Agile Online Model Selection: Resolving Adaptation Lag via Safeguarded Large Learning Rates
Pith reviewed 2026-06-29 19:42 UTC · model grok-4.3
The pith
An online algorithm uses learning rates as large as the time horizon while keeping total penalty logarithmic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A post-hoc penalty mechanism in optimistic online mirror descent permits learning rates up to Θ(T) by monitoring and excluding steps that would produce excessive regret, keeping the cumulative penalty O(log T) and thereby achieving near-optimal dynamic regret together with rapid adaptation to distribution shifts.
What carries the argument
The post-hoc penalty mechanism that dynamically excludes learning rates incurring excessive regret.
If this is right
- Dynamic regret bounds remain near-optimal even though rates reach Θ(T).
- Superior rates are obtained in benign environments without sacrificing the worst case.
- Empirical adaptation lag drops from hundreds of rounds to a few on both synthetic and real datasets.
- The method works under standard online convex optimization assumptions.
Where Pith is reading between the lines
- Similar post-hoc exclusion could relax learning-rate constraints in other non-stationary online problems.
- The approach may allow real-time systems to react faster to abrupt changes without manual retuning.
- Extending the penalty rule to non-convex losses would be a direct next test.
Load-bearing premise
The penalty can be computed from past data only and still stays O(log T) without extra assumptions on the losses.
What would settle it
A run in which the measured cumulative penalty grows faster than O(log T) or adaptation lag stays on the order of hundreds of rounds.
Figures
read the original abstract
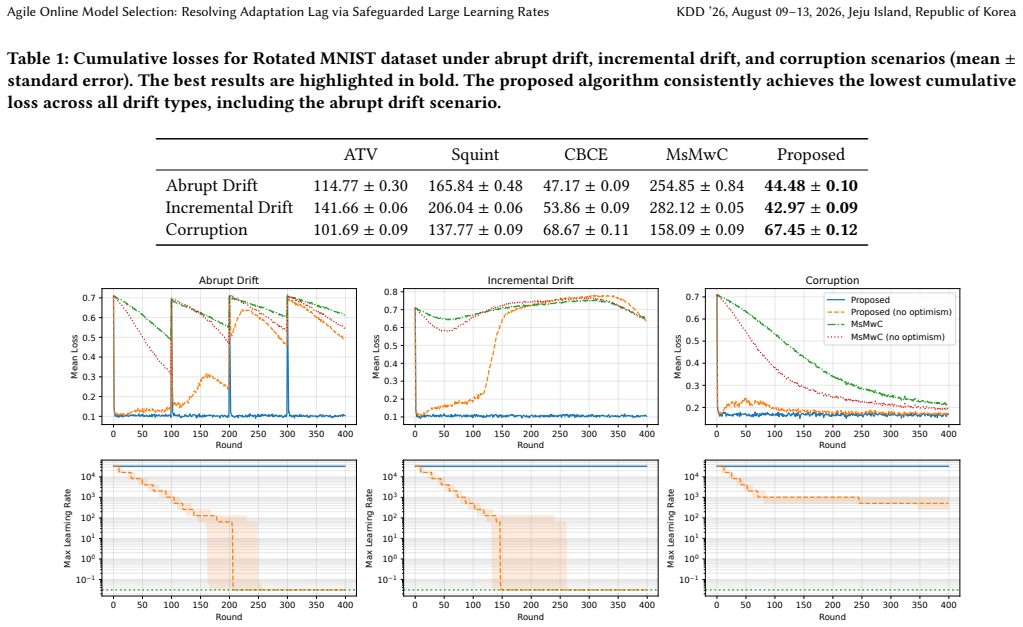
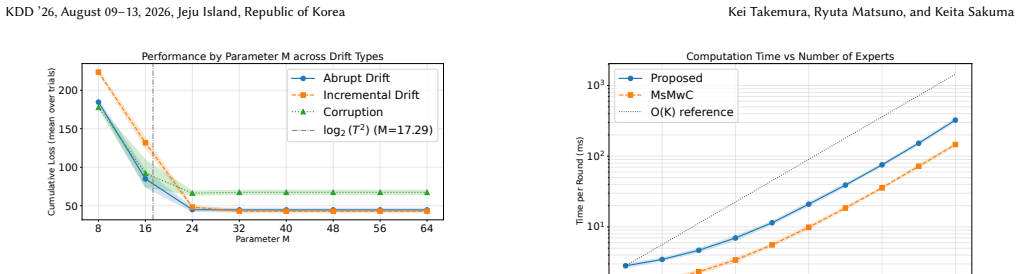
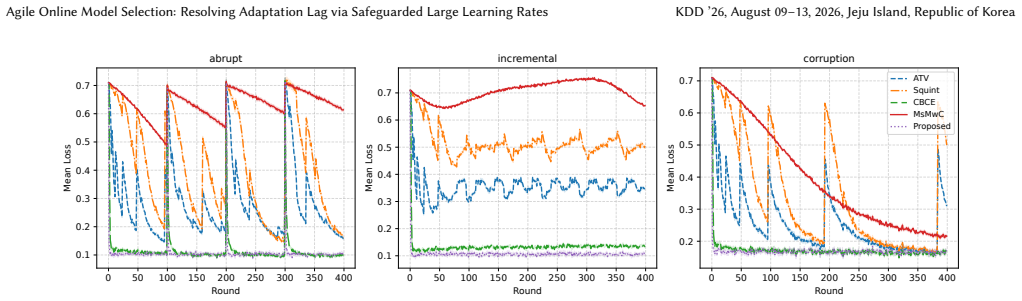
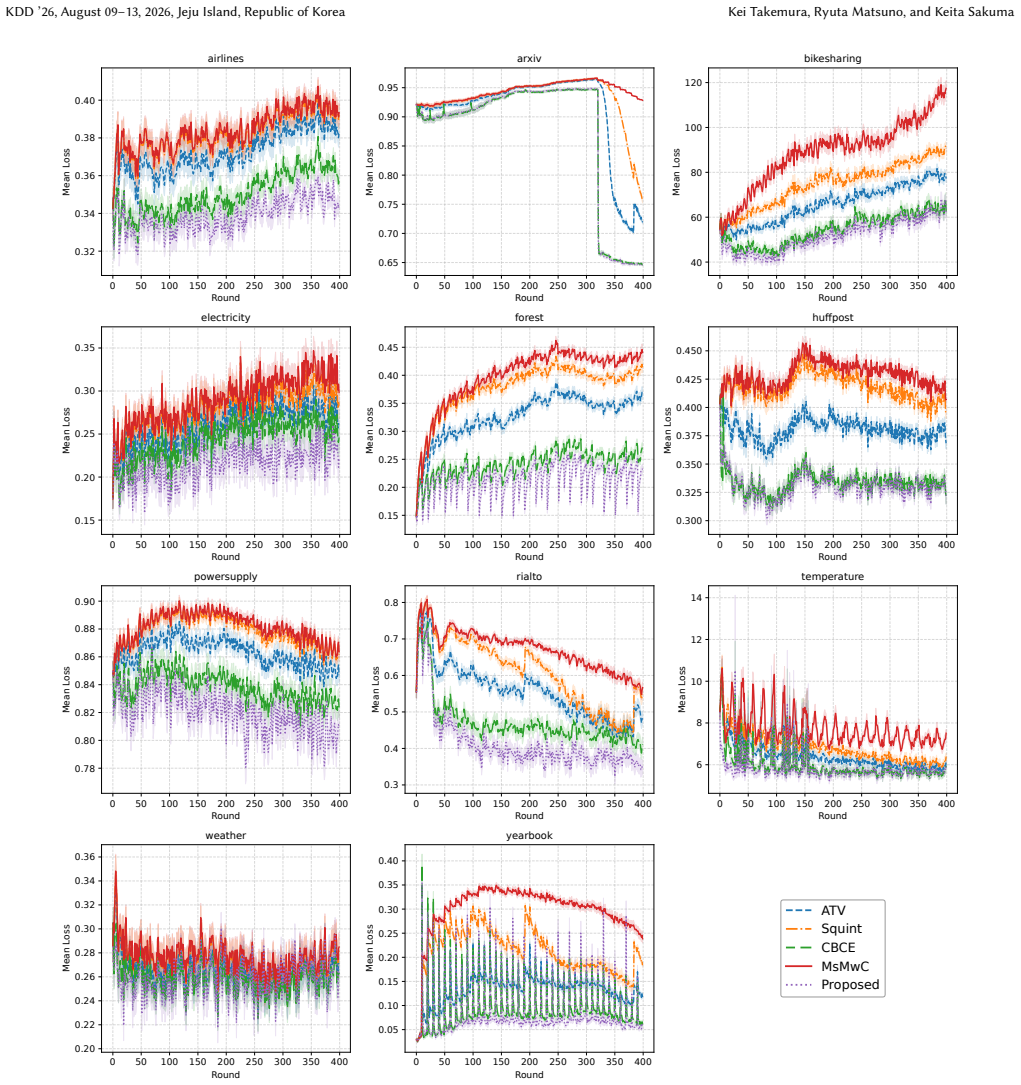
Maintaining predictive accuracy in non-stationary environments requires online model selection to adapt autonomously to unknown distribution shifts. However, existing tuning-free algorithms face a fundamental trade-off between robustness and agility. Specifically, to ensure dynamic regret bounds, they must restrict learning rates to small constants (e.g., $O(1)$). This restriction inevitably causes significant adaptation lag during abrupt changes. To resolve this, we propose a novel optimistic online mirror descent that utilizes safeguarded large learning rates up to $\Theta(T)$, where $T$ is the number of rounds. Our key technical contribution is a post-hoc penalty mechanism that dynamically monitors unstable updates and excludes learning rates incurring excessive regret, eliminating the need for restrictive a priori constraints. We show that the cumulative penalty remains $O(\log T)$, allowing our algorithm to match near-optimal worst-case guarantees while achieving superior rates in benign cases. Empirical evaluations on three synthetic and eleven diverse real-world datasets demonstrate that our approach reduces the adaptation lag from hundreds of rounds to a few rounds, consistently outperforming tuning-free baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an optimistic online mirror descent algorithm using safeguarded large learning rates up to Θ(T) together with a post-hoc penalty mechanism that monitors unstable updates and excludes those incurring excessive regret. It claims this yields a cumulative penalty of O(log T), enabling near-optimal dynamic regret bounds in non-stationary environments while reducing adaptation lag from hundreds of rounds to a few, with supporting experiments on three synthetic and eleven real-world datasets.
Significance. If the post-hoc penalty can be realized in a fully causal manner while preserving the O(log T) bound under standard online convex optimization assumptions, the work would meaningfully advance tuning-free online model selection by relaxing the usual restriction to O(1) learning rates without sacrificing worst-case guarantees.
major comments (1)
- [Abstract] Abstract: the central claim that the post-hoc penalty mechanism 'dynamically monitors unstable updates and excludes learning rates incurring excessive regret' while keeping total penalty O(log T) is load-bearing for the entire contribution, yet the description provides no indication of how the exclusion decision at round t is computed using only information available up to t (as opposed to hindsight comparison against the optimal comparator sequence). If the analysis implicitly relies on future losses or extra regularity conditions, the claimed bound fails to hold in the standard online setting and the adaptation-lag reduction cannot be guaranteed.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the importance of clarifying the causal nature of the post-hoc penalty. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the post-hoc penalty mechanism 'dynamically monitors unstable updates and excludes learning rates incurring excessive regret' while keeping total penalty O(log T) is load-bearing for the entire contribution, yet the description provides no indication of how the exclusion decision at round t is computed using only information available up to t (as opposed to hindsight comparison against the optimal comparator sequence). If the analysis implicitly relies on future losses or extra regularity conditions, the claimed bound fails to hold in the standard online setting and the adaptation-lag reduction cannot be guaranteed.
Authors: The full manuscript defines the exclusion decision at round t using only quantities available by time t: the loss observed at t, the current iterate, and a running estimate of local stability derived from prior rounds. No future losses or knowledge of the optimal comparator sequence enters the decision rule. The O(log T) penalty bound is proved under standard online convex optimization assumptions without additional regularity conditions. We agree, however, that the abstract is too terse on this point and does not indicate the information used for the decision. We will revise the abstract to state explicitly that the exclusion is computed from information available at t. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces a novel post-hoc penalty mechanism for online mirror descent and separately claims to derive that its cumulative penalty is O(log T). No equation or step in the provided abstract reduces the bound to a definitional tautology, a fitted parameter renamed as prediction, or a load-bearing self-citation. The central result (large learning rates up to Θ(T) with near-optimal dynamic regret) rests on the new mechanism rather than importing uniqueness or ansatzes from prior author work. Standard online convex optimization assumptions are invoked without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in online convex optimization such as convex loss functions and bounded gradients.
invented entities (1)
-
Post-hoc penalty mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Koolen, Alexey Chernov, and Vladimir Vovk
Dmitry Adamskiy, Wouter M. Koolen, Alexey Chernov, and Vladimir Vovk. 2012. A Closer Look at Adaptive Regret. InAlgorithmic Learning Theory(Lyon, France). Springer, Berlin, Heidelberg, 290–304. doi:10.1007/978-3-642-34106-9_24
-
[2]
Dheeraj Baby and Yu-Xiang Wang. 2023. Second Order Path Variationals in Non- Stationary Online Learning. InProceedings of The 26th International Conference on Artificial Intelligence and Statistics(Valencia, Spain)(Proceedings of Machine Learning Research, Vol. 206). PMLR, 9024–9075
2023
-
[3]
Jock A. Blackard and Denis J. Dean. 1999. Comparative Accuracies of Artificial Neural Networks and Discriminant Analysis in Predicting Forest Cover Types from Cartographic Variables.Computers and Electronics in Agriculture24, 3 (1999), 131–151. doi:10.1016/S0168-1699(99)00046-0
-
[4]
Dariusz Brzezinski and Jerzy Stefanowski. 2014. Reacting to Different Types of Concept Drift: The Accuracy Updated Ensemble Algorithm.IEEE Transactions on Neural Networks and Learning Systems25, 1 (2014), 81–94. doi:10.1109/TNNLS. 2013.2251352
-
[5]
2006.Prediction, Learning, and Games
Nicolò Cesa-Bianchi and Gábor Lugosi. 2006.Prediction, Learning, and Games. Cambridge University Press, Cambridge, UK. doi:10.1017/CBO9780511546921
-
[6]
Liyu Chen, Haipeng Luo, and Chen-Yu Wei. 2021. Impossible Tuning Made Possible: A New Expert Algorithm and Its Applications. InProceedings of Thirty Fourth Conference on Learning Theory(Boulder, CO, USA)(Proceedings of Machine Learning Research, Vol. 134). PMLR, 1216–1259
2021
-
[7]
Ashok Cutkosky. 2019. Artificial Constraints and Hints for Unbounded Online Learning. InProceedings of the Thirty-Second Conference on Learning Theory (Phoenix, AZ, USA)(Proceedings of Machine Learning Research, Vol. 99). PMLR, 874–894
2019
-
[8]
Grünwald, and Wouter M
Steven de Rooij, Tim van Erven, Peter D. Grünwald, and Wouter M. Koolen. 2014. Follow the Leader If You Can, Hedge If You Must.Journal of Machine Learning Research15, 37 (2014), 1281–1316
2014
-
[9]
Magdalena Deckert. 2011. Batch Weighted Ensemble for Mining Data Streams with Concept Drift. InFoundations of Intelligent Systems(Warsaw, Poland). Springer, Berlin, Heidelberg, 290–299. doi:10.1007/978-3-642-21916-0_32
-
[10]
Gregory Ditzler and Robi Polikar. 2013. Incremental Learning of Concept Drift from Streaming Imbalanced Data.IEEE Transactions on Knowledge and Data Engineering25, 10 (2013), 2283–2301. doi:10.1109/TKDE.2012.136
-
[11]
Gregory Ditzler, Manuel Roveri, Cesare Alippi, and Robi Polikar. 2015. Learning in Nonstationary Environments: A Survey.IEEE Computational Intelligence Magazine10, 4 (2015), 12–25. doi:10.1109/MCI.2015.2471196
-
[12]
Pedro Domingos and Geoff Hulten. 2000. Mining High-Speed Data Streams. InProceedings of the Sixth ACM SIGKDD International Conference on Knowl- edge Discovery and Data Mining(Boston, MA, USA). Association for Computing Machinery, New York, NY, USA, 71–80. doi:10.1145/347090.347107
-
[13]
Ryan Elwell and Robi Polikar. 2011. Incremental Learning of Concept Drift in Nonstationary Environments.IEEE Transactions on Neural Networks22, 10 (2011), 1517–1531. doi:10.1109/TNN.2011.2160459
-
[14]
Hadi Fanaee-T and João Gama. 2014. Event Labeling Combining Ensemble Detectors and Background Knowledge.Progress in Artificial Intelligence2, 2-3 (2014), 113–127. doi:10.1007/s13748-013-0040-3
-
[15]
Pierre Gaillard, Gilles Stoltz, and Tim van Erven. 2014. A Second-Order Bound with Excess Losses. InProceedings of The 27th Conference on Learning Theory (Barcelona, Spain)(Proceedings of Machine Learning Research, Vol. 35). PMLR, 176–196
2014
-
[16]
2010.Knowledge Discovery from Data Streams
João Gama. 2010.Knowledge Discovery from Data Streams. CRC Press, Boca Raton, FL, USA. doi:10.1201/EBK1439826119
-
[17]
João Gama, Indr˙e Žliobait ˙e, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. A Survey on Concept Drift Adaptation.Comput. Surveys46, 4, Article 44 (2014), 37 pages. doi:10.1145/2523813
-
[18]
Heitor Murilo Gomes, Albert Bifet, Jesse Read, Jean Paul Barddal, Fabrício Enem- breck, Bernhard Pfahringer, Geoff Holmes, and Talel Abdessalem. 2017. Adaptive Random Forests for Evolving Data Stream Classification.Machine Learning106, 9 (2017), 1469–1495. doi:10.1007/s10994-017-5642-8
-
[19]
Heitor Murilo Gomes, Jesse Read, Albert Bifet, Jean Paul Barddal, and João Gama
-
[20]
Machine Learning for Streaming Data: State of the Art, Challenges, and Opportunities.SIGKDD Explorations Newsletter21, 2 (2019), 6–22. doi:10.1145/ 3373464.3373470
-
[21]
1999.SPLICE-2 Comparative Evaluation: Electricity Pricing
Michael Harries. 1999.SPLICE-2 Comparative Evaluation: Electricity Pricing. Technical Report. University of New South Wales, School of Computer Science and Engineering, Sydney, Australia
1999
-
[22]
Seshadhri
Elad Hazan and C. Seshadhri. 2007.Adaptive Algorithms for Online Decision Problems. Technical Report TR07-088. Electronic Colloquium on Computational Complexity (ECCC)
2007
-
[23]
Mark Herbster and Manfred K. Warmuth. 2001. Tracking the Best Linear Predictor. Journal of Machine Learning Research1 (2001), 281–309
2001
-
[24]
Elena Ikonomovska, João Gama, and Sašo Džeroski. 2011. Learning Model Trees from Evolving Data Streams.Data Mining and Knowledge Discovery23, 1 (2011), 128–168. doi:10.1007/s10618-010-0201-y
-
[25]
Andrew Jacobsen and Francesco Orabona. 2024. An Equivalence Between Static and Dynamic Regret Minimization. InAdvances in Neural Information Processing Systems(Vancouver, BC, Canada), Vol. 37. Curran Associates, Inc., Red Hook, NY, USA, 98835–98870. doi:10.52202/079017-3137
-
[26]
Kwang-Sung Jun, Francesco Orabona, Stephen Wright, and Rebecca Willett. 2017. Online Learning for Changing Environments using Coin Betting.Electronic Journal of Statistics11, 2 (2017), 5282–5310. doi:10.1214/17-EJS1379SI
-
[27]
Jeremy Zico Kolter and Marcus A. Maloof. 2005. Using Additive Expert Ensembles to Cope with Concept Drift. InProceedings of the 22nd International Conference on Machine Learning(Bonn, Germany). Association for Computing Machinery, New York, NY, USA, 449–456. doi:10.1145/1102351.1102408
-
[28]
Jeremy Zico Kolter and Marcus A. Maloof. 2007. Dynamic Weighted Majority: An Ensemble Method for Drifting Concepts.Journal of Machine Learning Research8 (2007), 2755–2790
2007
-
[29]
Koolen, Dmitry Adamskiy, and Manfred K
Wouter M. Koolen, Dmitry Adamskiy, and Manfred K. Warmuth. 2012. Putting Bayes to Sleep. InAdvances in Neural Information Processing Systems(Lake Tahoe, NV, USA), Vol. 25. Curran Associates, Inc., Red Hook, NY, USA, 135–143
2012
-
[30]
Koolen and Tim van Erven
Wouter M. Koolen and Tim van Erven. 2015. Second-order Quantile Methods for Experts and Combinatorial Games. InProceedings of The 28th Conference on Learning Theory(Paris, France)(Proceedings of Machine Learning Research, Vol. 40). PMLR, 1155–1175
2015
-
[31]
Minku, João Gama, Jerzy Stefanowski, and Michał Woźniak
Bartosz Krawczyk, Leandro L. Minku, João Gama, Jerzy Stefanowski, and Michał Woźniak. 2017. Ensemble Learning for Data Stream Analysis: A Survey.Informa- tion Fusion37 (2017), 132–156. doi:10.1016/j.inffus.2017.02.004
-
[32]
David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient Episodic Memory for Continual Learning. InAdvances in Neural Information Processing Systems (Long Beach, CA, USA), Vol. 30. Curran Associates, Inc., Red Hook, NY, USA, 6467–6476
2017
-
[33]
Viktor Losing, Barbara Hammer, and Heiko Wersing. 2016. KNN Classifier with Self Adjusting Memory for Heterogeneous Concept Drift. In2016 IEEE 16th International Conference on Data Mining (ICDM)(Barcelona, Spain). IEEE, Piscataway, NJ, USA, 291–300. doi:10.1109/ICDM.2016.0040
-
[34]
Yang Lu, Yiu-ming Cheung, and Yuan Yan Tang. 2017. Dynamic Weighted Majority for Incremental Learning of Imbalanced Data Streams with Concept Drift. InProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17(Melbourne, Australia). International Joint Conferences on Artificial Intelligence Organization, 2393–2399....
-
[35]
Schapire
Haipeng Luo and Robert E. Schapire. 2015. Achieving All with No Parameters: AdaNormalHedge. InProceedings of The 28th Conference on Learning Theory(Paris, France)(Proceedings of Machine Learning Research, Vol. 40). PMLR, 1286–1304. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Kei Takemura, Ryuta Matsuno, and Keita Sakuma
2015
-
[36]
Yasuko Matsubara and Yasushi Sakurai. 2025. MicroAdapt: Self-Evolutionary Dynamic Modeling Algorithms for Time-evolving Data Streams. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (Toronto, ON, Canada). Association for Computing Machinery, New York, NY, USA, 2114–2125. doi:10.1145/3711896.3737048
-
[37]
2001.Online Ensemble Learning
Nikunj Chandrakant Oza. 2001.Online Ensemble Learning. Ph. D. Dissertation. University of California, Berkeley, Berkeley, CA, USA
2001
-
[38]
William Nick Street and YongSeog Kim. 2001. A Streaming Ensemble Algorithm (SEA) for Large-Scale Classification. InProceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(San Francisco, CA, USA). Association for Computing Machinery, New York, NY, USA, 377–382. doi:10.1145/502512.502568
-
[39]
Haixun Wang, Wei Fan, Philip S. Yu, and Jiawei Han. 2003. Mining Concept- Drifting Data Streams using Ensemble Classifiers. InProceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Washington, DC, USA). Association for Computing Machinery, New York, NY, USA, 226–235. doi:10.1145/956750.956778
-
[40]
Chen-Yu Wei, Yi-Te Hong, and Chi-Jen Lu. 2016. Tracking the Best Expert in Non- stationary Stochastic Environments. InAdvances in Neural Information Processing Systems(Barcelona, Spain), Vol. 29. Curran Associates, Inc., Red Hook, NY, USA, 3972–3980
2016
-
[41]
Huaxiu Yao, Caroline Choi, Bochuan Cao, Yoonho Lee, Pang Wei Koh, and Chelsea Finn. 2022. Wild-Time: A Benchmark of in-the-Wild Distribution Shift over Time. InAdvances in Neural Information Processing Systems(New Orleans, LA, USA), Vol. 35. Curran Associates, Inc., Red Hook, NY, USA, 10309–10324
2022
-
[42]
Peng Zhao, Le-Wen Cai, and Zhi-Hua Zhou. 2020. Handling Concept Drift via Model Reuse.Machine Learning109, 3 (2020), 533–568. doi:10.1007/s10994-019- 05835-w
-
[43]
2010.Stream Data Mining Repository
Xingquan Zhu. 2010.Stream Data Mining Repository. Retrieved February 7, 2026 from http://www.cse.fau.edu/~xqzhu/stream.html A Generalization for Real-World Environments In Section 2, we defined the Tracking the Best Expert problem under the assumptions of a fixed number of experts and bounded losses (ℓ𝑡 ∈ [ 0, 1]) for theoretical clarity. However, real-wo...
2010
-
[44]
The initial potential 𝑊(𝑤 ′ 1)= Í 𝑖,𝑗 𝑤 ′ 1 (𝑖,𝑗) 𝜂(𝑗) is 𝑂( 1) by the initializa- tion of𝑤 ′ 1 (as discussed in our proof of Theorem 2)
−1·𝑊(𝑤 ′ 𝑇+1 ) ≤𝑊(𝑤 ′ 1). The initial potential 𝑊(𝑤 ′ 1)= Í 𝑖,𝑗 𝑤 ′ 1 (𝑖,𝑗) 𝜂(𝑗) is 𝑂( 1) by the initializa- tion of𝑤 ′ 1 (as discussed in our proof of Theorem 2). Next, we analyze the sum of logarithmic terms, denoted by Slog: Slog = 1 𝜂(𝑗 ∗) 𝐾∑︁ 𝑖=1 𝑁𝑖∑︁ 𝑘=1 𝑎𝑘,𝑖 log 𝑤 ′ 𝑒𝑘,𝑖 +1 (𝑖, 𝑗 ∗) 𝑤 ′𝑠𝑘,𝑖 (𝑖, 𝑗 ∗) . Similarly rearranging the sum by time𝑡, the coe...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.