Linear and Neural Dueling Bandits with Delayed Feedback
Pith reviewed 2026-06-29 19:59 UTC · model grok-4.3
The pith
A loss function embedding inverse probability weighting corrects bias from delayed feedback in contextual dueling bandits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize Contextual Dueling Bandits with Stochastic Delayed Feedback and propose LDB-DF and NDB-DF algorithms. Their central device is a novel estimator that integrates an Inverse Probability Weighting mechanism directly into the loss function, ensuring unbiased correction for delayed or missing feedback even though dueling estimators lack closed-form solutions. The resulting linear algorithm attains an O(d sqrt(T)) regret bound while the neural algorithm attains sub-linear regret.
What carries the argument
The IPW term embedded inside the loss function that produces unbiased gradient estimates for dueling comparisons under stochastic delay.
If this is right
- Linear dueling bandits achieve the same O(d sqrt(T)) regret order as the immediate-feedback case once the IPW loss is used.
- Neural dueling bandits obtain sub-linear regret under the same delay model.
- The estimator applies directly to prompt optimization and recommender systems where user responses arrive after variable delays.
- Experiments on both simulated and real-world datasets confirm that the corrected algorithms outperform naive adaptations.
Where Pith is reading between the lines
- The same loss modification may let other preference-learning methods tolerate missing or late labels without new bias terms.
- Deployment in production recommendation systems could become feasible when response latency is modeled rather than ignored.
- Extending the approach to unknown or adversarial delay distributions would require a different weighting scheme.
Load-bearing premise
The probability that any given feedback arrives is known or can be estimated without error so that the weighting term remains unbiased.
What would settle it
A controlled experiment that measures cumulative regret of LDB-DF on linear dueling instances with known delay probabilities; if the observed regret grows faster than O(d sqrt(T)), the bound is falsified.
Figures
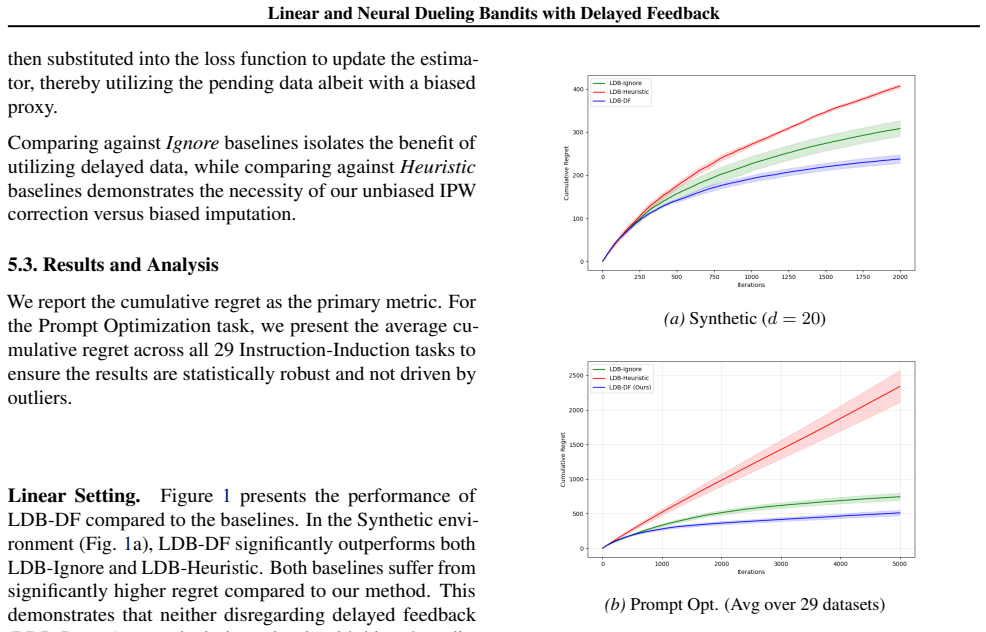
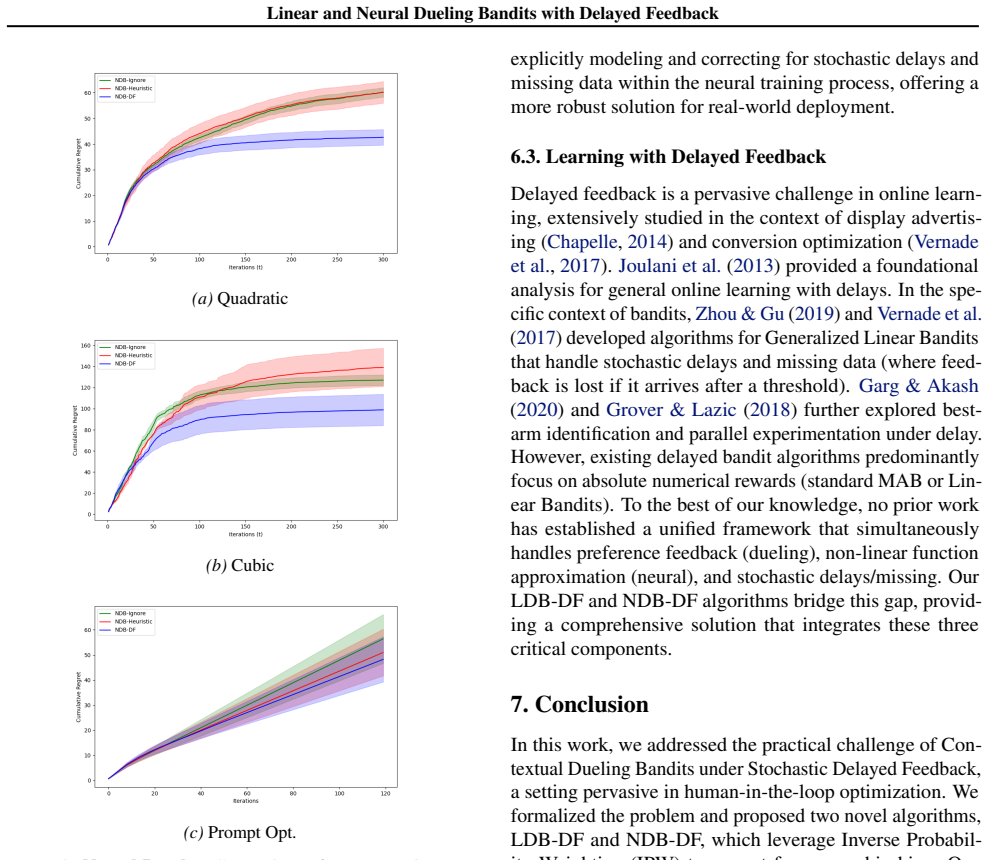
read the original abstract
Contextual dueling bandits form a cornerstone of preference-based decision-making, with critical applications in recommender systems and large language model alignment. However, standard algorithms rely on the idealized assumption of immediate feedback, a condition frequently violated in real-world scenarios such as prompt optimization. This setting introduces a unique theoretical challenge: unlike linear bandits, dueling bandit estimators lack closed-form solutions, rendering naive adaptations of standard weighting techniques biased. To address this, we formalize the problem of Contextual Dueling Bandits with Stochastic Delayed Feedback and propose two novel algorithms: Linear (LDB-DF) and Neural (NDB-DF) Dueling Bandits with Delayed Feedback. Central to our approach is a novel estimator that integrates an Inverse Probability Weighting (IPW) mechanism directly into the loss function, ensuring unbiased correction for delayed or missing feedback. We provide comprehensive theoretical analysis, establishing an O(d*sqrt(T)) regret bound for the linear setting and sub-linear guarantees for the neural setting. Extensive experiments on both simulated and real-world datasets demonstrate the effectiveness of our propose.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes contextual dueling bandits with stochastic delayed feedback and introduces two algorithms, LDB-DF (linear) and NDB-DF (neural). It proposes a novel estimator that embeds an Inverse Probability Weighting (IPW) term directly into the loss function to produce unbiased estimates despite the absence of closed-form solutions for dueling estimators. The central theoretical claims are an O(d sqrt(T)) regret bound in the linear case and sub-linear regret guarantees in the neural case, accompanied by experiments on simulated and real-world datasets.
Significance. If the IPW-integrated loss indeed yields unbiased estimators and the stated regret bounds hold, the work would meaningfully extend preference-based bandits to delayed-feedback regimes that arise in recommender systems and LLM alignment. The neural extension and the explicit handling of non-closed-form estimators would be the primary contributions.
major comments (1)
- [Abstract / theoretical analysis section] The load-bearing claim (abstract) that integrating IPW directly into the loss produces an unbiased estimator for delayed dueling feedback must be shown explicitly. Because dueling estimators lack closed-form solutions, the weighting cannot be applied to an explicit solution; the manuscript must supply the precise derivation (or lemma) establishing that the resulting implicit estimator remains unbiased and that the subsequent concentration arguments for the O(d sqrt(T)) and sub-linear bounds remain valid.
minor comments (1)
- [Abstract] The final sentence of the abstract contains a grammatical error ('our propose' should read 'our proposal' or 'our proposed method').
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on the theoretical claims. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis section] The load-bearing claim (abstract) that integrating IPW directly into the loss produces an unbiased estimator for delayed dueling feedback must be shown explicitly. Because dueling estimators lack closed-form solutions, the weighting cannot be applied to an explicit solution; the manuscript must supply the precise derivation (or lemma) establishing that the resulting implicit estimator remains unbiased and that the subsequent concentration arguments for the O(d sqrt(T)) and sub-linear bounds remain valid.
Authors: We agree that an explicit derivation is required to substantiate the unbiasedness claim, given the implicit nature of dueling estimators. In the revised manuscript we will insert a new lemma (Lemma 3.2) immediately after the problem formulation. The lemma computes the expectation of the IPW-weighted loss over the stochastic delay distribution and shows that it equals the expected loss under immediate feedback; the proof relies only on the definition of the IPW weights and linearity of expectation, without requiring a closed-form solution. The same lemma is then invoked to justify the concentration inequalities used for both the linear O(d sqrt(T)) bound and the neural sub-linear bound, so the subsequent regret analysis remains valid. revision: yes
Circularity Check
No circularity: derivation rests on independent estimator formalization and standard regret analysis
full rationale
The provided abstract and context describe a novel IPW-integrated loss estimator for delayed dueling feedback, followed by claimed O(d sqrt(T)) regret for linear and sublinear neural bounds. No quoted equation or step reduces the regret bound or unbiasedness claim to a fitted parameter, self-citation chain, or input by construction. The central theoretical analysis is presented as following from the new formalization rather than presupposing its own outputs. This matches the default expectation of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improved algorithms for linear stochastic bandits
Abbasi-Yadkori, Y., P\' a l, D., and Szepesv\' a ri, C. Improved algorithms for linear stochastic bandits. In Advances in Neural Information Processing Systems, volume 24, 2011
2011
-
[2]
Stochastic contextual dueling bandits under linear stochastic transitivity models
Bengs, V., Busa-Fekete, R., and H\" u llermeier, E. Stochastic contextual dueling bandits under linear stochastic transitivity models. In Proceedings of the 39th International Conference on Machine Learning, 2022
2022
-
[3]
Modeling delayed feedback in display advertising
Chapelle, O. Modeling delayed feedback in display advertising. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2014
2014
-
[4]
InstructZero : Efficient instruction optimization for black-box large language models
Chen, L., Chen, J., Goldstein, T., Huang, H., and Zhou, T. InstructZero : Efficient instruction optimization for black-box large language models. In Advances in Neural Information Processing Systems, 2024
2024
-
[5]
Dai, Z., Chen, Y., Low, B. K. H., Jaillet, P., and Ho, T. L. Sample-then-optimize batch neural T hompson sampling. In Advances in Neural Information Processing Systems, 2022
2022
-
[6]
Di, Q. et al. Nearly optimal algorithms for contextual dueling bandits from adversarial feedback. In Advances in Neural Information Processing Systems, 2023
2023
-
[7]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Fernando, C., Banarse, D., Michalewski, H., Osindero, S., and Rockt\" a schel, T. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
and Akash, K
Garg, S. and Akash, K. Stochastic bandits with delayed composite anonymous feedback. In Proceedings of the International Conference on Machine Learning, 2020
2020
-
[9]
and Lazic, N
Grover, A. and Lazic, N. Best arm identification in multi-armed bandits with delayed feedback. In Proceedings of the International Conference on Artificial Intelligence and Statistics, 2018
2018
-
[10]
Online learning under delayed feedback
Joulani, P., Gy\" o rfi, A., and Szepesv\' a ri, C. Online learning under delayed feedback. In Proceedings of the 30th International Conference on Machine Learning, 2013
2013
-
[11]
Regret lower bound and optimal algorithm in dueling bandit problem
Komiyama, J., Honda, J., Kashima, H., and Nakagawa, H. Regret lower bound and optimal algorithm in dueling bandit problem. In Proceedings of the 28th Conference on Learning Theory, 2015
2015
-
[12]
and Szepesv\' a ri, C
Lattimore, T. and Szepesv\' a ri, C. Bandit Algorithms. Cambridge University Press, 2020
2020
-
[13]
Li, L., Chu, W., Langford, J., and Schapire, R. E. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th International Conference on World Wide Web, 2010
2010
-
[14]
Feel-good thompson sampling for contextual dueling bandits
Li, X., Zhao, H., and Gu, Q. Feel-good thompson sampling for contextual dueling bandits. In arXiv preprint arXiv:2404.06013, 2024
-
[15]
Lin, X., Wu, Z., Dai, Z., Hu, W., Jaillet, P., and Low, B. K. H. Use your INSTINCT : Instruction optimization using neural bandits coupled with transformers. In Proceedings of the International Conference on Machine Learning, 2023
2023
-
[16]
Lin, X., Dai, Z., Verma, A., Ng, S.-K., Jaillet, P., and Low, B. K. H. Prompt optimization with human feedback. In Advances in Neural Information Processing Systems, 2024
2024
-
[17]
Optimal algorithms for stochastic contextual preference bandits
Saha, A. Optimal algorithms for stochastic contextual preference bandits. In Advances in Neural Information Processing Systems, volume 34, 2021
2021
-
[18]
and Krishnamurthy, A
Saha, A. and Krishnamurthy, A. Efficient and optimal algorithms for contextual dueling bandits under realizability. In Proceedings of Algorithmic Learning Theory, 2022
2022
-
[19]
Verma, A., Dai, Z., and Low, B. K. H. Bayesian optimization under stochastic delayed feedback. In Proceedings of the 39th International Conference on Machine Learning, 2022
2022
- [20]
-
[21]
Verma, A., Dai, Z., Lin, X., Jaillet, P., and Low, B. K. H. Neural dueling bandits: Preference-based optimization with human feedback. In International Conference on Learning Representations, 2025
2025
-
[22]
Stochastic bandit models for delayed conversions
Vernade, C., Capp\' e , O., and Perchet, V. Stochastic bandit models for delayed conversions. In Proceedings of the 33rd Conference on Uncertainty in Artificial Intelligence, 2017
2017
-
[23]
Wang, Z., Sun, J., Kong, M., Xie, J., Hu, Q., Lui, J. C., and Dai, Z. Online clustering of dueling bandits. arXiv preprint arXiv:2502.02079, 2025
-
[24]
Neural contextual bandits with shallow exploration
Xu, P., Wen, Z., Zhao, H., and Gu, Q. Neural contextual bandits with shallow exploration. In International Conference on Learning Representations, 2020
2020
-
[25]
and Joachims, T
Yue, Y. and Joachims, T. Interactively optimizing information retrieval systems as a dueling bandits problem. In Proceedings of the 26th International Conference on Machine Learning, 2009
2009
-
[26]
The K -armed dueling bandits problem
Yue, Y., Broder, J., Kleinberg, R., and Joachims, T. The K -armed dueling bandits problem. Journal of Computer and System Sciences, 78 0 (5): 0 1538--1556, 2012
2012
-
[27]
Neural T hompson sampling
Zhang, W., Zhou, D., Li, L., and Gu, Q. Neural T hompson sampling. In International Conference on Learning Representations, 2021
2021
-
[28]
and Gu, Q
Zhou, D. and Gu, Q. Learning contextual bandits in a non-stationary environment. In Proceedings of the ACM SIGMETRICS, 2019
2019
-
[29]
Neural contextual bandits with UCB -based exploration
Zhou, D., Li, L., and Gu, Q. Neural contextual bandits with UCB -based exploration. In Proceedings of the 37th International Conference on Machine Learning, 2020
2020
-
[30]
Relative upper confidence bound for the K -armed dueling bandit problem
Zoghi, M., Whiteson, S., Munos, R., and De Rijke, M. Relative upper confidence bound for the K -armed dueling bandit problem. In Proceedings of the 31st International Conference on Machine Learning, 2014
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.