An In-Vitro Study on Cross-Lingual Generalization in Language Models
Pith reviewed 2026-06-29 18:05 UTC · model grok-4.3
The pith
Tokenization that preserves reusable cross-lingual substructure drives transfer more than lexical similarity or balance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
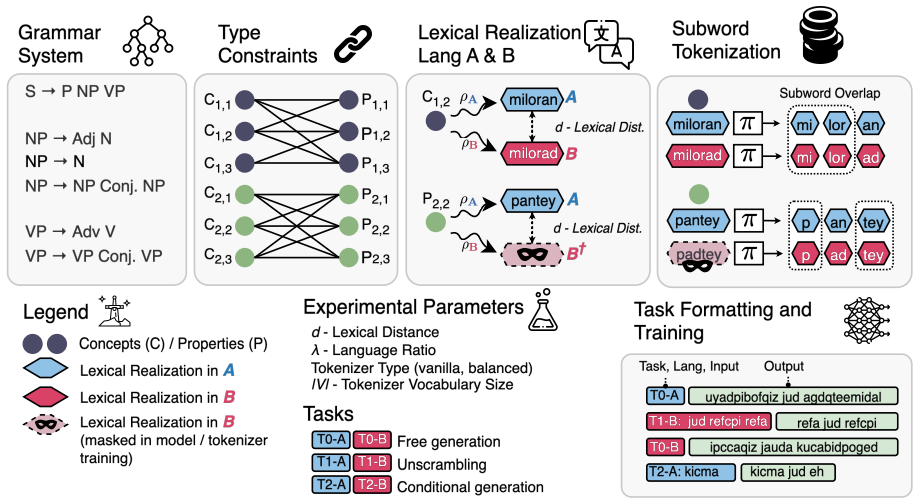
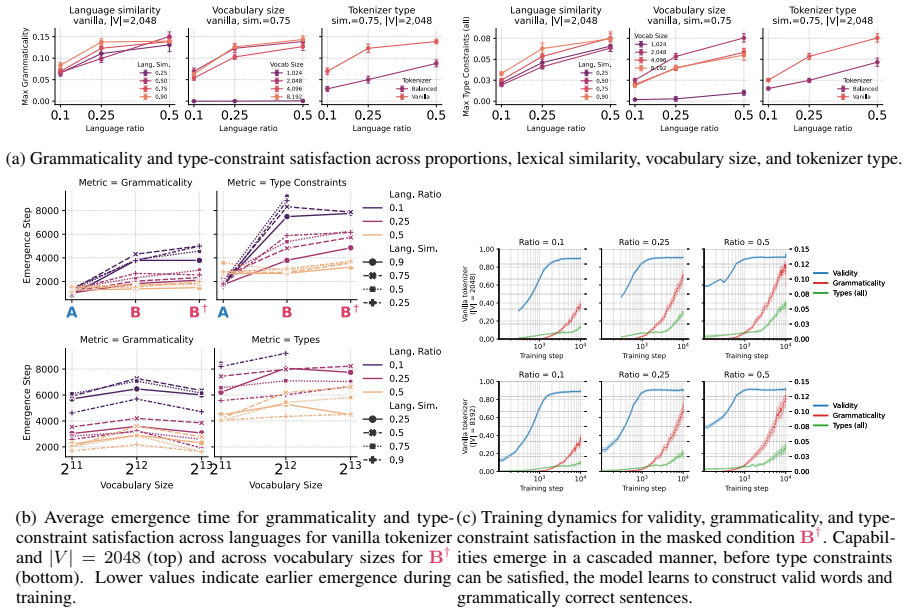
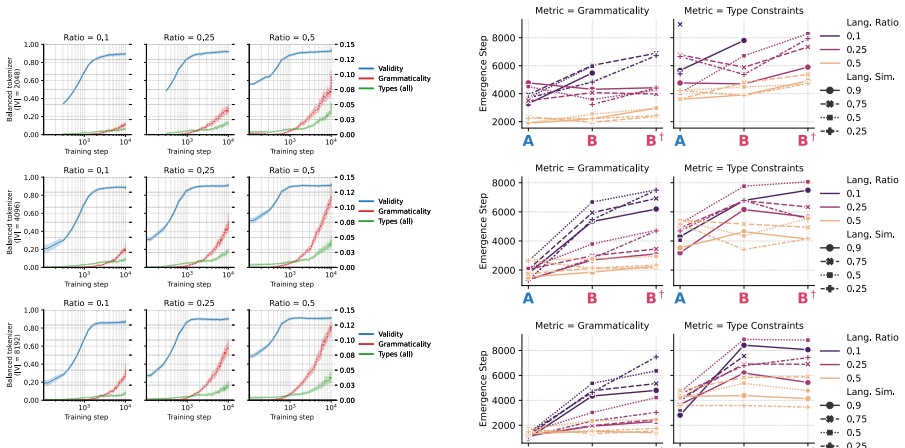
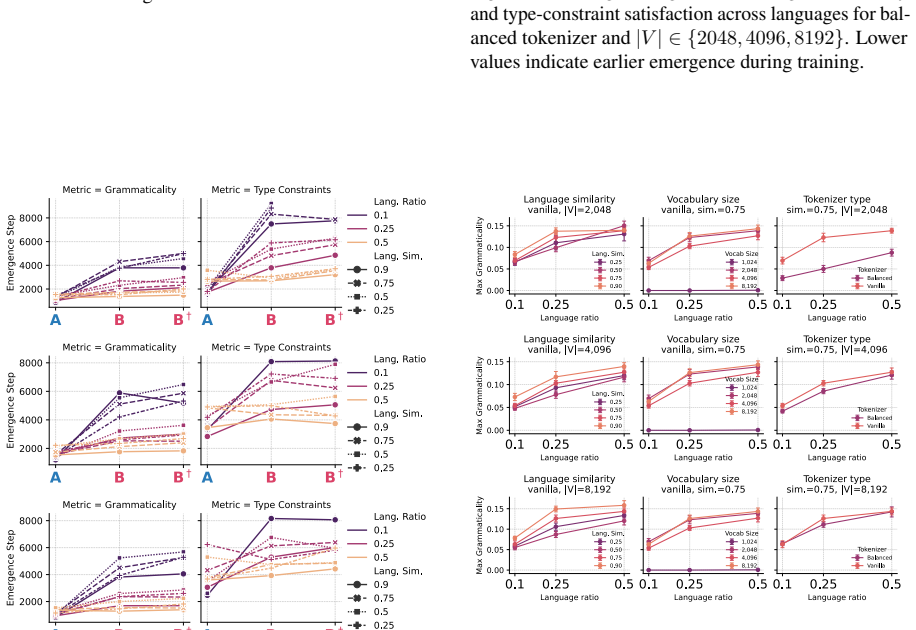
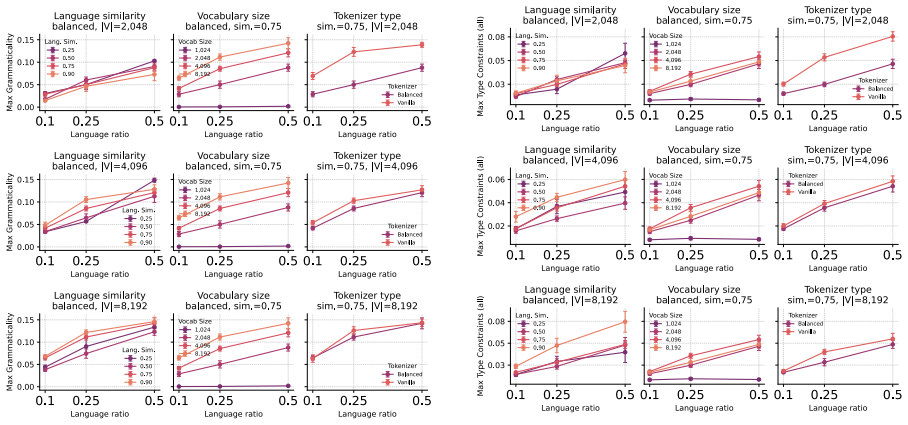
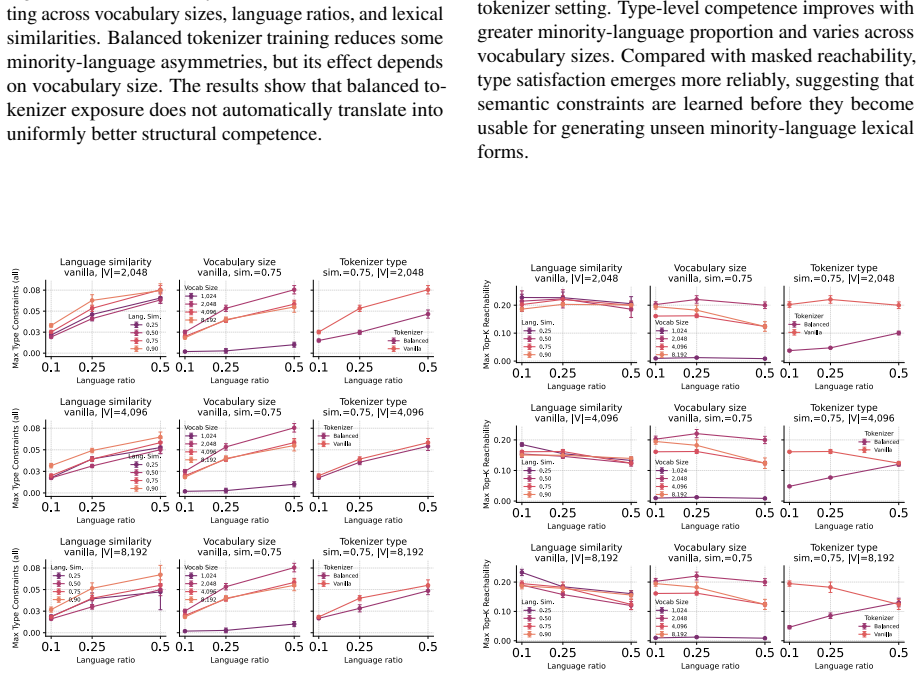
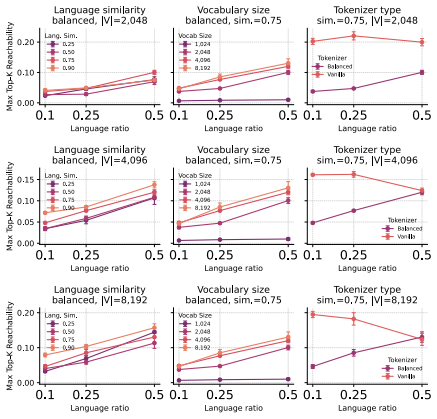
Using procedurally generated languages with identical ontology and grammar but different realizations, the study finds that cross-lingual masked transfer is governed primarily by the preservation of reusable substructure in tokenization, with smaller vocabularies improving performance by maintaining decomposability into shared fragments, and that transfer emerges as a staged process where grammatical competence precedes lexical generalization, explained by the strength of tokenizer bridges.
What carries the argument
Tokenizer bridges: the shared subword units that connect the two languages, whose measured strength correlates with the model's ability to reach masked minority-language forms.
If this is right
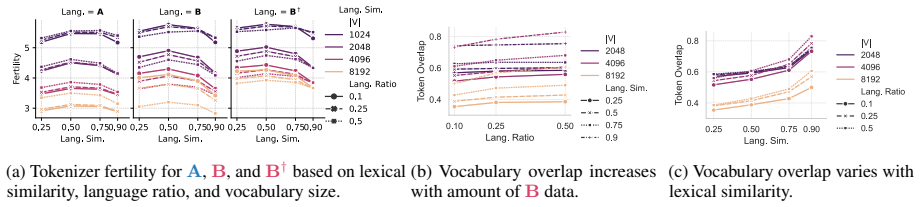
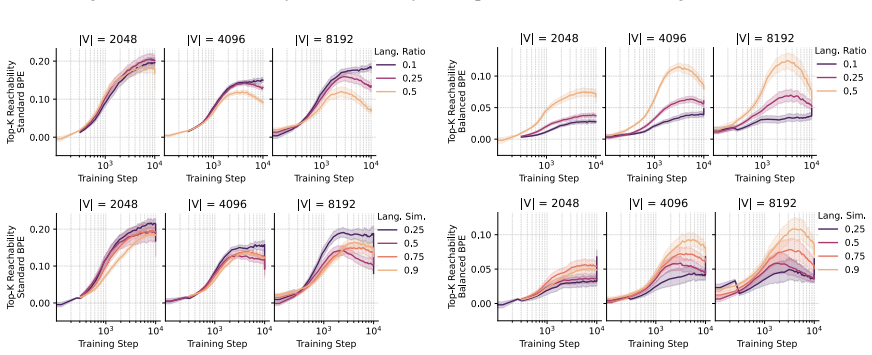
- Smaller vocabulary sizes improve masked transfer by preserving decomposable cross-lingual fragments rather than creating language-specific atoms.
- Transfer develops in stages: grammatical and type-level competence appear before the model can generalize to masked lexical items.
- Bridge strength between tokenizers directly predicts reachability of masked forms in the minority language.
- Raw lexical similarity and data balance are weaker predictors of transfer than whether tokenization maintains reusable substructure.
Where Pith is reading between the lines
- Tokenizer design for real multilingual models could prioritize shared subword patterns even when surface forms differ substantially.
- Early training with deliberately smaller vocabularies might strengthen later cross-lingual generalization in natural language pairs.
- The staged transfer finding suggests evaluation benchmarks should separately measure grammatical versus lexical transfer rather than using single aggregate scores.
Load-bearing premise
Procedurally generated languages with identical structure but different surfaces can isolate the effects of tokenization and lexical distance on transfer without introducing artifacts absent from natural language data.
What would settle it
An experiment measuring tokenizer bridge strength across vocabulary sizes but finding no correlation with masked transfer performance on the held-out language would falsify the claimed mechanism.
Figures



read the original abstract
Cross-lingual transfer in language models is difficult to study in natural corpora because lexical overlap, morphology, data imbalance, and tokenization are entangled. We introduce an in-vitro framework with two procedurally generated languages that share the same ontology, typed grammar, and compositional structure, but differ in surface realization. This lets us independently vary lexical distance, minority-language proportion, tokenizer training regime, and vocabulary size, while evaluating transfer on a masked minority-language condition whose lexical forms are never observed during training. Across 700 controlled runs, we find that transfer is governed less by tokenizer balance or raw lexical similarity than by whether tokenization preserves reusable cross-lingual substructure. Smaller vocabularies often improve masked transfer by keeping words decomposable into shared fragments, whereas larger vocabularies can turn forms into language-specific atoms. We further show that transfer emerges as a staged process: grammatical and type-level competence precede masked lexical generalization. Finally, we attempt to explain this mechanism through tokenizer bridges and show that bridge strength correlates strongly with masked reachability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an in-vitro framework with two procedurally generated languages sharing identical ontology, typed grammar, and compositional structure but differing in surface realization. This allows independent variation of lexical distance, minority-language proportion, tokenizer regime, and vocabulary size. Across 700 controlled runs on a masked minority-language condition with unseen lexical forms, the authors claim transfer depends primarily on whether tokenization preserves reusable cross-lingual substructure (rather than balance or raw lexical overlap), that smaller vocabularies improve transfer by maintaining decomposable shared fragments, that transfer is staged (grammatical/type competence precedes lexical generalization), and that tokenizer bridge strength correlates with masked reachability.
Significance. If the synthetic languages validly isolate the targeted factors without generation artifacts, the work offers a mechanistic account of cross-lingual transfer via substructure preservation and staged competence, supported by a large number of controlled runs. This could guide tokenizer choices in multilingual models. The controlled design is a clear strength for disentangling entangled variables in natural data.
major comments (2)
- [Generation procedure (Section 3)] Generation procedure (Section 3): The central claim that transfer is governed by preservation of reusable substructure (rather than balance or lexical similarity) and that smaller vocabularies improve masked transfer by keeping words decomposable rests on the assumption that the procedural surface realizations isolate these variables without systematic bias in subword decomposability. No validation is provided that the generation algorithm produces morphological variability comparable to natural languages, so the observed smaller-vocab benefit and bridge-strength correlations may be artifacts of the in-vitro construction.
- [Results on staged transfer and bridges (Section 5)] Results on staged transfer and bridges (Section 5): The staged-competence finding and bridge-strength correlation are load-bearing for the mechanistic explanation, yet the paper does not report whether these hold after controlling for the interaction between vocabulary size and lexical distance; if the effects are regime-specific, the general claim that substructure preservation dominates is weakened.
minor comments (2)
- The abstract states 700 runs but the methods should explicitly report variance, statistical tests, and whether all factor combinations were balanced.
- Define 'tokenizer bridges' and the exact metric for bridge strength with a formula or pseudocode in the methods.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our in-vitro framework. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that transfer is governed by preservation of reusable substructure (rather than balance or lexical similarity) and that smaller vocabularies improve masked transfer by keeping words decomposable rests on the assumption that the procedural surface realizations isolate these variables without systematic bias in subword decomposability. No validation is provided that the generation algorithm produces morphological variability comparable to natural languages, so the observed smaller-vocab benefit and bridge-strength correlations may be artifacts of the in-vitro construction.
Authors: We agree that the synthetic generation procedure is intentionally simplified and does not replicate the full morphological richness of natural languages; its purpose is to enable independent control over lexical distance, tokenization, and data balance rather than to model natural morphology. To address the concern, we will add a new subsection to Section 3 with quantitative statistics on the generated languages (average word length, affix frequency, and subword decomposability rates under BPE and unigram tokenizers). These diagnostics will show that the observed effects arise from the controlled manipulations rather than unintended biases in the generator. We view this as a clarification rather than a change to the core claims. revision: yes
-
Referee: The staged-competence finding and bridge-strength correlation are load-bearing for the mechanistic explanation, yet the paper does not report whether these hold after controlling for the interaction between vocabulary size and lexical distance; if the effects are regime-specific, the general claim that substructure preservation dominates is weakened.
Authors: Our experimental grid already varies vocabulary size and lexical distance independently across the 700 runs. However, the staged-transfer and bridge analyses in Section 5 do not explicitly condition on or report the interaction term. We will add supplementary analyses that stratify the staged-competence curves and bridge-strength correlations by the joint levels of vocabulary size and lexical distance. If the patterns remain consistent, we will include the controls in the main text; if they are regime-specific, we will qualify the generality of the substructure-preservation claim. This constitutes a partial revision pending the outcome of the new checks. revision: partial
Circularity Check
No circularity: empirical results from independent experimental controls
full rationale
The paper reports findings from 700 controlled runs on procedurally generated languages where lexical distance, tokenizer regime, vocabulary size, and minority proportion are varied independently. The central claims (transfer depends on preservation of reusable substructure; staged competence; bridge strength correlation) are direct observations from masked transfer evaluations on held-out lexical forms. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text; the derivation chain consists of experimental measurement rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Two procedurally generated languages share the same ontology, typed grammar, and compositional structure but differ in surface realization.
Reference graph
Works this paper leans on
-
[1]
One tokenizer to rule them all: Emergent language plasticity via multilingual tokenizers.arXiv preprint arXiv:2506.10766. Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Valentin Hofmann, Tomasz Limisiewicz, Yulia Tsvetkov, and Noah A Smith. 2024. Magnet: Improving the mul- tilingual fairness of language models with adaptive gradient-based tokenization.Advanc...
-
[2]
Terra Blevins, Hila Gonen, and Luke Zettlemoyer
Emergent abilities in large language models: A survey.arXiv preprint arXiv:2503.05788. Terra Blevins, Hila Gonen, and Luke Zettlemoyer. 2022. Analyzing the mono-and cross-lingual pretraining dy- namics of multilingual language models. InProceed- ings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3575–3590. Terra Blevins...
-
[3]
GLU Variants Improve Transformer
Overlap-based vocabulary generation im- proves cross-lingual transfer among related lan- guages. InProceedings of the 60th Annual Meet- ing of the Association for Computational Linguistics (V olume 1: Long Papers), pages 219–233. Aleksandar Petrov, Emanuele La Malfa, Philip Torr, and Adel Bibi. 2023. Language Model Tokenizers Intro- duce Unfairness Betwee...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
CVC", "CCV
Probing the emergence of cross-lingual align- ment during LLM training. InFindings of the As- sociation for Computational Linguistics: ACL 2024, pages 12159–12173. Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.