Trust, Geometry, and Rules: A Credibility-Aware Reinforcement Learning Framework for Safe USV Navigation under Uncertainty
Pith reviewed 2026-06-29 16:30 UTC · model grok-4.3
The pith
A reinforcement learning framework weights critic updates by perception reliability, inflates geometric obstacles with uncertainty, and smooths rule signals to achieve safer USV navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
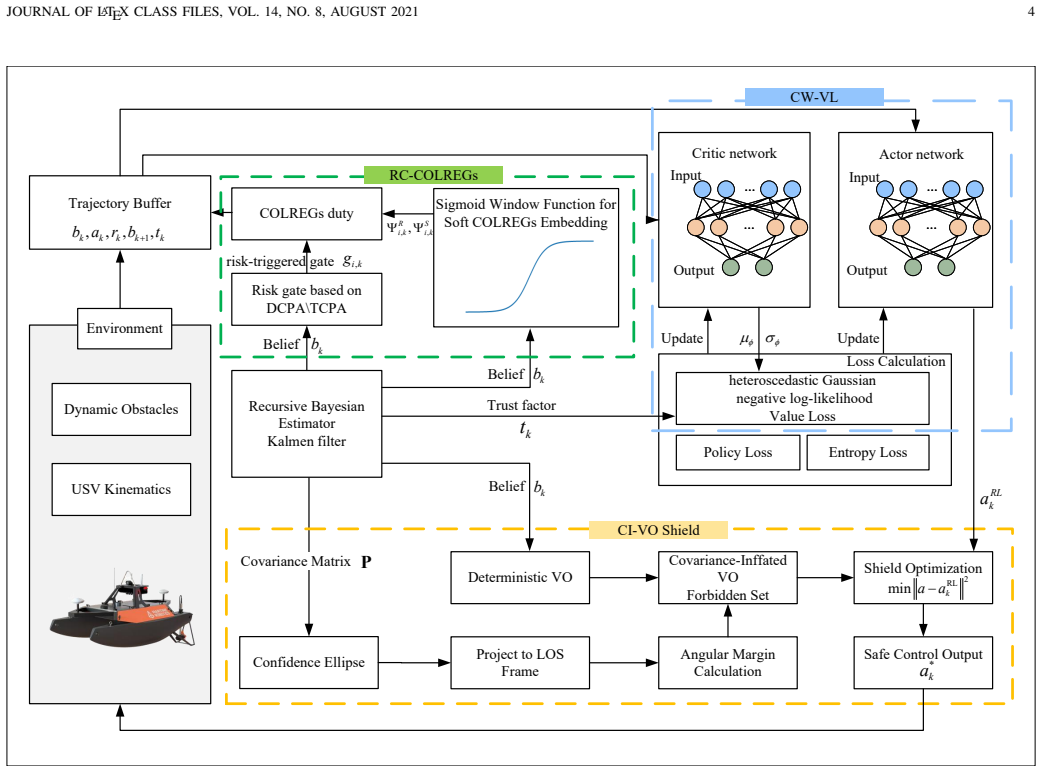
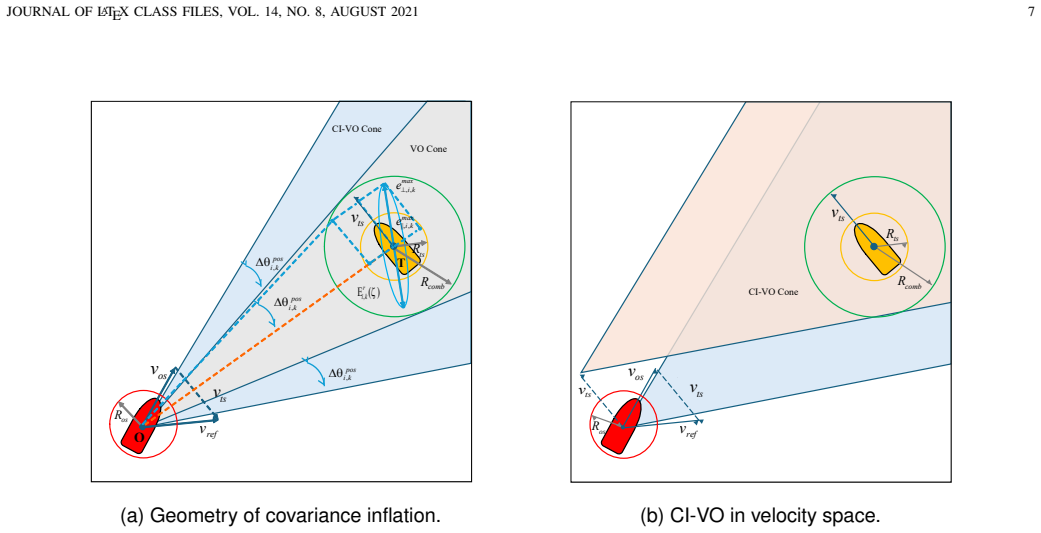
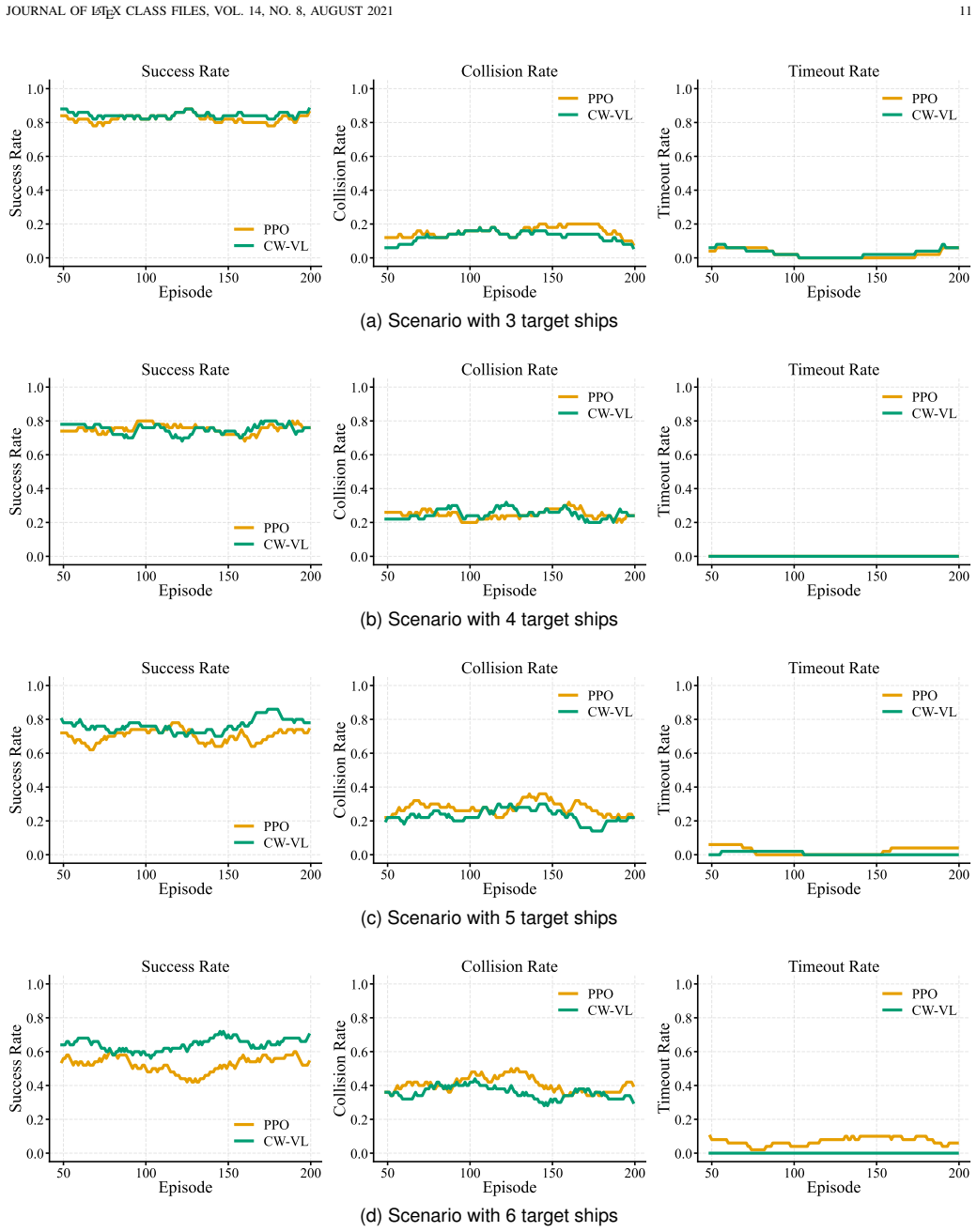
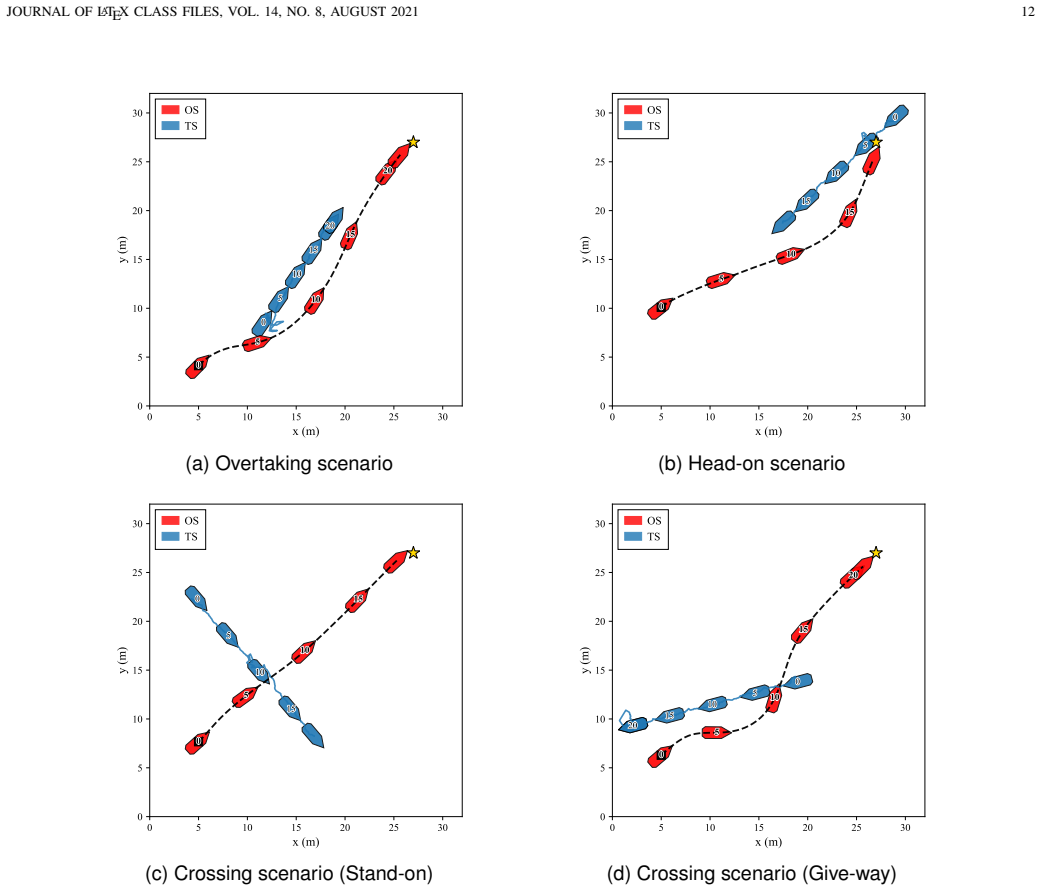
The authors introduce Credibility-Weighted Value Learning that computes a dynamic trust factor from the difference between filter covariance and empirical error statistics to scale the critic's heteroscedastic loss, Covariance-Inflated Velocity Obstacle that converts position uncertainty into enlarged angular exclusion zones to block unsafe actions, and Risk-Aware COLREGs Duty Embedding that converts binary encounter duties into continuous sector signals. Simulated encounter trials show the resulting policies exhibit greater robustness to perceptual inconsistency together with lower collision rates and higher COLREGs compliance than baseline reinforcement learning agents.
What carries the argument
Credibility-Weighted Value Learning that modulates critic loss via a trust factor derived from covariance-error discrepancy, paired with Covariance-Inflated Velocity Obstacles that supply geometric safety overrides and continuous COLREGs embeddings that supply smooth rule information.
If this is right
- Value estimates become less distorted by unreliable perception samples because the trust factor scales their contribution to the loss.
- Exploratory actions that would enter uncertainty-adjusted collision zones are blocked before execution by the geometric shield.
- Policy updates experience fewer abrupt changes because rule rewards arrive as continuous rather than binary signals.
- Trained policies record measurably lower collision incidence and higher rule compliance across varied encounter geometries.
Where Pith is reading between the lines
- The same trust-modulation idea could be tested on other sensor-driven robots where state estimates carry known error statistics.
- Real-world USV trials with actual wave and lighting disturbances would reveal whether simulation gains survive physical dynamics.
- The angular-margin construction might be extended to multi-agent traffic where each participant carries its own uncertainty estimate.
Load-bearing premise
The trust factor computed from the gap between predicted covariance and actual error statistics correctly identifies which samples should be down-weighted so the policy does not overfit to noise.
What would settle it
In the same simulated encounter scenarios, if the method produces collision rates or COLREGs violation counts statistically indistinguishable from or higher than standard reinforcement learning baselines, the performance claim would be refuted.
Figures
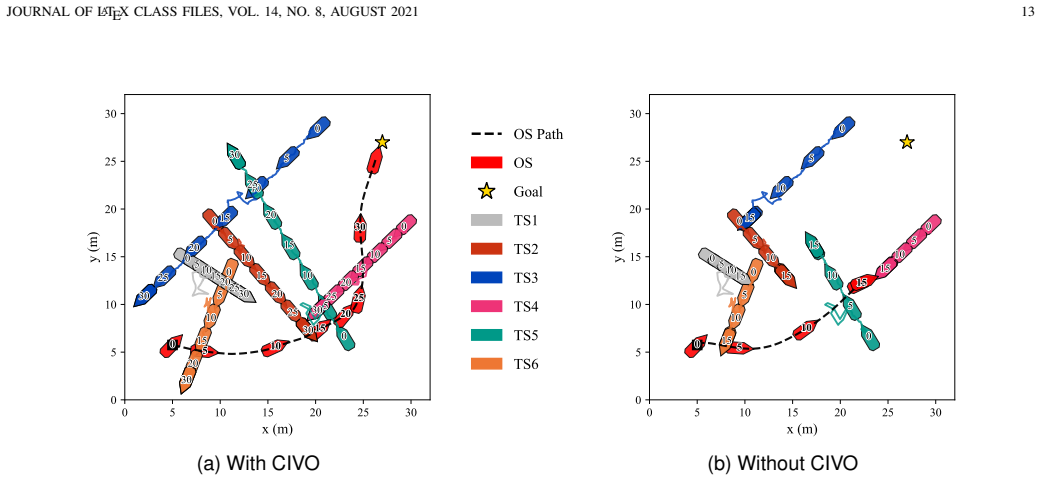
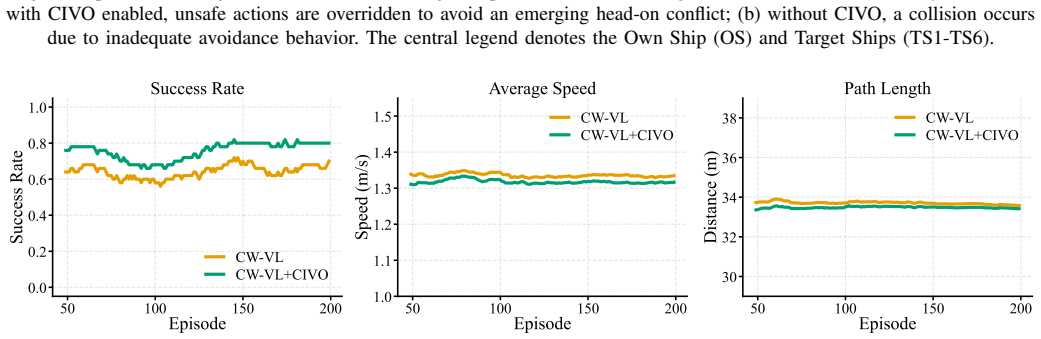
read the original abstract
Autonomous navigation of Unmanned Surface Vehicles (USVs) that is safe and compliant with the International Regulations for Preventing Collisions at Sea (COLREGs) remains a formidable challenge in dynamic maritime environments, particularly when perception systems exhibit miscalibrated uncertainty. Existing Reinforcement Learning (RL)-based methods often falter because state-estimation errors induce unreliable belief states that mislead the value function, while discrete traffic rules introduce discontinuity in the learning objective. To address these challenges, we propose a framework integrating credibility-aware learning, geometric safety shielding, and continuous rule-aware embedding. First, Credibility-Weighted Value Learning (CW-VL) introduces a dynamic trust factor derived from the discrepancy between filter-estimated covariance and empirical error statistics to modulate the critic's heteroscedastic loss, preventing policy overfitting to noisy samples. Second, the Covariance-Inflated Velocity Obstacle (CI-VO) maps position-estimation uncertainty into set-wise angular margins, forming a conservative geometric shield that overrides hazardous exploratory actions. Third, Risk-Aware COLREGs Duty Embedding relaxes binary encounter duties into continuous rule-aware signals, providing smooth sector-transition information and suppressing oscillation from sparse rule rewards. Simulated encounter studies demonstrate improved training robustness against perceptual inconsistency and superior collision avoidance and COLREGs compliance over baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a credibility-aware RL framework for USV navigation under perceptual uncertainty. It introduces Credibility-Weighted Value Learning (CW-VL) that derives a dynamic trust factor from the gap between filter-estimated covariance and empirical error statistics to modulate the critic's heteroscedastic loss; Covariance-Inflated Velocity Obstacle (CI-VO) that converts position uncertainty into angular safety margins; and Risk-Aware COLREGs Duty Embedding that relaxes binary rules into continuous signals. Simulated encounter studies are claimed to demonstrate improved training robustness, collision avoidance, and COLREGs compliance relative to baselines.
Significance. If the CW-VL trust factor is shown to correctly down-weight noisy samples without distorting value estimates or policy gradients, the framework would offer a concrete mechanism for safe RL in miscalibrated perception settings. The geometric shielding and continuous rule embedding provide complementary, non-RL components that could be evaluated independently. The reported simulation gains, if reproducible with error bars and ablation studies, would be of interest to the maritime autonomy community.
major comments (1)
- [Abstract / §3] Abstract / §3 (CW-VL description): The central claim that the discrepancy-derived trust factor 'prevents policy overfitting to noisy samples' and delivers robustness against perceptual inconsistency rests on an unverified property of the modulation. No derivation, fixed-point analysis, or edge-case examination (e.g., misspecified filter or noisy empirical statistics) is supplied showing that the resulting loss weights improve rather than bias the critic or policy gradients. This property is load-bearing for attributing the reported collision-avoidance and COLREGs gains to credibility-aware learning rather than to CI-VO or the embedding alone.
minor comments (2)
- [Abstract] The abstract states 'simulated encounter studies' but provides no quantitative metrics, baseline definitions, number of runs, or statistical significance; these details are required to assess the strength of the superiority claims.
- [§3] Notation for the trust factor, heteroscedastic loss, and CI-VO margins should be introduced with explicit equations rather than descriptive prose to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly to strengthen the theoretical grounding of CW-VL.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract / §3 (CW-VL description): The central claim that the discrepancy-derived trust factor 'prevents policy overfitting to noisy samples' and delivers robustness against perceptual inconsistency rests on an unverified property of the modulation. No derivation, fixed-point analysis, or edge-case examination (e.g., misspecified filter or noisy empirical statistics) is supplied showing that the resulting loss weights improve rather than bias the critic or policy gradients. This property is load-bearing for attributing the reported collision-avoidance and COLREGs gains to credibility-aware learning rather than to CI-VO or the embedding alone.
Authors: We agree that the manuscript provides no formal derivation, fixed-point analysis, or explicit edge-case examination of the trust-factor modulation. The current presentation relies on the design intuition that the discrepancy-based weight down-weights samples whose empirical error exceeds the filter covariance, together with the observed robustness gains in simulation. To address the concern that this property is load-bearing for attributing improvements to CW-VL, we will add a new subsection in §3 that (i) derives the effect of the modulation on the heteroscedastic critic loss and the resulting policy gradient, (ii) analyzes the fixed-point behavior under consistent versus inconsistent covariance estimates, and (iii) includes a brief sensitivity study for misspecified filters and noisy empirical statistics. We will also expand the experimental section with an ablation that isolates CW-VL from CI-VO and the COLREGs embedding, reporting mean and standard deviation over multiple seeds. revision: yes
Circularity Check
No circularity: proposed components are additive heuristics without self-referential reduction.
full rationale
The abstract and described framework introduce CW-VL (discrepancy-derived trust factor modulating heteroscedastic loss), CI-VO (covariance-inflated velocity obstacles), and continuous COLREGs embedding as independent engineering additions to standard RL. No equations or steps are presented that define a quantity in terms of itself, rename a fitted parameter as a prediction, or rely on self-citation chains for uniqueness. The simulation results are external to the definitions, so the derivation chain does not collapse by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Survey of deep learning for autonomous surface vehicles in marine environments,
Y . Qiao, J. Yin, W. Wang, F. Duarte, J. Yang, and C. Ratti, “Survey of deep learning for autonomous surface vehicles in marine environments,” IEEE Trans. Intell. Transp. Syst., vol. 24, no. 4, pp. 3678–3701, 2023
2023
-
[2]
Colreg and mass: Analytical review to identify research trends and gaps in the development of autonomous collision avoidance,
C.-H. Chang, I. B. Wijeratne, C. Kontovas, and Z. Yang, “Colreg and mass: Analytical review to identify research trends and gaps in the development of autonomous collision avoidance,”Ocean Eng., vol. 302, p. 117652, 2024
2024
-
[3]
Ude-based distributed formation control for msvs with collision avoidance and connectivity preservation,
S. He, S.-L. Dai, Z. Zhao, T. Zou, and Y . Ma, “Ude-based distributed formation control for msvs with collision avoidance and connectivity preservation,”IEEE Trans. Ind. Inf., vol. 20, no. 2, pp. 1476–1487, 2024
2024
-
[4]
Real-time obstacle avoidance for manipulators and mobile robots,
O. Khatib, “Real-time obstacle avoidance for manipulators and mobile robots,”Int. J. Robot. Res., vol. 5, no. 1, pp. 90–98, 1986
1986
-
[5]
Leader-follower control and apf for multi-usv coordination and obstacle avoidance,
P. Yuan, Z. Zhang, Y . Li, and J. Cui, “Leader-follower control and apf for multi-usv coordination and obstacle avoidance,”IEEE ROBOT AUTOM MAG, vol. 313, p. 119487, 2024
2024
-
[6]
The dynamic window approach to collision avoidance,
D. Fox, W. Burgard, and S. Thrun, “The dynamic window approach to collision avoidance,”IEEE Robot. Autom. Mag., vol. 4, no. 1, pp. 23–33, 1997
1997
-
[7]
Unmanned- surface-vehicle-aided maritime data collection using deep reinforcement learning,
N. Su, J.-B. Wang, C. Zeng, H. Zhang, M. Lin, and G. Y . Li, “Unmanned- surface-vehicle-aided maritime data collection using deep reinforcement learning,”IEEE Internet Things J., vol. 9, no. 20, pp. 19 773–19 786, 2022
2022
-
[8]
Hybrid path planning method for USV using bidirectional A* and improved DWA considering the manoeuvrability and COLREGs,
D. Xu, J. Yang, X. Zhou, and H. Xu, “Hybrid path planning method for USV using bidirectional A* and improved DWA considering the manoeuvrability and COLREGs,”Ocean Eng., vol. 298, p. 117210, 2024
2024
-
[9]
Motion planning in dynamic environments using velocity obstacles,
P. Fiorini and Z. Shiller, “Motion planning in dynamic environments using velocity obstacles,”Int. J. Robot. Res., vol. 17, no. 7, pp. 760–772, 1998
1998
-
[10]
Distributed multiple unmanned surface vehicles path planning integrated control framework in complex scenarios,
D. Xiao, Z. Song, M. Zhai, and N. Jiang, “Distributed multiple unmanned surface vehicles path planning integrated control framework in complex scenarios,”Comput. Electr. Eng., vol. 124, p. 110430, 2025
2025
-
[11]
Distributed mpc-based robust collision avoidance formation navigation of constrained multiple usvs,
G. Wen, J. Lam, J. Fu, and S. Wang, “Distributed mpc-based robust collision avoidance formation navigation of constrained multiple usvs,” IEEE Trans. Intell. Veh., vol. 9, no. 1, pp. 1804–1816, 2024
2024
-
[12]
Flocking of under-actuated unmanned surface vehicles via deep reinforcement learning and model predictive path integral control,
C. Pan, Z. Peng, Y . Li, B. Han, and D. Wang, “Flocking of under-actuated unmanned surface vehicles via deep reinforcement learning and model predictive path integral control,”IEEE Trans. Instrum. Meas., vol. 73, pp. 1–11, 2024
2024
-
[13]
Dynamic obstacle avoidance of fixed-wing aircraft in final phase via reinforcement learning,
Y . Ou, H. Xiong, H. Jiang, Y . Zhang, and B. R. Noack, “Dynamic obstacle avoidance of fixed-wing aircraft in final phase via reinforcement learning,” IEEE Trans. Aerosp. Electron. Syst., vol. 60, no. 4, pp. 3923–3935, 2024
2024
-
[14]
Reinforcement learned distributed multi-robot navigation with reciprocal velocity obstacle shaped rewards,
R. Han, S. Chen, S. Wang, Z. Zhang, R. Gao, Q. Hao, and J. Pan, “Reinforcement learned distributed multi-robot navigation with reciprocal velocity obstacle shaped rewards,”IEEE Rob. Autom. Lett., vol. 7, no. 3, pp. 5896–5903, 2022
2022
-
[15]
Path planning of USV in confined waters based on improved A* and DW A fusion algorithm,
J. Zhang, H. Ling, Z. Tang, W. Song, and A. Lu, “Path planning of USV in confined waters based on improved A* and DW A fusion algorithm,” Ocean Eng., vol. 322, p. 120475, 2025
2025
-
[16]
Integrated intelligent guidance and motion control of USVs with anticipatory collision avoidance decision-making,
Y . Tao, J. Du, and F. L. Lewis, “Integrated intelligent guidance and motion control of USVs with anticipatory collision avoidance decision-making,” IEEE Trans. Intell. Transp. Syst., vol. 25, no. 11, pp. 17 810–17 820, 2024
2024
-
[17]
Autonomous navigation and collision avoidance for unmanned surface vehicle based on TD3-PD algorithm with CNN-GRU network,
Z. Wei and Q. Wang, “Autonomous navigation and collision avoidance for unmanned surface vehicle based on TD3-PD algorithm with CNN-GRU network,”Ocean Eng., vol. 341, p. 122633, 2025
2025
-
[18]
Obstacle avoidance for environmentally-driven USVs based on deep reinforcement learning in large-scale uncertain environments,
P. Wang, R. Liu, X. Tian, X. Zhang, L. Qiao, and Y . Wang, “Obstacle avoidance for environmentally-driven USVs based on deep reinforcement learning in large-scale uncertain environments,”Ocean Eng., vol. 270, p. 113670, 2023
2023
-
[19]
An enhanced ship collision-avoidance method using Q-learning-optimized VO-PSO-Q-learning algorithm,
X. Wang, Y . Li, L. Gan, and Y . Ma, “An enhanced ship collision-avoidance method using Q-learning-optimized VO-PSO-Q-learning algorithm,” Ocean Eng., vol. 343, p. 123395, 2026
2026
-
[20]
What uncertainties do we need in Bayesian deep learning for computer vision?
A. Kendall and Y . Gal, “What uncertainties do we need in Bayesian deep learning for computer vision?” inAdv. Neural Inf. Process. Syst., vol. 30. Curran Associates, Inc., 2017, pp. 5574–5584
2017
-
[21]
A novel adaptive Kalman filter based on credibility measure,
Q. Ge, X. Hu, Y . Li, H. He, and Z. Song, “A novel adaptive Kalman filter based on credibility measure,”IEEE/CAA J. Autom. Sinica, vol. 10, no. 1, pp. 103–120, 2023
2023
-
[22]
Credible Gaussian sum cubature Kalman filter based on non-Gaussian characteristic analysis,
Q. Ge, Y . Cheng, G. Yao, S. Chen, and Y . Zhu, “Credible Gaussian sum cubature Kalman filter based on non-Gaussian characteristic analysis,” Neurocomputing, vol. 565, p. 126922, 2024
2024
-
[23]
One step closer to unbiased aleatoric uncertainty estimation,
W. Zhang, Z. M. Ma, S. Das, T.-W. L. Weng, A. Megretski, L. Daniel, and L. M. Nguyen, “One step closer to unbiased aleatoric uncertainty estimation,” inProc. AAAI Conf. Artif. Intell., vol. 38, no. 15, 2024, pp. 16 857–16 864
2024
-
[24]
Set- membership belief state-based reinforcement learning for POMDPs,
W. Wei, L. Zhang, L. Li, H. Song, and J. Liang, “Set- membership belief state-based reinforcement learning for POMDPs,” inICML, vol. 202, 2023, pp. 36 856–36 867. [Online]. Available: https://proceedings.mlr.press/v202/wei23d.html
2023
-
[25]
Uncertainty-aware deep distributed reinforcement learning for autonomous navigation of unmanned surface vehicles in complex environments,
M. Huang, X. Li, Z. Li, D. Zhang, and Y . Chen, “Uncertainty-aware deep distributed reinforcement learning for autonomous navigation of unmanned surface vehicles in complex environments,”Ocean Eng., vol. 342, p. 122899, 2025
2025
-
[26]
A path planning strategy unified with a COLREGS collision avoidance function based on deep reinforcement learning and artificial potential field,
L. Li, D. Wu, Y . Huang, and Z.-M. Yuan, “A path planning strategy unified with a COLREGS collision avoidance function based on deep reinforcement learning and artificial potential field,”Appl. Ocean Res., vol. 113, p. 102759, 2021
2021
-
[27]
Risk-based implementation of COLREGs for autonomous surface vehicles using deep reinforcement learning,
A. Heiberg, T. N. Larsen, E. Meyer, A. Rasheed, O. San, and D. Varag- nolo, “Risk-based implementation of COLREGs for autonomous surface vehicles using deep reinforcement learning,”Neural Networks, vol. 152, pp. 17–33, 2022
2022
-
[28]
COLREGs- constrained safe reinforcement learning for realising MASS’s risk- informed collision avoidance decision making,
C. Wang, X. Zhang, H. Gao, M. Bashir, H. Li, and Z. Yang, “COLREGs- constrained safe reinforcement learning for realising MASS’s risk- informed collision avoidance decision making,”Knowledge-Based Syst., vol. 300, p. 112205, 2024
2024
-
[29]
Provable traffic rule compliance in safe reinforcement learning on the open sea,
H. Krasowski and M. Althoff, “Provable traffic rule compliance in safe reinforcement learning on the open sea,”IEEE Trans. Intell. Veh., vol. 9, no. 12, pp. 7617–7634, 2024
2024
-
[30]
Multi-usv formation collision avoidance via deep reinforcement learning and colregs,
C.-C. Wang, Y .-L. Wang, and L. Jia, “Multi-usv formation collision avoidance via deep reinforcement learning and colregs,”IEEE/CAA J. Autom. Sinica, vol. 11, no. 11, pp. 2349–2351, 2024
2024
-
[31]
Planning and acting in partially observable stochastic domains,
L. P. Kaelbling, M. L. Littman, and A. R. Cassandra, “Planning and acting in partially observable stochastic domains,”Artificial Intelligence, vol. 101, no. 1–2, pp. 99–134, 1998
1998
-
[32]
Thrun, W
S. Thrun, W. Burgard, and D. Fox,Probabilistic Robotics. MIT Press, 2005
2005
-
[34]
Proximal Policy Optimization Algorithms
[Online]. Available: https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
G. J. Klir and B. Yuan,Fuzzy Sets and Fuzzy Logic: Theory and Applications. Prentice Hall, 1995
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.