MemFail: Stress-Testing Failure Modes of LLM Memory Systems
Pith reviewed 2026-06-29 18:06 UTC · model grok-4.3
The pith
MemFail isolates LLM memory failures by testing summarization, storage, and retrieval with separate adversarial datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
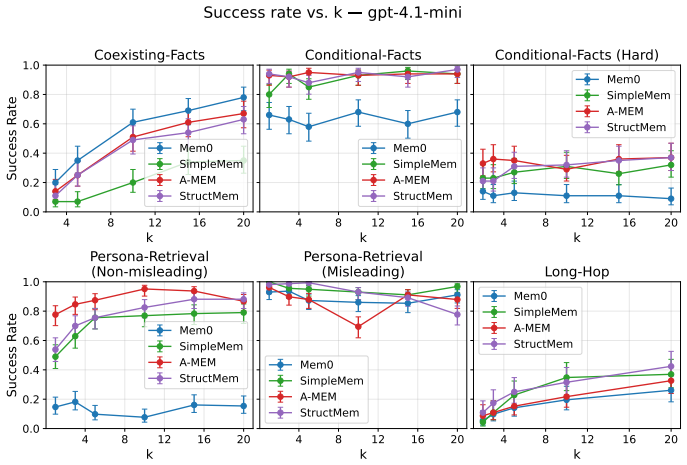
We introduce MemFail, a diagnostic benchmark that isolates the failure modes of modern LLM memory systems. We begin by formalizing memory systems as the composition of three canonical operations -- summarization, storage, and retrieval -- and identify the potential failure modes induced by each. Based on these hypothesized failure modes, we construct five datasets spanning four tasks, each adversarially designed to test a specific operation of a memory system. Using these datasets, we evaluate four state-of-the-art memory systems on MemFail and demonstrate how MemFail can be used to empirically understand the tradeoffs induced by differences in memory system architectures.
What carries the argument
The three canonical operations of summarization, storage, and retrieval, together with five adversarially designed datasets that test each operation independently.
If this is right
- Memory system architectures produce measurable and distinct tradeoffs across the three operations.
- Errors in long-horizon interactions can be traced to one operation rather than reported only as overall inaccuracy.
- Targeted fixes become possible once a failure is localized to summarization, storage, or retrieval.
- Black-box benchmarks that report only aggregate accuracy are insufficient for diagnosing memory problems.
Where Pith is reading between the lines
- Future agent designs could incorporate operation-specific diagnostics as a standard evaluation step before deployment.
- The same isolation approach might extend to other agent components such as planning or tool use.
- Developers could use the datasets to compare new memory proposals against the four systems already tested.
Load-bearing premise
Failure modes of memory systems can be cleanly isolated to summarization, storage, and retrieval without confounding factors from other system parts.
What would settle it
Running the five datasets on existing memory systems and finding that error patterns cannot be attributed to specific operations or that all systems show indistinguishable failure distributions across the datasets.
Figures

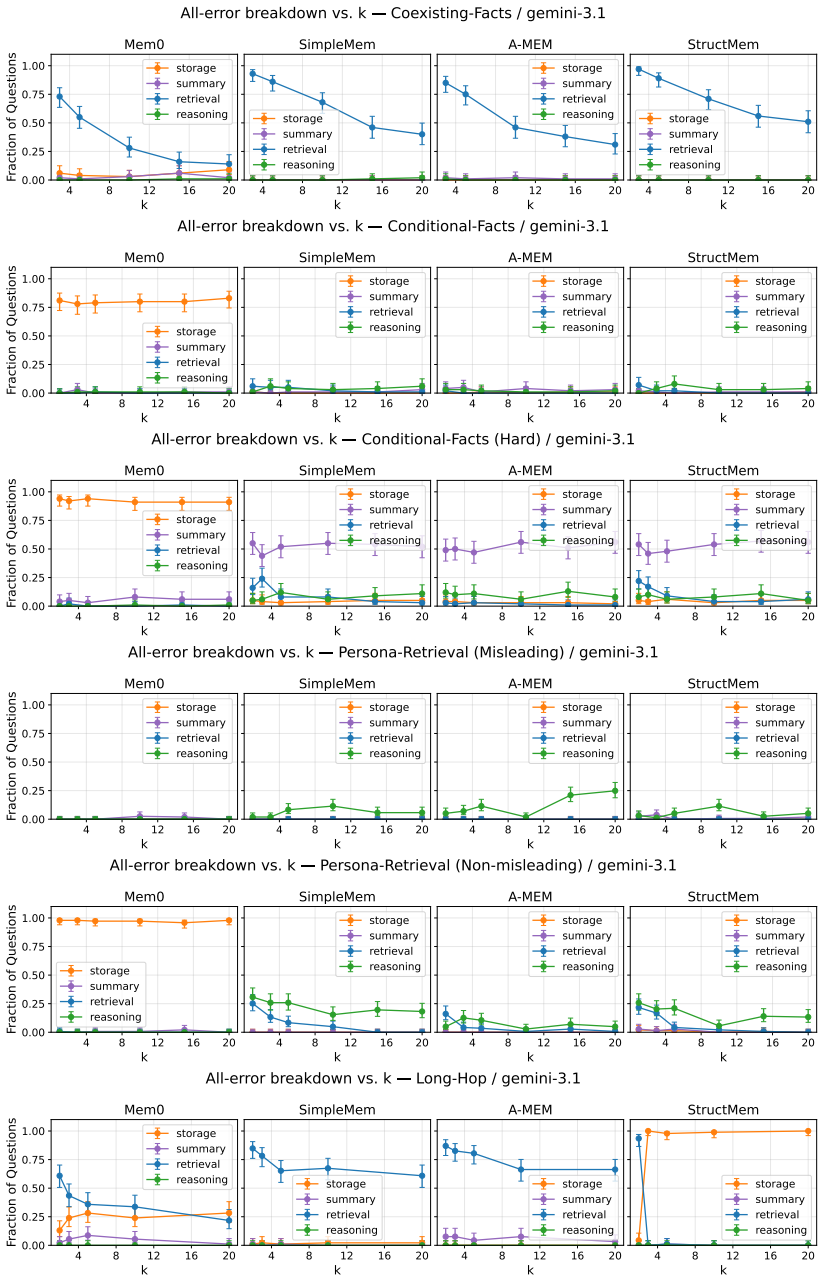
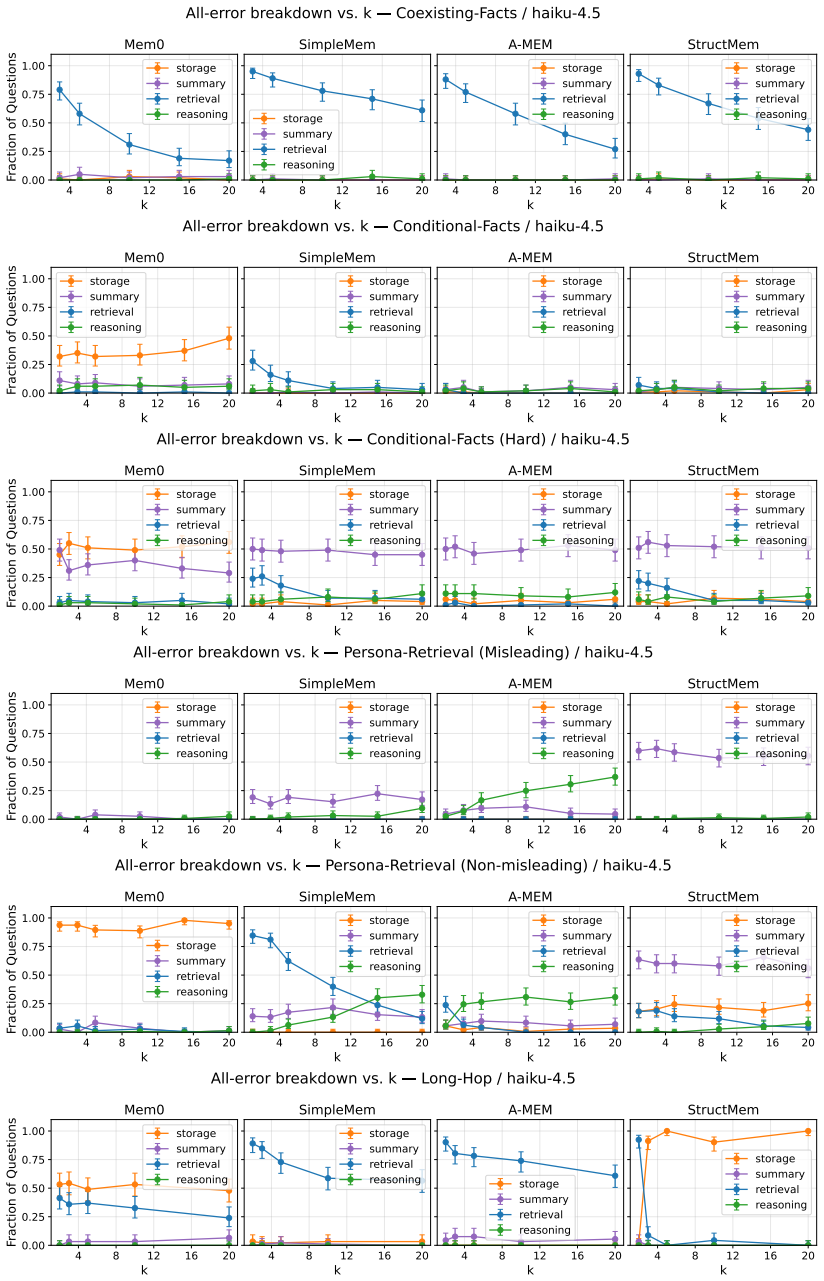
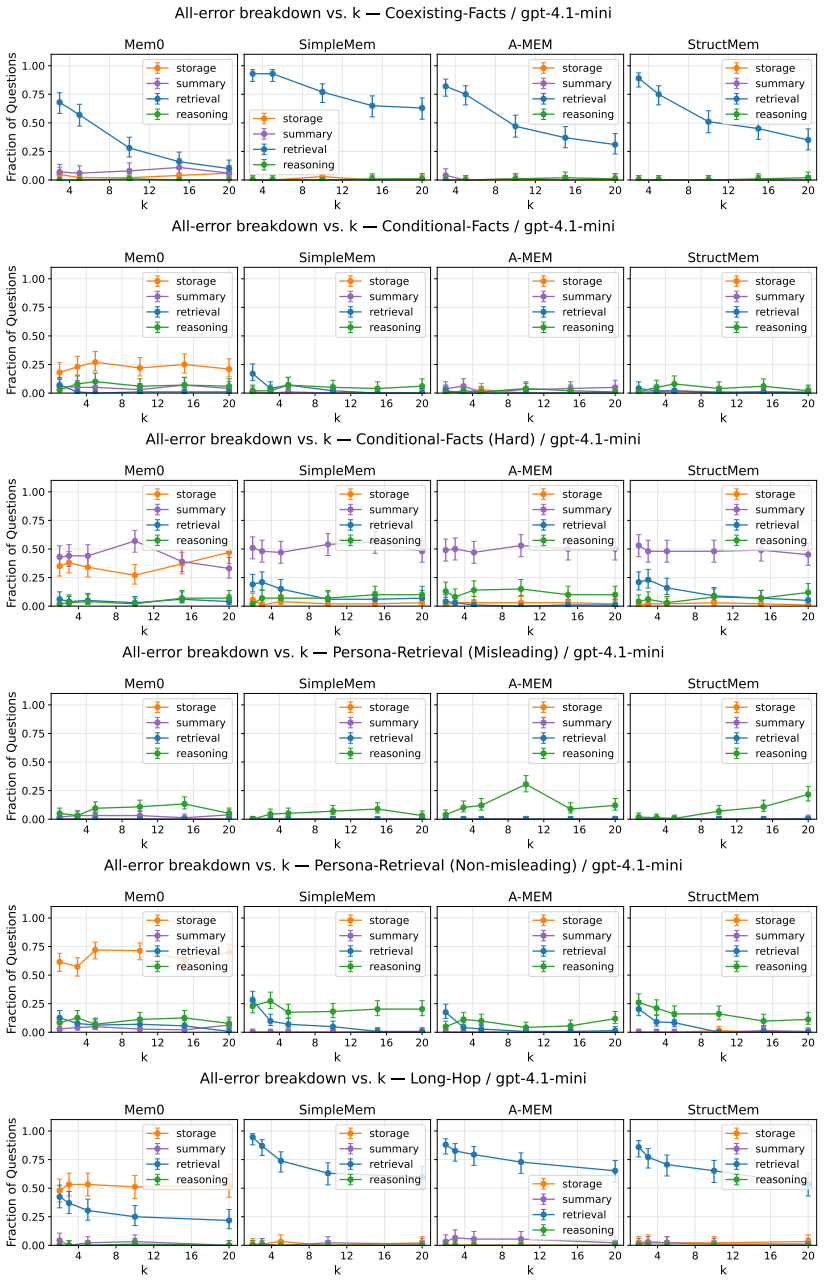
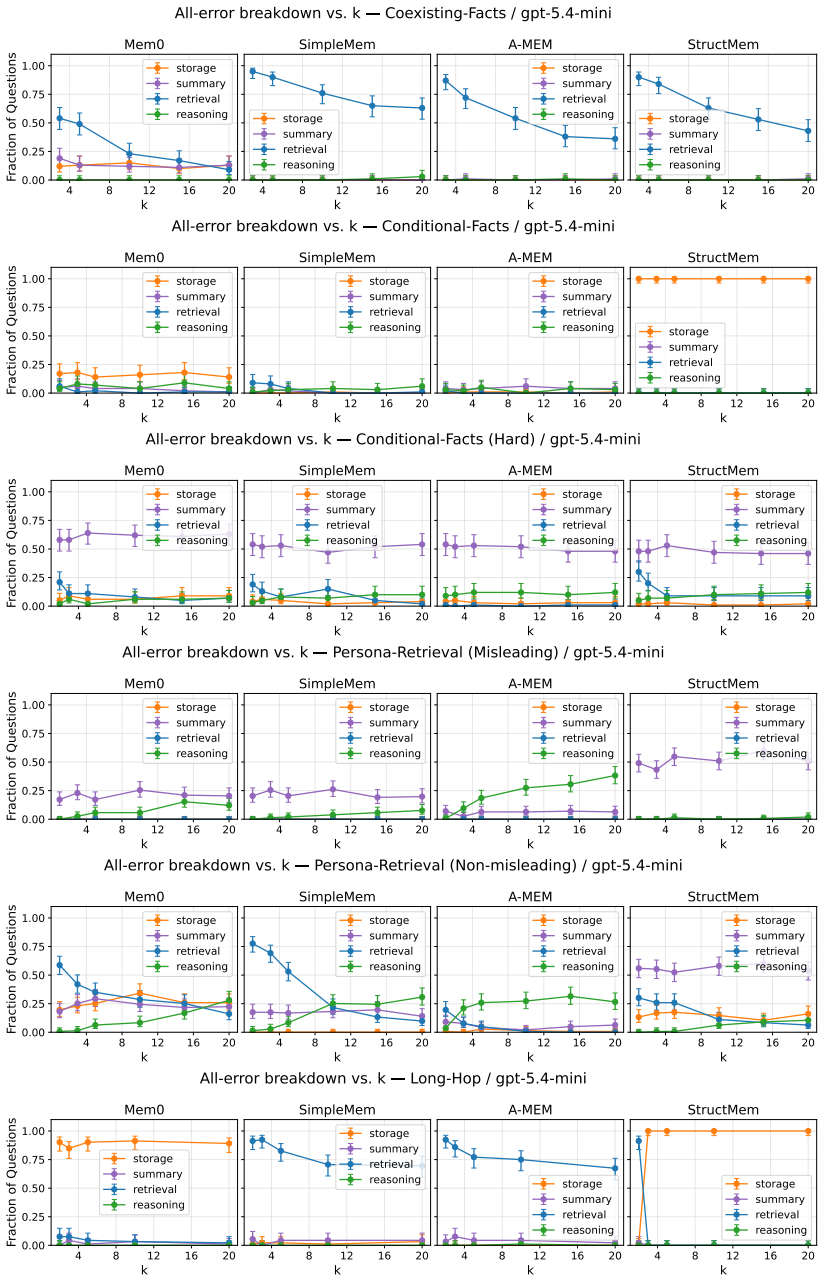
read the original abstract
Large language model (LLM) agents increasingly rely on external memory systems to remain consistent across long-horizon interactions, but little empirical work has been done to understand the specific failure modes and design choices that these systems present. Existing benchmarks report aggregate question-answering accuracy and treat memory systems as black boxes, making it impossible to attribute an incorrect answer to a particular failure mode of the system. We introduce MemFail, a diagnostic benchmark that isolates the failure modes of modern LLM memory systems. We begin by formalizing memory systems as the composition of three canonical operations -- summarization, storage, and retrieval -- and identify the potential failure modes induced by each. Based on these hypothesized failure modes, we construct five datasets spanning four tasks, each adversarially designed to test a specific operation of a memory system. Using these datasets, we evaluate four state-of-the-art memory systems on MemFail and demonstrate how MemFail can be used to empirically understand the tradeoffs induced by differences in memory system architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemFail, a diagnostic benchmark for LLM memory systems. It formalizes memory systems as compositions of summarization, storage, and retrieval operations, identifies potential failure modes for each, constructs five adversarially designed datasets across four tasks to test these operations specifically, evaluates four state-of-the-art memory systems on these datasets, and uses the results to demonstrate architectural tradeoffs in memory system design.
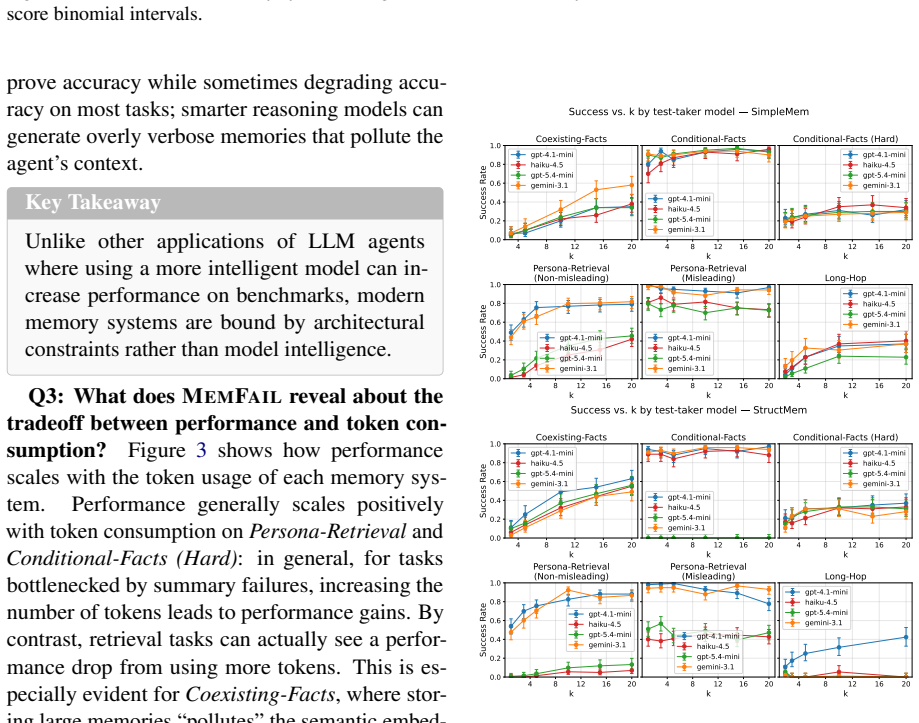
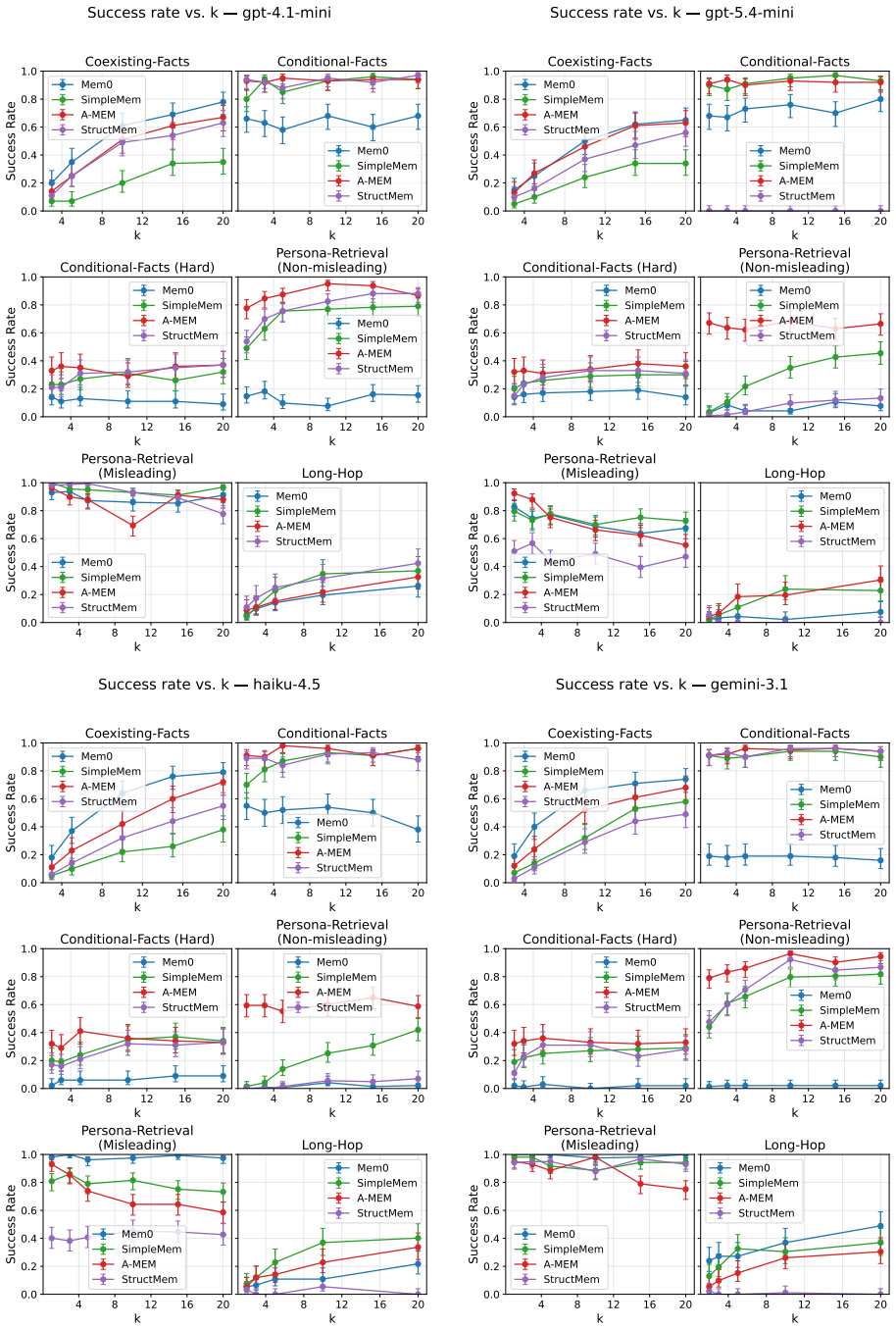
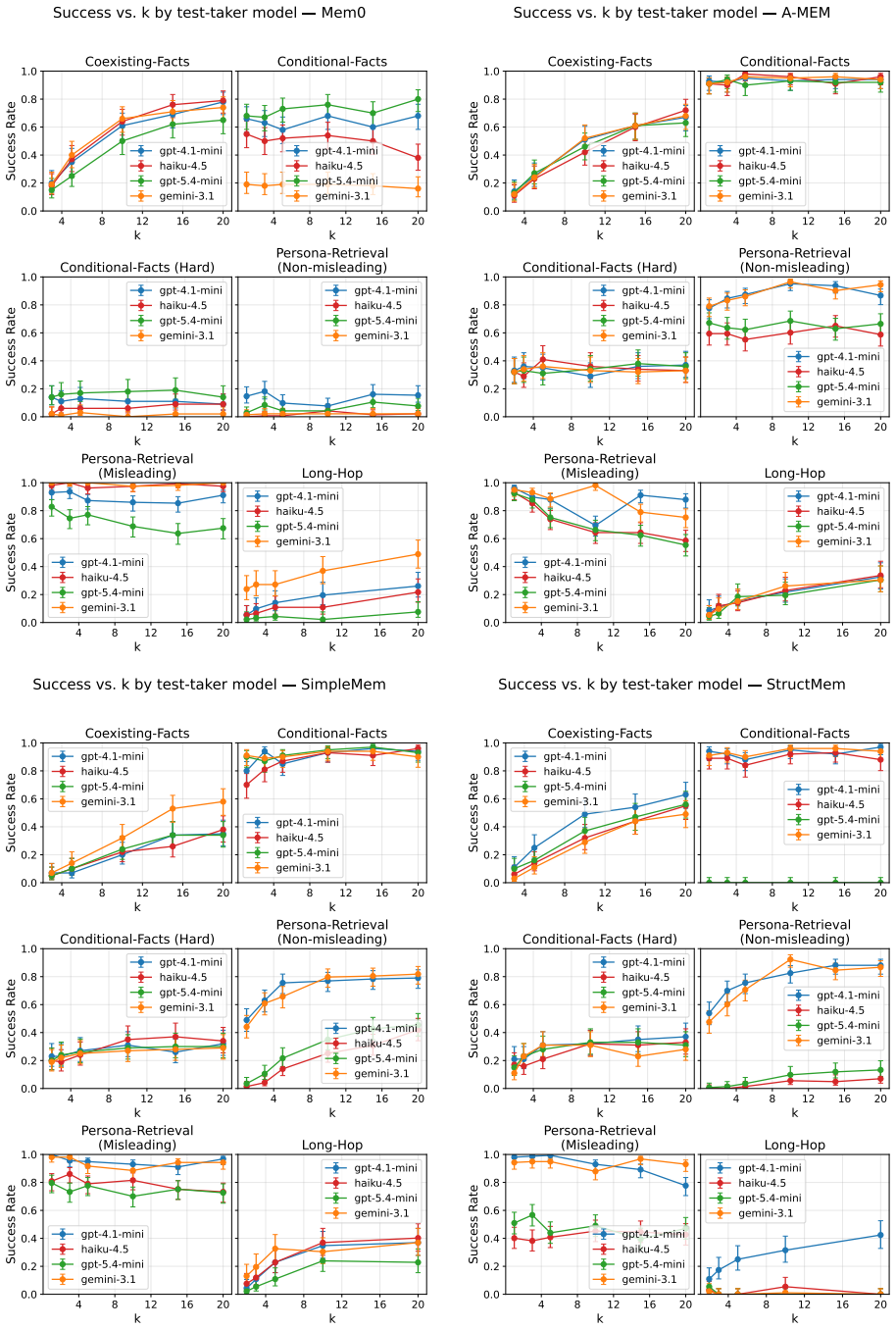
Significance. If the datasets successfully isolate the targeted failure modes without confounding factors from base LLM capabilities or other system components, MemFail would provide a valuable tool for empirically diagnosing and comparing memory architectures in LLM agents. This could advance the field by moving beyond aggregate accuracy metrics to targeted failure analysis. However, the current description provides no quantitative results or validation of the isolation, limiting the assessed significance.
major comments (1)
- [Abstract and Dataset Construction] Abstract (and implied Dataset Construction section): The central claim requires that each dataset triggers failures attributable only to one of the three operations. This is not supported by any described controls, ablations, or oracle-memory experiments showing that errors disappear when the targeted component is replaced by an oracle. Without such validation, attribution of performance drops to the hypothesized failure modes (rather than base LLM reasoning or task confounders) cannot be established, undermining the benchmark's diagnostic utility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and Dataset Construction] Abstract (and implied Dataset Construction section): The central claim requires that each dataset triggers failures attributable only to one of the three operations. This is not supported by any described controls, ablations, or oracle-memory experiments showing that errors disappear when the targeted component is replaced by an oracle. Without such validation, attribution of performance drops to the hypothesized failure modes (rather than base LLM reasoning or task confounders) cannot be established, undermining the benchmark's diagnostic utility.
Authors: We agree that explicit validation of isolation is important for establishing the benchmark's diagnostic value. The manuscript constructs the datasets adversarially based on the formalized failure modes for summarization, storage, and retrieval, and the reported evaluations on four memory systems show performance patterns consistent with architectural differences. However, the current version does not include oracle ablations or controls that replace a targeted component to confirm error attribution. We will add such experiments in the revised manuscript (e.g., oracle summarization or perfect retrieval) to demonstrate that errors decrease when the hypothesized component is idealized, and include these results in the Experiments and Dataset Construction sections. revision: yes
Circularity Check
Empirical benchmark proposal with no derivation or fitting chain
full rationale
The paper introduces MemFail as a diagnostic benchmark by formalizing memory systems into three operations and constructing five adversarially designed datasets to test them. No equations, parameter fitting, self-citations, or uniqueness theorems are present in the provided text. The work is self-contained as an empirical proposal whose claims are tested via external evaluation on existing memory systems rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memory systems can be formalized as the composition of summarization, storage, and retrieval operations whose failure modes can be tested independently.
Reference graph
Works this paper leans on
-
[1]
SimpleMem: Efficient Lifelong Memory for LLM Agents
SimpleMem: Efficient Lifelong Memory for LLM Agents.Preprint, arXiv:2601.02553. Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long Papers), pages 13851–13870, Bangkok, Thailand. Association for Computational Linguistics. Elliot Nelson, Georgios Kollias, Payel Das, Subhajit Chaudhury, and Soham Dan. 2024. Needle in ...
-
[3]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as Operating Sys- tems.Preprint, arXiv:2310.08560. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interac- tive Simulacra of Human Behavior.Preprint, arXiv:2304.03442. Mitchell Piehl, Zhaohan Xi, Zuobin Xiong, Pan He, and Muchao Ye. 2026. ER-MIA...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Re- inforcement Learning.Preprint, arXiv:2303.11366. Alina Shutova, Alexandra Olenina, Ivan Vinogradov, and Anton Sinitsin. 2026. Evaluating memory struc- ture in LLM agents. InICLR 2026 Workshop on Memory for LLM-Based Agentic Systems (MemA- gents). Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahme...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
entity": a realistic first name (for ,→persons/characters) or a pet name (for ,→pets) e.g
"entity": a realistic first name (for ,→persons/characters) or a pet name (for ,→pets) e.g. "Jordan", "Miso", "Captain Rex"
-
[6]
behavior
"behavior": a short action phrase ,→describing what the entity does ,→conditionally. Invent something creative and specific ,→to the entity and condition type -- do ,→NOT default to cliches like "goes for a run" or ,→"drinks coffee". The behavior should ,→feel personal and idiosyncratic, not universally ,→common. The examples below are illustrative ONLY ,...
-
[7]
condition
"condition": the specific condition ,→under which the behavior occurs e.g. "after 5pm", "when it's raining", ,→"when feeling stressed" - Must be concrete and testable -- the ,→question will present a specific context - Avoid vague conditions like ,→"sometimes" or "often"
-
[8]
entity_facts
"entity_facts": a list containing ,→exactly 1 natural statement that ,→directly encodes the full conditional fact -- both the ,→behavior AND the condition in a single ,→sentence. - Must be a casual, first-person or ,→third-person conversational sentence - Must clearly state BOTH what the ,→entity does AND when/under what condition - 1-2 sentences max - Th...
-
[9]
question
"question": a natural question about ,→whether the entity should do (or would ,→do) the behavior, given a SPECIFIC context that may or may ,→not satisfy the condition. CRITICAL RULE -- the question MUST be ,→non-inferrable without the entity's ,→specific fact: A person with no knowledge of the entity ,→should NOT be able to guess the correct ,→answer from...
-
[10]
question_context
"question_context": the specific context ,→presented in the question e.g. "3pm", "quiet Sunday morning", "18C ,→at the park"
-
[11]
condition_met
"condition_met": "yes" if the question ,→context satisfies the condition, "no" if ,→not Think carefully -- if the condition is ,→"after 5pm" and the context is "3pm", ,→it's "no"
-
[12]
ground_truth_answer
"ground_truth_answer": a short yes/no ,→answer with a brief reason e.g. "No -- it's only 3pm and Alex ,→doesn't drink coffee before 5pm." e.g. "Yes -- it's raining, which is ,→exactly when Jordan likes to cook ,→elaborate meals." Return strict JSON with key "rows", a list ,→of objects: - row_id (int) - entity (string) - entity_category (string: "person", ...
-
[13]
entity_facts must have exactly 1 ,→statement encoding both the behavior and ,→the condition
-
[14]
The condition must be concrete and ,→testable (not vague)
-
[15]
The question must present a specific ,→context value that clearly either meets ,→or doesn't meet the condition
-
[16]
condition_met must correctly reflect ,→whether the question context satisfies ,→the condition
-
[17]
ground_truth_answer must be consistent ,→with condition_met
-
[18]
The question MUST be non-inferrable: ,→without knowing the entity's specific ,→rule, a reasonable person should be genuinely ,→uncertain about the answer
-
[19]
yes" and ,→
Vary condition_met between "yes" and ,→"no" across the batch
-
[20]
Do NOT reuse any entity names, ,→behaviors, conditions, or phrasings from ,→the examples above -- they exist only to illustrate the format
-
[21]
Output ONLY valid JSON Input specs: {specs as JSON} Generation:Conditional-F actsessay wrapper (Easy) For each item below, write a natural essay ,→(7-10 sentences) about the entity that embeds the conditional fact into a ,→rich, casual narrative. Rules:
-
[22]
Paraphrase is ,→fine; do not omit either part
The essay MUST preserve the conditional ,→fact clearly -- both the behavior AND the condition must be present. Paraphrase is ,→fine; do not omit either part
-
[23]
Every such sentence must be an unconditional, factual statement
All other sentences should describe the ,→entity's background, personality, daily ,→routines, relationships, hobbies, quirks, or life ,→context. Every such sentence must be an unconditional, factual statement
-
[24]
only when
Do NOT introduce any new conditional ,→statements anywhere in the essay. ,→Forbidden constructions: "only when", "unless", ,→"except when", "but only if", "whenever ,→X then Y", "only after", "only if", or any other ,→conditional phrasing beyond what was ,→already in the original fact
-
[25]
The essay should feel natural -- like an ,→excerpt from a chat conversation, ,→personal blog, or journal entry, not a formal report or ,→list
-
[26]
The conditional fact may appear anywhere ,→in the essay, surrounded by unrelated ,→context before and after it
-
[27]
It's usually
5-8 sentences total. Return strict JSON with key "rows", a list ,→of: row_id (int, same as input), essay ,→(string) Output ONLY valid JSON. Input: {items as JSON} Generation:Conditional-F actsessay wrapper (Hard) For each item below, write a natural essay ,→(8-12 sentences) about the entity that DECOMPOSES the original conditional ,→fact into THREE distri...
-
[28]
The behavior and condition must BOTH be ,→recoverable by a careful reader who ,→composes sentences (A), (B), and (C) -- but ,→NEITHER should appear in the same ,→sentence
-
[29]
only when
Do NOT use explicit conditional phrasing ,→anywhere ("only when", "whenever", "if", "unless", "except when", "but only if", ,→"only after", "only if")
-
[30]
The link sentence (C) should use ,→timing/scene language, not logical ,→connectives
-
[31]
All remaining sentences should describe ,→the entity's background, personality, ,→daily routines, relationships, hobbies, ,→quirks, or life context -- unconditional ,→factual statements
-
[32]
The essay should feel natural -- like an ,→excerpt from a personal blog or journal ,→entry
-
[33]
It should ,→NOT be vague or too subtle
The correlation between the behavior and ,→condition should be obvious to somebody ,→who has read both sentences. It should ,→NOT be vague or too subtle
-
[34]
Return strict JSON with key "rows", a list ,→of: row_id (int, same as input), essay ,→(string) Output ONLY valid JSON
8-12 sentences total. Return strict JSON with key "rows", a list ,→of: row_id (int, same as input), essay ,→(string) Output ONLY valid JSON. Input: {items as JSON} D.1.2Coexisting-F acts A single datapoint generator (Prompt D.1.2) pro- duces, for each preference category, N isolated first-person statements plus a holistic scenario ques- tion whose answer ...
-
[35]
preferences
"preferences": list of exactly ,→num_preferences distinct preferences in ,→the category (e.g. for foods: ["pizza", "sushi", ,→"ramen"])
-
[36]
preference_facts
"preference_facts": list of exactly ,→num_preferences short, natural ,→first-person statements -- ONE statement per preference, in the ,→same order as "preferences". - Each statement must stand alone as a ,→complete, self-contained fact - Each statement must mention ONLY that ,→single preference (not the others) - Use varied, natural phrasing -- not a ,→t...
-
[37]
question
"question": a natural first-person ,→scenario question that REQUIRES knowing ,→ALL preferences. - Must NOT be a direct "list all my X" ,→request -- make it a realistic scenario - Good: "I'm going grocery shopping -- ,→what should I pick up for dinners this ,→week?" - Good: "My friend wants to plan an ,→outing I'd enjoy -- what are some solid ,→options?" -...
-
[38]
ground_truth_answer
"ground_truth_answer": a concise ,→comma-separated list of all preference ,→names Example: "pizza, sushi, ramen" Return strict JSON with key "rows", a list ,→of objects: - row_id (int) - preference_category (string, same as ,→input) - preferences (list of strings) - preference_facts (list of strings, same ,→length as preferences, one fact per ,→preference...
-
[39]
preference_facts must have exactly the ,→same length as preferences
-
[40]
Each fact covers exactly ONE preference ,→and stands alone -- no cross-references
-
[41]
list all my ,→X
The question must be a realistic ,→first-person scenario, NOT "list all my ,→X"
-
[42]
Ground truth must include every ,→preference, comma-separated
-
[43]
distractor
Output ONLY valid JSON Input specs: {specs as JSON} D.1.3Persona-Retrieval A single datapoint generator (Prompt D.1.3) jointly produces the third-person essay about E and the three first-person follow-up questions, with each slot pre-marked as misleading-or-not by the calling code. Generation:Persona-Retrievaldatapoint generator Generate misleading-person...
-
[44]
essay": a natural personal essay about ,→the entity (10-15 sentences). - Written in third person, naming the ,→entity (e.g
"essay": a natural personal essay about ,→the entity (10-15 sentences). - Written in third person, naming the ,→entity (e.g. "Maya Patel"). Pronouns are ,→fine after the first mention. - Embed MANY specific, memorable, ,→idiosyncratic facts: daily rituals, ,→unusual hobbies, hard constraints ,→(allergies/aversions/rules), strong ,→preferences, quirky poss...
-
[45]
questions
"questions": a list of EXACTLY 3 ,→question objects, in the order given by spec.question_slots. Each slot specifies ,→whether that question is misleading and, ,→if so, the distractor name to use. For each slot: If is_misleading=false: - "text": a first-person question that ,→explicitly names the entity by their ,→full name. The asker wants advice or info ...
-
[46]
The essay is 10-15 sentences, ,→third-person, names the entity, and ,→never mentions any distractor name from any slot
-
[47]
Each non-misleading question names the ,→entity exactly and never names any ,→distractor
-
[48]
Each misleading question names that ,→slot's distractor exactly and never ,→names the entity
-
[49]
Non-misleading questions must NOT embed ,→their own answers as assumptions
-
[50]
Each non-misleading ground_truth_answer ,→is supported by specific essay details
-
[51]
Each misleading ground_truth_answer ,→indicates the system should abstain
-
[52]
Output ONLY valid JSON. Input specs: {specs as JSON} D.1.4Long-Hop Long-Hop generation runs in three phases: chain proposal (Prompts D.1.4–D.1.4), cross-chain con- flict / similarity audit (Prompt D.1.4), and per-chain distractor generation (Prompts D.1.4–D.1.4). Generation:Long-Hopchain proposal — system mes- sage You are constructing a benchmark of ,→mu...
-
[53]
Each ,→statement is a single declarative English sentence, max ~16 words, no ,→commas-separated multi-claims
EXACTLY K+1 statements per chain. Each ,→statement is a single declarative English sentence, max ~16 words, no ,→commas-separated multi-claims
-
[54]
loves",
Statement i mentions anchor i and anchor ,→i+1, plus an explicit relation word -- a verb ("loves", "hates", ,→"always picks"), a conditional ("when", "whenever", "if"), a causal ("because", ,→"leads to", "makes me"), a temporal ("after", "before"), or a preference ("I ,→do X when Y"). MIDDLE and TERMINAL anchors (anchors 2 .. K+2) must appear ,→ONLY in th...
-
[55]
bored", ,→
K+2 anchors total per chain. Anchors ,→should be SUBJECTIVE / PERSONAL content that cannot be looked up in an ,→encyclopedia. Use anchors like: - States, moods, feelings ("bored", ,→"anxious", "calm"). - Actions, habits, routines ("eat ,→apples", "skip lunch", "go for a run"). - Preferences and opinions ("loves ,→Korean food", "thinks pop music is overrat...
-
[56]
Within a single chain, all K+2 anchors ,→must be distinct (case-insensitive)
-
[57]
Vary the relation patterns across the ,→K+1 statements within one chain -- do not reuse the same conditional or verb ,→template back-to-back
-
[58]
What does Diego do when he is bored?
The graded question must reference ,→anchor 1 (the head) at least once by name and ask about the terminal anchor ,→(the last in the chain), without ever naming any intermediate anchor. The ,→question should read as a single natural English sentence and have a ,→unique correct answer given the K+1 statements. Natural pronouns are ,→encouraged when they aid...
-
[59]
drop a leading ,→"the" only if the canonical phrase has no article)
ground_truth_answer must equal the ,→terminal anchor exactly (or its shortest natural form -- e.g. drop a leading ,→"the" only if the canonical phrase has no article)
-
[60]
sleep" or
Across chains in this batch, AVOID ,→retelling the same narrative as anything in PRIOR CHAIN SUMMARIES (provided in ,→the user message). Generic words like "sleep" or "bored" may repeat across ,→chains, but a chain that paraphrases another chain's storyline must not be ,→produced. Distractor options are produced in a ,→separate downstream step -- DO NOT ,...
-
[61]
drink water
SAME-SHAPE PLAUSIBILITY. Match the ,→correct answer in grammatical form, length range, and answer category. If ,→the correct answer is a noun phrase naming a mood, every distractor is a ,→noun phrase naming a mood. If the correct answer is a short verb phrase ,→("drink water"), every distractor is a short verb phrase of similar length ,→and shape. Pronoun...
-
[62]
duel a swan
REALISTIC AND ORDINARY. Each distractor ,→must name something a real person could plausibly feel, do, prefer, eat, ,→or experience in everyday life. NO absurd, surreal, slapstick, joke, or ,→comically random options. NO things almost no one actually does ,→(e.g., "duel a swan", "memorize country capitals from memory", "argue with ,→neighbors about constel...
-
[63]
Must not be a ,→paraphrase, synonym, sub-phrase, near-spelling, or otherwise overlapping ,→with the correct answer or with any anchor / relation phrase that ,→appears in any fact
UNAMBIGUOUSLY WRONG. Must not be a ,→paraphrase, synonym, sub-phrase, near-spelling, or otherwise overlapping ,→with the correct answer or with any anchor / relation phrase that ,→appears in any fact
-
[64]
what comes next
ORTHOGONAL TO EVERY FACT. A reader ,→looking at any single fact in isolation must NOT be able to guess the distractor ,→as a plausible "what comes next" or "natural consequence" via ,→common-sense world knowledge. Avoid distractors that name typical effects, ,→components, properties, or strong associations of any concept mentioned in ,→any fact (e.g., if ...
-
[65]
I eat apples when I'm bored
DISTINCT. The four distractors must be ,→distinct from each other (case-insensitive) and distinct from the ,→correct answer. Examples (note: realistic, ordinary, ,→orthogonal): CHAIN A facts: - "I eat apples when I'm bored." - "When I'm bored I go to sleep." - "When I sleep I have a dream." - "Every dream I have leaves me curious ,→about the future." GRAD...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.