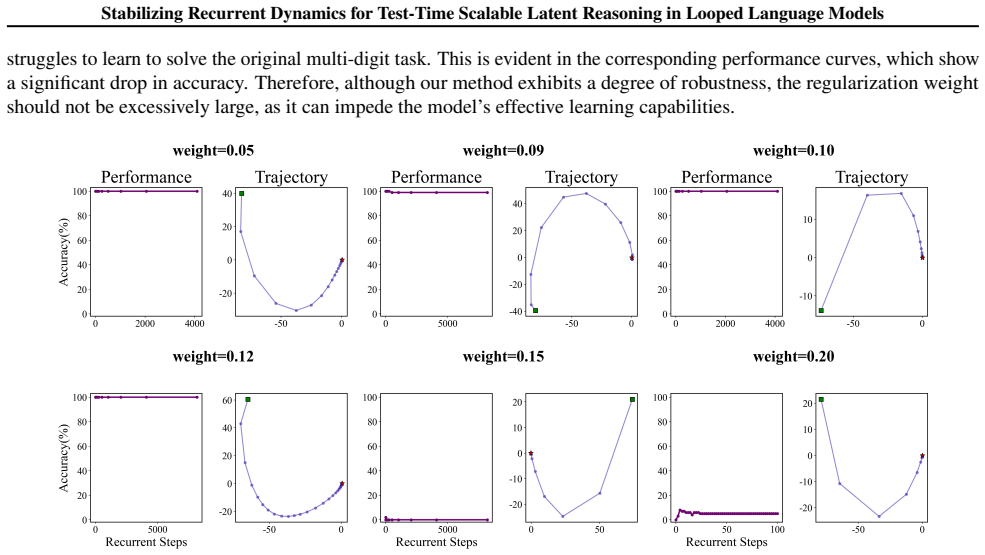
Stabilizing Recurrent Dynamics for Test-Time Scalable Latent Reasoning in Looped Language Models
Pith reviewed 2026-06-29 20:01 UTC · model grok-4.3
The pith
Constraining latent states in looped language models to stable fixed points enables reliable scaling with recurrence depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
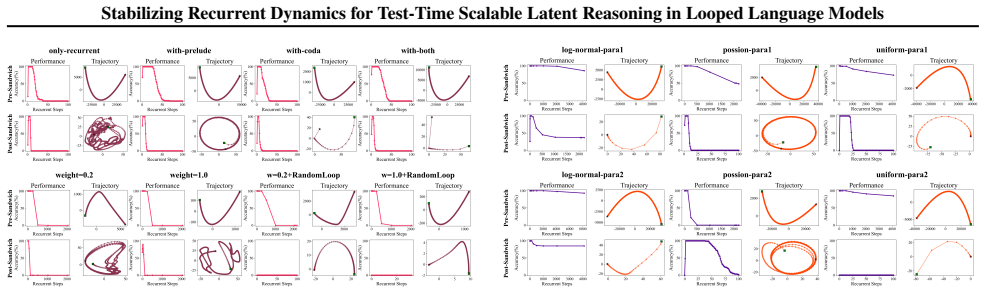
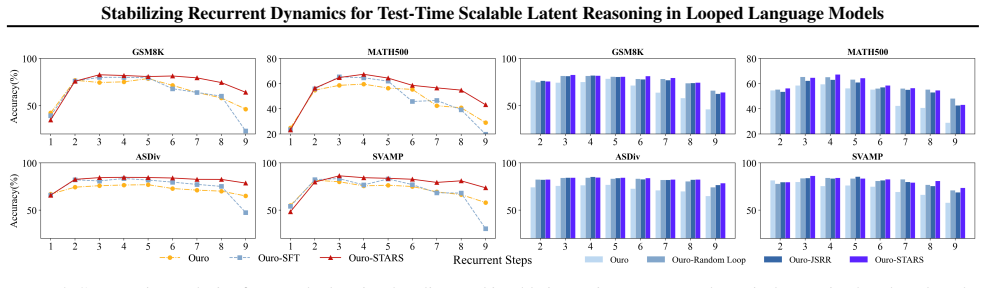
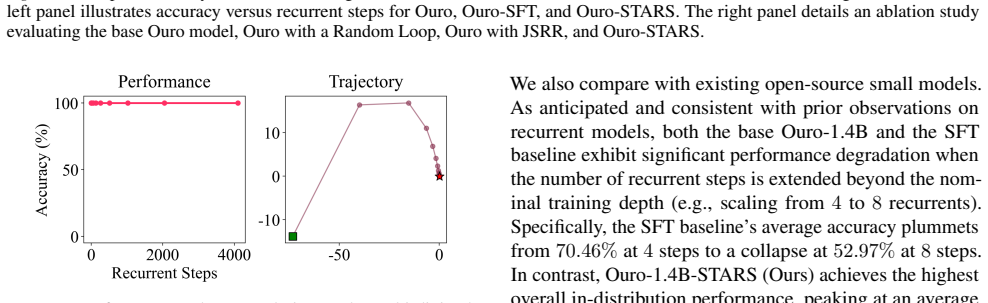
The authors propose STARS, a training framework that constrains latent states in looped language models to approach asymptotically stable fixed points. This is achieved by efficient Jacobian spectral radius regularization with random loop sampling. By conceptualizing reasoning as uncertainty reduction, the method maximizes effectiveness while ensuring rigorous stability. On arithmetic tasks this yields reliable test-time scaling, and on complex mathematical reasoning it mitigates performance degradation as recurrence depth grows while also improving peak performance.
What carries the argument
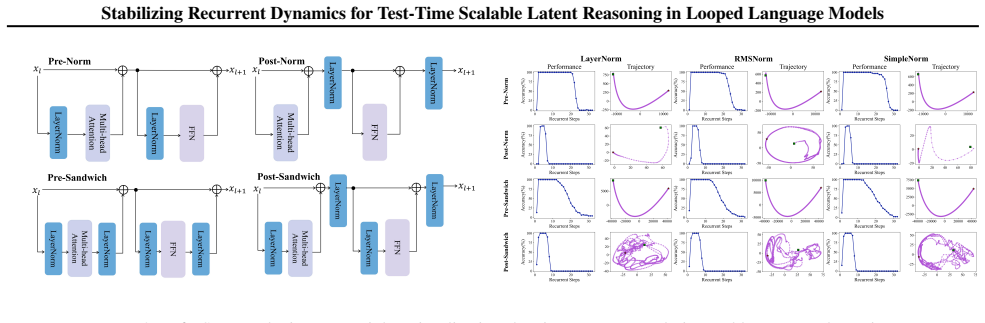
Jacobian Spectral Radius Regularization with random loop sampling, which penalizes the spectral radius of the Jacobian to drive latent dynamics toward asymptotically stable fixed points.
If this is right
- Reliable test-time scaling occurs on arithmetic tasks as recurrence depth increases.
- Performance degradation is substantially reduced as recurrence depth increases on complex mathematical reasoning.
- Peak performance improves alongside the gain in scaling reliability.
- The framework treats reasoning as progressive uncertainty reduction through convergence to fixed points.
Where Pith is reading between the lines
- The dynamical-systems framing could be applied to stabilize recurrence in non-language recurrent architectures.
- Fixed-point properties might be inspected post-training to interpret what intermediate reasoning states represent.
- The regularization objective could be tested in combination with other depth-extension methods such as added recurrence layers.
Load-bearing premise
The premise that driving latent states toward asymptotically stable fixed points will preserve or increase reasoning effectiveness rather than trading one for the other.
What would settle it
Training the same looped models with the Jacobian regularization and observing either lower peak accuracy or continued performance collapse at high recurrence depths compared with unregularized baselines on the same arithmetic or math tasks.
Figures



read the original abstract
Looped Language Models (LoopLMs) enable efficient latent reasoning through depth recurrence, yet exhibit unreliable test-time scaling behavior: performance often peaks at a certain iteration depth and then collapses with further recurrence. Through latent dynamics analysis, we find an inherent trade-off between stability and effectiveness in existing architectures and strategies. By conceptualizing reasoning as uncertainty reduction, we propose that convergence toward stable fixed points while preserving effectiveness represents a promising way. To this end, we propose STARS (STAbility-driven Recurrent Scaling), a training framework that constrains latent states to approach asymptotically stable fixed points. This is realized via efficient Jacobian Spectral Radius Regularization with random loop sampling, enabling STARS to maximize effectiveness while ensuring rigorous stability. Experiments on arithmetic tasks show that STARS achieves reliable test-time scaling, and on complex mathematical reasoning it substantially mitigates performance degradation as recurrence depth increases while also improving peak performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STARS, a training framework for Looped Language Models that uses Jacobian Spectral Radius Regularization combined with random loop sampling to drive latent states toward asymptotically stable fixed points. The central claim is that this resolves an observed stability-effectiveness trade-off in prior LoopLMs, yielding reliable test-time scaling on arithmetic tasks and both higher peak performance and reduced degradation with increasing recurrence depth on complex mathematical reasoning.
Significance. If the reported experimental outcomes hold under rigorous controls, the work would be significant for practical deployment of recurrent latent reasoning, as it offers a concrete regularization-based recipe that appears to decouple stability from performance collapse. The approach builds on standard dynamical-systems tools (spectral radius) in a scalable training loop, which is a strength; however, the lack of a first-principles argument that the regularizer preserves rather than damps useful dynamics limits its theoretical reach.
major comments (1)
- [Abstract / §3 (Method)] The manuscript states an observed stability-effectiveness trade-off and then asserts that spectral-radius regularization plus random loop sampling will 'maximize effectiveness while ensuring rigorous stability,' yet supplies no derivation (Lyapunov analysis, contraction mapping argument, or otherwise) showing why the added term does not simply move the model along the same trade-off curve. This premise is load-bearing for the claim that STARS achieves both goals simultaneously rather than trading one for the other.
minor comments (1)
- [Abstract] The abstract supplies no equations, implementation pseudocode, or quantitative metrics; even a high-level statement of the regularization objective (e.g., the precise form of the Jacobian term and the sampling distribution) would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the theoretical basis of our central claim. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract / §3 (Method)] The manuscript states an observed stability-effectiveness trade-off and then asserts that spectral-radius regularization plus random loop sampling will 'maximize effectiveness while ensuring rigorous stability,' yet supplies no derivation (Lyapunov analysis, contraction mapping argument, or otherwise) showing why the added term does not simply move the model along the same trade-off curve. This premise is load-bearing for the claim that STARS achieves both goals simultaneously rather than trading one for the other.
Authors: We agree that the manuscript supplies no formal derivation (Lyapunov, contraction mapping, or otherwise) proving that Jacobian spectral radius regularization plus random loop sampling necessarily avoids the observed trade-off rather than shifting along it. The approach is motivated by dynamical-systems observations and the empirical finding that prior LoopLMs exhibit the trade-off; the regularizer is introduced to enforce spectral radius below 1 while random loop sampling varies training trajectories to retain effectiveness. The claim rests on experimental outcomes: STARS yields both higher peak performance and reduced degradation with depth on mathematical reasoning, results that would be unlikely under a pure trade-off shift. We will revise §3 and add a discussion paragraph explicitly acknowledging the absence of a first-principles guarantee and grounding the simultaneous improvement claim in the reported empirical evidence. revision: yes
Circularity Check
No circularity; regularization objective is an independent training constraint with no reduction to fitted inputs or self-citations.
full rationale
The paper presents STARS via Jacobian Spectral Radius Regularization as a novel training framework derived from observed trade-offs in prior LoopLMs, with the regularization term introduced as an external constraint rather than a quantity defined by or fitted to the target performance metrics. No equations or claims reduce the effectiveness preservation to a self-referential fit, renamed pattern, or load-bearing self-citation chain. Experimental results on arithmetic and math tasks are reported as validation, not as quantities forced by construction from the inputs. This is the common case of a self-contained proposal against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Cheng, J. and Van Durme, B. Compressed chain of thought: Efficient reasoning through dense representations.arXiv preprint arXiv:2412.13171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Dehghani, M., Gouws, S., Vinyals, O., Uszkoreit, J., and Kaiser, Ł. Universal transformers.arXiv preprint arXiv:1807.03819,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Du, H., Dong, Y ., and Ning, X. Latent thinking optimiza- tion: Your latent reasoning language model secretly en- codes reward signals in its latent thoughts.arXiv preprint arXiv:2509.26314,
-
[7]
Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
Fan, Y ., Du, Y ., Ramchandran, K., and Lee, K. Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
-
[8]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Geiping, J., McLeish, S., Jain, N., Kirchenbauer, J., Singh, S., Bartoldson, B. R., Kailkhura, B., Bhatele, A., and Goldstein, T. Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Training Large Language Models to Reason in a Continuous Latent Space
Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y . Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
9 Stabilizing Recurrent Dynamics for Test-Time Scalable Latent Reasoning in Looped Language Models McLeish, S., Li, A., Kirchenbauer, J., Kalra, D. S., Bartold- son, B. R., Kailkhura, B., Schwarzschild, A., Geiping, J., Goldstein, T., and Goldblum, M. Teaching pretrained lan- guage models to think deeper with retrofitted recurrence. arXiv preprint arXiv:2...
-
[14]
Mohtashami, A., Pagliardini, M., and Jaggi, M. Cot- former: A chain-of-thought driven architecture with budget-adaptive computation cost at inference.arXiv preprint arXiv:2310.10845,
-
[15]
Are NLP Models really able to Solve Simple Math Word Problems?
Patel, A., Bhattamishra, S., and Goyal, N. Are nlp models really able to solve simple math word problems?arXiv preprint arXiv:2103.07191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Shen, Z., Yan, H., Zhang, L., Hu, Z., Du, Y ., and He, Y . Codi: Compressing chain-of-thought into continuous space via self-distillation.arXiv preprint arXiv:2502.21074,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ram ´e, A., Rivi`ere, M., et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Team, Q. et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2(3),
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Sim-cot: Supervised implicit chain-of- thought.arXiv preprint arXiv:2509.20317,
Wei, X., Liu, X., Zang, Y ., Dong, X., Cao, Y ., Wang, J., Qiu, X., and Lin, D. Sim-cot: Supervised implicit chain-of- thought.arXiv preprint arXiv:2509.20317,
-
[20]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Looped transformers are better at learning learning al- gorithms.arXiv preprint arXiv:2311.12424,
Yang, L., Lee, K., Nowak, R., and Papailiopoulos, D. Looped transformers are better at learning learning al- gorithms.arXiv preprint arXiv:2311.12424,
-
[22]
Zelikman, E., Harik, G., Shao, Y ., Jayasiri, V ., Haber, N., and Goodman, N. D. Quiet-star: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Eligen: Entity-level controlled image generation with regional attention
Zhang, J., Zhu, Y ., Sun, M., Luo, Y ., Qiao, S., Du, L., Zheng, D., Chen, H., and Zhang, N. Lightthinker: Thinking step- by-step compression.arXiv preprint arXiv:2502.15589, 2025a. Zhang, Q., Lyu, F., Sun, Z., Wang, L., Zhang, W., Hua, W., Wu, H., Guo, Z., Wang, Y ., Muennighoff, N., et al. A survey on test-time scaling in large language mod- els: What, ...
-
[24]
Zhu, R.-J., Peng, T., Cheng, T., Qu, X., Huang, J., Zhu, D., Wang, H., Xue, K., Zhang, X., Shan, Y ., et al. A survey on latent reasoning.arXiv preprint arXiv:2507.06203, 2025a. Zhu, R.-J., Wang, Z., Hua, K., Zhang, T., Li, Z., Que, H., Wei, B., Wen, Z., Yin, F., Xing, H., et al. Scaling latent reasoning via looped language models.arXiv preprint arXiv:251...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.