Efficient Agentic Reinforcement Learning with On-Policy Intrinsic Knowledge Boundary Enhancement
Pith reviewed 2026-06-29 17:51 UTC · model grok-4.3
The pith
AKBE uses dual-path rollouts in agentic RL to identify each question's intrinsic knowledge boundary and reduce unnecessary tool calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
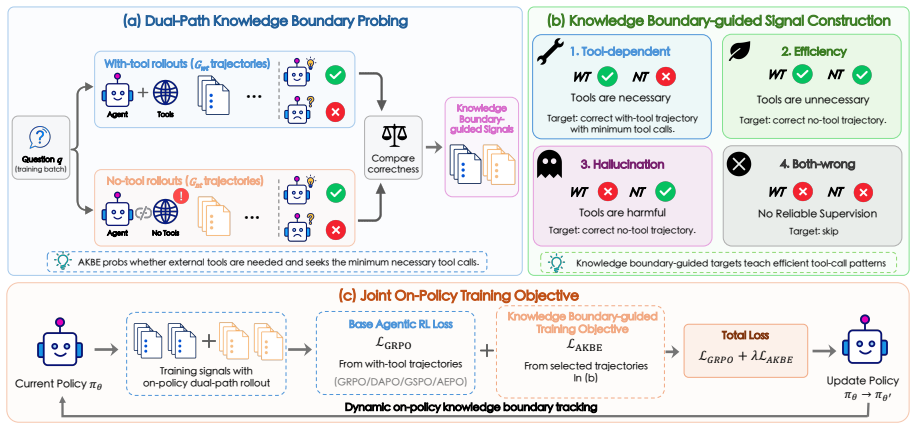
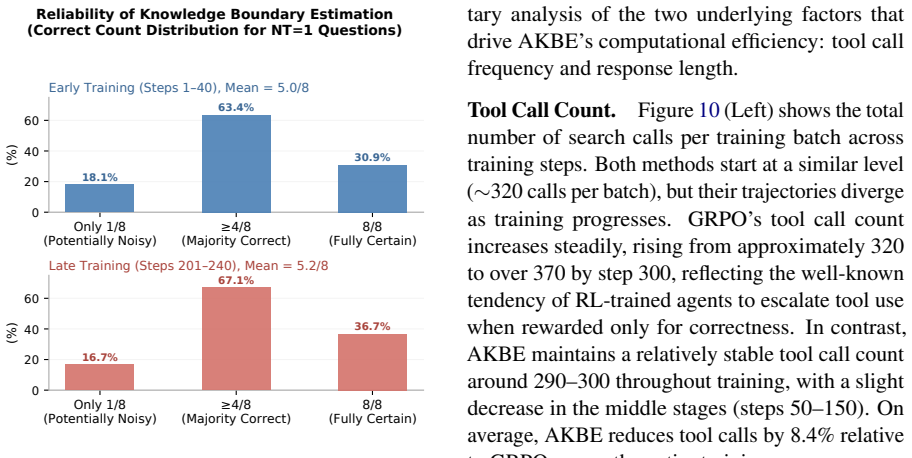
AKBE defines the per-instance knowledge boundary as the determination of tool necessity and minimum calls needed, obtained by comparing correctness outcomes across dual-path rollouts. Trajectories are categorized from these comparisons and used to construct supervisory signals that guide efficient tool-use patterns, which are then inserted directly into the agentic RL training loop.
What carries the argument
Dual-path (with-tool and no-tool) rollouts whose correctness comparison categorizes instances and supplies per-question supervisory signals to the on-policy RL loop.
If this is right
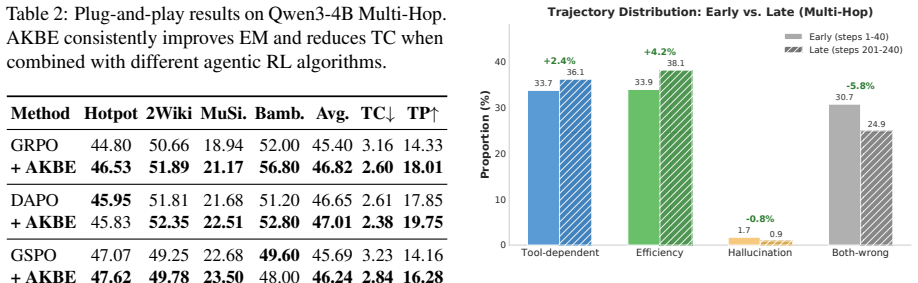
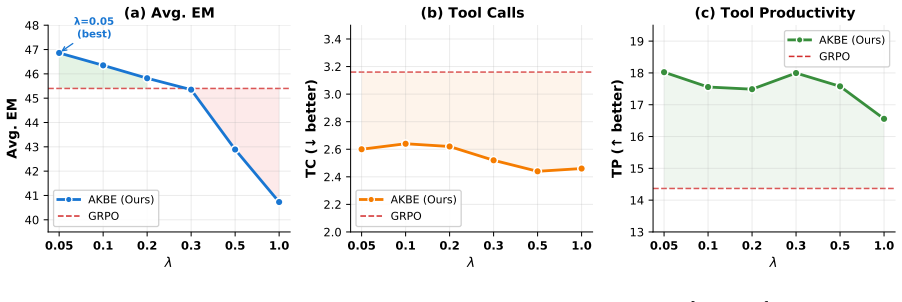
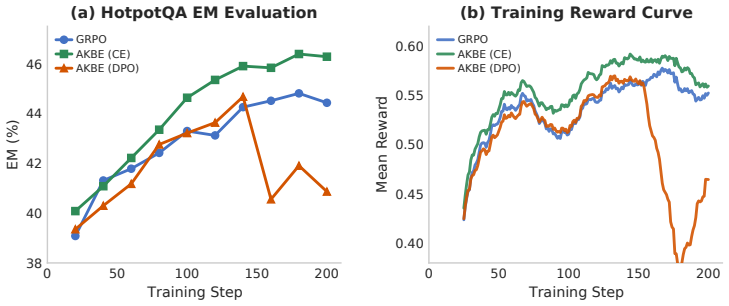
- Average task accuracy rises by 1.85 points over baseline agentic RL.
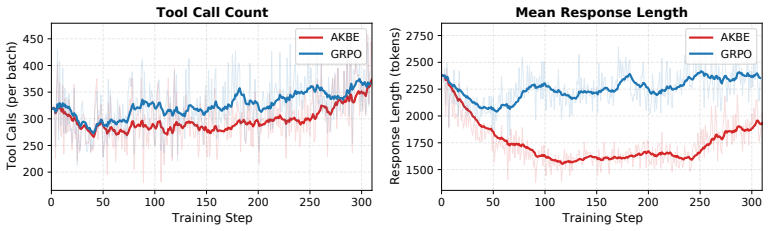
- Tool calls fall by 18 percent, producing 25 percent higher tool productivity.
- No accuracy-efficiency trade-off appears across the tested benchmarks.
- The method integrates as a plug-and-play addition to multiple RL algorithms.
Where Pith is reading between the lines
- The same dual-path labeling could be tested on agent tasks outside question answering, such as web navigation or code execution.
- Stabilizing the knowledge-boundary labels over many training epochs might further reduce variance in tool-use behavior.
- If the boundary signals prove stable, they could serve as a lightweight calibration signal for deployed agents facing usage-cost constraints.
Load-bearing premise
That correctness differences between the with-tool and no-tool rollouts for each instance reliably mark the true intrinsic knowledge boundary and remain valid signals inside the continuing training loop.
What would settle it
A controlled experiment on the same seven QA benchmarks in which AKBE produces either lower average accuracy or no reduction in tool calls relative to standard agentic RL would falsify the reported gains.
Figures



read the original abstract
Agentic reinforcement learning (RL) has proven effective for training LLM-based agents with external tool-use capabilities. However, we identify that agentic RL training induces increasing redundant tool calls and blurs the model's intrinsic knowledge boundary, where the model fails to distinguish when tools are needed versus when parametric knowledge suffices. Existing solutions based on reward shaping create coarse-grained optimization targets that tend to incentivize indiscriminate tool-call suppression, leading to reward hacking. In this paper, we propose AKBE (Agentic Knowledge Boundary Enhancement), an on-policy method that dynamically probes the model's intrinsic knowledge boundary through dual-path (with-tool and no-tool) rollouts during training. We define the knowledge boundary as the per-instance determination of whether tools are required and the minimum tool calls necessary. By comparing correctness across paths, AKBE categorizes trajectories and constructs targeted supervisory signals that guide efficient tool-use patterns for each question. These signals are integrated seamlessly into the agentic RL training loop. Experiments on seven QA benchmarks demonstrate that AKBE improves task accuracy by +1.85 on average and reduces tool calls by 18% over standard agentic RL, yielding 25% higher tool productivity without any accuracy-efficiency trade-off. Further analysis suggests its plug-and-play compatibility across different RL algorithms and the mechanism of each signal category. Our code is available at https://github.com/CuSO4-Chen/AKBE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AKBE, an on-policy method for agentic RL that dynamically probes the model's intrinsic knowledge boundary via dual-path (with-tool and no-tool) rollouts per instance. Correctness comparisons define per-question supervisory signals for whether tools are required and the minimum calls needed; these signals are inserted into the ongoing RL loop to discourage redundant tool use. Experiments on seven QA benchmarks report +1.85 average accuracy, 18% fewer tool calls, and 25% higher tool productivity versus standard agentic RL, with no accuracy-efficiency trade-off and plug-and-play compatibility across RL algorithms.
Significance. If the results and underlying assumptions hold, the work offers a concrete mechanism to mitigate redundant tool calls in agentic RL without sacrificing task performance. The on-policy integration of boundary-derived signals and the public code release are strengths that could support follow-up work on efficient agent training.
major comments (3)
- [Abstract] Abstract: the reported gains (+1.85 accuracy, 18% tool-call reduction) supply no statistical significance, standard deviations, baseline implementation details, or data-split information, preventing assessment of whether the improvements are reliable or reproducible.
- [Method] Method (dual-path construction): the supervisory signals rest on the assumption that a single with-tool rollout realizes the minimal necessary calls and that correctness differences isolate intrinsic parametric knowledge rather than rollout variance or partial tool success; no multiple-rollout analysis or variance quantification is provided to support this load-bearing step.
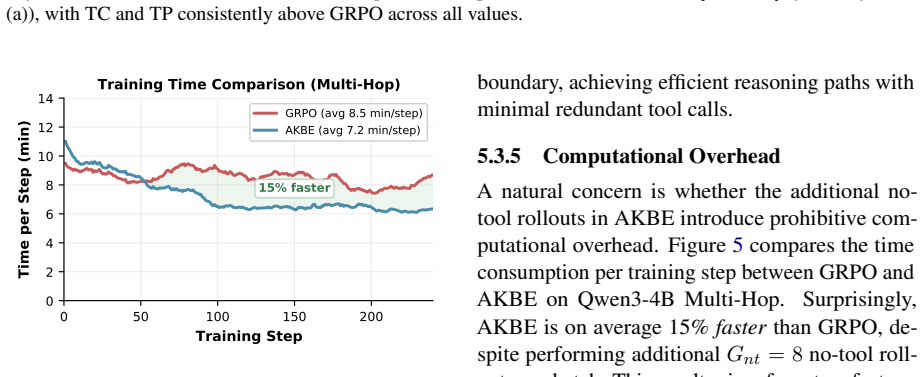
- [Experiments] Experiments / §4: no ablation re-probes knowledge-boundary labels mid-training or quantifies label stability under policy updates, despite the on-policy loop making earlier labels potentially stale; this directly affects whether the inserted signals remain valid targets.
minor comments (2)
- [Abstract] Abstract: the metric 'tool productivity' is introduced without an explicit definition or formula.
- [Experiments] The manuscript would benefit from a table listing per-benchmark results (accuracy and tool calls) rather than only averages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below and will revise the manuscript to incorporate clarifications and additional analyses where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported gains (+1.85 accuracy, 18% tool-call reduction) supply no statistical significance, standard deviations, baseline implementation details, or data-split information, preventing assessment of whether the improvements are reliable or reproducible.
Authors: We agree that the abstract would benefit from greater statistical rigor and self-containment. In the revision we will add standard deviations from multiple random seeds, report statistical significance tests for the key metrics, and briefly note data splits and baseline implementation details directly in the abstract while retaining full details in §4. revision: yes
-
Referee: [Method] Method (dual-path construction): the supervisory signals rest on the assumption that a single with-tool rollout realizes the minimal necessary calls and that correctness differences isolate intrinsic parametric knowledge rather than rollout variance or partial tool success; no multiple-rollout analysis or variance quantification is provided to support this load-bearing step.
Authors: The single-rollout design per path is chosen to control compute cost during on-policy training. While we acknowledge that rollout variance could affect the boundary estimate, the correctness comparison is used only to generate coarse supervisory categories that are then refined by the ongoing RL objective. To strengthen this claim we will add a limited multi-rollout variance study on a data subset in the supplementary material. revision: partial
-
Referee: [Experiments] Experiments / §4: no ablation re-probes knowledge-boundary labels mid-training or quantifies label stability under policy updates, despite the on-policy loop making earlier labels potentially stale; this directly affects whether the inserted signals remain valid targets.
Authors: This is a legitimate concern about potential label staleness. We will add an ablation that re-probes boundary labels at multiple training checkpoints, measures label-change frequency, and reports downstream performance impact, placing the results in §4 or the appendix. revision: yes
Circularity Check
No circularity; experimental gains measured independently of boundary definitions
full rationale
The paper defines the knowledge boundary via dual-path rollouts and uses the resulting labels as supervisory signals inside the RL loop, then reports accuracy and tool-call reductions on seven external QA benchmarks. No equations, fitted parameters, or self-citations are shown that reduce the reported deltas to a re-labeling or re-use of the same inputs by construction. The central claims rest on empirical comparison against standard agentic RL rather than on any definitional equivalence or imported uniqueness result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dual-path (with-tool and no-tool) rollouts can accurately determine whether tools are required and the minimum number of calls needed for each instance.
Reference graph
Works this paper leans on
-
[1]
A 2 tgpo: Agentic turn-group policy optimiza- tion with adaptive turn-level clipping.arXiv preprint arXiv:2605.06200. Guanting Dong, Licheng Bao, Zhongyuan Wang, Kangzhi Zhao, Xiaoxi Li, Jiajie Jin, Jinghan Yang, Hangyu Mao, Fuzheng Zhang, Kun Gai, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Agentic entropy-balanced policy optimization
Agentic entropy-balanced policy optimization. Preprint, arXiv:2510.14545. Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An
-
[3]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi- hop QA dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th Inter- national Conference on Computational Linguistics, pages 6609–6625, Barcelona...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
Over-searching in search-augmented large lan- guage models.arXiv preprint arXiv:2601.05503. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen3 technical repor...
-
[5]
is a large-scale Wikipedia-derived bench- mark with supporting-fact annotations, serving as a widely used testbed for multi-hop question answer- ing.2WikiMultiHopQA(Ho et al., 2020) com- bines Wikipedia passages with Wikidata triples, producing questions that require explicit multi-hop entity reasoning.MuSiQue(Trivedi et al., 2022) contains approximately ...
2020
-
[6]
offers a small but adversarial set of compo- sitional queries, serving as a robustness probe for agentic RL policies. Single-Hop QA.This category verifies perfor- mance on single-step retrieval tasks.Natural Questions (NQ)(Kwiatkowski et al., 2019) aggre- gates real user queries answered from Wikipedia and serves as a standard benchmark for retrieval- aug...
2019
-
[7]
at least one correct
features substantial lexical and syntactic di- vergence between questions and supporting ev- idence, testing robustness to surface variation. PopQA(Mallen et al., 2022) is an entity-centric benchmark designed to separate the contribution of external retrieval from parametric memoriza- tion, making it a natural diagnostic for whether the policy genuinely l...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.