Signal-to-Noise Ratio and Sample Size Govern Representational Alignment in Neural Networks
Pith reviewed 2026-06-29 15:44 UTC · model grok-4.3
The pith
Representational alignment in neural networks increases monotonically with signal-to-noise ratio but dips to a minimum near the interpolation threshold as sample size grows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
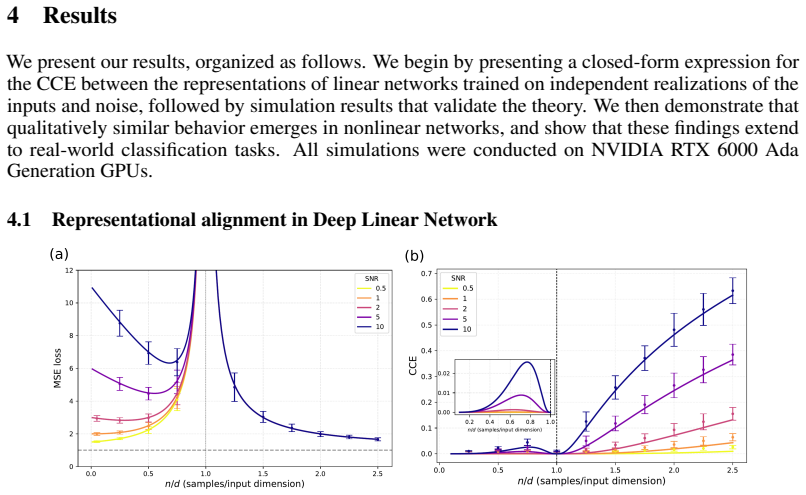
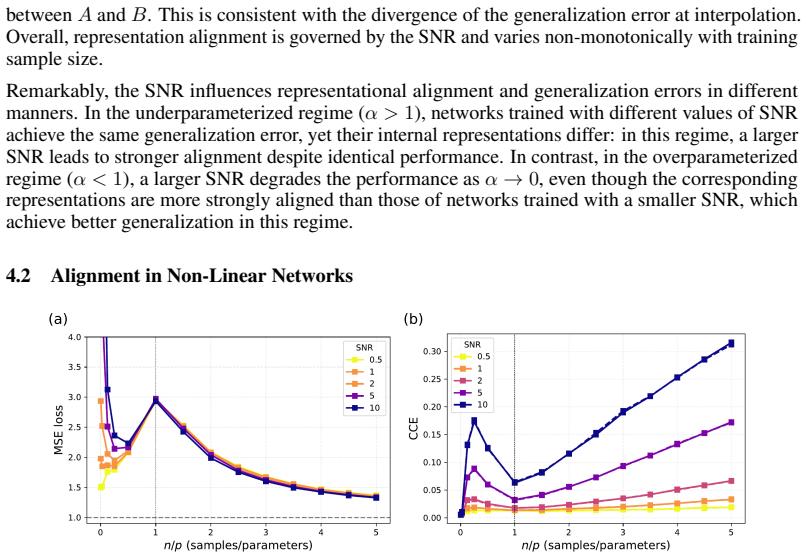
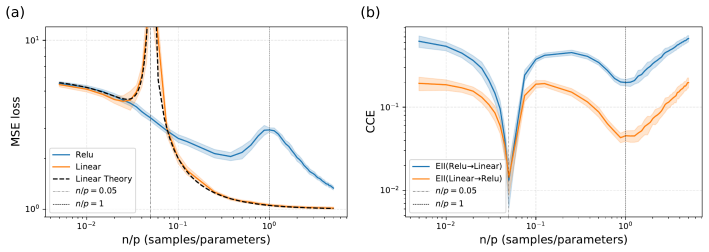
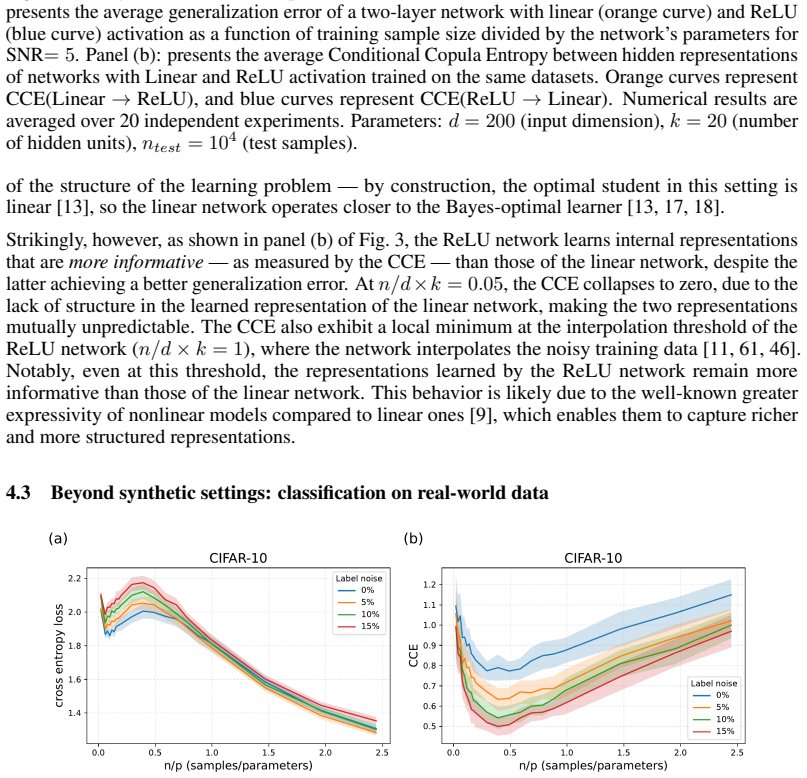
Across linear and nonlinear networks, regression and classification tasks, and both synthetic and real-world data, we consistently observe that alignment varies monotonically with SNR but non-monotonically with training sample size. In particular, the alignment is minimized near the interpolation threshold, and a stronger alignment does not necessarily correspond to better generalization error.
What carries the argument
Training ensembles on independently noise-perturbed versions of the same dataset, with analytic alignment computation in a single-hidden-layer linear network.
If this is right
- Alignment increases as the signal-to-noise ratio of the training data increases.
- Alignment reaches a minimum near the interpolation threshold when sample size is varied.
- Stronger alignment does not imply lower generalization error.
- The same dependence on SNR and sample size appears in both the linear analytic model and nonlinear networks on real data.
Where Pith is reading between the lines
- Data collection strategies could target sample sizes away from the interpolation threshold if high alignment is needed for a downstream task.
- The observed decoupling suggests alignment and generalization are controlled by distinct aspects of the training dynamics.
- Non-monotonic dependence on sample size may appear in other similarity measures between networks.
Load-bearing premise
The specific noise process and alignment metric make the linear network's behavior representative of nonlinear networks trained on real data.
What would settle it
Measure alignment in networks trained at multiple sample sizes around the interpolation threshold and find that it does not reach a minimum there.
Figures
read the original abstract
Neural networks are known to develop latent representations that are $aligned$, namely structurally similar across networks trained with different architectures, training protocols, or training datasets. We study this phenomenon in a controlled setting, where we train an ensemble of networks on regression and classification tasks using training sets perturbed by independent realizations of a noise process. We show that the signal-to-noise ratio (SNR) and the training sample size influence the alignment in qualitatively similar ways in networks trained on real-world datasets and in an extremely simple $linear$ network with a single hidden layer, for which the alignment can be estimated analytically. Across linear and nonlinear networks, regression and classification tasks, and both synthetic and real-world data, we consistently observe that alignment varies monotonically with SNR but non-monotonically with training sample size. In particular, the alignment is minimized near the interpolation threshold, and a stronger alignment does not necessarily correspond to better generalization error. These findings reveal a non-trivial dependence of alignment on data quality and quantity, decoupled from generalization performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies representational alignment across an ensemble of neural networks trained on independently noise-perturbed copies of the same dataset. It claims that alignment increases monotonically with signal-to-noise ratio (SNR) while varying non-monotonically with training sample size (minimum near the interpolation threshold), that these patterns hold for both an analytically solvable linear network and nonlinear networks on synthetic and real data, and that alignment is decoupled from generalization error. The linear-network derivation supplies an independent check on the empirical observations.
Significance. If the central claims hold, the work supplies a concrete, analytically grounded account of when and why representations align across models. The closed-form linear-network result is a clear strength, as is the consistency of the SNR and sample-size patterns across regression/classification, synthetic/real data, and linear/nonlinear regimes. The decoupling from generalization performance is a useful negative result for interpretability and ensembling research.
minor comments (4)
- §3.2, Eq. (8): the alignment metric is defined via centered kernel alignment; a one-sentence reminder of its invariance properties would help readers connect it to the linear closed form.
- Figure 4 caption: the interpolation threshold is marked but the precise definition (e.g., number of parameters vs. effective degrees of freedom) is not restated; readers must hunt in §4.1.
- §5.3: the sensitivity analysis to noise-process parameters is present but reported only for two values of σ; a brief table or inset showing the monotonicity slope across a wider grid would be helpful.
- Table 2: the R² values for the linear-network fit are given, but the number of independent noise realizations used to compute each point is not stated in the table or caption.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work and the recommendation of minor revision. The report does not list any specific major comments.
Circularity Check
No significant circularity identified
full rationale
The paper's central results are observational comparisons: alignment is shown to vary monotonically with SNR and non-monotonically with sample size (minimum near interpolation) both in an analytically solvable linear network and in nonlinear networks on real data. The linear analytic estimate is derived independently from the model equations rather than fitted to the nonlinear results, and the alignment metric is defined explicitly without reducing to a parameter fit by construction. No self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided abstract or reader summary. The derivation chain is self-contained against external benchmarks (analytic solution + controlled experiments), yielding a normal non-circular outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard mathematical definitions of representational alignment and interpolation threshold apply to both linear and nonlinear networks.
Reference graph
Works this paper leans on
-
[1]
Acevedo, S., Mascaretti, A., Rende, R., Mahaut, M., Baroni, M., and Laio, A. (2025). A quantitative analysis of semantic information in deep representations of text and images.arXiv preprint arXiv:2505.17101
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
S., Saxe, A
Advani, M. S., Saxe, A. M., and Sompolinsky, H. (2020). High-dimensional dynamics of generalization error in neural networks.Neural Networks, 132:428–446
2020
-
[3]
H., and Zoccolan, D
Ansuini, A., Laio, A., Macke, J. H., and Zoccolan, D. (2019). Intrinsic dimension of data representations in deep neural networks.Advances in Neural Information Processing Systems, 32
2019
-
[4]
Arora, S., Cohen, N., Hu, W., and Luo, Y . (2019). Implicit regularization in deep matrix factorization.Advances in neural information processing systems, 32
2019
-
[5]
Atanasov, A., Bordelon, B., and Pehlevan, C. (2022). Neural networks as kernel learners: The silent alignment effect. InInternational Conference on Learning Representations
2022
-
[6]
W., et al
Bai, Z., Silverstein, J. W., et al. (2010).Spectral analysis of large dimensional random matrices, volume 20. Springer
2010
-
[7]
and Hornik, K
Baldi, P. and Hornik, K. (1989). Neural networks and principal component analysis: Learning from examples without local minima.Neural networks, 2(1):53–58
1989
-
[8]
Bansal, Y ., Nakkiran, P., and Barak, B. (2021). Revisiting model stitching to compare neural representations.Advances in neural information processing systems, 34:225–236
2021
- [9]
-
[10]
J., Györfi, L., Van der Meulen, E
Beirlant, J., Dudewicz, E. J., Györfi, L., Van der Meulen, E. C., et al. (1997). Nonparametric entropy estimation: An overview.International Journal of Mathematical and Statistical Sciences, 6(1):17–39
1997
-
[11]
Belkin, M., Hsu, D., Ma, S., and Mandal, S. (2019). Reconciling modern machine-learning practice and the classical bias–variance trade-off.Proceedings of the National Academy of Sciences, 116(32):15849–15854
2019
-
[12]
Bengio, Y ., Courville, A., and Vincent, P. (2013). Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828
2013
-
[13]
Bishop, C. M. and Nasrabadi, N. M. (2006).Pattern recognition and machine learning, volume 4. Springer
2006
-
[14]
Braun, L., Grant, E., and Saxe, A. M. (2025). Not all solutions are created equal: An analytical dissociation of functional and representational similarity in deep linear neural networks. In Forty-second International Conference on Machine Learning
2025
-
[15]
and Berger, R
Casella, G. and Berger, R. (2024).Statistical inference. Chapman and Hall/CRC
2024
-
[16]
Cho, K., Van Merriënboer, B., Gulçehre, Ç., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y . (2014). Learning phrase representations using rnn encoder–decoder for statistical machine translation. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1724–1734. 10
2014
-
[17]
Cui, H., Krzakala, F., and Zdeborova, L. (2023). Bayes-optimal learning of deep random networks of extensive-width. InInternational Conference on Machine Learning, pages 6468–6521. PMLR
2023
-
[18]
Cui, H., Krzakala, F., and Zdeborová, L. (2025). Bayes-optimal learning of deep ran- dom networks of extensive-width.Journal of Statistical Mechanics: Theory and Experiment, 2025(1):014001
2025
-
[19]
Del Tatto, V ., Fortunato, G., Bueti, D., and Laio, A. (2024). Robust inference of causality in high- dimensional dynamical processes from the information imbalance of distance ranks.Proceedings of the National Academy of Sciences, 121(19):e2317256121
2024
-
[20]
Dominé, C. C., Anguita, N., Proca, A. M., Braun, L., Kunin, D., Mediano, P. A., and Saxe, A. M. (2024). From lazy to rich: Exact learning dynamics in deep linear networks.arXiv preprint arXiv:2409.14623
-
[21]
Dominé, C. C. J., Anguita, N., Proca, A. M., Braun, L., Kunin, D., Mediano, P. A. M., and Saxe, A. M. (2025). From lazy to rich: Exact learning dynamics in deep linear networks. InThe Thirteenth International Conference on Learning Representations
2025
-
[22]
Glielmo, A., Zeni, C., Cheng, B., Csányi, G., and Laio, A. (2022). Ranking the information content of distance measures.PNAS nexus, 1(2):pgac039
2022
-
[23]
(2016).Deep learning, volume 1
Goodfellow, I., Bengio, Y ., Courville, A., and Bengio, Y . (2016).Deep learning, volume 1. MIT Press
2016
-
[24]
Gröger, F., Wen, S., and Brbi´c, M. (2026). Revisiting the platonic representation hypothesis: An aristotelian view.arXiv preprint arXiv:2602.14486
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Gu, Y ., Zheng, X., and Aste, T. (2024). Unraveling the enigma of double descent: An in-depth analysis through the lens of learned feature space. InThe Twelfth International Conference on Learning Representations
2024
-
[26]
Hastie, T., Montanari, A., Rosset, S., and Tibshirani, R. J. (2022). Surprises in high-dimensional ridgeless least squares interpolation.Annals of statistics, 50(2):949
2022
-
[27]
E., Mohamed, A.-r., Jaitly, N., Senior, A., Vanhoucke, V ., Nguyen, P., Sainath, T
Hinton, G., Deng, L., Yu, D., Dahl, G. E., Mohamed, A.-r., Jaitly, N., Senior, A., Vanhoucke, V ., Nguyen, P., Sainath, T. N., et al. (2012). Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups.IEEE Signal processing magazine, 29(6):82–97
2012
-
[28]
Huh, M., Cheung, B., Wang, T., and Isola, P. (2024). The platonic representation hypothesis. arXiv preprint arXiv:2405.07987
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Jarvis, D., Lee, S., Carla Juliette Dominé, C., M Saxe, A., and Sarao Mannelli, S. (2025). A theory of initialisation’s impact on specialisation.Journal of Statistical Mechanics: Theory and Experiment, 2025(11):114001
2025
-
[30]
Kalimeris, D., Kaplun, G., Nakkiran, P., Edelman, B., Yang, T., Barak, B., and Zhang, H. (2019). Sgd on neural networks learns functions of increasing complexity.Advances in neural information processing systems, 32
2019
- [31]
-
[32]
Klabunde, M., Schumacher, T., Strohmaier, M., and Lemmerich, F. (2025). Similarity of neural network models: A survey of functional and representational measures.ACM Computing Surveys, 57(9):1–52
2025
-
[33]
Kornblith, S., Norouzi, M., Lee, H., and Hinton, G. (2019). Similarity of neural network representations revisited. In Chaudhuri, K. and Salakhutdinov, R., editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3519–3529. PMLR. 11
2019
-
[34]
Kraskov, A., Stögbauer, H., and Grassberger, P. (2004). Estimating mutual information.Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, 69(6):066138
2004
-
[35]
Kriegeskorte, N., Mur, M., and Bandettini, P. A. (2008). Representational similarity analysis- connecting the branches of systems neuroscience.Frontiers in systems neuroscience, 2:249
2008
-
[36]
Krizhevsky, A., Hinton, G., et al. (2009). Learning multiple layers of features from tiny images
2009
-
[37]
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25
2012
-
[38]
and Hertz, J
Krogh, A. and Hertz, J. A. (1992). Generalization in a linear perceptron in the presence of noise. Journal of Physics A: Mathematical and General, 25(5):1135–1147
1992
-
[39]
K., Chan, S
Lampinen, A. K., Chan, S. C., and Hermann, K. (2024). Learned feature representations are biased by complexity, learning order, position, and more.Transactions on Machine Learning Research
2024
-
[40]
Lampinen, A. K., Chan, S. C., Li, Y ., and Hermann, K. (2025). Representation biases: will we achieve complete understanding by analyzing representations?arXiv preprint arXiv:2507.22216
-
[41]
Lampinen, A. K. and Ganguli, S. (2018). An analytic theory of generalization dynamics and transfer learning in deep linear networks.arXiv preprint arXiv:1809.10374
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
LeCun, Y . (1998). The mnist database of handwritten digits.http://yann. lecun. com/exdb/mnist/
1998
-
[43]
LeCun, Y ., Bengio, Y ., and Hinton, G. (2015). Deep learning.nature, 521(7553):436–444
2015
-
[44]
Li, Y ., Yosinski, J., Clune, J., Lipson, H., and Hopcroft, J. (2015). Convergent learning: Do different neural networks learn the same representations?arXiv preprint arXiv:1511.07543
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[45]
Marˇcenko, V . A. and Pastur, L. A. (1967). Distribution of eigenvalues for some sets of random matrices.Mathematics of the USSR-Sbornik, 1(4):457–483
1967
-
[46]
and Montanari, A
Mei, S. and Montanari, A. (2022). The generalization error of random features regression: Pre- cise asymptotics and the double descent curve.Communications on Pure and Applied Mathematics, 75(4):667–766
2022
-
[47]
Mendes, V . C., Bardone, L., Koller, C., Moreira, J. M., Erba, V ., Troiani, E., and Zdeborová, L. (2026). A solvable high-dimensional model where nonlinear autoencoders learn structure invisible to pca while test loss misaligns with generalization.arXiv preprint arXiv:2602.10680
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [48]
-
[49]
Nakkiran, P., Kaplun, G., Bansal, Y ., Yang, T., Barak, B., and Sutskever, I. (2021). Deep double descent: Where bigger models and more data hurt.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124003
2021
-
[50]
Nelsen, R. B. (2006).An introduction to copulas. Springer
2006
-
[51]
G., Athalye, A., and Mueller, J
Northcutt, C. G., Athalye, A., and Mueller, J. (2021). Pervasive label errors in test sets destabilize machine learning benchmarks.arXiv preprint arXiv:2103.14749
-
[52]
Raghu, M., Gilmer, J., Yosinski, J., and Sohl-Dickstein, J. (2017). Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability.Advances in neural information processing systems, 30
2017
-
[53]
Refinetti, M., Ingrosso, A., and Goldt, S. (2023). Neural networks trained with sgd learn distributions of increasing complexity. InInternational Conference on Machine Learning, pages 28843–28863. PMLR
2023
-
[54]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Saxe, A. M., McClelland, J. L., and Ganguli, S. (2013). Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv preprint arXiv:1312.6120. 12
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[55]
M., McClelland, J
Saxe, A. M., McClelland, J. L., and Ganguli, S. (2019). A mathematical theory of seman- tic development in deep neural networks.Proceedings of the National Academy of Sciences, 116(23):11537–11546
2019
-
[56]
C., Cueva, C
Sucholutsky, I., Muttenthaler, L., Weller, A., Peng, A., Bobu, A., Kim, B., Love, B. C., Cueva, C. J., Grant, E., Groen, I., Achterberg, J., Tenenbaum, J. B., Collins, K. M., Hermann, K., Oktar, K., Greff, K., Hebart, M. N., Cloos, N., Kriegeskorte, N., Jacoby, N., Zhang, Q., Marjieh, R., Geirhos, R., Chen, S., Kornblith, S., Rane, S., Konkle, T., O’Conne...
2025
-
[57]
H., Nando Tezoh, F
Umar, A. H., Nando Tezoh, F. K., Barbier, J., Acevedo, S., and Laio, A. (2026). The effect of label noise on the information content of neural representations.Frontiers in Physics, 14:1717253
2026
-
[58]
N., Kaiser, Ł., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. (2017). Attention is all you need.Advances in neural information processing systems, 30
2017
-
[59]
H., Kunz, E., Kornblith, S., and Linderman, S
Williams, A. H., Kunz, E., Kornblith, S., and Linderman, S. (2021). Generalized shape metrics on neural representations.Advances in neural information processing systems, 34:4738–4750
2021
-
[60]
D., Moroshko, E., Savarese, P., Golan, I., Soudry, D., and Srebro, N
Woodworth, B., Gunasekar, S., Lee, J. D., Moroshko, E., Savarese, P., Golan, I., Soudry, D., and Srebro, N. (2020). Kernel and rich regimes in overparametrized models. InConference on Learning Theory, pages 3635–3673. PMLR
2020
-
[61]
Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. (2016). Understanding deep learning requires rethinking generalization.arXiv preprint arXiv:1611.03530. 13 A Related Work A.1 Measures of representational similarity/alignment. Quantifying when two information processing systems represent information in compatible ways is a long-standing questio...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[62]
A single-layer FCNN with k hidden units, with input and output dimensions fixed to match the number of pixels in the input image and the number of classes in the task, respectively
-
[63]
The Maxpoll is [2,2,2,4]
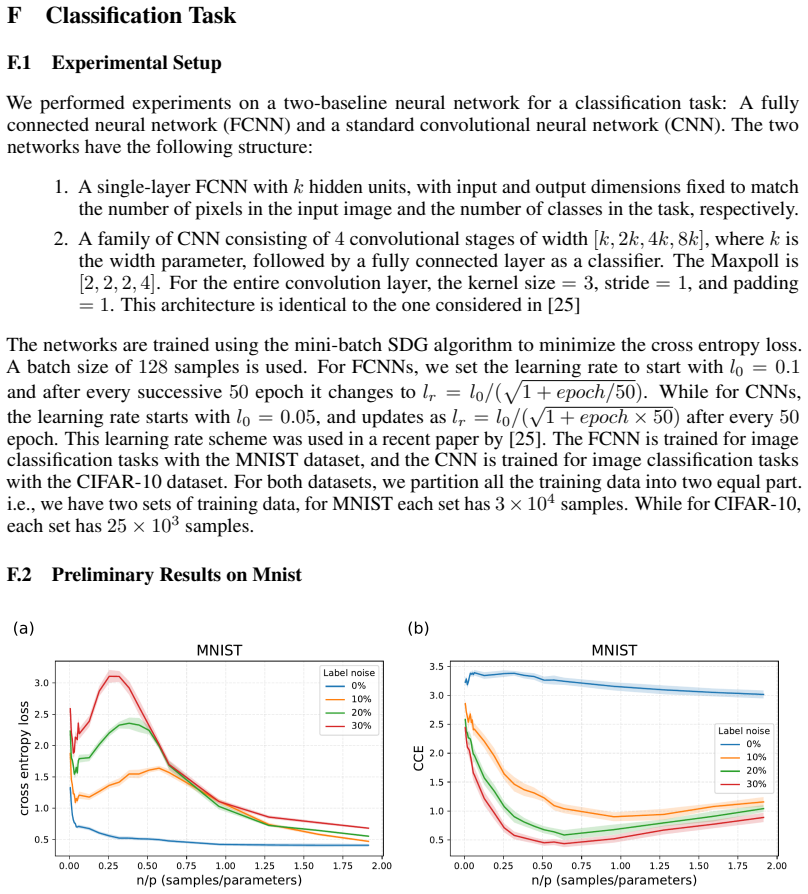
A family of CNN consisting of 4 convolutional stages of width [k,2k,4k,8k] , where k is the width parameter, followed by a fully connected layer as a classifier. The Maxpoll is [2,2,2,4] . For the entire convolution layer, the kernel size = 3, stride = 1, and padding = 1. This architecture is identical to the one considered in [25] The networks are traine...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.