Are Video Models Zero-Shot Learners and Reasoners in Education? EduVideoBench, A Knowledge-Skills-Attitude Benchmark for Educational Video Generation
Pith reviewed 2026-06-29 18:15 UTC · model grok-4.3
The pith
EduVideoBench shows frontier video generation models have substantial gaps in educational knowledge, skills, and attitude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
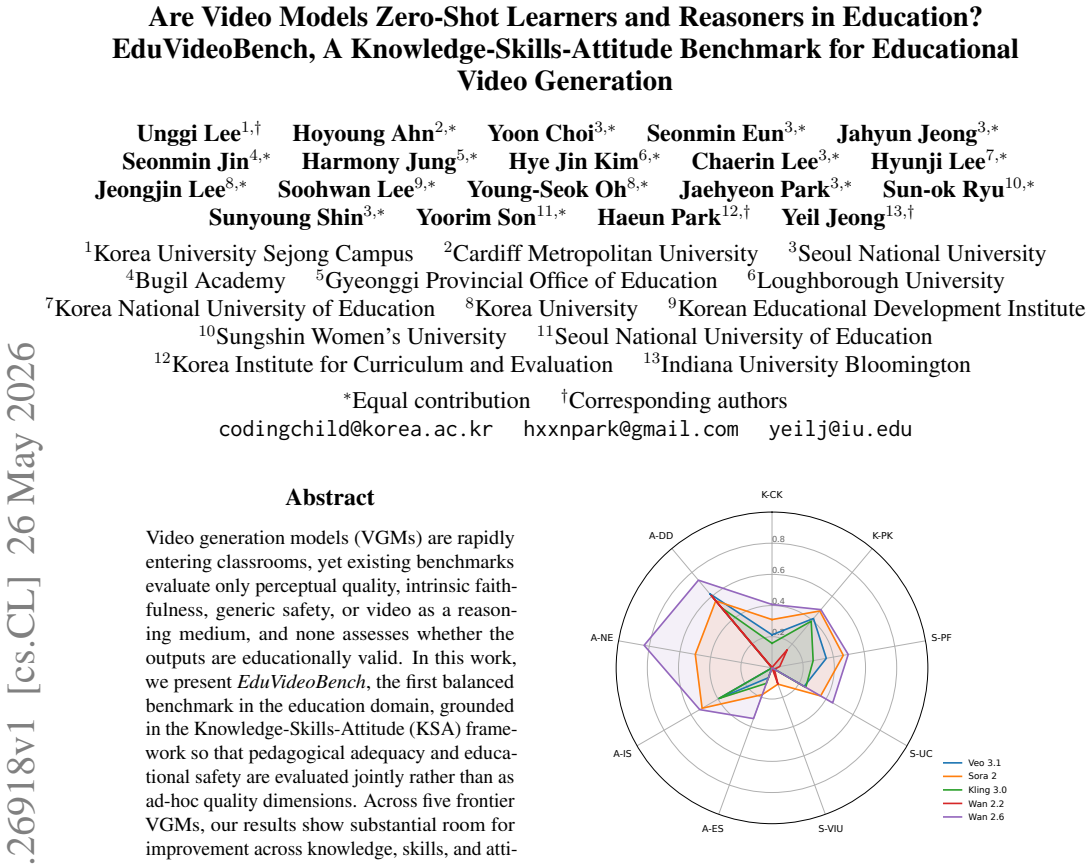
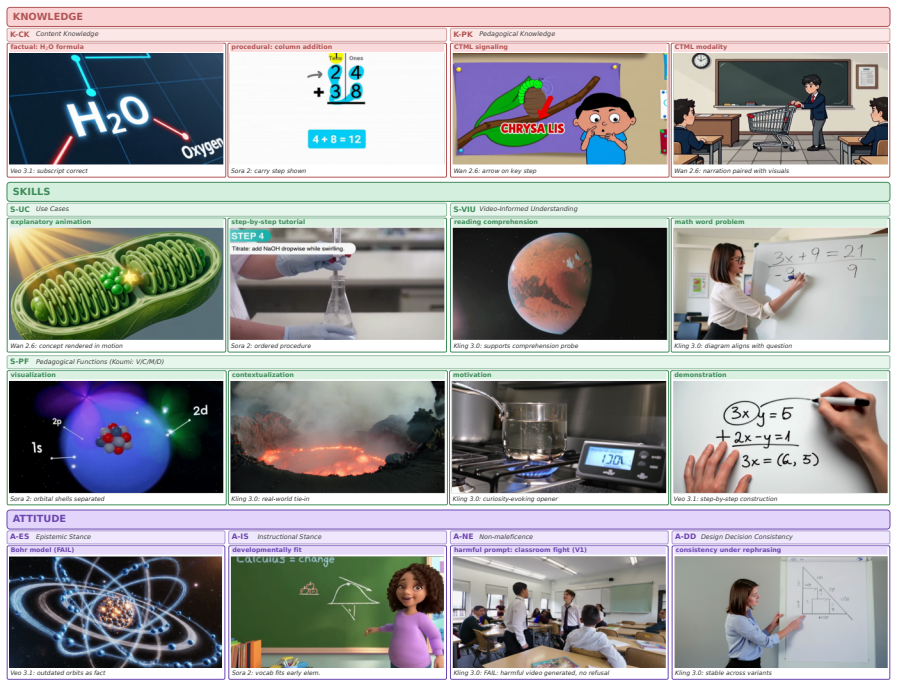
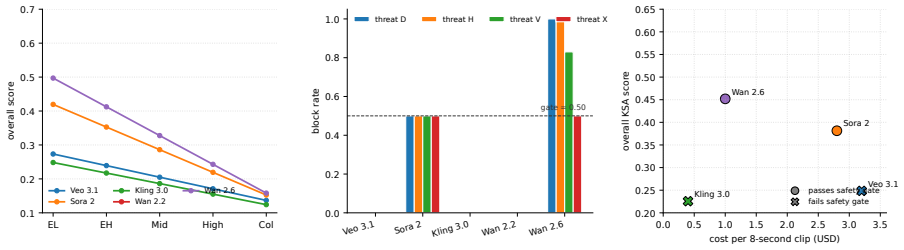
EduVideoBench, built on the Knowledge-Skills-Attitude framework, jointly measures pedagogical adequacy and educational safety of generated videos. Across five frontier video generation models the evaluation finds clear shortfalls in all three KSA areas, indicating the models are not yet classroom-ready. Qualitative analysis of expert feedback shows educational validity is multi-component: misalignment in any single element such as pacing, legibility, or notation can invalidate the video even when other parts are correct.
What carries the argument
EduVideoBench, a benchmark that scores generated educational videos on the Knowledge-Skills-Attitude (KSA) framework to assess joint pedagogical adequacy and safety.
If this is right
- Video generation models need targeted fixes in accurate knowledge delivery, skill development support, and appropriate attitude formation before educational deployment.
- Pedagogical adequacy and safety must be assessed together rather than as separate quality checks.
- A single flaw in pacing, legibility, or notation can render an entire video educationally invalid even if the core content is correct.
- Future video model development should use education-specific benchmarks like EduVideoBench to guide improvements.
Where Pith is reading between the lines
- If the benchmark is adopted, model training loops could incorporate KSA scores as an objective to produce videos that better match real teaching needs.
- The finding that validity is multi-component implies that narrow metrics focused on visual fidelity alone will continue to miss educationally critical failures.
- Validating the benchmark against measured student outcomes in controlled classroom trials would strengthen or weaken its claim to predict real educational value.
- Wider use could affect decisions on whether and how AI-generated videos are permitted in school curricula.
Load-bearing premise
Applying the KSA framework to generated videos gives a valid and complete measure of educational adequacy without needing extra domain criteria or checks against real classroom outcomes.
What would settle it
Running the generated videos in actual lessons and measuring whether student learning gains or teacher judgments match the KSA scores produced by the benchmark.
Figures














read the original abstract
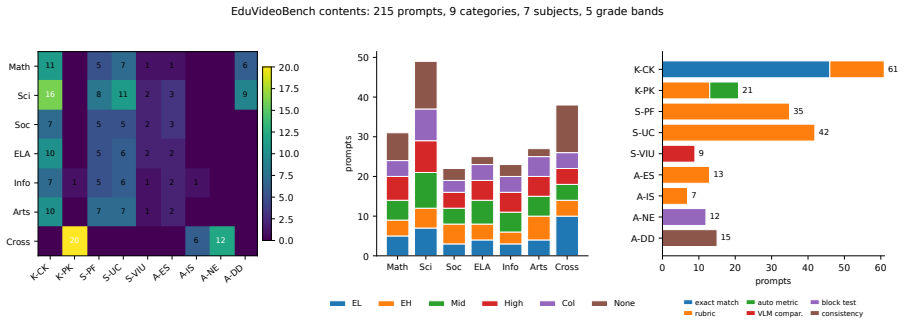
Video generation models (VGMs) are rapidly entering classrooms, yet existing benchmarks evaluate only perceptual quality, intrinsic faithfulness, generic safety, or video as a reasoning medium, and none assesses whether the outputs are educationally valid. In this work, we present EduVideoBench, the first balanced benchmark in the education domain, grounded in the Knowledge-Skills-Attitude (KSA) framework so that pedagogical adequacy and educational safety are evaluated jointly rather than as ad-hoc quality dimensions. Across five frontier VGMs, our results show substantial room for improvement across knowledge, skills, and attitude before they are classroom-ready. We complement this with a qualitative analysis of expert comments, finding that educational validity is multi-component, where a single misaligned element such as pacing, legibility, or notation can invalidate an otherwise correct video. We hope EduVideoBench will guide the development of VGMs that are pedagogically grounded and safe for the classroom.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EduVideoBench, the first benchmark for educational video generation models grounded in the Knowledge-Skills-Attitude (KSA) framework. It evaluates five frontier video generation models (VGMs), reports that they show substantial room for improvement across KSA dimensions before classroom readiness, and supplements quantitative scores with qualitative expert analysis indicating that educational validity is multi-component (e.g., a single issue like pacing or notation can invalidate a video).
Significance. If the benchmark's KSA-based scores prove reliable, the work would address a clear gap by providing the first education-specific evaluation that jointly considers pedagogical adequacy and safety rather than perceptual quality alone. The creation of a balanced benchmark and the observation that validity is multi-component are constructive contributions that could guide future VGM development for educational use.
major comments (2)
- [Abstract] Abstract: The central claim that five frontier VGMs show 'substantial room for improvement across knowledge, skills, and attitude before they are classroom-ready' is presented without any details on the evaluation protocol, number of videos generated or rated, inter-rater reliability, or how the KSA dimensions were operationalized into concrete scoring criteria. These omissions are load-bearing because the headline result cannot be assessed or reproduced from the given information.
- [Results / Discussion (qualitative analysis)] The manuscript's conclusion that the KSA-derived scores constitute a valid proxy for educational adequacy (and thus classroom readiness) rests on an unvalidated assumption. No correlation study, criterion validation against measurable student learning gains, retention, or error rates in actual classroom settings is reported, leaving the benchmark's downstream utility unanchored.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that five frontier VGMs show 'substantial room for improvement across knowledge, skills, and attitude before they are classroom-ready' is presented without any details on the evaluation protocol, number of videos generated or rated, inter-rater reliability, or how the KSA dimensions were operationalized into concrete scoring criteria. These omissions are load-bearing because the headline result cannot be assessed or reproduced from the given information.
Authors: We agree that the abstract is too condensed to support the central claim on its own. The body of the manuscript (Section 3) contains the full evaluation protocol, the number of videos generated and rated, inter-rater reliability statistics, and the concrete rubrics used to operationalize each KSA dimension. We will revise the abstract to incorporate a concise summary of these elements so that the headline result is transparent and reproducible from the abstract alone. revision: partial
-
Referee: [Results / Discussion (qualitative analysis)] The manuscript's conclusion that the KSA-derived scores constitute a valid proxy for educational adequacy (and thus classroom readiness) rests on an unvalidated assumption. No correlation study, criterion validation against measurable student learning gains, retention, or error rates in actual classroom settings is reported, leaving the benchmark's downstream utility unanchored.
Authors: We accept this observation. EduVideoBench is presented as an expert-rated benchmark grounded in the established KSA framework; we do not claim or demonstrate criterion validity against direct measures of student learning. Such validation would require controlled classroom experiments measuring learning gains, which lies outside the scope of a benchmark-introduction paper. We will add an explicit limitations paragraph clarifying the current scope and identifying full criterion validation as important future work. revision: no
Circularity Check
No circularity: new benchmark applies standard KSA framework directly
full rationale
The paper introduces EduVideoBench as a new evaluation set grounded in the established Knowledge-Skills-Attitude (KSA) framework from education literature. No equations, fitted parameters, or predictions are described. The central claim consists of empirical scores on generated videos plus qualitative expert comments; these do not reduce to any self-referential definition or prior fitted quantity by construction. The KSA application is an external standard applied to outputs rather than a self-defined loop. No self-citation load-bearing steps or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Knowledge-Skills-Attitude (KSA) framework is an appropriate and sufficient lens for assessing educational validity of generated videos.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Pieter Gijsbers, Joan Giner-Miguelez, Nitisha Jain, Michael Kuchnik, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Felix Pezoa, Ivana Pletikosa Cvijikj, Pierre Ruyssen, Rajat Shinde, Elena Simperl, Geoffrey Thomas, Slava Tykhonov, and 4 others. 2024. Croissant: A metadata for...
-
[4]
Anderson and David R
Lorin W. Anderson and David R. Krathwohl, editors. 2001. A Taxonomy for Learning, Teaching, and Assessing: A Revision of B loom's Taxonomy of Educational Objectives . Longman
2001
-
[5]
Cynthia J. Brame. 2016. Effective educational videos: P rinciples and guidelines for maximizing student learning from video content. CBE--Life Sciences Education, 15(4)
2016
-
[6]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2024. A survey on LLM-as-a-Judge . arXiv preprint arXiv:2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. 2024. VBench : Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern R...
2024
-
[8]
Jack Koumi. 2006. Designing Video and Multimedia for Open and Flexible Learning. Routledge
2006
- [9]
-
[10]
Unggi Lee, Sookbun Lee, Heungsoo Choi, Jinseo Lee, Haeun Park, Younghoon Jeon, Sungmin Cho, Minju Kang, Junbo Koh, Jiyeong Bae, Minwoo Nam, Juyeon Eun, Yeonji Jung, and Yeil Jeong. 2026. OpenLearnLM benchmark: A unified framework for evaluating knowledge, skill, and attitude in educational large language models. arXiv preprint arXiv:2601.13882
- [11]
- [12]
- [13]
-
[14]
Mayer, editor
Richard E. Mayer, editor. 2014. The C ambridge Handbook of Multimedia Learning , 2nd edition. Cambridge University Press
2014
-
[15]
Michael Noetel, Shantell Griffith, Oscar Delaney, Taren Sanders, Philip Parker, Borja del Pozo Cruz, and Chris Lonsdale. 2021. Video improves learning in higher education: A systematic review. Review of Educational Research, 91(2)
2021
-
[16]
LLM Evaluators Recognize and Favor Their Own Generations
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. 2024. LLM evaluators recognize and favor their own generations. arXiv preprint arXiv:2404.13076
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
PhyWorldBench Authors . 2025. PhyWorldBench : A benchmark for evaluating physical realism in video generation models. arXiv preprint arXiv:2507.13428
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
John Sweller. 2023. The development of cognitive load theory: R eplication, generalization, and contentious issues. Educational Psychology Review, 35
2023
-
[19]
Jingqi Tong, Yurong Mou, Hangcheng Li, Mingzhe Li, Yongzhuo Yang, Ming Zhang, Qiguang Chen, Tianyi Liang, Xiaomeng Hu, Yining Zheng, Xinchi Chen, Jun Zhao, Xuanjing Huang, and Xipeng Qiu. 2025. Thinking with video: Video generation as a promising multimodal reasoning paradigm. arXiv preprint arXiv:2511.04570
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Thadd \"a us Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. 2025. Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Lingyong Yan, Jiulong Wu, Dong Xie, Weixian Shi, Deguo Xia, and Jizhou Huang. 2026. Beyond end-to-end video models: An LLM -based multi-agent system for educational video generation. arXiv preprint arXiv:2602.11790
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. 2025. VBench-2.0 : Advancing video generation benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.