOTA performance claim is stated without any numeric results, baseline comparisons, ablation values, or error analysis, preventing assessment of effect size or robustness; the central empirical claim therefore cannot be evaluated from the provided description.
Authors: The abstract is written as a concise overview, with all numeric results, baseline comparisons, ablation studies, and error analyses provided in the experiments and analysis sections of the full manuscript. To allow direct assessment from the abstract, we will add key performance figures (e.g., improvements under harsh and lenient criteria across backbones) and a brief reference to the evaluation setup in the revised abstract. revision: yes
Circularity Check
No circularity; empirical evaluation on newly introduced benchmark
full rationale
The paper introduces EHR-ReasonCon (new benchmark with expert annotations) and EHR-Inspector (new framework), then reports empirical SOTA results on that benchmark using LLM-as-a-judge metrics. No equations, fitted parameters, predictions, or derivations appear. No self-citation chains, uniqueness theorems, or ansatzes are invoked to support central claims. The annotation protocol is described as expert-guided but the evaluation does not reduce to self-definition or fitted inputs by construction. This matches the default case of a self-contained empirical paper against its own artifacts.
Axiom & Free-Parameter Ledger
axioms (1)
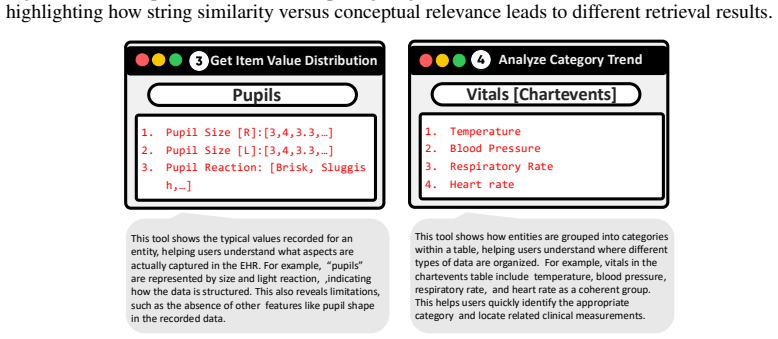
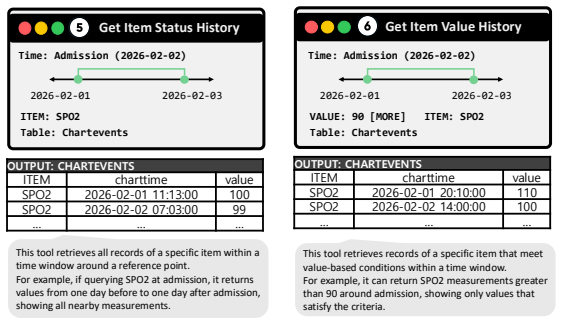
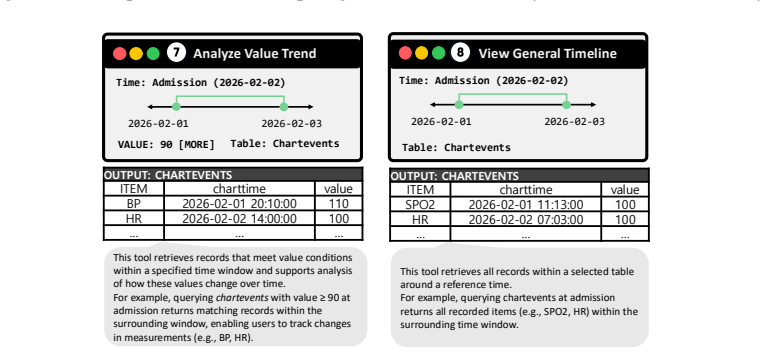
- domain assumption Expert-guided annotations with specialized table-exploration tools produce high-quality ground-truth labels for consistency assessment.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
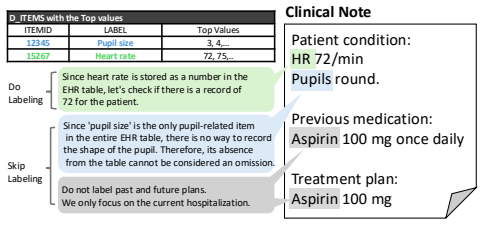
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Scibert: A pretrained language model for scientific text
Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pretrained language model for scientific text. InProceedings of EMNLP-IJCNLP, pages 3615–3620, 2019
2019
-
[3]
Variation in physicians’ electronic health record documentation and potential patient harm from that variation.Journal of general internal medicine, 34(11):2355–2367, 2019
Genna R Cohen, Charles P Friedman, Andrew M Ryan, Caroline R Richardson, and Julia Adler-Milstein. Variation in physicians’ electronic health record documentation and potential patient harm from that variation.Journal of general internal medicine, 34(11):2355–2367, 2019
2019
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Health professionals’ routine practice documentation and its associated factors in a resource-limited setting: a cross-sectional study
Addisalem Workie Demsash, Sisay Yitayih Kassie, et al. Health professionals’ routine practice documentation and its associated factors in a resource-limited setting: a cross-sectional study. BMJ Health & Care Informatics, 30(1):e100699, 2023
2023
-
[6]
Clinical natural language processing for secondary uses.Journal of Biomedical Informatics, 150:104596, Feb 2024
Yanjun Gao, Diwakar Mahajan, Özlem Uzuner, and Meliha Yetisgen. Clinical natural language processing for secondary uses.Journal of Biomedical Informatics, 150:104596, Feb 2024
2024
-
[7]
Characterizing the value of information in medical notes
Chao-Chun Hsu, Shantanu Karnwal, Sendhil Mullainathan, Ziad Obermeyer, and Chenhao Tan. Characterizing the value of information in medical notes. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 2062–2072, 2020
2020
-
[8]
Chuang Jiang, Mingyue Cheng, Xiaoyu Tao, Qingyang Mao, Jie Ouyang, and Qi Liu. Table- mind: An autonomous programmatic agent for tool-augmented table reasoning.arXiv preprint arXiv:2509.06278, 2025
-
[9]
Mimic-iv.PhysioNet
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Steven Horng, Leo Anthony Celi, and Roger Mark. Mimic-iv.PhysioNet. Available online at: https://physionet. org/content/mimi- civ/1.0/(accessed August 23, 2021), pages 49–55, 2020
2021
-
[10]
MIMIC-III Clinical Database.PhysioNet, September 2016
Alistair Johnson, Tom Pollard, and Roger Mark. MIMIC-III Clinical Database.PhysioNet, September 2016. Version 1.4
2016
-
[11]
Mimicause: Representation and automatic extraction of causal relation types from clinical notes
Vivek Khetan, Md Imbesat Rizvi, Jessica Huber, Paige Bartusiak, Bogdan Sacaleanu, and Andrew Fano. Mimicause: Representation and automatic extraction of causal relation types from clinical notes. InFindings of the association for computational linguistics: ACL 2022, pages 764–773, 2022
2022
-
[12]
Ehrcon: Dataset for checking consistency between unstructured notes and structured tables in electronic health records
Yeonsu Kwon, Jiho Kim, Gyubok Lee, Seongsu Bae, Daeun Kyung, Wonchul Cha, Tom Pollard, Alistair Johnson, and Edward Choi. Ehrcon: Dataset for checking consistency between unstructured notes and structured tables in electronic health records. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2024. 10
2024
-
[13]
An end-to-end hybrid algorithm for automated medication discrepancy detection.BMC Medical Informatics and Decision Making, 15(1):37, 2015
Qi Li, Stephen Andrew Spooner, Megan Kaiser, Nataline Lingren, Jessica Robbins, Todd Lingren, Huaxiu Tang, Imre Solti, and Yizhao Ni. An end-to-end hybrid algorithm for automated medication discrepancy detection.BMC Medical Informatics and Decision Making, 15(1):37, 2015
2015
-
[14]
Seger, Kimberly G
Ying-Chih Lo, Sheril Varghese, Suzanne Blackley, Diane L. Seger, Kimberly G. Blumenthal, Foster R. Goss, and Li Zhou. Reconciling allergy information in the electronic health record after a drug challenge using natural language processing.Frontiers in Allergy, 3:904923, 2022
2022
-
[15]
TART: An open- source tool-augmented framework for explainable table-based reasoning
Xinyuan Lu, Liangming Pan, Yubo Ma, Preslav Nakov, and Min-Yen Kan. TART: An open- source tool-augmented framework for explainable table-based reasoning. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational Linguistics: NAACL 2025, pages 4323–4339, Albuquerque, New Mexico, April 2025. Association for Computatio...
2025
-
[16]
Mark Machina and Marciano Siniscalchi.Ambiguity and Ambiguity Aversion, volume 1. 12 2014
2014
-
[17]
Liv Mathiesen, Tram Bich Michelle Nguyen, Ingrid Dæhlen, Morten Mowé, and Marianne Lea. Effect of integrated medicines management on quality of discharge medication information—a secondary endpoint in a randomized controlled trial.International Journal for Quality in Health Care, 36(4):mzae100, 2024
2024
-
[18]
Clinical ner model
Saketh Mattupalli. Clinical ner model. https://huggingface.co/blaze999/ clinical-ner, 2023. HuggingFace model for clinical named entity recognition, fine-tuned from DeBERTa-v3-base
2023
-
[19]
Denis Newman-Griffis, Guy Divita, Bart Desmet, Ayah Zirikly, Carolyn P Rosé, and Eric Fosler-Lussier. Ambiguity in medical concept normalization: An analysis of types and coverage in electronic health record datasets.Journal of the American Medical Informatics Association, 28(3):516–532, 2021
2021
-
[20]
Temporal expression classification and normalization from chinese narrative clinical texts: Pattern learning approach
Xiaoyi Pan, Boyu Chen, Heng Weng, Yongyi Gong, and Yingying Qu. Temporal expression classification and normalization from chinese narrative clinical texts: Pattern learning approach. JMIR Med Inform, 8(7):e17652, Jul 2020
2020
-
[21]
Communication at transitions of care.Pediatric Clinics, 66(4):751–773, 2019
Shilpa J Patel and Christopher P Landrigan. Communication at transitions of care.Pediatric Clinics, 66(4):751–773, 2019
2019
-
[22]
Using voice to create inpatient progress notes: effects on note timeliness, quality, and physician satisfaction.JAMIA open, 1(2):218–226, 2018
Thomas H Payne, W David Alonso, J Andrew Markiel, Kevin Lybarger, Ross Lordon, Meliha Yetisgen, Jennifer M Zech, and Andrew A White. Using voice to create inpatient progress notes: effects on note timeliness, quality, and physician satisfaction.JAMIA open, 1(2):218–226, 2018
2018
-
[23]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Chen, Eric Fosler-Lussier, and Albert M
Preethi Raghavan, James L. Chen, Eric Fosler-Lussier, and Albert M. Lai. How essential are unstructured clinical narratives and information fusion to clinical trial recruitment? InAMIA Joint Summits on Translational Science Proceedings, volume 2014, pages 218–223, Apr 2014
2014
-
[25]
Deciphering clinical abbreviations with a privacy protecting machine learning system.Nature communications, 13(1):7456, 2022
Alvin Rajkomar, Eric Loreaux, Yuchen Liu, Jonas Kemp, Benny Li, Ming-Jun Chen, Yi Zhang, Afroz Mohiuddin, and Juraj Gottweis. Deciphering clinical abbreviations with a privacy protecting machine learning system.Nature communications, 13(1):7456, 2022
2022
-
[26]
Automatic detection of inconsistencies between free text and coded data in sarcoma discharge letters
Ruty Rinott, Michele Torresani, Rossella Bertulli, Abigail Goldsteen, Paolo Casali, Boaz Carmeli, and Noam Slonim. Automatic detection of inconsistencies between free text and coded data in sarcoma discharge letters. InStudies in Health Technology and Informatics, volume 180, pages 661–666, 2012
2012
-
[27]
Data from clinical notes: a perspective on the tension between structure and flexible documentation.Journal of the American Medical Informatics Association, 18(2):181–186, 2011
S Trent Rosenbloom, Joshua C Denny, Hua Xu, Nancy Lorenzi, William W Stead, and Kevin B Johnson. Data from clinical notes: a perspective on the tension between structure and flexible documentation.Journal of the American Medical Informatics Association, 18(2):181–186, 2011. 11
2011
-
[28]
Seinen, Jan A
Tom M. Seinen, Jan A. Kors, Erik M. van Mulligen, and Peter R. Rijnbeek. Using structured codes and free-text notes to measure information complementarity in electronic health records: Feasibility and validation study.Journal of Medical Internet Research, 27, 2024
2024
-
[29]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Temporal annotation in the clinical domain.Transactions of the association for computational linguistics, 2:143–154, 2014
William F Styler IV , Steven Bethard, Sean Finan, Martha Palmer, Sameer Pradhan, Piet C De Groen, Brad Erickson, Timothy Miller, Chen Lin, Guergana Savova, et al. Temporal annotation in the clinical domain.Transactions of the association for computational linguistics, 2:143–154, 2014
2014
-
[32]
Safe practices for copy and paste in the ehr: Systematic review, recommendations, and novel model for health it collaboration.Applied Clinical Informatics, 8(1):12–34, 2017
Amy Y Tsou, Christoph U Lehmann, Jeremy Michel, Ronni Solomon, Lorraine Possanza, and Tejal Gandhi. Safe practices for copy and paste in the ehr: Systematic review, recommendations, and novel model for health it collaboration.Applied Clinical Informatics, 8(1):12–34, 2017
2017
-
[33]
South, Shuying Shen, and Scott L
Ozlem Uzuner, Brett R. South, Shuying Shen, and Scott L. DuVall. 2010 i2b2/va challenge on concepts, assertions, and relations in clinical text.Journal of the American Medical Informatics Association, 18(5):552–556, 2011
2010
-
[34]
A review on usability features for designing elec- tronic health records
Luis Bernardo Villa and Ivan Cabezas. A review on usability features for designing elec- tronic health records. In2014 IEEE 16th International Conference on e-Health Networking, Applications and Services (Healthcom), pages 49–54, 2014
2014
-
[35]
Clinical information extraction applications: A literature review.Journal of Biomedical Informatics, 77:34–49, 2018
Yanshan Wang, Liwei Wang, Majid Rastegar-Mojarad, Sungrim Moon, Feichen Shen, Naveed Afzal, Sijia Liu, Yuqun Zeng, Saeed Mehrabi, Sunghwan Sohn, and Hongfang Liu. Clinical information extraction applications: A literature review.Journal of Biomedical Informatics, 77:34–49, 2018
2018
-
[36]
Ziwei Wang, Jiayuan Su, Mengyu Zhou, Huaxing Zeng, Mengni Jia, Xiao Lv, Haoyu Dong, Xiaojun Ma, Shi Han, and Dongmei Zhang. Sheetbrain: A neuro-symbolic agent for accurate reasoning over complex and large spreadsheets.arXiv preprint arXiv:2510.19247, 2025
-
[37]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art na...
2020
-
[38]
Tablezoomer: a collaborative agent framework for large-scale table question answering.Vicinagearth, 2(1):1–23, 2025
Sishi Xiong, Ziyang He, Zhongjiang He, Yu Zhao, Changzai Pan, Jie Zhang, Shuangyong Song, and Yongxiang Li. Tablezoomer: a collaborative agent framework for large-scale table question answering.Vicinagearth, 2(1):1–23, 2025
2025
-
[39]
Llm-based agents for tool learning: A survey.Data Science and Engineering, 10:533–563, 2025
Weikai Xu, Chengrui Huang, Shen Gao, and Shuo Shang. Llm-based agents for tool learning: A survey.Data Science and Engineering, 10:533–563, 2025
2025
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Stidham, and V
Deahan Yu, Ryan W. Stidham, and V . G. Vinod Vydiswaran. A systematic temporal extraction pipeline for medical concepts in clinical notes. InAMIA Annual Symposium Proceedings, volume 2023, pages 1314–1323, Jan 2024
2023
-
[42]
A text structuring method for chinese medical text based on temporal information.International journal of environmental research and public health, 15(3):402, 2018
Runtong Zhang, Fuzhi Chu, Donghua Chen, and Xiaopu Shang. A text structuring method for chinese medical text based on temporal information.International journal of environmental research and public health, 15(3):402, 2018. 12
2018
-
[43]
Yuhang Zhou, Mingrui Zhang, Ke Li, Mingyi Wang, Qiao Liu, Qifei Wang, Jiayi Liu, Fei Liu, Serena Li, Weiwei Li, et al. Mixture-of-minds: Multi-agent reinforcement learning for table understanding.arXiv preprint arXiv:2510.20176, 2025. 13 Supplementary Contents A Dataset Details 16 A.1 Tables and Columns inEHR-ReasonCon. . . . . . . . . . . . . . . . . . ....
-
[44]
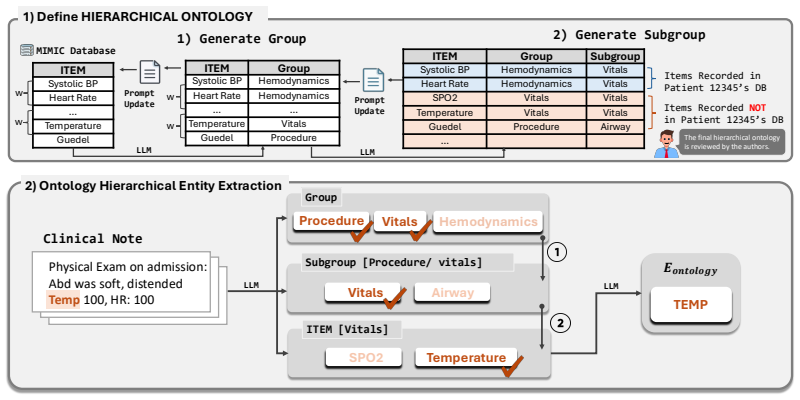
Generate Group 2) Generate Subgroup Items Recorded in Patient 12345’sDB Items Recorded NOT in Patient 12345’sDB
-
[45]
Define HIERARCHICAL ONTOLOGY Physical Exam on admission: Abd was soft, distended Tem p 100, HR: 100 Clinical Note
-
[46]
Temp: 100
Ontology Hierarchical Entity Extraction Procedure Vitals Hemodynamics Group Vitals Subgroup [Procedure/ vitals] Airway SPO2 ITEM [Vitals] Te mp e rature TEMP 𝑬𝒐𝒏𝒕𝒐𝒍𝒐𝒈𝒚 w w w w The final hierarchical ontology is reviewed by the authors.LLM LLM LLM LLM Figure 17: Overview of ontology-guided entity extraction. item set. For example,Systolic BP–Hemodynamicsan...
-
[47]
Intravenous fluids were initiated
-
[48]
T” recorded in the note is an abbreviation for temperature and is semantically linked to this entity. Therefore, the numeric value “97
Vitals: T: 97 BP: 94/49 on 0.06 levophed Output: Line number 0. Intravenous fluids: [] - [IV site 1] →Rationale: The initiation of IV can be associated with IV Site 1. Line number 1. T: [97] - [Temperature Fahrenheit] → Rationale: In the pre-defined list, the Temperature Fahrenheit entity holds temperature values. The “T” recorded in the note is an abbrev...
-
[49]
Item_Search • N-gram based cosine similarity for label matching
-
[50]
Patient-Centric Tools Tools that set time conditions based on an individual patient’s admission time to verify whether specific events actually occurred
Top_Values_for_Entities • Aggregates the top-N values that frequently appear for a specific item in a particular table across the entire dataset. Patient-Centric Tools Tools that set time conditions based on an individual patient’s admission time to verify whether specific events actually occurred
-
[51]
Semantic_Search • Searches for similar items within a patient’s table based on input keywords such as test names or medication names using meaning-based matching
-
[52]
Table_Value_Time • Searches for data that simultaneously satisfies both value and time conditions based on individual patient criteria
-
[53]
Table_Category_Time • Verifies the existence of events within a patient’s time conditions based on an item’s category
-
[54]
Table_Time • Filters based solely on time conditions without value or category conditions
-
[55]
Table_Selected_Item_Time • You must use the item names exactly as they appear in the name column (i.e.,LABEL or DRUG) of the table obtained through the previous search steps, because items need to be searched using those exact expressions
-
[56]
Table_Selected_Item_Value_Time • You must use the item names exactly as they appear in the name column (i.e.,LABEL or DRUG) of the table obtained through the previous search steps, because items need to be searched using those exact expressions. Use the available tools to check whether the information about specific entities such as symptoms, test results...
-
[57]
A clinical note may contain multiple claims, and each claim should be evaluated independently
-
[58]
The goal of this task is to determine whether the factual statements explicitly mentioned in the clinical note are present in the structured EHR data
-
[59]
If the value in the clinical note can be considered medically consistent with the value in the structured table, it should be labeledConsistent
-
[60]
If a note clearly includes a timestamp in the format of YYYY-MM-DD or YYYY-MM-DD HH:MM:SS, the event must be recorded exactly on that date or at that time in order to be consideredConsistent
-
[61]
Output Requirements For each claim, provide the following items
If it is noted that medication was prescribed forndays, but the patient was discharged during that period, and the prescription in the table ends on the discharge date, this case is consideredConsistent. Output Requirements For each claim, provide the following items. 1.Single Fact • For clinical notes with multiple facts, clearly state the individual fac...
-
[62]
Contradictory Evidence Inconsistent: The structured EHR table contains data that clearly contradicts the claim in the clinical note
-
[63]
soft” and “distended,
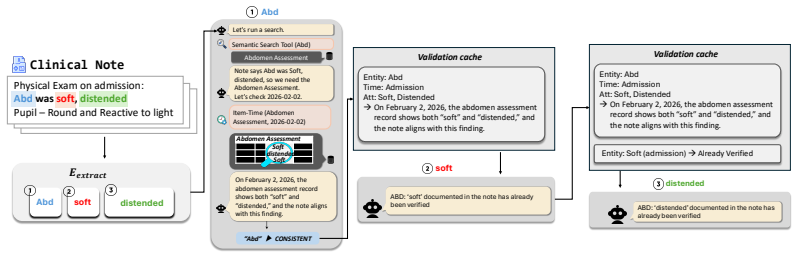
Information Missing Inconsistent (NEI): The claim is clearly stated in the clinical note, but the structured EHR table contains no relevant information at all. <<<<Examples>>>> Figure 27: Prompt Template for Final Verification. 41 Clinical Note Physical Exam on admission: Abd was soft, distended Pupil – Round and Reactive to light Abd 𝑬𝒆𝒙𝒕𝒓𝒂𝒄𝒕 soft disten...
2026
-
[64]
who” and “when
Core Tables (The Foundation) These tables define the “who” and “when” of the data. •PATIENTS:Contains one row per patient. –Columns:subject_id,gender,dob,dod(date of death). •ADMISSIONS:Tracks each unique hospital visit. – Columns: subject_id, hadm_id, admittime, dischtime, admission_type, insurance,religion,marital_status,ethnicity. • ICUSTAYS:Defines st...
-
[65]
abnormal
Event Tables (The Clinical Data) These are the largest tables, containing longitudinal data points timestamped to the patient’s stay. •CHARTEVENTS:The largest table. Contains all charted data for a patient (vitals, sensor data, etc.). 48 – Columns: subject_id, hadm_id, icustay_id, itemid, charttime, valuenum, valueuom(unit of measurement). •LABEVENTS:Cont...
-
[66]
oldest old
Dictionary Tables To keep the database normalized, specific codes are mapped to human-readable labels in “D” tables. •D_ICD_DIAGNOSES:Maps ICD codes to diagnosis descriptions. • D_ITEMS:Maps the itemid found in CHARTEVENTS to what it actually represents (e.g., Heart Rate, GCS, Temperature). •D_LABITEMS:Maps theitemidinLABEVENTSto the specific lab test nam...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.