Beyond Pairwise Preferences: Listwise Reward-Aware Alignment for Diffusion Models
Pith reviewed 2026-06-29 19:35 UTC · model grok-4.3
The pith
Diffusion LAIR aligns text-to-image diffusion models by turning continuous reward scores into listwise advantage weights instead of using pairwise winner-loser labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
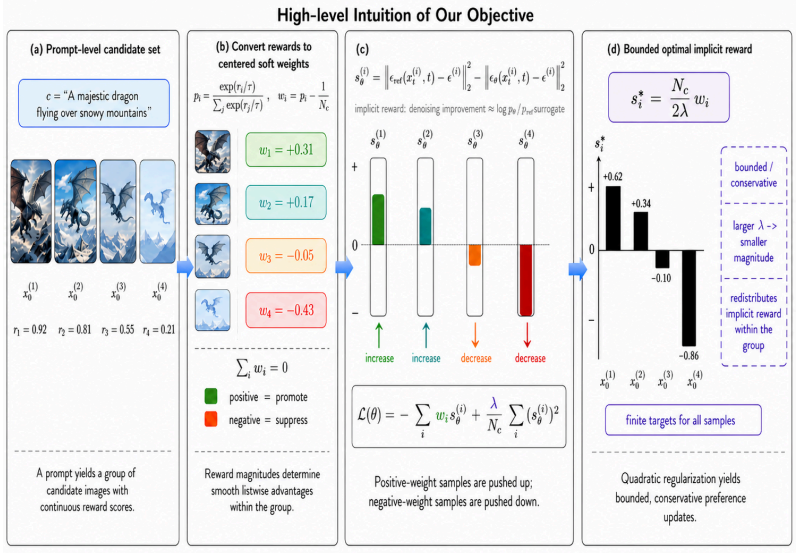
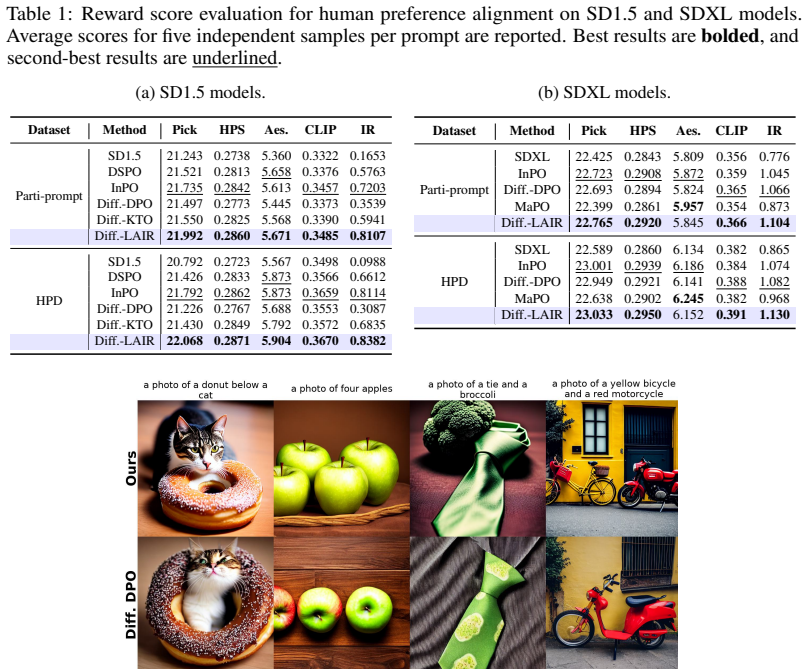
For each prompt, reward scores across candidate images are converted into centered advantage weights; the model then optimizes an advantage-weighted regression objective on the implicit reward (denoising-loss improvement over a reference) with an added quadratic penalty that keeps the implicit reward magnitude bounded, yielding a closed-form optimum and outperforming pairwise baselines on SD1.5 and SDXL for text-to-image, compositional, and editing tasks.
What carries the argument
The LAIR objective: advantage-weighted regression on implicit reward (denoising-loss improvement over reference) with quadratic penalty, which admits a bounded closed-form optimum in implicit-reward space.
If this is right
- All candidate images per prompt are used simultaneously rather than reduced to selected pairs.
- The quadratic penalty explicitly limits the magnitude of the implicit-reward update.
- The resulting objective has a closed-form solution whose size is controlled by the regularization strength.
- Performance gains appear across text-to-image generation, compositional generation, and image editing on both SD1.5 and SDXL.
Where Pith is reading between the lines
- The listwise formulation could extend to other generative architectures that already produce multiple samples per conditioning input.
- If the external reward model itself contains systematic biases, centering and weighting may propagate those biases into the diffusion updates.
- The closed-form optimum suggests a route to adaptive regularization schedules that depend on observed reward variance per prompt.
Load-bearing premise
Continuous reward scores are reliable and their conversion into centered advantage weights supplies a more informative training signal than binary pairwise labels.
What would settle it
If Diffusion LAIR shows no improvement or underperforms the strongest pairwise baseline on the same SD1.5 text-to-image benchmark when using identical reward scores, the central claim would be falsified.
Figures





read the original abstract
Preference optimization has emerged as an efficient alternative to online reinforcement learning from human feedback (RLHF) for aligning text-to-image diffusion models. However, existing methods largely reduce supervision to binary pairwise comparisons. This pairwise reduction is limiting when training data naturally contains multiple candidate images for the same prompt, and when continuous reward scores can provide richer information than a single winner-loser label. To address these limitations, we propose Diffusion LAIR, a reward-aware listwise preference optimization method for diffusion models. For each prompt, LAIR converts reward scores across a group of candidate images into centered advantage weights, then optimizes an advantage-weighted regression objective on the implicit reward, defined as the denoising-loss improvement of the current model over a fixed reference model, with a quadratic penalty that regularizes the magnitude of the implicit reward. The resulting objective uses all candidates simultaneously rather than selecting pairs, and remains conservative by explicitly controlling the magnitude of the implicit reward. The LAIR objective admits a bounded closed-form optimum in implicit-reward space, clarifying how the regularization strength controls the magnitude of the preference update. Experiments show that Diffusion LAIR outperforms strong preference optimization baselines on SD1.5 and SDXL across text-to-image generation, compositional generation, and image editing benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Diffusion LAIR, a listwise reward-aware preference optimization method for text-to-image diffusion models. For each prompt, continuous reward scores across multiple candidate images are converted to centered advantage weights; these weights are then used in an advantage-weighted regression objective on the implicit reward (defined as the improvement in denoising loss relative to a fixed reference model), subject to a quadratic penalty that regularizes the magnitude of the implicit reward. The objective is shown to admit a bounded closed-form optimum in implicit-reward space. Experiments are reported to demonstrate that LAIR outperforms strong pairwise preference optimization baselines on SD1.5 and SDXL across text-to-image generation, compositional generation, and image editing benchmarks.
Significance. If the experimental claims hold under controlled conditions, the work would offer a concrete way to exploit listwise data and continuous reward signals rather than reducing to binary pairs, together with a closed-form characterization of the regularization effect. The explicit quadratic penalty and closed-form optimum constitute a modest theoretical contribution that clarifies the magnitude of the preference update.
major comments (3)
- [§4] §4 (Experiments): The headline claim that listwise advantage weighting supplies a strictly more informative gradient than pairwise DPO-style objectives requires an ablation that holds the candidate set, reward model, and total compute fixed while switching only the objective (listwise centered advantage weights vs. pairwise winner-loser reduction). No such controlled comparison is described; without it the observed gains cannot be attributed to the listwise formulation rather than differences in data or reward model.
- [§3.2] §3.2 (LAIR objective): The claim that the quadratic penalty 'correctly controls update magnitude' is load-bearing for the conservatism argument. The manuscript should derive or empirically verify that the resulting implicit-reward optimum remains bounded independently of the number of candidates and that the bound scales predictably with the regularization strength; the current closed-form statement does not yet address this scaling.
- [§4.1–4.3] §4.1–4.3 (Benchmarks): The abstract and experimental sections report outperformance on SD1.5 and SDXL but supply no information on the reward model used to obtain the continuous scores, the procedure for generating the candidate lists, the number of candidates per prompt, or any statistical significance tests. These omissions prevent verification that the reported gains are robust rather than artifacts of a particular reward model or data construction.
minor comments (2)
- Notation for the implicit reward (denoising-loss delta) should be introduced once with a clear symbol and reused consistently; occasional redefinition across sections reduces readability.
- The manuscript should cite the specific pairwise baselines (e.g., Diffusion-DPO, etc.) with version numbers or exact implementation references so that reproduction is unambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where they strengthen the work.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The headline claim that listwise advantage weighting supplies a strictly more informative gradient than pairwise DPO-style objectives requires an ablation that holds the candidate set, reward model, and total compute fixed while switching only the objective (listwise centered advantage weights vs. pairwise winner-loser reduction). No such controlled comparison is described; without it the observed gains cannot be attributed to the listwise formulation rather than differences in data or reward model.
Authors: We agree that isolating the objective via a controlled ablation is the cleanest way to attribute gains to the listwise formulation. The current experiments compare against pairwise baselines but do not hold candidate sets, reward model, and compute exactly fixed in the manner requested. We will add this ablation in the revision, using identical candidate lists and reward signals for both the listwise advantage-weighted objective and the pairwise reduction. revision: yes
-
Referee: [§3.2] §3.2 (LAIR objective): The claim that the quadratic penalty 'correctly controls update magnitude' is load-bearing for the conservatism argument. The manuscript should derive or empirically verify that the resulting implicit-reward optimum remains bounded independently of the number of candidates and that the bound scales predictably with the regularization strength; the current closed-form statement does not yet address this scaling.
Authors: The closed-form optimum derived in §3.2 already demonstrates boundedness for a given candidate set and shows explicit dependence on the regularization strength λ. We acknowledge that the explicit scaling of the bound with the number of candidates is not analyzed. Because advantages are centered, the weights sum to zero independently of list size; we will extend the derivation in the revision to prove that the bound on the implicit-reward optimum is independent of the number of candidates and scales as O(1/λ). revision: yes
-
Referee: [§4.1–4.3] §4.1–4.3 (Benchmarks): The abstract and experimental sections report outperformance on SD1.5 and SDXL but supply no information on the reward model used to obtain the continuous scores, the procedure for generating the candidate lists, the number of candidates per prompt, or any statistical significance tests. These omissions prevent verification that the reported gains are robust rather than artifacts of a particular reward model or data construction.
Authors: We will revise §§4.1–4.3 (and the appendix) to report: (i) the exact reward model and its training details, (ii) the candidate-list generation procedure, (iii) the number of candidates per prompt, and (iv) statistical significance tests (paired t-tests across seeds) for all main results. These details were omitted for brevity but are straightforward to include. revision: yes
Circularity Check
No significant circularity; derivation self-contained from listwise regression principles
full rationale
The paper presents Diffusion LAIR as converting reward scores to centered advantage weights and optimizing an advantage-weighted regression on the implicit reward (denoising-loss delta) with quadratic penalty, admitting a closed-form optimum. This is framed as derived from listwise regression principles rather than reducing by construction to fitted inputs or self-citations. No load-bearing step in the abstract or described objective equates a prediction to its own inputs via definition or prior self-work. Experiments provide external comparison to baselines on fixed models, keeping the central claim independent of any internal fit renamed as prediction. Score 0 is appropriate as the most common honest finding for self-contained proposals.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization strength
axioms (1)
- domain assumption Implicit reward equals denoising-loss improvement of current model over fixed reference model.
Reference graph
Works this paper leans on
-
[1]
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
1, 3 Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017. 3 Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.174...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Scalable ranked preference optimization for text-to-image generation
3 10 Shyamgopal Karthik, Huseyin Coskun, Zeynep Akata, Sergey Tulyakov, Jian Ren, and Anil Kag. Scalable ranked preference optimization for text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 18399–18410, 2025. 3 Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pi...
-
[3]
Score-Based Generative Modeling through Stochastic Differential Equations
Accessed: 2023-11-10. 8 Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020. 3 Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Fine-Tuning Language Models from Human Preferences
1, 3, 8, 9 Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019. 3 13 A Proofs A.1 Optimal Implicit Reward Proof Proof of Proposition 1. For a fixed prompt c, timestep t, noise realizations {ϵi}Nc...
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[5]
a photo of a green cup and a red pizza
dataset. We randomly sample 1000 image-prompt pairs from InstructPix2Pix and use SDEdit (Meng et al., 2021) with a noise strength of 0.6 to generate image edits. For each prompt we generate 5 images, with random seeds standardized across evaluation runs, and compute average reward scores. The win rate of a model against SDXL is computed as the ratio of im...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.