KARMA: Karma-Aligned Reward Model Adaptation
Pith reviewed 2026-06-29 17:48 UTC · model grok-4.3
The pith
A Reddit context-only reward model improves LLM pragmatics performance more than one that accurately predicts karma scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
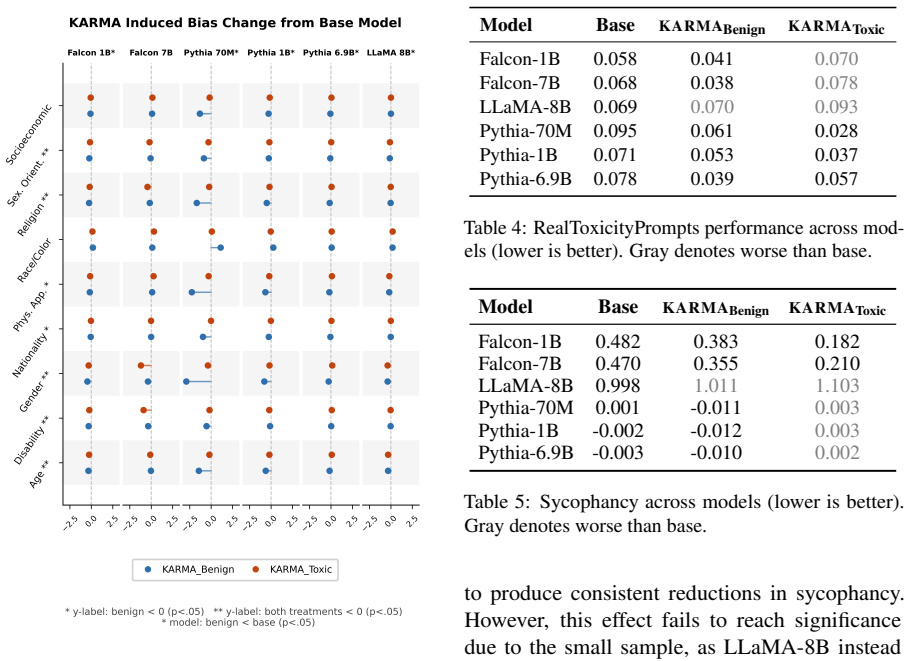
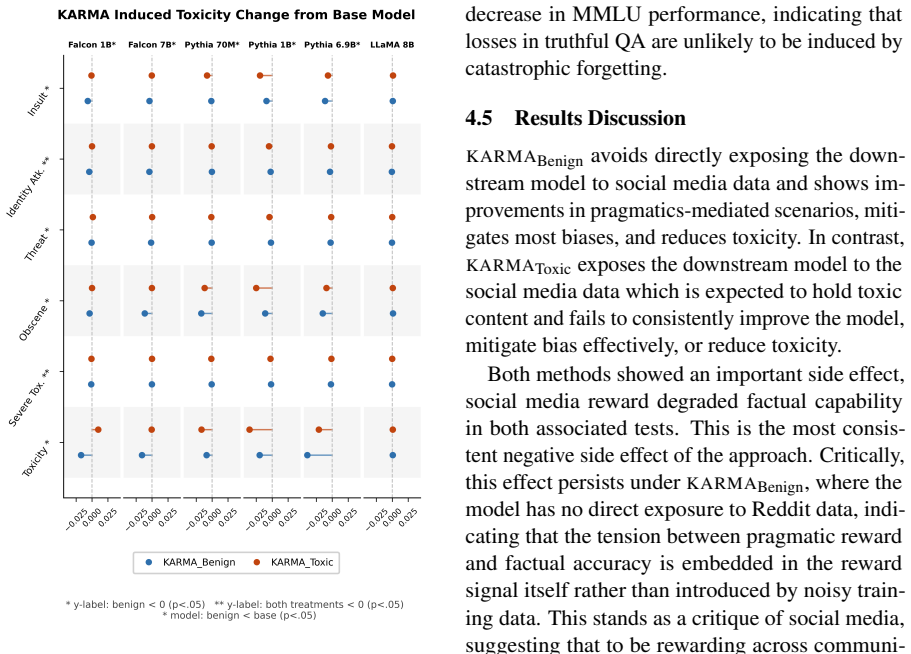
KARMA trains a reward model on Reddit conversations to predict response valuation conditioned on context, and uses this signal to fine-tune language models via reinforcement learning. The highest performing reward model does not lead to better downstream model alignment: a reward model relying exclusively on conversational context was a worse predictor of Reddit karma but yielded substantially better downstream performance. Factuality is consistently diminished by KARMA across all conditions, including when the downstream model has no direct exposure to Reddit data, suggesting that this tension is embedded in the reward signal itself rather than introduced by noisy training data.
What carries the argument
Context-conditioned reward model trained on Reddit conversations to predict response valuation.
If this is right
- LLMs fine-tuned via KARMA exhibit improved performance on pragmatics-mediated tasks.
- Undesirable side effects are largely mitigated in the resulting models.
- Factuality decreases consistently, even without direct exposure to the social media data.
- The trade-off between karma prediction accuracy and downstream alignment is embedded in the reward signal itself.
Where Pith is reading between the lines
- Social media reward signals may inherently favor engaging but less factual responses over accurate ones.
- Similar adaptations could be applied to other social platforms to test if the pattern holds beyond Reddit.
- Future work might explore combining multiple reward signals to balance pragmatics gains with maintained factuality.
Load-bearing premise
Improvements on the evaluated pragmatics-mediated tasks reflect genuine gains in context-sensitive conversational behavior rather than artifacts of the evaluation setup or RL process.
What would settle it
Applying the context-only reward model to fine-tune an LLM and measuring no gain in pragmatics task performance or no factuality drop would falsify the central findings.
Figures

read the original abstract
Human communication depends on implicit social signals where effectiveness is shaped by tone, context, and conversational norms rather than semantic content alone. We introduce KARMA (Karma-Aligned Reward Model Adaptation), a framework for LLM learning of context-sensitive conversational behavior from large-scale social interaction data. KARMA trains a reward model on Reddit conversations to predict response valuation conditioned on context, and uses this signal to fine-tune language models via reinforcement learning to improve performance on pragmatics-mediated tasks. Critically, we find that the highest performing reward model does not lead to better downstream model alignment: a reward model relying exclusively on conversational context was a worse predictor of Reddit karma but yielded substantially better downstream performance. We evaluate the effects of KARMA applied to a downstream model with and without direct exposure to the social media data. The resulting models show improved pragmatics-mediated behaviors with largely mitigated undesirable side effects. Factuality is consistently diminished by KARMA across all conditions, including when the downstream model has no direct exposure to Reddit data, suggesting that this tension is embedded in the reward signal itself rather than introduced by noisy training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KARMA, a framework that trains a reward model on Reddit conversations to predict response valuation conditioned on context and then applies this signal via reinforcement learning to fine-tune LLMs for improved performance on pragmatics-mediated tasks. The central empirical claim is that a reward model relying exclusively on conversational context, despite being a worse predictor of Reddit karma, yields substantially better downstream alignment than higher-performing karma-predicting models; this holds in evaluations both with and without direct exposure to the social media data, with improved pragmatics but consistently diminished factuality across conditions, implying the trade-off is inherent to the reward signal.
Significance. If the results hold after addressing the noted gaps, the work would be significant for demonstrating that reward models optimized purely for implicit social signals from large-scale interaction data can enhance context-sensitive conversational behaviors in LLMs, while also surfacing an embedded tension with factuality that persists even without direct data exposure. The counterintuitive result that the best karma predictor does not produce the best alignment provides a useful empirical caution for reward model design in alignment research.
major comments (2)
- [Evaluation and Results sections] The claim that the context-only reward model produces better downstream performance specifically because of learned context sensitivity (rather than RL optimization artifacts) is load-bearing for the central contribution. No ablations are described that isolate the reward formulation from policy gradient effects, response length biases, or evaluation metric sensitivities (e.g., comparing against RL with a non-contextual or random reward baseline).
- [Results on factuality and no-exposure condition] The assertion that factuality is diminished by KARMA even in the no-direct-Reddit-exposure condition (thereby locating the tension in the reward signal itself) requires stronger support. Details on the exact training protocol, dataset construction, and statistical tests for this condition are needed to rule out confounds from the RL process or evaluation setup.
minor comments (2)
- [Abstract] The abstract states that 'undesirable side effects' are 'largely mitigated' but does not enumerate what those effects are or provide quantitative metrics for them.
- [Methods] Clarify the precise definition of 'conversational context' used in the context-only reward model versus the full karma-predicting models, including any differences in input features or conditioning.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas to strengthen our manuscript. We address each point below.
read point-by-point responses
-
Referee: [Evaluation and Results sections] The claim that the context-only reward model produces better downstream performance specifically because of learned context sensitivity (rather than RL optimization artifacts) is load-bearing for the central contribution. No ablations are described that isolate the reward formulation from policy gradient effects, response length biases, or evaluation metric sensitivities (e.g., comparing against RL with a non-contextual or random reward baseline).
Authors: We acknowledge that the manuscript would benefit from explicit ablations to further isolate the contribution of context sensitivity. The existing experiments compare multiple reward model variants (context-only vs. karma-predictive) under identical RL setups, which provides some control for optimization artifacts. However, to address this concern directly, we will add ablations using a random reward baseline and a non-contextual reward model in the revised version, along with analyses of response length and metric sensitivities. revision: yes
-
Referee: [Results on factuality and no-exposure condition] The assertion that factuality is diminished by KARMA even in the no-direct-Reddit-exposure condition (thereby locating the tension in the reward signal itself) requires stronger support. Details on the exact training protocol, dataset construction, and statistical tests for this condition are needed to rule out confounds from the RL process or evaluation setup.
Authors: We will revise the Methods and Results sections to include comprehensive details on the training protocol and dataset construction for the no-exposure condition. This condition involves applying the KARMA reward model to an LLM fine-tuned on a non-Reddit dataset. We will also report statistical tests, including p-values, for the observed factuality differences across conditions to strengthen the evidence that the trade-off is inherent to the reward signal. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained against external benchmarks
full rationale
The paper trains a reward model to predict Reddit karma from conversational context, then applies the resulting signal via RL to downstream pragmatics tasks, with explicit controls for whether the policy model saw Reddit data. The key empirical claim is a dissociation: the context-only reward model underperforms on karma prediction yet improves alignment metrics, and the factuality penalty persists even without Reddit exposure. No equation or step reduces by construction to a fitted input, no self-citation chain is load-bearing, and no uniqueness theorem or ansatz is smuggled in. The evaluation metrics are distinct from the karma labels used for training, satisfying the independence criteria for a non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Issa Annamoradnejad and Gohar Zoghi. 2024. https://doi.org/10.1016/j.eswa.2024.123685 Colbert: Using bert sentence embedding in parallel neural networks for computational humor . Expert Systems with Applications, 249:123685
- [2]
-
[3]
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. 2023. https://arxiv.org/abs/2305.14233 Enhancing chat language models by scaling high-quality instructional conversations . Preprint, arXiv:2305.14233
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Marta Dynel. 2011. Pragmatics and linguistic research into humour. na
2011
-
[5]
Hao Fang, Hao Cheng, and Mari Ostendorf. 2016. https://arxiv.org/abs/1608.04808 Learning latent local conversation modes for predicting community endorsement in online discussions . Preprint, arXiv:1608.04808
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Madeleine Mary Ferrar. 1993. The Logic of the Ludicrous: A Pragmatic study of humour. University of London, University College London (United Kingdom)
1993
-
[7]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. https://arxiv.org/abs/2009.11462 Realtoxicityprompts: Evaluating neural toxic degeneration in language models . Preprint, arXiv:2009.11462
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Robert Geirhos, J \"o rn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. 2020. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665--673
2020
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. https://arxiv.org/abs/2009.03300 Measuring massive multitask language understanding . Preprint, arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Sura Dhiaa Ibraheem and Nawal Fadhil Abbas. 2016. A pragmatic study of humor. Advances in Language and Literary Studies, 7(1):80--87
2016
-
[12]
Xianbo Li and Kunpei Xu. 2025. Sentiment analysis of conversational implicature: A computational pragmatics approach. Applied Artificial Intelligence, 39(1):2565173
2025
-
[13]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://arxiv.org/abs/2109.07958 Truthfulqa: Measuring how models mimic human falsehoods . Preprint, arXiv:2109.07958
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [14]
-
[15]
Bolei Ma, Yuting Li, Wei Zhou, Ziwei Gong, Yang Janet Liu, Katja Jasinskaja, Annemarie Friedrich, Julia Hirschberg, Frauke Kreuter, and Barbara Plank. 2025. Pragmatics in the era of large language models: A survey on datasets, evaluation, opportunities and challenges. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguisti...
2025
- [16]
-
[17]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. https://arxiv.org/abs/2203.02155 Training language models to f...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Ethan Perez, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, Andy Jones, Anna Chen, Ben Mann, Brian Israel, Bryan Seethor, Cameron McKinnon, Christopher Olah, Da Yan, Daniela Amodei, and 44 others. 2022. https://doi.org/10.48550/ARXIV.2212.09251 Discovering language mo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.09251 2022
-
[19]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Jared Scott and Jesse Roberts. 2026. https://doi.org/10.32473/flairs.39.1.141777 Reward-guided fine-tuning of language models with social feedback . The International FLAIRS Conference Proceedings, 39(1)
-
[21]
Sp1786. 2023. https://huggingface.co/datasets/Sp1786/multiclass-sentiment-analysis-dataset Multiclass sentiment analysis dataset
2023
-
[22]
Vicky Zayats and Mari Ostendorf. 2017. https://arxiv.org/abs/1704.02080 Conversation modeling on reddit using a graph-structured lstm . Preprint, arXiv:1704.02080
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[24]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.