Probabilistic Recurrent Intention Switching Model
Pith reviewed 2026-06-29 19:20 UTC · model grok-4.3
The pith
A recurrent network for intention transitions lets multi-intention IRL decompose into independent closed-form reward subproblems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
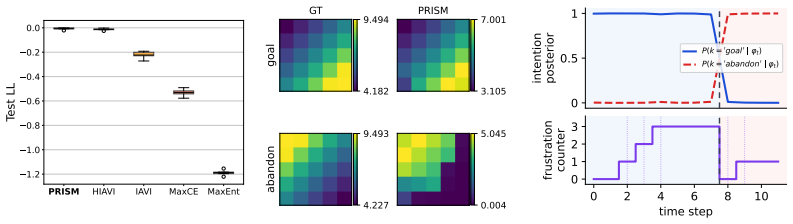
The Probabilistic Recurrent Intention Switching Model replaces memoryless Markov chains and manual state augmentation with a lightweight recurrent network that maps observation history to a per-step intention distribution; the resulting EM objective decomposes exactly into independent per-intention reward subproblems, each solvable in closed form, yielding an O(nK) E-step with no variational approximation.
What carries the argument
The lightweight recurrent network that maps observation history to a per-step intention distribution, which enables the exact decomposition of the EM objective into independent per-intention subproblems.
If this is right
- The E-step runs in O(nK) time with an exact closed-form solution per intention.
- Reward functions for each intention can be learned independently without joint optimization.
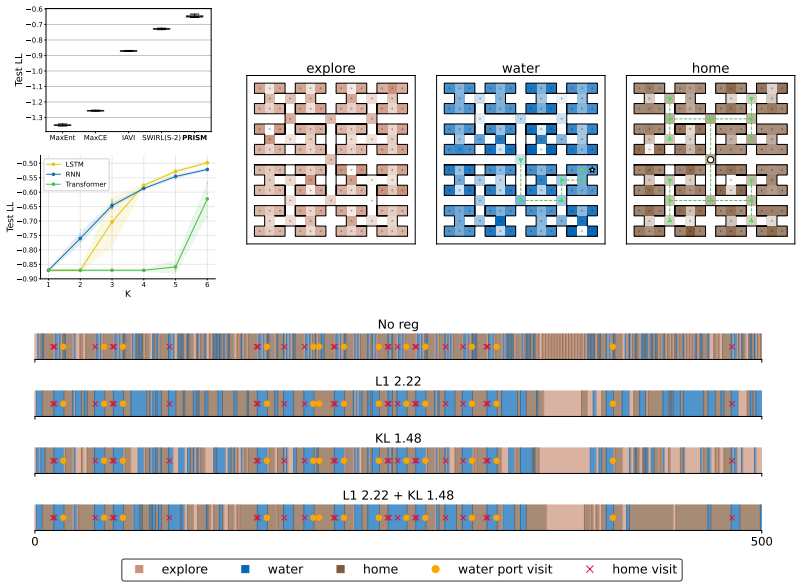
- The approach scales to the first large-scale robotic manipulation dataset for multi-intention IRL.
- Recovered intentions are temporally coherent and nameable without any intention labels.
Where Pith is reading between the lines
- The same recurrent-history mechanism could be tested in other latent-mode sequential decision problems beyond IRL.
- Online intention inference during execution becomes feasible because the recurrent component already conditions on history at each step.
- Biological agents that exhibit goal switching may be modeled with comparable lightweight recurrent dynamics rather than explicit Markov memory.
Load-bearing premise
Intention transitions can be adequately captured by feeding observation history into a lightweight recurrent network that produces a per-step intention distribution, replacing both memoryless Markov chains and manual fixed-history augmentation.
What would settle it
Running the model on the mouse labyrinth or BridgeData V2 dataset and finding that held-out log-likelihood does not exceed that of Markov-chain multi-intention baselines would falsify the claimed advantage.
Figures


read the original abstract
Inverse reinforcement learning (IRL) recovers reward functions from observed behavior, yet traditional methods assume a single stationary reward that cannot capture goal switching within an episode. Recent multi-intention IRL methods address this by segmenting trajectories, but model intention transitions as either a memoryless Markov chain or via manual state augmentation with a fixed history window. We propose the Probabilistic Recurrent Intention Switching Model (PRISM), which replaces both mechanisms with a lightweight recurrent network that maps observation history to a per-step intention distribution. We prove that the resulting EM objective decomposes exactly into independent per-intention reward subproblems, each solvable in closed form, yielding an $\mathcal{O}(nK)$ E-step with no variational approximation. We evaluate PRISM on a non-Markovian gridworld, a mouse labyrinth, and BridgeData~V2 robotic manipulation, the first large-scale robotic application of multi-intention IRL. Across all settings PRISM achieves the highest held-out log-likelihood while recovering nameable, temporally coherent intentions from unlabeled demonstrations, suggesting that discrete goal switching is present in both biological and artificial agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Probabilistic Recurrent Intention Switching Model (PRISM) for multi-intention inverse reinforcement learning. It replaces memoryless Markov chains or fixed-history augmentation with a lightweight recurrent network that produces per-step intention distributions from observation history. The central claim is a proof that the resulting EM objective decomposes exactly into K independent per-intention reward subproblems, each solvable in closed form, yielding an O(nK) E-step with no variational approximation. Experiments on a non-Markovian gridworld, mouse labyrinth, and BridgeData V2 robotic manipulation dataset report highest held-out log-likelihood and recovery of nameable, temporally coherent intentions.
Significance. If the exact decomposition holds for a recurrent intention model, the result would enable scalable multi-intention IRL without variational approximations or manual history engineering, with particular value for large robotic datasets. The BridgeData V2 application is a notable first for the subfield. The paper also supplies concrete empirical evidence of discrete goal switching in both biological and artificial agent trajectories.
major comments (2)
- [§3] §3 (EM derivation and Theorem 1): The claimed exact decomposition of the EM objective into independent per-intention closed-form reward subproblems must explicitly show how the recurrent hidden-state recursion (h_t depending on all prior observations and previous intention outputs) produces no residual cross-intention coupling terms after marginalization. The abstract and high-level argument assert factorization follows directly from the model definition, but the provided steps do not demonstrate cancellation of the time-dependent dependencies introduced by the RNN; this is load-bearing for both the closed-form claim and the O(nK) complexity.
- [§4.3] §4.3 (BridgeData V2 experiments): The reported performance advantage is stated without the specific baseline methods, exact metrics (e.g., whether log-likelihood is normalized per trajectory or per step), number of runs, or error bars. Because the central efficiency claim rests on the decomposition being exact, the empirical section must include these controls to allow verification that gains are not artifacts of implementation details.
minor comments (2)
- [§2.2] Notation for the recurrent network output (intention distribution at each step) is introduced without an explicit equation linking it to the hidden state update; adding this would clarify the input to the E-step.
- [Figure 3] Figure 3 (intention recovery visualizations) lacks axis labels on the time axis and a legend distinguishing ground-truth vs. inferred segments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will incorporate clarifications and additional details in the revised version.
read point-by-point responses
-
Referee: [§3] §3 (EM derivation and Theorem 1): The claimed exact decomposition of the EM objective into independent per-intention closed-form reward subproblems must explicitly show how the recurrent hidden-state recursion (h_t depending on all prior observations and previous intention outputs) produces no residual cross-intention coupling terms after marginalization. The abstract and high-level argument assert factorization follows directly from the model definition, but the provided steps do not demonstrate cancellation of the time-dependent dependencies introduced by the RNN; this is load-bearing for both the closed-form claim and the O(nK) complexity.
Authors: We agree that the current proof sketch in §3 would benefit from an expanded derivation to explicitly demonstrate the cancellation. The intention variable z_t is drawn conditionally on the RNN hidden state h_t, and the per-step reward likelihood depends only on the current z_t (not on h_t directly). When taking the expectation in the E-step over the posterior over intention sequences, the complete-data log-likelihood factors as a sum over independent per-intention terms because each trajectory segment assigned to a given intention contributes only to its own reward subproblem; the RNN parameters are updated separately in the M-step. To address the referee's concern, we will insert a multi-line expansion of the marginalization step in the revised Theorem 1 proof that isolates and cancels the time-dependent cross terms arising from the recurrent recursion. This addition will make the O(nK) claim fully rigorous without altering the model or algorithm. revision: yes
-
Referee: [§4.3] §4.3 (BridgeData V2 experiments): The reported performance advantage is stated without the specific baseline methods, exact metrics (e.g., whether log-likelihood is normalized per trajectory or per step), number of runs, or error bars. Because the central efficiency claim rests on the decomposition being exact, the empirical section must include these controls to allow verification that gains are not artifacts of implementation details.
Authors: We concur that the experimental reporting in §4.3 is currently underspecified. In the revision we will (i) list all baselines explicitly (Markov intention chain, fixed-window augmentation, and any additional ablations), (ii) state that held-out log-likelihood is computed per step and normalized by trajectory length, (iii) report results over 5 independent random seeds with mean and standard deviation, and (iv) include error bars on all plots. These additions will allow direct verification that the observed gains are attributable to the exact decomposition rather than implementation choices. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central result is a claimed mathematical proof that the EM objective decomposes exactly into independent per-intention reward subproblems solvable in closed form. This is presented as following from the model definition (recurrent network mapping observation history to intention distributions) rather than from any fitted parameters or self-citations. No load-bearing steps reduce by construction to inputs, and no self-citation chains or ansatzes are invoked for the decomposition. The recurrent component is an explicit modeling choice whose effect on the objective is asserted to preserve exact factorization; any question of whether that assertion holds is a matter of proof validity or correctness, not circularity. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intention transitions are generated by a recurrent network from observation history
invented entities (1)
-
Probabilistic Recurrent Intention Switching Model (PRISM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jingyang Ke, Feiyang Wu, Jiyi Wang, Jeffrey Markowitz, and Anqi Wu. Inverse reinforcement learning with switching rewards and history dependency for characterizing animal behaviors.arXiv preprint arXiv:2501.12633,
-
[3]
Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions.arXiv preprint arXiv:2403.03181,
-
[4]
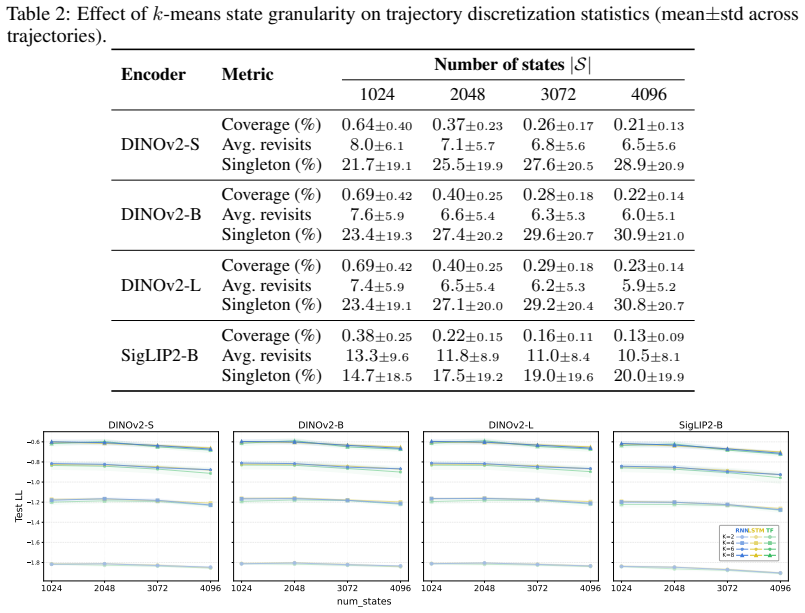
DINOv2: Learning Robust Visual Features without Supervision
10 Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Benjamin Freed, Antoine Dedieu, Clement Gehring, Nikolaos Gkanatsios, Kristian Hartikainen, Nikhil Joshi, Karl Labat, Haotian Li, Jianlan Luo, et al. π0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdul- mohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
When P is known, this can be solved in closed form via least squares, yielding IA VI [Kalweit et al., 2020]
11 A Theoretical and Technical Details A.1 IA VI Formulation Given expert demonstrationsD, the IRL problem under a Boltzmann policy is formulated as: maximizeE (ξ,ψ)∼(D,O) logP(ξ|π r) subject toπ r(a|s) = exp Q(s, a)−log P a′∈A expQ(s, a ′) Q(s, a) =r(s, a) +γ P s′ P(s ′ |s, a) max a′∈A Q(s′, a′) s∈ S, a∈ A (A.1) where r is the optimization variable. When...
2020
-
[8]
Closer to zero is better
goal abandon goal abandon PRISM (K=2)2.40±0.37 5.60±0.45−1.74±0.59−6.02±0.85 HIQL (K=2)2.51±0.13 6.12±0.38−1.95±0.54−6.80±1.25 IA VI (K=1)2.06±0.02 6.74±0.00−1.41±0.01−9.20±0.00 MaxCausalEnt (K=1)5.32±0.00 6.67±0.00−3.32±0.00−9.12±0.00 MaxEnt (K=1)6.61±0.00 6.76±0.00−4.16±0.00−9.10±0.00 Table B.1: Expected value difference on the frustration gridworld (5-...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.