Black-box Membership Inference Attacks on the Pre-training Data of Image-generation Models
Pith reviewed 2026-06-29 18:36 UTC · model grok-4.3
The pith
Perturbing both suspect images and their textual instructions extracts stronger membership signals from black-box diffusion models than image-only methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
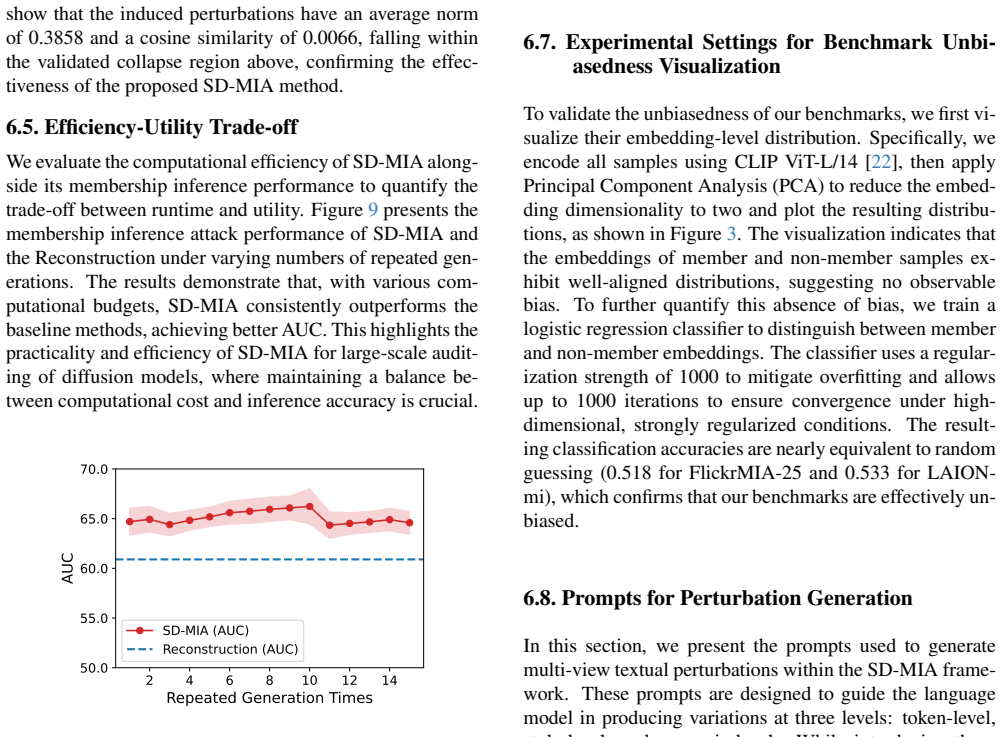
Core claim
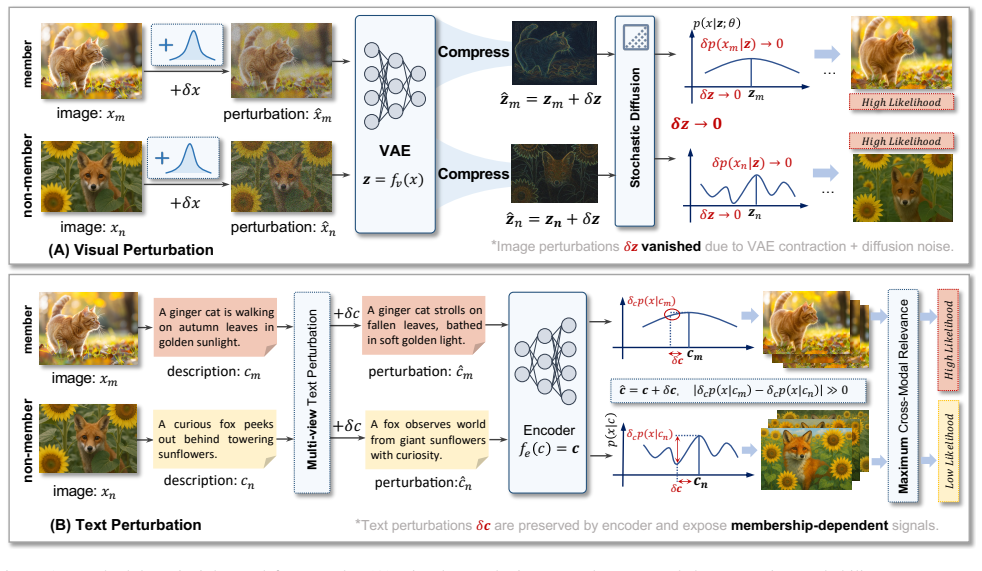
Analyzing how a black-box diffusion model denoises a target image together with perturbed textual instructions reveals more distinctive membership cues, allowing the SD-MIA framework to detect pre-training data through a cross-modal data perturbation mechanism.
What carries the argument
The cross-modal data perturbation mechanism that perturbs both the target image and corresponding textual instructions to extract membership signals from the denoising process.
If this is right
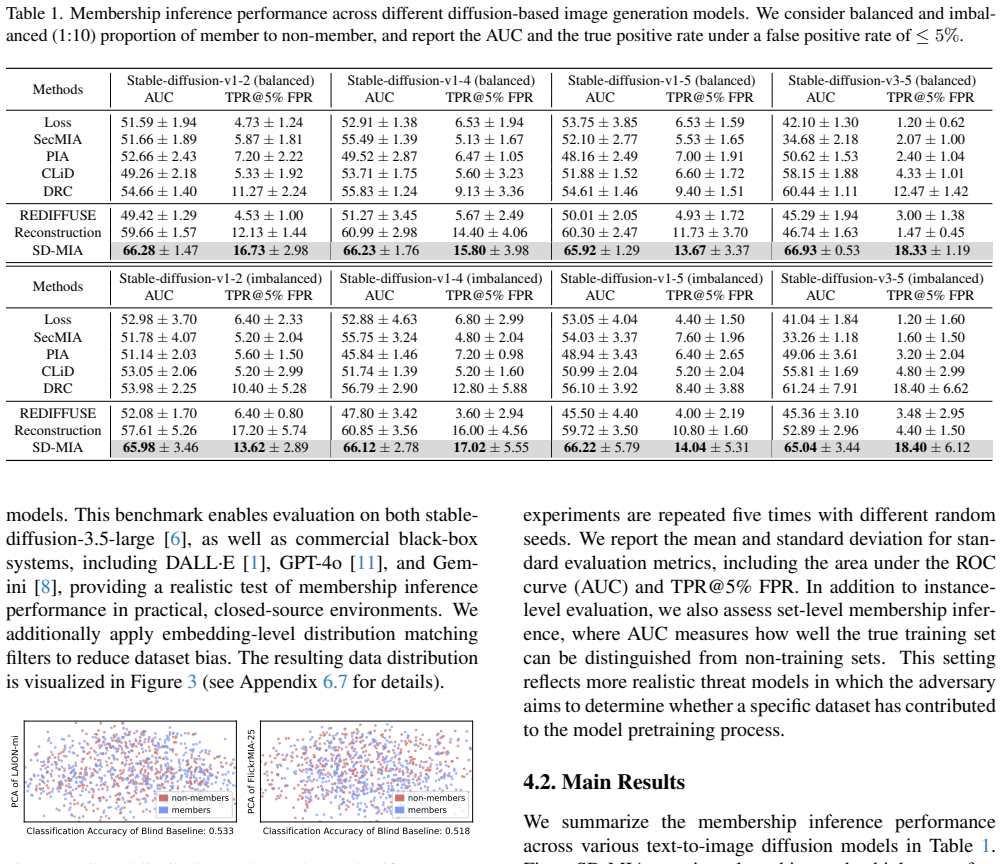
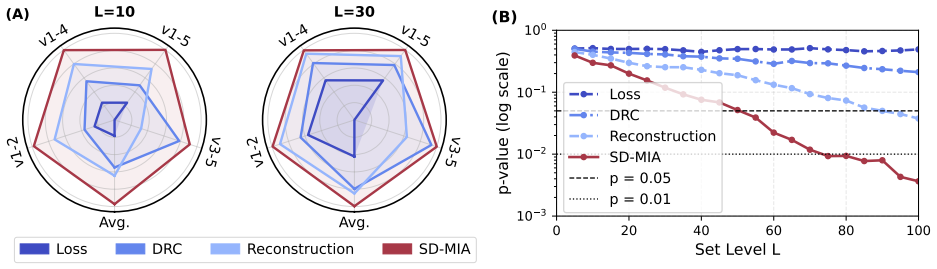
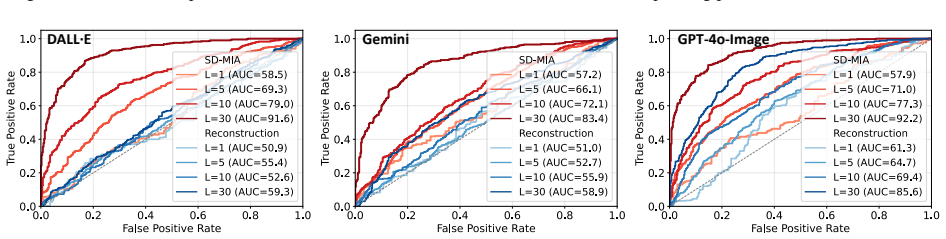
- SD-MIA outperforms existing baselines, including methods that access internal model features.
- The approach succeeds on both public benchmarks and newly built datasets that enforce identical member and non-member distributions.
- Membership detection remains effective for pre-training data where image-only perturbation methods lose power.
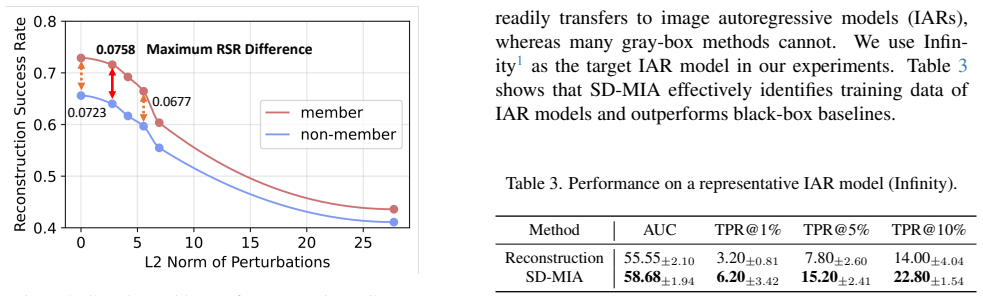
- The attack applies directly to closed-source image generation platforms without requiring internal access.
Where Pith is reading between the lines
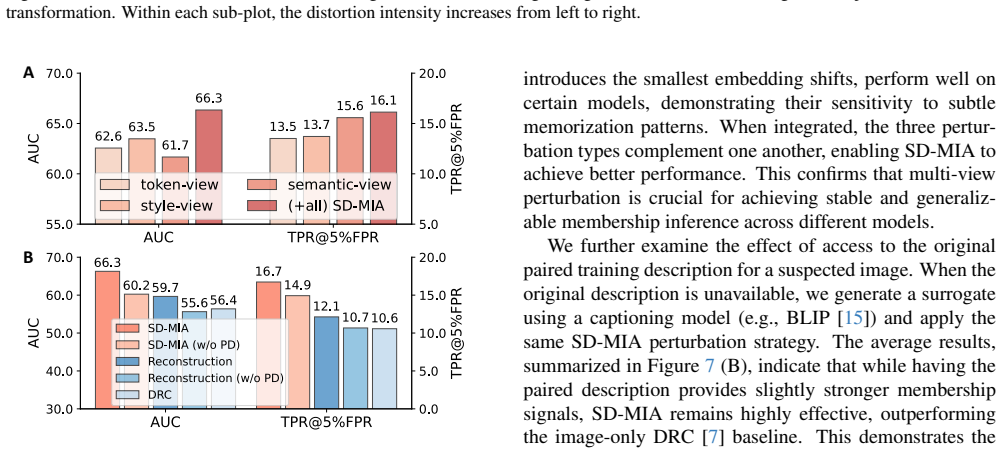
- Similar cross-modal techniques might apply to other multimodal generative systems to audit training data usage.
- Model developers could add regularization that reduces leakage of membership information across image and text modalities.
- Auditing services might adopt this style of test to verify compliance with data-use policies in commercial generators.
Load-bearing premise
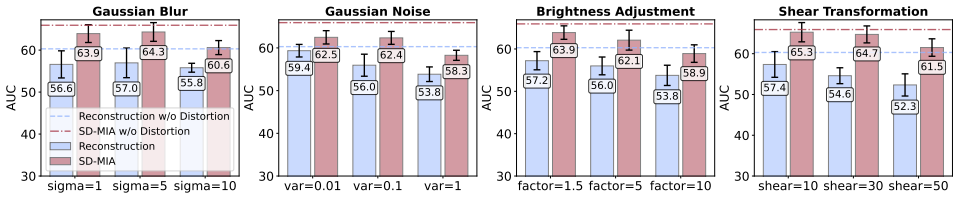
Cross-modal perturbations of images and text will keep producing membership signals that distinguish pre-training data even when member and non-member samples follow identical distributions.
What would settle it
A controlled test on a dataset with identical member and non-member distributions in which SD-MIA accuracy falls to chance level while the underlying diffusion model shows equivalent denoising performance on both sets.
Figures
read the original abstract
The rapid advancement of diffusion-based image generation models has raised serious concerns regarding potential copyright and privacy infringements involving human-created data. Membership inference attacks (MIAs) have emerged as a promising tool for identifying unauthorized data usage during model training. Existing methods typically assess the ability of model to denoise perturbed suspect images as an indicator of membership status. However, the discriminative power of such features is highly dependent on the degree of model memorization and deteriorates significantly when applied to less exposed data (e.g., pre-training data). Although several methods attempt to enhance detection by leveraging internal model features, these features are generally inaccessible in mainstream closed-source image generation platforms, limiting their practicality. In this paper, we demonstrate that analyzing how a black-box diffusion model denoises a target image and corresponding perturbed textual instructions can reveal more distinctive membership cues. Based on this insight, we propose a black-box membership inference attack framework (named SD-MIA) that leverages a cross-modal data perturbation mechanism to detect pre-training data in diffusion models. We conduct extensive experiments on both a public benchmark dataset and a newly constructed dataset, each comprising pre-training membership and non-membership samples with identical distributions. Experimental results demonstrate that SD-MIA achieves superior performance compared to existing baselines, including those with the unfair advantage of accessing internal model features.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SD-MIA, a black-box membership inference attack on pre-training data of diffusion image-generation models. It claims that analyzing denoising behavior under cross-modal perturbations (target image plus perturbed textual instructions) yields more distinctive membership signals than image-only perturbations, and reports that SD-MIA outperforms baselines—including some that access internal features—on both a public benchmark and a newly constructed dataset where member and non-member samples have identical distributions.
Significance. If the experimental claims are substantiated, the work would be significant for practical privacy auditing of closed-source generative models, as it targets the difficult regime of pre-training data (where memorization is low) using only black-box access. The construction of a matched-distribution dataset is a methodological strength that supports fair evaluation.
major comments (2)
- [Abstract] Abstract: the central claim that 'SD-MIA achieves superior performance compared to existing baselines' is asserted without any quantitative metrics, tables, statistical tests, ablation studies, or error analysis. This absence is load-bearing because the paper's contribution rests on demonstrating that the cross-modal mechanism produces discriminative signals where image-only methods fail.
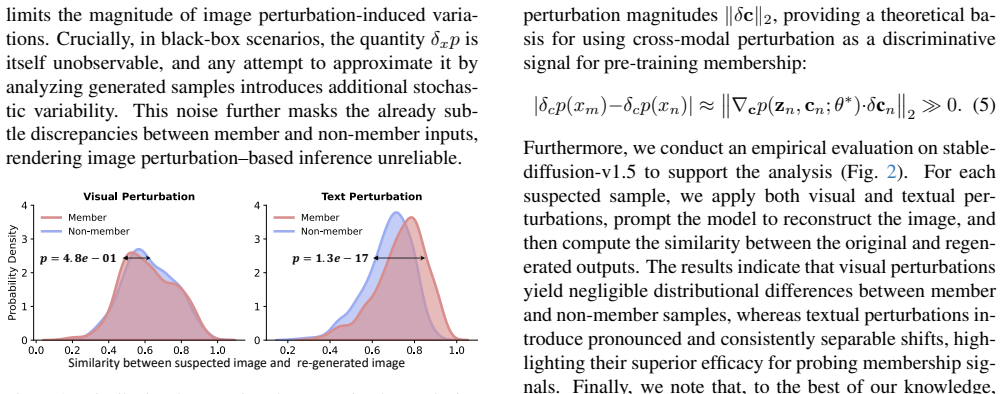
- [Experimental results] The manuscript provides no details on how the cross-modal perturbation mechanism is implemented or validated (e.g., choice of textual perturbations, aggregation of denoising signals, or comparison to image-only baselines on the new dataset), preventing assessment of whether the reported superiority is robust or an artifact of the evaluation setup.
minor comments (1)
- [Abstract] The abstract refers to 'a public benchmark dataset' without naming it or providing a citation, which reduces clarity for readers attempting to reproduce the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments below and will make revisions to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'SD-MIA achieves superior performance compared to existing baselines' is asserted without any quantitative metrics, tables, statistical tests, ablation studies, or error analysis. This absence is load-bearing because the paper's contribution rests on demonstrating that the cross-modal mechanism produces discriminative signals where image-only methods fail.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claim. In the revised version we will add concise performance metrics (e.g., AUC values and relative gains versus baselines on both datasets) while preserving length constraints. The full manuscript already contains the supporting tables, ablations, and error analysis in Sections 4 and 5; the abstract revision will simply preview these results. revision: yes
-
Referee: [Experimental results] The manuscript provides no details on how the cross-modal perturbation mechanism is implemented or validated (e.g., choice of textual perturbations, aggregation of denoising signals, or comparison to image-only baselines on the new dataset), preventing assessment of whether the reported superiority is robust or an artifact of the evaluation setup.
Authors: We will expand the experimental section with a dedicated subsection that explicitly describes the perturbation generation process (synonym replacement and paraphrasing of textual instructions), the aggregation of denoising signals (average L2 distance over selected timesteps), and additional direct comparisons against image-only baselines on the matched-distribution dataset. These elements are outlined in Sections 3.2 and 4 but will be elaborated with pseudocode and validation ablations for clarity. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical black-box membership inference attack (SD-MIA) based on cross-modal perturbations of images and text for diffusion models. Claims rest on experimental evaluation against baselines on public and constructed datasets with matched member/non-member distributions. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description that reduce the central results to inputs by construction. The work is self-contained as an empirical demonstration.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. 2023. 1, 6
2023
-
[2]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX Security Symposium, pages 2633–2650, 2021. 1
2021
-
[3]
Are diffusion models vulnerable to membership inference attacks? InProceedings of the 40th International Conference on Machine Learning, pages 8717–8730
Jinhao Duan, Fei Kong, Shiqi Wang, Xiaoshuang Shi, and Kaidi Xu. Are diffusion models vulnerable to membership inference attacks? InProceedings of the 40th International Conference on Machine Learning, pages 8717–8730. PMLR,
-
[4]
Towards more realistic membership inference attacks on large diffusion models
Jan Dubi ´nski, Antoni Kowalczuk, Stanisław Pawlak, Prze- myslaw Rokita, Tomasz Trzci ´nski, and Paweł Morawiecki. Towards more realistic membership inference attacks on large diffusion models. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 4860–4869, 2024. 1, 2, 5
2024
-
[5]
Cdi: Copyrighted data identification in dif- fusion models
Jan Dubi ´nski, Antoni Kowalczuk, Franziska Boenisch, and Adam Dziedzic. Cdi: Copyrighted data identification in dif- fusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18674–18684, 2025. 7
2025
-
[6]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InProceedings of the 41st International Conference on Ma- chine Learning, pages 12606–12633, 2024. 1, 6
2024
-
[7]
Unlocking generative priors: A new membership inference framework for diffusion models
Xiaomeng Fu, Xi Wang, Qiao Li, Jin Liu, Jiao Dai, Jizhong Han, and Xingyu Gao. Unlocking generative priors: A new membership inference framework for diffusion models. IEEE Transactions on Information Forensics and Security, 20:4638–4650, 2025. 1, 2, 3, 6, 8, 11
2025
-
[8]
Gemini 2.0 flash model card
Google DeepMind. Gemini 2.0 flash model card. Technical report, Google DeepMind, 2025. 6
2025
-
[9]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InProceedings of the 33rd Advances in Neural Information Processing Systems, pages 6840–6851, 2020. 2, 3
2020
-
[10]
Membership inference at- tacks on machine learning: A survey.ACM Computing Sur- veys, 54(11s):1–37, 2022
Hongsheng Hu, Zoran Salcic, Lichao Sun, Gillian Dobbie, Philip S Yu, and Xuyun Zhang. Membership inference at- tacks on machine learning: A survey.ACM Computing Sur- veys, 54(11s):1–37, 2022. 1
2022
-
[11]
Gpt-4o: The cutting-edge advancement in multimodal llm
Raisa Islam and Owana Marzia Moushi. Gpt-4o: The cutting-edge advancement in multimodal llm. InIntelli- gent Computing-Proceedings of the Computing Conference, pages 47–60. Springer, 2025. 6
2025
-
[12]
Copyright violations and large language models
Antonia Karamolegkou, Jiaang Li, Li Zhou, and Anders Søgaard. Copyright violations and large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7403–7412, 2023. 1
2023
-
[13]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
An efficient membership inference attack for the diffusion model by proximal initialization
Fei Kong, Jinhao Duan, RuiPeng Ma, Heng Tao Shen, Xi- aoshuang Shi, Xiaofeng Zhu, and Kaidi Xu. An efficient membership inference attack for the diffusion model by proximal initialization. InProceedings of the 12th Interna- tional Conference on Learning Representations, 2024. 1, 2, 11
2024
-
[15]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InPro- ceedings of the 40th International Conference on Machine Learning, pages 19730–19742. PMLR, 2023. 6, 8
2023
-
[16]
Towards black-box membership inference attack for diffu- sion models
Jingwei Li, Jing Dong, Tianxing He, and Jingzhao Zhang. Towards black-box membership inference attack for diffu- sion models. InProceedings of the 42nd International Con- ference on Machine Learning, 2025. 2, 11
2025
-
[17]
Unveiling structural memo- rization: Structural membership inference attack for text-to- image diffusion models
Qiao Li, Xiaomeng Fu, Xi Wang, Jin Liu, Xingyu Gao, Jiao Dai, and Jizhong Han. Unveiling structural memo- rization: Structural membership inference attack for text-to- image diffusion models. InProceedings of the 32nd ACM In- ternational Conference on Multimedia, pages 10554–10562,
-
[18]
Real-world benchmarks make membership inference attacks fail on diffusion models
Chumeng Liang and Jiaxuan You. Real-world benchmarks make membership inference attacks fail on diffusion models. arXiv preprint arXiv:2410.03640, 2024. 1, 2
-
[19]
Membership inference attacks against diffusion models
Tomoya Matsumoto, Takayuki Miura, and Naoto Yanai. Membership inference attacks against diffusion models. In 2023 IEEE Security and Privacy Workshops, pages 77–83. IEEE, 2023. 1, 2, 11
2023
-
[20]
Black-box membership infer- ence attacks against fine-tuned diffusion models
Yan Pang and Tianhao Wang. Black-box membership infer- ence attacks against fine-tuned diffusion models. InProceed- ings of Network and Distributed System Security Symposium,
-
[21]
White-box membership inference attacks against diffusion models
Yan Pang, Tianhao Wang, Xuhui Kang, Mengdi Huai, and Yang Zhang. White-box membership inference attacks against diffusion models. InProceedings on Privacy En- hancing Technologies, pages 398–415, 2025. 2
2025
-
[22]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PmLR, 2021. 6, 12
2021
-
[23]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 3, 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Vari- ational autoencoders pursue pca directions (by accident)
Michal Rolinek, Dominik Zietlow, and Georg Martius. Vari- ational autoencoders pursue pca directions (by accident). In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 12406–12415, 2019. 3
2019
-
[25]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 5
2022
-
[26]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 2, 3
2022
-
[27]
Copyright safety for generative ai.Hous
Matthew Sag. Copyright safety for generative ai.Hous. L. Rev., 61:295, 2023. 1
2023
-
[28]
Photorealistic text-to-image diffusion models with deep language understanding.In Proceedings of the 35th Advances in Neural Information Processing Systems, 35: 36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.In Proceedings of the 35th Advances in Neural Information Processing Systems, 35: 36479–36494, 2022. 1, 3, 11
2022
-
[29]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy, pages 3–18. IEEE, 2017. 1
2017
-
[30]
Aaditya Singh, Adam Fry, Adam Perelman, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Shengfang Zhai, Huanran Chen, Yinpeng Dong, Jiajun Li, Qingni Shen, Yansong Gao, Hang Su, and Yang Liu. Mem- bership inference on text-to-image diffusion models via con- ditional likelihood discrepancy.In Proceedings of the 37th Advances in Neural Information Processing Systems, 37: 74122–74146, 2024. 1, 2, 11
2024
-
[32]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 3, 11
2023
-
[33]
On copyright risks of text-to-image diffusion models
Yang Zhang, Teoh Tze Tzun, Lim Wei Hern, and Kenji Kawaguchi. On copyright risks of text-to-image diffusion models. InECCV 2024 Workshop The Dark Side of Genera- tive AIs and Beyond. 1
2024
-
[34]
Appendix 6.1. Preliminary Diffusion-based image generation models [23, 28, 32] aim to generate an imagex∈R H×W×3 conditioned on a text promptc, by learning the joint distributionp(x, c)or condi- tional distributionp(x|c)via a denoising diffusion process in either pixel or latent space. Formally, the forward diffu- sion process is defined as: q(zt|zt−1) =N...
2023
-
[35]
4) Ensure the output remains truthful and consis- tent with the original caption
Output only the new caption, no quotes or extra text. 4) Ensure the output remains truthful and consis- tent with the original caption. Prompt 2: style-view perturbation Rewrite the given image caption so that the content/- subject remains exactly the same, but change the artis- tic style of the image. Add only 1-2 style modifiers like ’photorealistic’, ’...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.