SeDT: Sentence-Transformer Decision-Transformer Conditioning for Multi-Turn Conversation Reliability
Pith reviewed 2026-06-29 18:43 UTC · model grok-4.3
The pith
Conditioning on relevance-annotated history recovers performance lost when tasks unfold across multiple turns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SeDT imports return-to-go conditioning from offline reinforcement learning by annotating each conversation shard with a cumulative relevance score derived from three complementary semantic, lexical, and positional signals and presents the full annotated history to the model at the final turn, without weight changes, without training data, and without discarding context, thereby recovering performance that would otherwise be lost when tasks are revealed incrementally.
What carries the argument
Sentence-transformer Decision-Transformer conditioning that annotates each conversation shard with a cumulative relevance score derived from three complementary signals and supplies the annotated history at the final turn.
If this is right
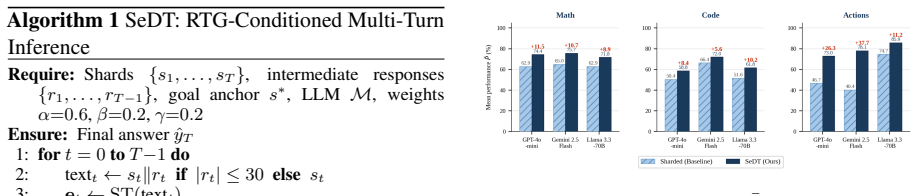
- SeDT outperforms the sharded baseline in all nine model-task combinations.
- Mean performance P rises by as much as 37.7 percent.
- Unreliability falls in seven of the nine combinations.
- The gains appear without any model training or additional data.
- The method preserves the entire conversation context.
Where Pith is reading between the lines
- Models appear to retain the required knowledge but need explicit prioritization signals to use it reliably in extended dialogs.
- The same relevance-annotation pattern could be tested on sequential tasks outside conversation, such as step-by-step planning or code repair.
- Replacing the fixed three-signal scorer with a learned relevance estimator might produce further gains while remaining training-free at inference time.
- Applying the method to conversations longer than those in the current benchmark would test whether the benefit scales with history length.
Load-bearing premise
A flat conversation history assigns equal implicit weight to every prior turn and therefore gives the model no signal to distinguish a critical constraint from incidental dialog.
What would settle it
Running the same Lost-in-Conversation benchmark with relevance scores added to the history and observing no gain in mean performance P or reduction in unreliability compared with the plain sharded baseline.
Figures

read the original abstract
Large language models (LLMs) achieve impressive performance when a task is fully specified in a single turn, yet the same models lose up to 39% of that performance when the identical task is revealed incrementally across multiple turns, a phenomenon documented at scale as Lost in Conversation. Crucially, this collapse is almost entirely a reliability failure; the best case, the aptitude only falls 16%, while the unreliability more than doubles (+112%). We argue that the root cause is structural, a flat conversation history assigns equal implicit weight to every prior turn, giving the model no signal to distinguish a critical constraint from incidental dialog. We present SeDT Sentence-transformer Decision-Transformer, a training-free inference-time method that resolves this by importing return-to-go conditioning from offline reinforcement learning. SeDT annotates each conversation shard with a cumulative relevance score derived from three complementary semantic, lexical, and positional signals and presents the full annotated history to the model at the final turn, without weight changes, without training data, and without discarding context. Evaluated on the Lost-in-Conversation benchmark in three LLMs and three generation tasks, SeDT outperforms the sharded baseline in all nine model-task combinations, with gains up to +37.7% in mean performance P and simultaneous reductions in unreliability in seven of the nine combinations. In short, telling the model which past turns matter is sufficient to substantially recover the performance lost in conversation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SeDT, a training-free inference-time method that imports return-to-go conditioning from offline RL to annotate each shard of a multi-turn conversation history with a cumulative relevance score derived from semantic, lexical, and positional signals via sentence transformers. The annotated history is then presented to the LLM at the final turn. Evaluated on the Lost-in-Conversation benchmark across three LLMs and three generation tasks, SeDT is reported to outperform the sharded baseline in all nine model-task combinations (gains up to +37.7% in mean performance P) while also reducing unreliability in seven of the nine cases.
Significance. If the numerical results prove robust under proper statistical controls, the contribution would be meaningful: it supplies a simple, training-free intervention that recovers substantial performance lost to incremental task specification without model fine-tuning or context truncation. The explicit linkage of relevance annotation to decision-transformer-style conditioning is a clear strength, as is the emphasis on reliability (unreliability metric) rather than raw accuracy alone.
major comments (2)
- [Abstract] Abstract: the headline claim of consistent outperformance 'in all nine model-task combinations' with gains 'up to +37.7%' and unreliability reductions 'in seven of the nine' is carried solely by point estimates. No number of runs, random seeds, standard deviations, error bars, or statistical tests are mentioned, despite the well-known stochasticity of LLM decoding. This directly undermines the ability to assess whether the reported differences are reliable or consistent with noise.
- [Abstract] Abstract (and presumably §3–4): the method is described as 'training-free' and 'without weight changes,' yet the relevance score is formed from 'three complementary semantic, lexical, and positional signals' whose combination rule, normalization, or possible hyperparameters are not specified. If any tunable coefficients exist, the 'parameter-free' framing would require explicit justification.
minor comments (2)
- [Abstract] The abstract would be clearer if it named the three LLMs and three tasks used in the nine combinations.
- [Abstract] Notation for the performance metric P and the unreliability measure should be defined on first use rather than assumed from the benchmark citation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of consistent outperformance 'in all nine model-task combinations' with gains 'up to +37.7%' and unreliability reductions 'in seven of the nine' is carried solely by point estimates. No number of runs, random seeds, standard deviations, error bars, or statistical tests are mentioned, despite the well-known stochasticity of LLM decoding. This directly undermines the ability to assess whether the reported differences are reliable or consistent with noise.
Authors: We acknowledge that the reported results rely on single-run point estimates without multiple random seeds, standard deviations, or statistical tests. While the consistent direction of improvement across all nine model-task combinations offers supporting evidence, this does not replace formal statistical controls. We will revise the abstract and results sections to report performance aggregated over multiple decoding seeds, include standard deviations or error bars, and add appropriate statistical tests where feasible. revision: yes
-
Referee: [Abstract] Abstract (and presumably §3–4): the method is described as 'training-free' and 'without weight changes,' yet the relevance score is formed from 'three complementary semantic, lexical, and positional signals' whose combination rule, normalization, or possible hyperparameters are not specified. If any tunable coefficients exist, the 'parameter-free' framing would require explicit justification.
Authors: The relevance score is computed from the three signals using a fixed, non-tunable aggregation rule with no learned or tunable coefficients. We will revise the method description (and abstract where relevant) to explicitly state the combination formula, normalization steps, and confirm the absence of any hyperparameters, thereby justifying the training-free and parameter-free characterization. revision: yes
Circularity Check
No circularity: empirical method with independent benchmark evaluation
full rationale
The paper presents SeDT as a training-free inference-time intervention that annotates shards with cumulative relevance scores from three signals and feeds the annotated history to the model. No equations, derivations, or parameter-fitting steps are described that would reduce the reported gains to self-referential definitions or fitted inputs. The central claim rests on direct comparison against a sharded baseline on the external Lost-in-Conversation benchmark across nine model-task pairs. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are invoked as load-bearing premises. The method is self-contained against the stated benchmark and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 techni- cal report.arXiv preprint arXiv:2303.08774. Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jia- heng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Let’s (not) just put things in context: Test-time training for long-context llms,
Let’s (not) just put things in context: Test-time training for long-context llms.arXiv preprint arXiv:2512.13898. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others
-
[3]
Evaluating Large Language Models Trained on Code
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901. Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. 2021a. Decision trans- former: Reinforcement learning via sequence mod- eling.Advances in neural information processing s...
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[4]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Christine Herlihy, Jennifer Neville, Tobias Schnabel, and Adith Swaminathan
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2406.01633
On overcoming mis- calibrated conversational priors in llm-based chatbots. arXiv preprint arXiv:2406.01633. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica
-
[7]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Live- codebench: Holistic and contamination free eval- uation of large language models for code.arXiv preprint arXiv:2403.07974. Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, Liangyou Li, Lifeng Shang, Xin Jiang, Qun Liu, and Kam-Fai Wong
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing, pages 20153–20177
Mt-eval: A multi- turn capabilities evaluation benchmark for large lan- guage models. InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing, pages 20153–20177. Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville
2024
-
[9]
LLMs Get Lost In Multi-Turn Conversation
Llms get lost in multi-turn conversation.arXiv preprint arXiv:2505.06120. Geng Liu, Fei Zhu, Rong Feng, Changyi Ma, Shiqi Wang, and Gaofeng Meng
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2602.07338
Intent mismatch causes llms to get lost in multi-turn conversation. arXiv preprint arXiv:2602.07338. Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
-
[11]
RePAIR: Interactive Machine Unlearning through Prompt-Aware Model Repair
Training language models to follow in- structions with human feedback.Advances in neural information processing systems, 35:27730–27744. Jagadeesh Rachapudi, Pranav Singh, Ritali Vatsi, Praful Hambarde, and Amit Shukla. 2026a. Repair: In- teractive machine unlearning through prompt-aware model repair.arXiv preprint arXiv:2604.12820. Jagadeesh Rachapudi, R...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3982–3992. Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie- Yan Liu
2019
-
[13]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Mint: Evaluating llms in multi-turn interaction with tools and language feedback.arXiv preprint arXiv:2309.10691. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others
-
[15]
Chain-of-thought prompting elic- its reasoning in large language models.Advances in neural information processing systems, 35:24824– 24837. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric P Xing, and 1 others. 2023a. Lmsys-chat-1m: A large-scale real-world llm conver- sation datase...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.