Evidence Absence Is Not Evidence Insufficiency: Diagnosing NEI Construction Artifacts in Fact Verification
Pith reviewed 2026-06-29 18:17 UTC · model grok-4.3
The pith
NEI competence does not transfer reliably across different evidence construction methods in fact verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
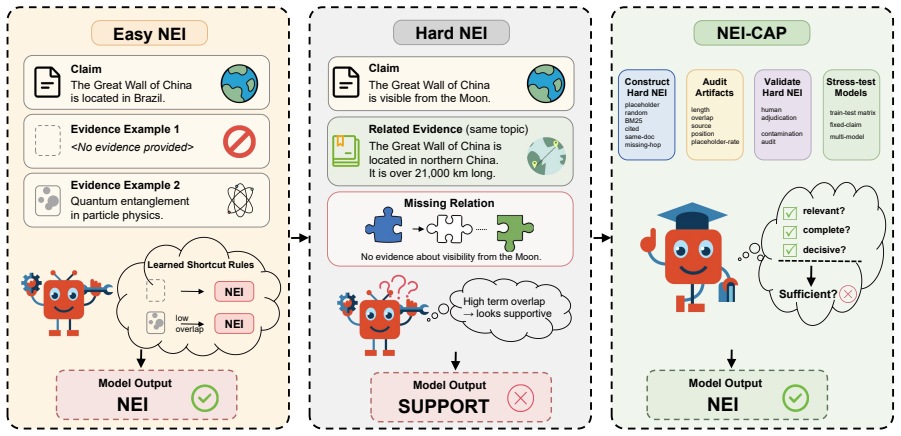
NEI competence does not transfer reliably: models trained on shortcut-prone constructions fail to recognize semantically related insufficient evidence, and mixed-construction training narrows but does not close the gap. Fixed-claim diagnostics further show that the evidence condition shifts confidence in the reference Support/Refute label, not only NEI recall, so an aggregate NEI score can hide which problem a model has actually solved.
What carries the argument
NEI-CAP, a construction-aware diagnostic protocol that tags each NEI example with its construction family, audits shortcut cues, validates hard cases through human adjudication, and tests cross-family transfer.
If this is right
- Models trained on shortcut-prone NEI constructions fail to recognize insufficient evidence in semantically related cases from other construction families.
- Mixed-construction training narrows but does not close the performance gap across families.
- The evidence condition used for NEI examples also shifts model confidence on the reference Support and Refute labels.
- Aggregate NEI scores can mask whether a model has learned general insufficiency detection or construction-specific patterns.
Where Pith is reading between the lines
- Different construction families may be probing separate underlying competencies rather than a single insufficiency-detection skill.
- Evaluation protocols should include routine cross-construction tests to prevent overestimation of robustness in fact verification systems.
- The same construction-tracking approach could expose similar artifacts in other NLP tasks that rely on constructed neutral or negative labels.
- Human validation of hard cases assumes adjudicators do not introduce systematic biases beyond those already present in the benchmark data.
Load-bearing premise
The different NEI construction families produce meaningfully distinct evidence conditions that test distinct model competencies, and human adjudication reliably validates hard cases without introducing new biases.
What would settle it
A model trained exclusively on one NEI construction family that then achieves cross-family NEI accuracy comparable to mixed-training baselines on held-out families would falsify the non-transfer result.
Figures

read the original abstract
Evidence absence is not evidence insufficiency, but fact verification benchmarks can make them observationally similar. The Not Enough Information (NEI) label is often operationalized through different evidence conditions, and that choice silently determines what a verifier learns and what its score can hide. We introduce NEI-CAP, a construction-aware diagnostic protocol for insufficient-evidence evaluation. Each NEI example carries the construction family that produced it; NEI-CAP audits shortcut cues, validates hard cases through human adjudication, and tests whether competence transfers across constructions. We instantiate the protocol in SciFact-style scientific verification, with FEVER and HoVer as bounded external controls. Across these settings, NEI competence does not transfer reliably: models trained on shortcut-prone constructions fail to recognize semantically related insufficient evidence, and mixed-construction training narrows but does not close the gap. Fixed-claim diagnostics further show that the evidence condition shifts confidence in the reference Support/Refute label, not only NEI recall, so an aggregate NEI score can hide which problem a model has actually solved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that NEI labels in fact verification are constructed via distinct families that introduce observable artifacts, proposes the NEI-CAP diagnostic protocol (with construction tagging, shortcut auditing, human adjudication of hard cases, and cross-construction transfer tests), and reports that models trained on shortcut-prone constructions fail to recognize semantically related insufficient evidence even under mixed training; fixed-claim diagnostics further show that evidence condition affects Support/Refute confidence, so aggregate NEI scores can mask the actual problem solved. Experiments are instantiated on SciFact-style scientific verification with FEVER and HoVer as controls.
Significance. If the empirical transfer gaps and human-adjudication results hold, the work is significant for benchmark design in fact verification and NLI-style tasks: it supplies a reusable protocol for isolating construction artifacts, demonstrates that mixed training is insufficient to close gaps, and shows how evidence conditions can shift non-NEI predictions. The explicit use of external controls and human validation of hard cases strengthens the diagnostic framing and could improve robustness evaluation practices.
major comments (2)
- [§4] §4 (Experiments): the central transfer-gap claim requires explicit reporting of per-construction example counts, class balance, and statistical significance tests (e.g., McNemar or bootstrap) on the observed gaps; without these, it is unclear whether the reported failure of mixed training to close the gap is driven by construction differences or by unequal data volumes across families.
- [§3.2] §3.2 (Human adjudication): the protocol description must specify exclusion criteria, inter-annotator agreement (e.g., Fleiss' κ), and how adjudicators were instructed to distinguish 'semantically related insufficient evidence' from other NEI subtypes; these details are load-bearing for validating that the hard cases truly test distinct competencies.
minor comments (2)
- [§3] Notation for construction families is introduced in §3 but used inconsistently in later tables; a single glossary or legend would improve readability.
- [Abstract / §4] The abstract states results across 'these settings' but the main text should include a summary table of all quantitative transfer metrics (accuracy deltas, NEI F1) with confidence intervals to allow direct comparison with the qualitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the paper accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the central transfer-gap claim requires explicit reporting of per-construction example counts, class balance, and statistical significance tests (e.g., McNemar or bootstrap) on the observed gaps; without these, it is unclear whether the reported failure of mixed training to close the gap is driven by construction differences or by unequal data volumes across families.
Authors: We agree that explicit reporting of per-construction example counts, class balance, and statistical significance is necessary to support the transfer-gap claims. In the revised manuscript, we will add a dedicated subsection or table in §4 reporting the exact number of examples per construction family, their label distributions, and the results of bootstrap or McNemar tests on the performance differences. This will confirm that the gaps are attributable to construction artifacts rather than data volume imbalances. revision: yes
-
Referee: [§3.2] §3.2 (Human adjudication): the protocol description must specify exclusion criteria, inter-annotator agreement (e.g., Fleiss' κ), and how adjudicators were instructed to distinguish 'semantically related insufficient evidence' from other NEI subtypes; these details are load-bearing for validating that the hard cases truly test distinct competencies.
Authors: We agree that these details are important for validating the human adjudication protocol. In the revision, we will expand §3.2 to explicitly state the exclusion criteria used, report inter-annotator agreement via Fleiss' κ, and include the full adjudication guidelines provided to annotators regarding the distinction between 'semantically related insufficient evidence' and other NEI subtypes. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces an empirical diagnostic protocol (NEI-CAP) for evaluating NEI construction artifacts in fact verification. It relies on dataset comparisons, human adjudication, and transfer tests across construction families rather than any mathematical derivations, fitted parameters, or self-referential definitions. No load-bearing steps reduce to inputs by construction, and external controls (FEVER, HoVer) plus human validation provide independent grounding. This is a standard non-circular empirical analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human adjudication provides reliable validation for hard NEI cases
Reference graph
Works this paper leans on
-
[1]
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R
Missing counter-evidence renders NLP fact- checking unrealistic for misinformation.arXiv preprint arXiv:2210.13865. Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R. Bowman, and Noah A. Smith. 2018. Annotation artifacts in natural lan- guage inference data. InProceedings of the 2018 Conference of the North American Chapter of the A...
-
[2]
DeBERTaV3: Improving DeBERTa us- ing ELECTRA-style pre-training with gradient- disentangled embedding sharing.arXiv preprint arXiv:2111.09543. Alon Jacovi, Andrew Wang, Chris Alberti, Connie Tao, Jon Lipovetz, Kate Olszewska, Lukas Haas, Michelle Liu, Nate Keating, Adam Bloniarz, Carl Saroufim, Corey Fry, Dror Marcus, Doron Kuklian- sky, Gaurav Singh Toma...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Yichen Jiang, Shikha Bordia, Zheng Zhong, Charles Dognin, Maneesh Singh, and Mohit Bansal
The FACTS grounding leaderboard: Bench- marking LLMs’ ability to ground responses to long- form input.arXiv preprint arXiv:2501.03200. Yichen Jiang, Shikha Bordia, Zheng Zhong, Charles Dognin, Maneesh Singh, and Mohit Bansal. 2020. HoVer: A dataset for many-hop fact extraction and 8 claim verification. InFindings of the Association for Computational Lingu...
-
[4]
Adversarial attacks against Fact Extraction and VERification
Association for Computational Linguistics. Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: BM25 and be- yond.F oundations and Trends in Information Re- trieval, 3:333–389. Tal Schuster, Adam Fisch, and Regina Barzilay. 2021. Get your vitamin C! robust fact verification with contrastive evidence. InProceedings of the 2021 ...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[5]
Step-by-step fact verification system for med- ical claims with explainable reasoning. InProceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computa- tional Linguistics: Human Language Technologies (V olume 2: Short Papers), pages 805–816, Albu- querque, New Mexico. Association for Computa- tional Linguistics...
2025
-
[6]
HealthFC: Verifying health claims with evidence-based medical fact-checking.arXiv preprint arXiv:2309.08503. David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. 2020. Fact or fiction: Verifying scientific claims. InProceedings of the 2020 Con- ference on Empirical Methods in Natural Language Proc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.