ChainCaps: Composition-Safe Tool-Using Agents via Monotonic Capability Attenuation
Pith reviewed 2026-06-29 17:30 UTC · model grok-4.3
The pith
ChainCaps stops permission laundering by intersecting sink-specific capability budgets during tool composition so authority never increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
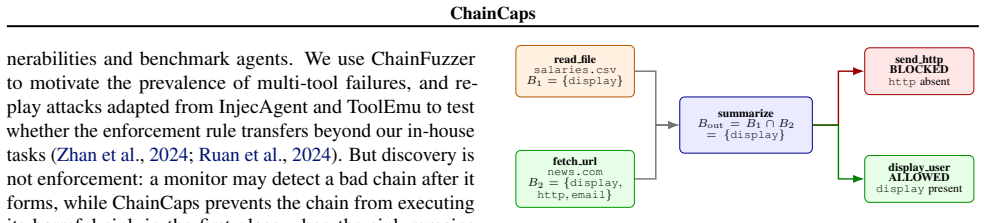
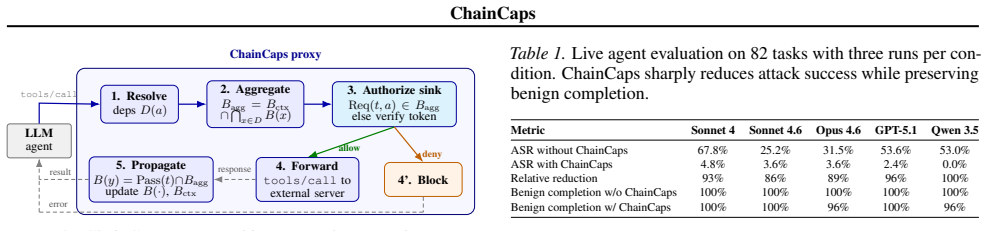
ChainCaps enforces monotonic capability attenuation: every value carries a sink-specific budget, composition takes the intersection of budgets, and therefore a value can preserve or lose authority but cannot gain new authority through any sequence of tools.
What carries the argument
Sink-specific capability budget attached to each value and reduced by intersection on every tool step.
If this is right
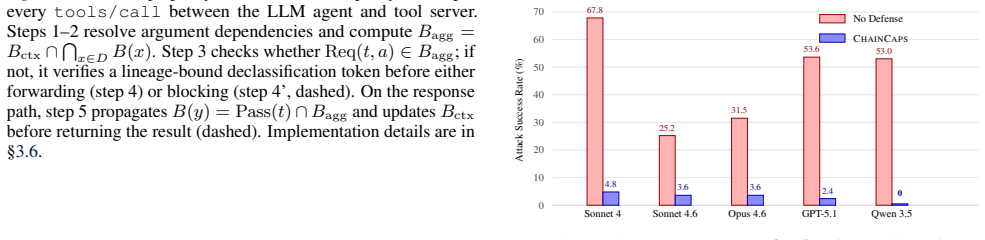
- Attack success falls from 25-68 percent to 0-4.8 percent on the tested tasks.
- Benign completion stays between 96 and 100 percent.
- The method outperforms scalar-IFC and per-function isolation baselines in replay experiments.
- Expert manifests reach 100 percent attack blocking while naive manifests reach only 27.3 percent.
Where Pith is reading between the lines
- Better automated manifest generation would reduce the main deployment bottleneck.
- The same intersection rule could be tested on implicit flows if the proxy gains visibility into internal agent state.
- Attenuation budgets could be applied to other composition points such as multi-agent hand-offs.
Load-bearing premise
Manifests correctly list the permissions of every tool and the proxy can see every data movement between tools.
What would settle it
An agent completing a laundering sequence such as reading a confidential file, summarizing it, and sending the summary to an external sink despite the proxy, or a legitimate task failing solely because of budget intersection.
Figures
read the original abstract
Tool-using agents increasingly operate in open-ended deployment environments, where they compose file systems, web APIs, code interpreters, and enterprise services at runtime. This creates a safety gap in tool composition: an agent can satisfy every per-tool permission check and still produce an unsafe end-to-end effect, such as reading a confidential document, summarizing it, and sending the summary to an external endpoint. We call this failure mode permission laundering. ChainCaps addresses it with a runtime rule: every value carries a sink-specific capability budget, and tool composition propagates budgets by intersection. A value can preserve or lose authority as it moves through a tool chain, but it cannot gain new authority through composition. We implement ChainCaps as a transparent MCP proxy that requires no changes to the agent or tool servers. On 82 tasks across five frontier models from three providers, ChainCaps reduces attack success rate from 25-68% to 0-4.8% while preserving 96-100% benign completion. In replay experiments, it also outperforms scalar-IFC and per-function-isolation baselines. Manifest quality is the dominant deployment bottleneck: expert manifests reach 100% attack blocking, while naive manifests fall to 27.3%. Our claims are limited to explicit-flow composition safety under trusted manifests and proxy-visible data movement, a practical gap in deployed tool-using agents today.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChainCaps to mitigate permission laundering in tool-composing agents. It assigns sink-specific capability budgets to values and propagates them via intersection during tool chains, ensuring authority cannot increase through composition. Implemented as a transparent MCP proxy, the system is evaluated on 82 tasks across five frontier models, reducing attack success rates from 25-68% to 0-4.8% while retaining 96-100% benign completion rates. It outperforms scalar-IFC and per-function-isolation baselines, with manifest quality identified as the primary practical bottleneck. All claims are explicitly scoped to explicit-flow composition safety under trusted manifests and proxy-visible data movement.
Significance. If the results hold under the stated scope, this provides a practical, deployable mechanism for addressing composition safety gaps in tool-using agents, supported by concrete empirical evaluation across multiple models and tasks plus baseline comparisons. The clear scoping of claims and identification of manifest quality as the dominant bottleneck are strengths that enhance the work's utility for practitioners.
minor comments (1)
- The abstract and evaluation summary would benefit from a brief statement on how the 82 tasks were selected and categorized to allow readers to assess coverage of composition patterns.
Simulated Author's Rebuttal
We thank the referee for the detailed and positive review, including the clear summary of our contributions, the assessment of significance, and the recommendation to accept. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper describes a runtime capability propagation rule (intersection on budgets) and evaluates it empirically on 82 tasks across five models, reporting attack success reductions and benign completion rates against external baselines. No equations, predictions, or first-principles derivations are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. Manifest quality is identified as an external bottleneck with explicit experimental comparison (expert vs. naive). The work is scoped to explicit-flow safety under trusted manifests and contains no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Trusted manifests and proxy-visible data movement suffice for safety claims
invented entities (1)
-
sink-specific capability budget
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https: //arxiv.org/abs/2510.21236. Chen, J. and Cong, S. L. Agentguard: Repurposing agen- tic orchestrator for safety evaluation of tool orchestra- tion,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://arxiv.org/abs/2503.22738. Costa, M., K¨opf, B., Kolluri, A., Paverd, A., Russinovich, M., Salem, A., Tople, S., Wutschitz, L., and Zanella- B´eguelin, S. Securing ai agents with information-flow control,
-
[3]
Securing AI Agents with Information-Flow Control
URL https://arxiv.org/abs/ 2505.23643. Garby, Z., Gordon, A. D., and Sands, D. The llmbda calcu- lus: Ai agents, conversations, and information flow,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Ji, Z., Wu, D., Jiang, W., Ma, P., Li, Z., Gao, Y ., Wang, S., and Li, Y
URLhttps://arxiv.org/abs/2602.20064. Ji, Z., Wu, D., Jiang, W., Ma, P., Li, Z., Gao, Y ., Wang, S., and Li, Y . Taming various privilege escalation in llm-based agent systems: A mandatory access control framework,
-
[5]
Jiang, X., Yang, S., Yang, W., Liu, Y ., and Ji, C
URL https://arxiv.org/abs/ 2601.11893. Jiang, X., Yang, S., Yang, W., Liu, Y ., and Ji, C. Sok: A taxonomy of attack vectors and defense strategies for agentic supply chain runtime,
-
[6]
SOK: A Taxonomy of Attack Vectors and Defense Strategies for Agentic Supply Chain Runtime
URL https:// arxiv.org/abs/2602.19555. Kim, J., Choi, W., and Lee, B. Prompt flow integrity to prevent privilege escalation in llm agents,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URL https://arxiv.org/abs/2503.15547. Ruan, Y ., Dong, H., Wang, A., Pitis, S., Zhou, Y ., Ba, J., Dubois, Y ., Maddison, C. J., and Hashimoto, T. Identi- fying the risks of lm agents with an lm-emulated sand- box,
-
[8]
Xing, W., Qi, Z., Qin, Y ., Li, Y ., Chang, C., Yu, J., Lin, C., Xie, Z., and Han, M
URL https://arxiv.org/ abs/2603.12614. Xing, W., Qi, Z., Qin, Y ., Li, Y ., Chang, C., Yu, J., Lin, C., Xie, Z., and Han, M. Mcp-guard: A multi-stage defense-in-depth framework for securing model context protocol in agentic ai,
-
[9]
URL https://arxiv. org/abs/2508.10991. Zhan, Q., Liang, Z., Ying, Z., and Kang, D. Injeca- gent: Benchmarking indirect prompt injections in tool- integrated large language model agents,
-
[10]
URL https://arxiv.org/abs/2403.02691. 7
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.