Tournament-GRPO: Group-Wise Tournament Rewards for Reinforcement Learning in Open-Ended Long-Form Generation
Pith reviewed 2026-06-29 18:51 UTC · model grok-4.3
The pith
Tournament-GRPO converts rubric-based LLM judgments into relative rewards through multi-round group tournaments to strengthen RL training signals for open-ended long-form generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
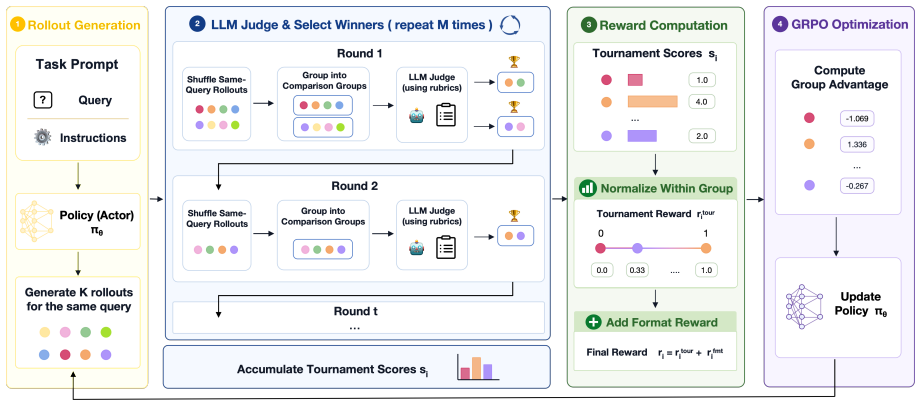
Tournament-GRPO converts rubric-guided LLM judgments into relative rewards through repeated multi-round tournaments among same-query rollouts, compares candidates within groups, accumulates tournament outcomes, and normalizes them into group-wise rewards for GRPO training.
What carries the argument
Group-wise tournament rewards that accumulate outcomes from multi-round comparisons within same-query response groups and normalize them into training signals.
If this is right
- Relative tournament rewards provide stronger discrimination among responses generated for identical queries than absolute pointwise scores.
- The method reduces saturation during policy optimization compared with direct use of absolute LLM judgments.
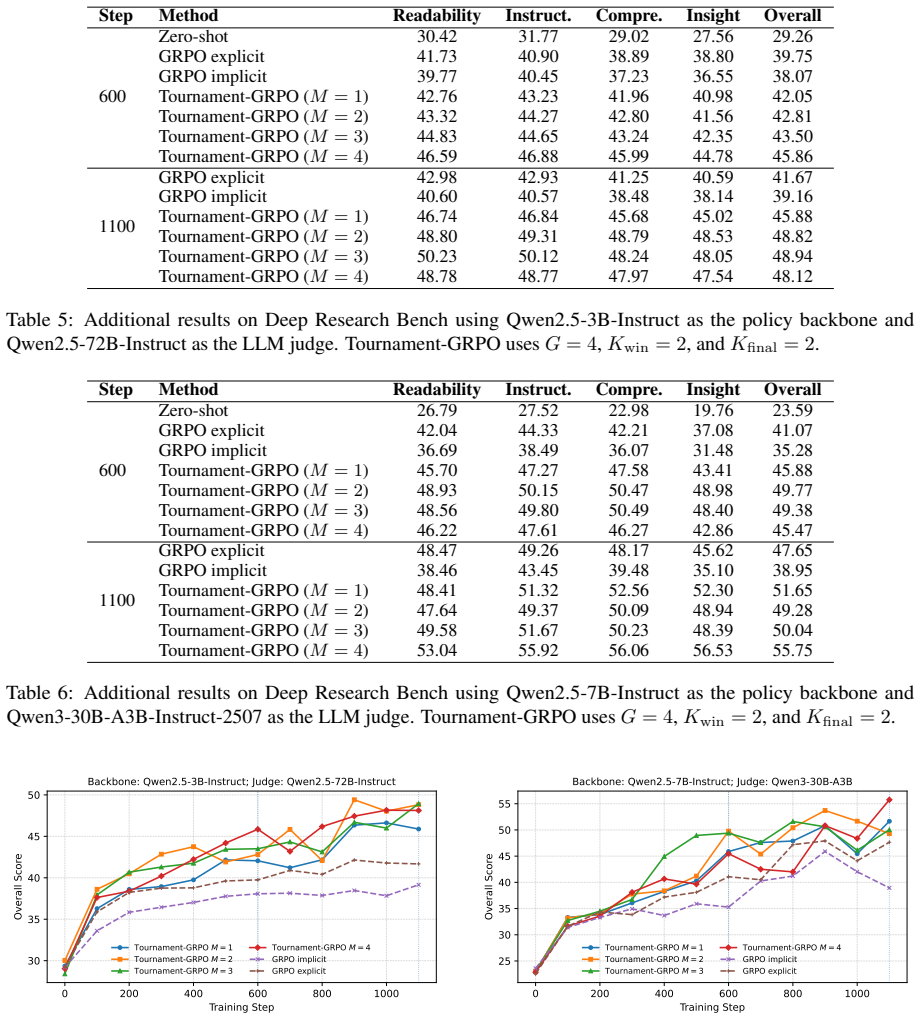
- Tournament-GRPO achieves a 4.52-point overall-score improvement over the strongest reward-design baseline on Deep Research Bench.
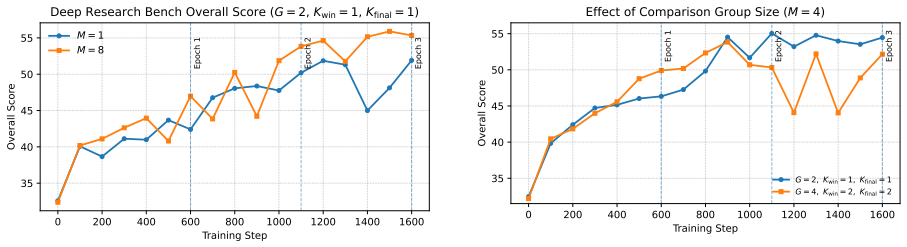
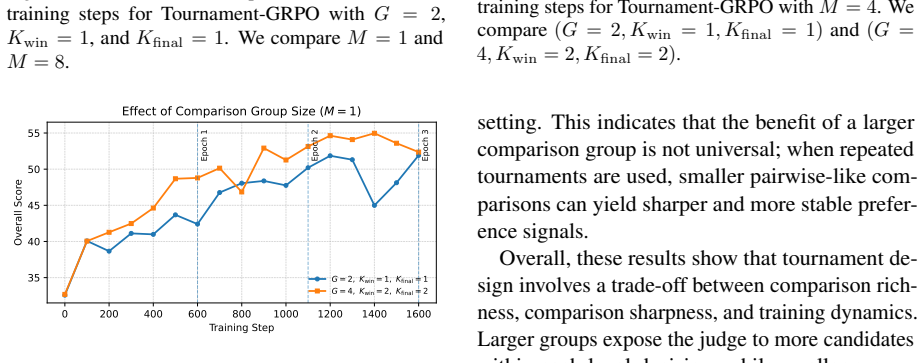
- Tournament design choices directly affect training dynamics and the effectiveness-efficiency balance.
- Group-wise relative rewards remain effective when reference answers and automatic metrics are unavailable.
Where Pith is reading between the lines
- The same tournament normalization could be applied to other subjective generation domains where absolute scoring is unreliable.
- Varying group size or number of rounds might allow tuning the reward signal for different output lengths or task complexities.
- The accumulated win counts could be combined with existing reward models without requiring full recalibration of absolute scales.
Load-bearing premise
Turning absolute rubric scores into relative outcomes via tournament structure produces a more calibrated and discriminative signal without introducing new saturation or bias effects that cancel the gains.
What would settle it
A controlled replication on Deep Research Bench in which pointwise rubric scoring achieves equal or higher final scores than the tournament method under matched training budgets and model settings.
Figures

read the original abstract
Reinforcement learning in open-ended long-form generation is challenging because reliable reference answers and automatic metrics are often unavailable. Existing rubric-based methods typically rely on pointwise LLM-as-a-judge scoring, but absolute scores are difficult to calibrate across complex responses, may provide weak discrimination among same-query rollouts, and can become saturated during optimization. We propose Tournament-GRPO, a group-wise reward framework that converts rubric-guided LLM judgments into relative rewards through repeated multi-round tournaments among same-query rollouts. Tournament-GRPO compares candidates within groups, accumulates tournament outcomes, and normalizes them into group-wise rewards for GRPO training. Experiments on Deep Research Bench show that Tournament-GRPO consistently outperforms existing reward-design baselines, achieving a 4.52-point overall-score improvement over the strongest baseline. Further analyses show that tournament rewards provide a favorable effectiveness--efficiency trade-off and that tournament design affects training dynamics. These results suggest that rubric-guided tournament comparison provides an effective reward signal for reinforcement learning in open-ended long-form generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tournament-GRPO, a group-wise reward framework for reinforcement learning in open-ended long-form generation. It converts rubric-guided LLM judgments into relative rewards through repeated multi-round tournaments among same-query rollouts, accumulates outcomes, and normalizes them into group-wise rewards for GRPO training. This addresses issues with pointwise LLM-as-a-judge scoring such as poor calibration, weak discrimination, and saturation. Experiments on Deep Research Bench report a 4.52-point overall-score improvement over the strongest baseline, along with analyses of effectiveness-efficiency trade-offs and effects of tournament design on training dynamics.
Significance. If the reported improvement holds under rigorous controls, the work would be significant for reward design in RL settings lacking references or automatic metrics, such as research-oriented generation. It extends GRPO with a relative tournament mechanism that may yield more discriminative signals. The empirical evaluation on Deep Research Bench and the focus on training dynamics are positive contributions, though the strength depends on verification of the experimental protocol.
major comments (2)
- [Experiments] Experiments section: the central claim of a 4.52-point overall-score improvement over the strongest baseline is load-bearing, yet the provided description lacks any account of the number of runs, statistical significance, variance across seeds, or controls for LLM judge inconsistencies and prompt sensitivity. This prevents assessment of whether the data support the outperformance conclusion.
- [Method] Method section (tournament reward construction): the assumption that multi-round tournaments among same-query rollouts produce a more calibrated signal without introducing saturation or structural bias from the tournament graph itself is load-bearing for the method's advantage over pointwise scoring, but no formal analysis or ablation of tournament parameters (e.g., number of rounds, pairing strategy, or normalization) is referenced to substantiate this.
minor comments (2)
- The abstract would be clearer if it named the specific reward-design baselines used for comparison.
- Notation for group-wise normalization and reward accumulation should be introduced with an equation or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental reporting and methodological assumptions. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of a 4.52-point overall-score improvement over the strongest baseline is load-bearing, yet the provided description lacks any account of the number of runs, statistical significance, variance across seeds, or controls for LLM judge inconsistencies and prompt sensitivity. This prevents assessment of whether the data support the outperformance conclusion.
Authors: We agree that the absence of reported variance, multiple runs, and statistical tests limits the strength of the central claim. In the revised manuscript we will add results from at least three independent training runs with different seeds, report mean and standard deviation of the overall score, and include paired statistical significance tests against the strongest baseline. We will also document our protocol for LLM-judge stability, including the use of fixed prompts and the number of judgments per comparison. revision: yes
-
Referee: [Method] Method section (tournament reward construction): the assumption that multi-round tournaments among same-query rollouts produce a more calibrated signal without introducing saturation or structural bias from the tournament graph itself is load-bearing for the method's advantage over pointwise scoring, but no formal analysis or ablation of tournament parameters (e.g., number of rounds, pairing strategy, or normalization) is referenced to substantiate this.
Authors: The manuscript already contains empirical analyses demonstrating that tournament design influences training dynamics and yields a favorable effectiveness-efficiency trade-off. Nevertheless, we acknowledge that a more systematic examination of potential graph-induced biases and saturation is warranted. In revision we will add explicit ablations varying the number of rounds and pairing strategies, include a short discussion of normalization choices, and provide a qualitative argument for why the relative tournament format mitigates saturation relative to pointwise scoring. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract describes Tournament-GRPO as a group-wise reward framework that converts rubric-guided LLM judgments into relative rewards via multi-round tournaments among same-query rollouts, then normalizes them for GRPO training, with reported empirical gains over baselines. No equations, fitted parameters, self-citations, or derivation steps are presented that reduce the claimed results or rewards to inputs by construction, self-definition, or renaming. The method extends existing GRPO and LLM-judge components without load-bearing self-referential elements or predictions that are statistically forced. This matches the reader's assessment of no circularity and indicates a self-contained proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM judgments become more reliable and less saturated when structured as relative tournament outcomes rather than absolute pointwise scores
Reference graph
Works this paper leans on
-
[1]
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
Tourrank: Utilizing large language models for documents ranking with a tournament-inspired strat- egy. InProceedings of the ACM on Web Conference 2025, pages 1638–1652. Paul F Christiano, Jan Leike, Tom Brown, Miljan Mar- tic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences.Ad- vances in neural information processing...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as rewards: Reinforcement learn- ing beyond verifiable domains.arXiv preprint arXiv:2507.17746. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783. Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, and 1 others. 2021. Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.0...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Proximal Policy Optimization Algorithms
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamis...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
query":
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. 11 A Rubric Generation Prompt Before RL training, we generate query-specific rubrics for each training query. The generated rubrics are fixed and used by both Tournament- GRPO and baselines. Rubric Generation Prompt Create a query-sp...
-
[6]
Start with exactly one non-empty <think>...</think>
-
[7]
Then perform one or more research segments
-
[8]
Each tool cycle must follow: <call_tool name="...">...</call_tool> <tool_output>...</tool_output> <think>...</think>
In each research segment, first do one or more google_search cycles, and then optionally do zero or more browse_webpage cycles. Each tool cycle must follow: <call_tool name="...">...</call_tool> <tool_output>...</tool_output> <think>...</think>
-
[9]
google_search
End with exactly one final <answer>...</answer>. Additional Constraints - Do not output any text outside these tags. - Do not skip the <think> block before the final <an- swer>. - Only output <answer> when you have enough informa- tion for a complete response. - <answer>...</answer> may appear only once, and it must be the final block in the entire respon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.