Latent Recurrent Transformer: Architecture Exploration, Training Strategies, and Scaling Behavior
Pith reviewed 2026-06-29 19:33 UTC · model grok-4.3
The pith
Latent Recurrent Transformer improves language modeling loss and in-context learning by reusing prior-token hidden states as memory while adding 0.3 percent parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
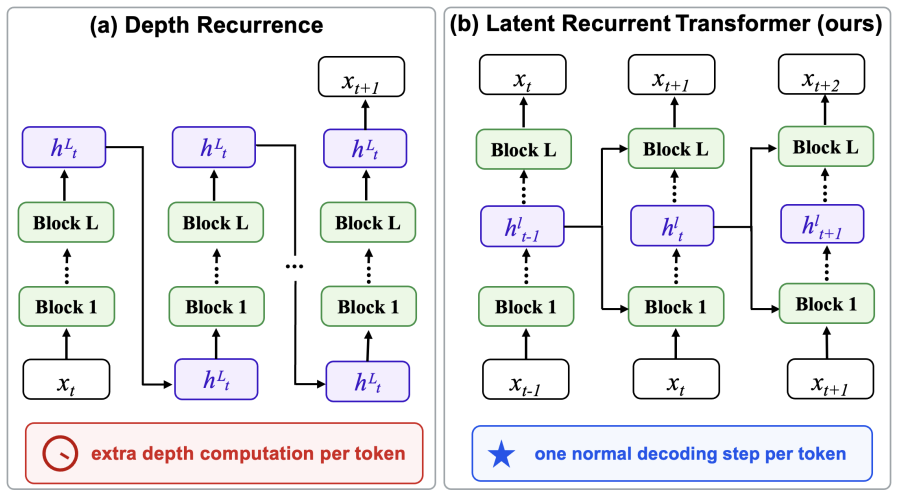
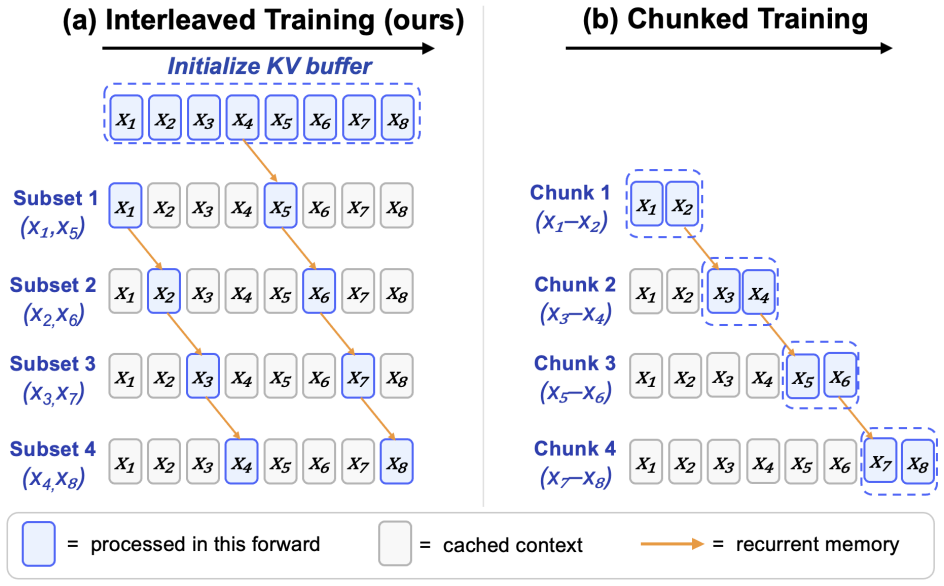
LRT augments autoregressive transformers with a recurrent latent pathway that reuses a source-layer hidden state from the previous token as memory for the current token. Because this state is already computed during ordinary decoding, the method requires no pause tokens or extra depth loops and leaves the standard attention mechanism and KV-cache interface unchanged. Interleaved parallel training pretrains the recurrence without sequential unrolling: a single full-sequence initialization pass builds a shared buffer, after which disjoint position subsets are refined in parallel and written back at roughly twice baseline compute. Across nanochat-style backbones and a wide range of tokens-per-p
What carries the argument
The cross-layer recurrent latent pathway that reuses a high-level source-layer hidden state from the prior token position as memory for the next token, trained via interleaved parallel training.
If this is right
- LRT can be applied to existing nanochat-style transformer backbones with minimal parameter overhead.
- Gains in language-modeling loss and in-context learning hold across a range of tokens-per-parameter budgets under matched effective compute.
- The standard attention mechanism and KV-cache interface remain unchanged, preserving compatibility with existing inference stacks.
- Interleaved parallel training enables scaling of the recurrent component without the cost of full sequential unrolling.
- Both perplexity and few-shot in-context learning metrics improve relative to matched baselines.
Where Pith is reading between the lines
- The explicit state carry-over across tokens could allow better capture of long-range dependencies than attention alone provides in some regimes.
- The interleaved training procedure might be adapted to other forms of recurrence or stateful augmentation in decoder-only models.
- If the equivalence between parallel and sequential updates holds, similar efficiency tricks could reduce training costs for other recurrent neural architectures.
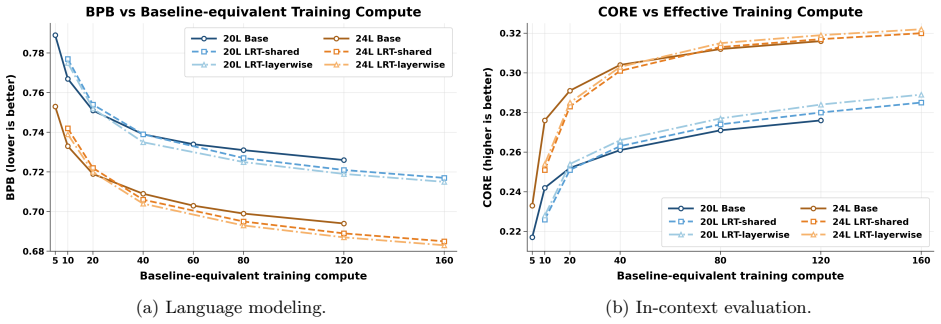
- Performance curves under varying tokens-per-parameter budgets suggest the method may alter scaling behavior by providing recurrence benefits at low marginal cost.
Load-bearing premise
The interleaved parallel training produces hidden-state updates statistically equivalent to true sequential unrolling of the recurrent pathway without introducing distribution shift or gradient inconsistencies.
What would settle it
Training the same model architecture with true sequential unrolling of the recurrent pathway and measuring whether final language-modeling loss or in-context learning scores diverge from those obtained with interleaved parallel training.
Figures
read the original abstract
We study Latent Recurrent Transformer (LRT), a lightweight augmentation of autoregressive transformers that reuses a high-level source-layer hidden state from the previous token as recurrent memory for the next token. Because this source state is already computed during ordinary decoding, LRT adds a cross-layer recurrent latent pathway across positions without inserting pause tokens or extra depth loops, and the standard attention mechanism and KV-cache interface are preserved. To pretrain this recurrence at scale without sequentially unrolling the transformer, we introduce interleaved parallel training: a single full-sequence initialization forward pass builds a shared buffer; then disjoint position subsets are refined in parallel and written back, so that all tokens receive recurrent-memory-aware supervision at roughly 2 times baseline compute. Across nanochat style backbones and a wide range of tokens-per-parameter budgets, LRT improves both language-modeling loss and in-context learning under matched effective compute while adding as little as 0.3% parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Latent Recurrent Transformer (LRT) as a lightweight augmentation to autoregressive transformers. It reuses a high-level source-layer hidden state from the previous token as recurrent memory for the next token via a cross-layer pathway, preserving standard attention and KV-cache. To enable scalable pretraining without sequential unrolling, the authors propose interleaved parallel training: a full-sequence initialization pass populates a shared buffer, followed by parallel refinement of disjoint position subsets that are written back. The central empirical claim is that, across nanochat-style backbones and a range of tokens-per-parameter budgets, LRT improves language-modeling loss and in-context learning under matched effective compute while adding as little as 0.3% parameters.
Significance. If the equivalence between interleaved parallel training and true sequential recurrent unrolling holds and the reported gains are reproducible with proper controls, the work would demonstrate a parameter-efficient route to injecting recurrence into transformers without altering inference interfaces or requiring pause tokens. The scaling analysis across compute budgets could also inform when such augmentations are beneficial. The approach is presented as an engineering contribution rather than a parameter-free derivation.
major comments (2)
- [Abstract / interleaved parallel training] Abstract and training-strategy description: the central claim that LRT yields improvements 'under matched effective compute' requires that the interleaved parallel procedure (full-sequence init pass then parallel writes to a shared buffer) produces hidden-state updates statistically equivalent to true sequential unrolling of the recurrent pathway. No derivation, small-scale verification, ablation on distribution shift, or gradient-flow analysis is supplied to support this equivalence. If the parallel writes introduce causal inconsistencies or train-test mismatch, the LM-loss and ICL gains cannot be attributed to the recurrent mechanism.
- [Abstract] Abstract: the claim of empirical improvements under matched effective compute supplies no quantitative details on baseline models, variance across runs, data-exclusion rules, or the precise operational definition of 'effective compute.' Without these, the magnitude and robustness of the reported gains cannot be assessed.
minor comments (2)
- [Abstract] The abstract states that standard attention/KV-cache are preserved, but the manuscript should explicitly confirm that inference-time recurrence does not alter the KV-cache interface or require changes to autoregressive decoding.
- [Training strategy] Minor notation: the description of 'disjoint position subsets' in the parallel refinement step would benefit from a diagram or pseudocode to clarify how writes to the shared buffer maintain causality.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments. We address the two major concerns point-by-point below, agreeing that additional justification and detail are needed.
read point-by-point responses
-
Referee: [Abstract / interleaved parallel training] Abstract and training-strategy description: the central claim that LRT yields improvements 'under matched effective compute' requires that the interleaved parallel procedure (full-sequence init pass then parallel writes to a shared buffer) produces hidden-state updates statistically equivalent to true sequential unrolling of the recurrent pathway. No derivation, small-scale verification, ablation on distribution shift, or gradient-flow analysis is supplied to support this equivalence. If the parallel writes introduce causal inconsistencies or train-test mismatch, the LM-loss and ICL gains cannot be attributed to the recurrent mechanism.
Authors: We acknowledge that the manuscript provides no formal derivation, small-scale verification, or gradient-flow analysis to establish statistical equivalence between interleaved parallel training and true sequential unrolling. This is a substantive gap. In revision we will add a new subsection containing (i) a small-scale controlled comparison of hidden-state distributions and per-token losses on a 125M model, (ii) an explicit discussion of potential causal inconsistencies introduced by the shared buffer, and (iii) a brief gradient-flow argument showing that the parallel refinement step preserves the same first-order updates as sequential recurrence. These additions will allow readers to assess whether the reported gains can be attributed to the recurrent mechanism. revision: yes
-
Referee: [Abstract] Abstract: the claim of empirical improvements under matched effective compute supplies no quantitative details on baseline models, variance across runs, data-exclusion rules, or the precise operational definition of 'effective compute.' Without these, the magnitude and robustness of the reported gains cannot be assessed.
Authors: We agree that the abstract is insufficiently precise. We will expand it to name the exact baseline architectures and sizes, report standard deviations over at least three independent runs, state the data-exclusion policy, and define 'effective compute' as total training FLOPs normalized by the observed 2 imes overhead of the interleaved procedure so that comparisons are made at equal wall-clock-equivalent cost. revision: yes
Circularity Check
No circularity; claims rest on empirical scaling results
full rationale
The abstract and provided text present LRT as an architectural change plus an interleaved parallel training procedure whose equivalence to sequential unrolling is asserted as an engineering solution rather than derived from prior fitted quantities or self-citations. No equations, self-definitional loops, or load-bearing self-citations appear; the reported LM-loss and ICL gains are framed as measured outcomes under matched compute, leaving the central chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901,
1901
-
[2]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Soham De, Samuel L Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Addressing some limitations of transformers with feedback memory.arXiv preprint arXiv:2002.09402,
Angela Fan, Thibaut Lavril, Edouard Grave, Armand Joulin, and Sainbayar Sukhbaatar. Addressing some limitations of transformers with feedback memory.arXiv preprint arXiv:2002.09402,
-
[4]
Daniel Y Fu, Tri Dao, Khaled K Saab, Armin W Thomas, Atri Rudra, and Christopher R´ e. Hungry hungry hippos: Towards language modeling with state space models.arXiv preprint arXiv:2212.14052,
-
[5]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. InInternational Conference on Learning Representations, volume 2024, pages 27896–27923,
2024
-
[6]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Thinking tokens for language modeling.arXiv preprint arXiv:2405.08644,
David Herel and Tomas Mikolov. Thinking tokens for language modeling.arXiv preprint arXiv:2405.08644,
-
[9]
Trans- formerfam: Feedback attention is working memory.arXiv preprint arXiv:2404.09173,
Dongseong Hwang, Weiran Wang, Zhuoyuan Huo, Khe Chai Sim, and Pedro Moreno Mengibar. Trans- formerfam: Feedback attention is working memory.arXiv preprint arXiv:2404.09173,
-
[10]
Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bern- stein. Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan. github. io/posts/muon, 6(3):4,
2024
-
[11]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al. Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Fineweb-edu: the finest collection of educational content, 2024.URL https://huggingface
11 Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. Fineweb-edu: the finest collection of educational content, 2024.URL https://huggingface. co/datasets/HuggingFaceFW/fineweb-edu,
2024
-
[13]
Amirkeivan Mohtashami and Martin Jaggi. Landmark attention: Random-access infinite context length for transformers.arXiv preprint arXiv:2305.16300,
-
[14]
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave no context behind: Efficient infinite context transformers with infini-attention.arXiv preprint arXiv:2404.07143, 101:15,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo andK. K. G. V. Grella, et al. Rwkv: Reinventing rnns for the transformer era.arXiv preprint arXiv:2305.13048,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Jacob Pfau, William Merrill, and Samuel R Bowman. Let’s think dot by dot: Hidden computation in transformer language models.arXiv preprint arXiv:2404.15758,
-
[17]
Compressive Transformers for Long-Range Sequence Modelling
Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling.arXiv preprint arXiv:1911.05507,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[18]
Simplified State Space Layers for Sequence Modeling
Jimmy TH Smith, Andrew Warrington, and Scott W Linderman. Simplified state space layers for sequence modeling.arXiv preprint arXiv:2208.04933,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states. arXiv preprint arXiv:2407.04620,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, L´ eonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ram´ e, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Memorizing transformers.arXiv preprint arXiv:2203.08913,
Yuhuai Wu, Markus N Rabe, DeLesley Hutchins, and Christian Szegedy. Memorizing transformers.arXiv preprint arXiv:2203.08913,
-
[23]
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D Goodman. Quiet-star: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
13 A Implementation Details Backbone.We follow the nanochat training stack [Karpathy, 2025]. The baseline is a pre-norm decoder- only Transformer [Vaswani et al., 2017, Radford et al., 2019, Brown et al., 2020] with untied input embeddings and LM head, parameter-free RMSNorm [Zhang and Sennrich, 2019], RoPE positional encodings with base 10,000 [Su et al....
2025
-
[25]
The final shard is held out as validation and the remaining shards are used for training
Data.We pretrain on FineWeb-Edu 100BT [Lozhkov et al., 2024] using the pre-shuffled nanochat re- lease [Karpathy, 2025]. The final shard is held out as validation and the remaining shards are used for training. Documents are tokenized on the fly with the nanochat BPE tokenizer with vocabulary size 32,768. We train with MuonAdamW following nanochat default...
2024
-
[26]
WithC= 256, the recurrent signal becomes too sparse and the result is nearly identical to the baseline
With chunk sizeC= 64, chunked training slightly improves over the baseline, but remains far behind interleaved parallel training. WithC= 256, the recurrent signal becomes too sparse and the result is nearly identical to the baseline. Moreover, small chunks are inefficient in wall- clock training: with sequence length 2048,C= 64 requires 32 sequential chun...
2048
-
[27]
IncreasingScreates a longer sparse refinement chain, but does not improve BPB in this setting
Lower BPB is better. IncreasingScreates a longer sparse refinement chain, but does not improve BPB in this setting. We therefore useS= 2 by default, which is the simplest and most parallel option that matches the best observed BPB. Algorithm 1Interleaved Parallel Training Step 1:Inputs: token sequencex 1:T , subset countS, partition{I s}S s=1 2:B (0) ←For...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.