Attribute-Based Diagnosis of LLM Alignment with Hate Speech Annotations
Pith reviewed 2026-06-29 18:25 UTC · model grok-4.3
The pith
LLMs align with humans on explicit hate speech attributes but invert evaluative ones, and attribute regression reconstructs scores at R² 0.71
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
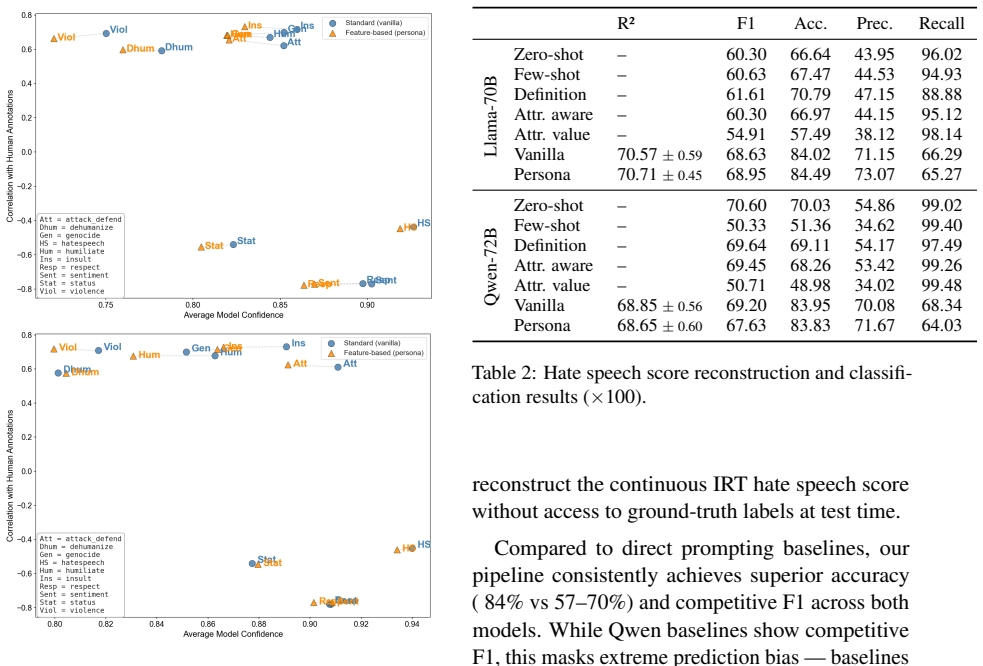
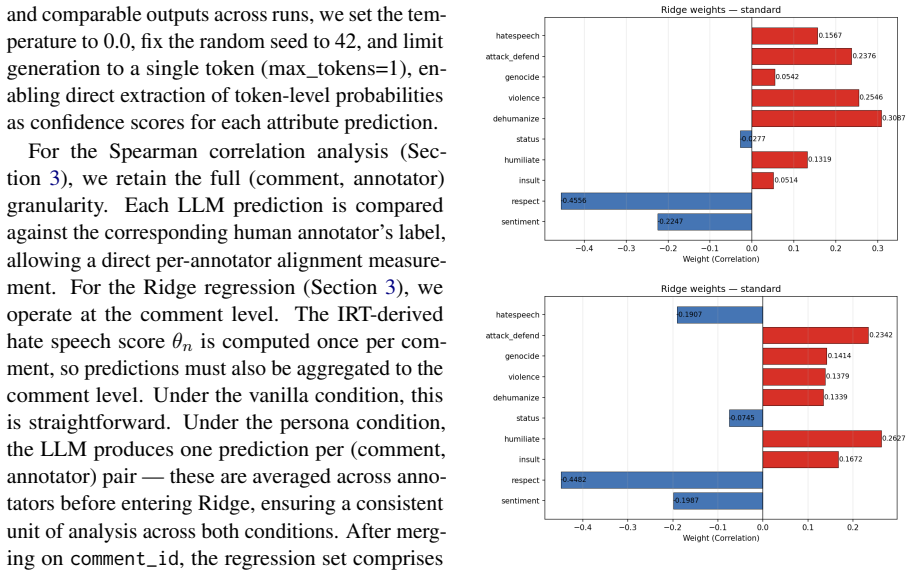
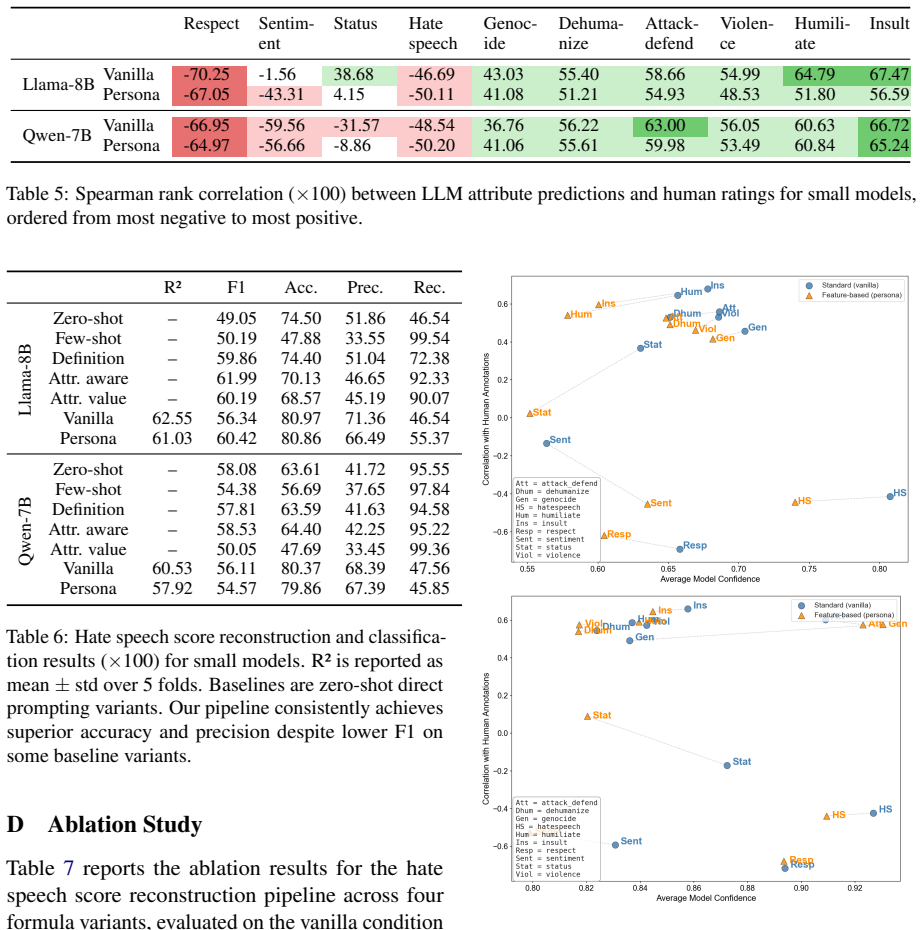
The central claim is that LLMs display reliable alignment with human annotators on behaviorally explicit attributes such as insult, humiliate, and attack-defend, yet produce inverted correlations on evaluative attributes such as respect, sentiment, and overall hate speech. Combining the ten attribute-level predictions from models including Llama 3.1 and Qwen 2.5 via confidence-weighted Ridge regression reconstructs continuous hate speech scores from the Measuring Hate Speech corpus at R² up to 0.71, outperforming direct end-to-end prompting baselines. Persona-based demographic conditioning reduces output confidence without raising alignment.
What carries the argument
Confidence-weighted Ridge regression that combines attribute-level LLM predictions to reconstruct continuous hate speech scores
If this is right
- Explicit behavioral attributes can be extracted reliably from LLMs for large-scale annotation support.
- Evaluative attributes require explicit correction because of systematic inversion.
- Attribute decomposition produces higher human alignment than direct prediction of the final hate speech label.
- The regression approach scales continuous score reconstruction without additional human labeling.
Where Pith is reading between the lines
- The same attribute decomposition could be tested on other subjective labeling tasks such as toxicity or misinformation where direct prompting also underperforms.
- The inversion pattern may point to a broader difference between how models and humans integrate social evaluation signals.
- Retraining or prompting strategies that target only the inverted attributes could be checked for downstream gains in overall alignment.
Load-bearing premise
The ten attributes fully capture the dimensions humans use to judge hate speech and the observed inversions on evaluative attributes reflect systematic model behavior rather than noise or prompt effects.
What would settle it
Re-annotating a held-out portion of the Measuring Hate Speech corpus with fresh human raters and finding that the new attribute correlations do not match the reported pattern or that the regression R² drops below direct-prompting performance.
Figures
read the original abstract
Hate speech annotation is costly, subjective, and prone to annotator disagreement, making large-scale dataset construction challenging. We systematically analyze how well large language models (LLMs) align with human judgments across ten theoretically grounded subjective attributes, such as dehumanization, violence, and sentiment, evaluating both small and large variants of Llama 3.1 and Qwen 2.5. Our analysis reveals a consistent split across all models: behaviorally explicit dimensions (insult, humiliate, attack-defend) correlate strongly with human annotations, while evaluative dimensions (respect, sentiment, hate speech) are systematically inverted. Demographic persona conditioning reduces model confidence without improving alignment. Building on these insights, we propose combining attribute-level LLM predictions via a confidence-weighted Ridge regression to reconstruct continuous hate speech scores from the Measuring Hate Speech corpus, achieving $R^2$ of up to 0.71 and outperforming direct prompting baselines, demonstrating that structured attribute decomposition recovers a richer and more human-aligned signal than end-to-end label prediction alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines LLM alignment with human hate speech annotations on the Measuring Hate Speech corpus using ten theoretically grounded attributes (e.g., dehumanization, violence, sentiment). It reports a consistent pattern across Llama 3.1 and Qwen 2.5 models where explicit behavioral attributes correlate positively with human labels while evaluative attributes are inverted. It then combines attribute-level predictions via confidence-weighted Ridge regression to reconstruct continuous hate speech scores, claiming R² up to 0.71 and superiority over direct prompting baselines.
Significance. If the reconstruction result is shown to be robust via held-out evaluation, the work would provide evidence that attribute decomposition can yield more human-aligned signals than direct end-to-end prediction on subjective tasks, with potential value for scalable annotation and LLM alignment diagnostics.
major comments (1)
- [Abstract] Abstract: the headline reconstruction result (R² up to 0.71 via confidence-weighted Ridge regression on the ten attribute predictions) is presented without any statement that the fit or evaluation used held-out instances, k-fold cross-validation, or a separate test partition. If the regression is performed and scored on the same Measuring Hate Speech corpus instances used for the attribute analysis and baseline comparisons, the reported lift may capture corpus-specific covariances rather than demonstrating generalizable out-of-sample reconstruction; this is the load-bearing step for the central claim that attribute decomposition recovers a richer human-aligned signal.
minor comments (2)
- [Abstract] Abstract: the ten attributes are described only by examples; a complete enumerated list with precise operational definitions would aid reproducibility.
- [Abstract] Abstract: no details are given on how model confidence is quantified or how the weighting is implemented in the Ridge regression.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the need for explicit clarification on the evaluation of the reconstruction result. We address this point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline reconstruction result (R² up to 0.71 via confidence-weighted Ridge regression on the ten attribute predictions) is presented without any statement that the fit or evaluation used held-out instances, k-fold cross-validation, or a separate test partition. If the regression is performed and scored on the same Measuring Hate Speech corpus instances used for the attribute analysis and baseline comparisons, the reported lift may capture corpus-specific covariances rather than demonstrating generalizable out-of-sample reconstruction; this is the load-bearing step for the central claim that attribute decomposition recovers a richer human-aligned signal.
Authors: We agree that the abstract should explicitly state the evaluation procedure. The full manuscript describes the confidence-weighted Ridge regression as evaluated via 5-fold cross-validation on held-out folds of the Measuring Hate Speech corpus (ensuring the R² reflects out-of-sample performance rather than in-sample fit). We will revise the abstract to include this detail (e.g., 'achieving R² of up to 0.71 via 5-fold cross-validation') so that the headline result accurately conveys the held-out nature of the evaluation. This directly addresses the concern about generalizability while preserving the comparison to baselines, which were also assessed under the same protocol. revision: yes
Circularity Check
Ridge regression R² on Measuring Hate Speech corpus is in-sample fit, not independent reconstruction
specific steps
-
fitted input called prediction
[Abstract]
"we propose combining attribute-level LLM predictions via a confidence-weighted Ridge regression to reconstruct continuous hate speech scores from the Measuring Hate Speech corpus, achieving R² of up to 0.71 and outperforming direct prompting baselines"
The regression is fit to attribute scores and hate-speech targets from the identical corpus; the R² therefore measures how well the fitted linear combination reproduces the training targets rather than demonstrating generalization or independent predictive power.
full rationale
The central reconstruction result (R² up to 0.71) is obtained by fitting a confidence-weighted Ridge regression directly to attribute predictions and continuous targets drawn from the same Measuring Hate Speech corpus. No description of held-out partitions, k-fold CV, or separate test set is provided in the abstract or methods summary, so the reported metric reduces to the in-sample goodness-of-fit of the regression rather than an out-of-sample prediction. This matches the fitted_input_called_prediction pattern and is load-bearing for the claim that attribute decomposition outperforms direct prompting.
Axiom & Free-Parameter Ledger
free parameters (1)
- Ridge regression regularization strength
axioms (1)
- domain assumption Human annotations on the ten attributes constitute the correct reference for measuring LLM alignment
Reference graph
Works this paper leans on
-
[1]
O zge Alacam, Sanne Hoeken, Andreas S \
\"O zge Alacam, Sanne Hoeken, Andreas S \"a uberli, Hannes Gr \"o ner, Diego Frassinelli, Sina Zarrie , and Barbara Plank. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1460 Disentangling subjectivity and uncertainty for hate speech annotation and modeling using gaze . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Proc...
-
[2]
Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting, and David Wingate. 2023. https://doi.org/10.1017/pan.2023.2 Out of one, many: Using language models to simulate human samples . Political Analysis, 31(3):337–351
- [3]
-
[4]
Georgios Chochlakis, Alexandros Potamianos, Kristina Lerman, and Shrikanth Narayanan. 2025. https://doi.org/10.18653/v1/2025.naacl-long.284 Aggregation artifacts in subjective tasks collapse large language models' posteriors . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Hum...
-
[5]
Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.88 Toxicity in chatgpt: Analyzing persona-assigned language models . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1236--1270, Singapore. Association for Computational Linguistics
-
[6]
Neele Falk and Gabriella Lapesa. 2025. https://doi.org/10.18653/v1/2025.acl-long.1116 Mining the uncertainty patterns of humans and models in the annotation of moral foundations and human values . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22898--22921, Vienna, Austria. Associa...
-
[7]
Faeze Ghorbanpour, Daryna Dementieva, and Alexander Fraser. 2025 a . https://doi.org/10.18653/v1/2025.emnlp-main.1507 Data-efficient hate speech detection via cross-lingual nearest neighbor retrieval with limited labeled data . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29674--29692, Suzhou, China. Ass...
-
[8]
Faeze Ghorbanpour, Viktor Hangya, and Alexander Fraser. 2025 b . https://doi.org/10.18653/v1/2025.naacl-long.551 Fine-grained transfer learning for harmful content detection through label-specific soft prompt tuning . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Langua...
-
[9]
Fabrizio Gilardi, Meysam Alizadeh, and Ma \"e l Kubli. 2023. Chatgpt outperforms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences, 120(30):e2305016120
2023
-
[10]
Tommaso Giorgi, Lorenzo Cima, Tiziano Fagni, Marco Avvenuti, and Stefano Cresci. 2025. Human and llm biases in hate speech annotations: A socio-demographic analysis of annotators and targets. In Proceedings of the International AAAI Conference on Web and Social Media, volume 19, pages 653--670
2025
-
[11]
Kristina Gligori \'c , Tijana Zrnic, Cinoo Lee, Emmanuel Cand \`e s, and Dan Jurafsky. 2025. https://doi.org/10.18653/v1/2025.naacl-long.179 Can unconfident LLM annotations be used for confident conclusions? In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technol...
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Tiancheng Hu and Nigel Collier. 2024. https://doi.org/10.18653/v1/2024.acl-long.554 Quantifying the persona effect in LLM simulations . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10289--10307, Bangkok, Thailand. Association for Computational Linguistics
-
[14]
Chris J Kennedy, Geoff Bacon, Alexander Sahn, and Claudia von Vacano. 2020. Constructing interval variables via faceted rasch measurement and multitask deep learning: a hate speech application. arXiv preprint arXiv:2009.10277
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611--626
2023
-
[16]
Nayeon Lee, Chani Jung, Junho Myung, Jiho Jin, Jose Camacho-Collados, Juho Kim, and Alice Oh. 2024. https://doi.org/10.18653/v1/2024.naacl-long.236 Exploring cross-cultural differences in E nglish hate speech annotations: From dataset construction to analysis . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Comp...
-
[17]
Junyu Lu, Kai Ma, Kaichun Wang, Kelaiti Xiao, Roy Ka-Wei Lee, Bo Xu, Liang Yang, and Hongfei Lin. 2025. Is llm an overconfident judge? unveiling the capabilities of llms in detecting offensive language with annotation disagreement. In Findings of the Association for Computational Linguistics: ACL 2025, pages 5609--5626
2025
-
[18]
Aida Mostafazadeh Davani, Mark D \'i az, and Vinodkumar Prabhakaran. 2022. https://doi.org/10.1162/tacl_a_00449 Dealing with disagreements: Looking beyond the majority vote in subjective annotations . Transactions of the Association for Computational Linguistics, 10:92--110
-
[19]
Bhaktipriya Radharapu, Manon Revel, Megan Ung, Sebastian Ruder, and Adina Williams. 2025. https://doi.org/10.18653/v1/2025.findings-acl.243 Arbiters of ambivalence: Challenges of using LLM s in no-consensus tasks . In Findings of the Association for Computational Linguistics: ACL 2025, pages 4677--4731, Vienna, Austria. Association for Computational Linguistics
-
[20]
Pratik Sachdeva, Renata Barreto, Geoff Bacon, Alexander Sahn, Claudia Von Vacano, and Chris Kennedy. 2022 a . The measuring hate speech corpus: Leveraging rasch measurement theory for data perspectivism. In Proceedings of the 1st Workshop on Perspectivist Approaches to NLP@ LREC2022, pages 83--94
2022
-
[21]
Pratik S Sachdeva, Renata Barreto, Claudia von Vacano, and Chris J Kennedy. 2022 b . Assessing annotator identity sensitivity via item response theory: A case study in a hate speech corpus. In Proceedings of the 2022 ACM conference on fairness, accountability, and transparency, pages 1585--1603
2022
-
[22]
Maarten Sap, Swabha Swayamdipta, Laura Vianna, Xuhui Zhou, Yejin Choi, and Noah A. Smith. 2022. https://doi.org/10.18653/v1/2022.naacl-main.431 Annotators with attitudes: How annotator beliefs and identities bias toxic language detection . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:...
-
[23]
o rg Schl \
Olufunke Sarumi, Charles Welch, Daniel Braun, and J \"o rg Schl \"o tterer. 2025. The impact of annotator personas on llm behavior across the perspectivism spectrum. In Proceedings of the 8th International Conference on Natural Language and Speech Processing (ICNLSP-2025), pages 121--136
2025
-
[24]
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, and Huan Liu. 2024. Large language models for data annotation and synthesis: A survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 930--957
2024
-
[25]
Zeerak Waseem and Dirk Hovy. 2016. https://doi.org/10.18653/v1/N16-2013 Hateful symbols or hateful people? predictive features for hate speech detection on T witter . In Proceedings of the NAACL Student Research Workshop , pages 88--93, San Diego, California. Association for Computational Linguistics
-
[26]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. https://doi.org/10.18653/v1...
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[29]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.