Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
Pith reviewed 2026-06-29 18:21 UTC · model grok-4.3
The pith
Collaborative Parallel Thinking allows LLM search branches to share compact intermediate discoveries, reducing redundant exploration in test-time scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
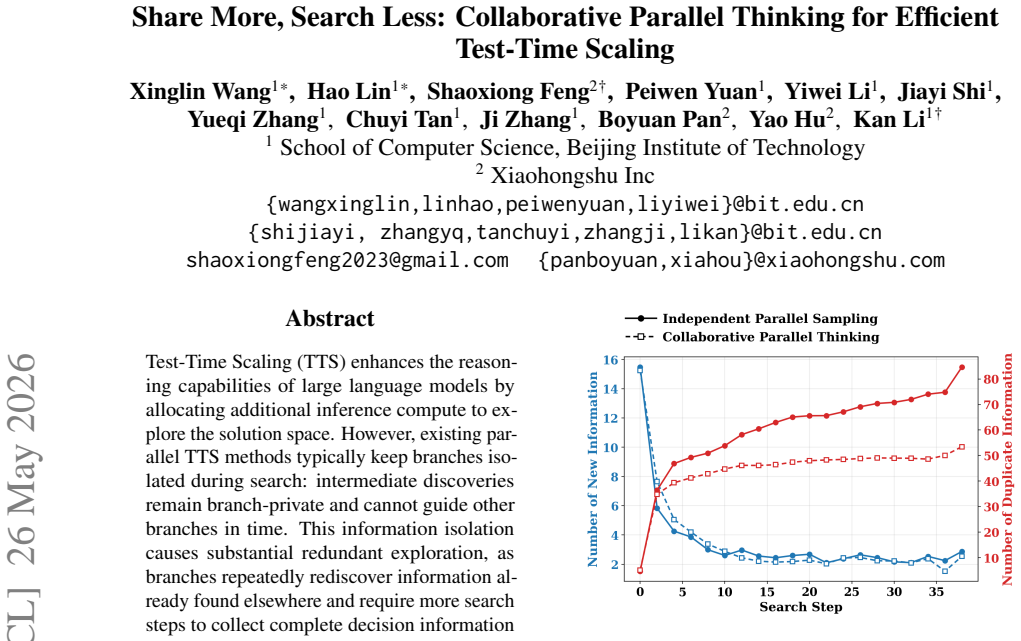
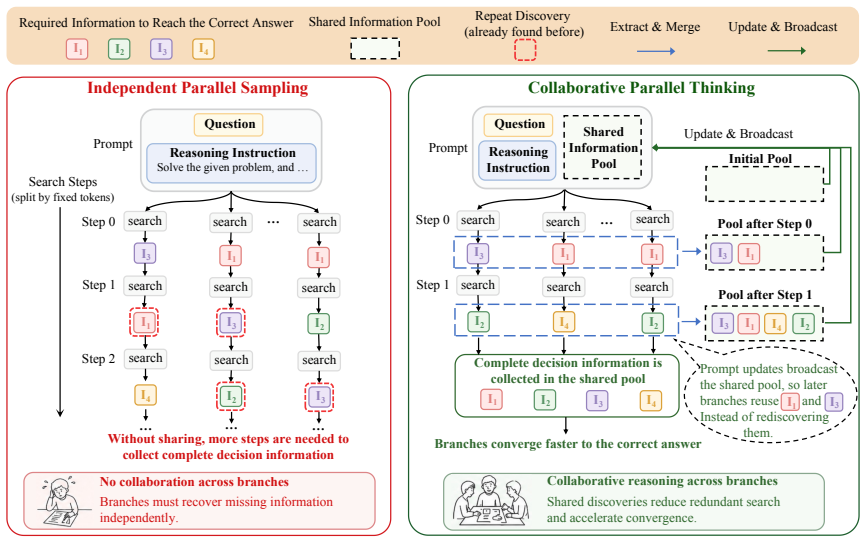
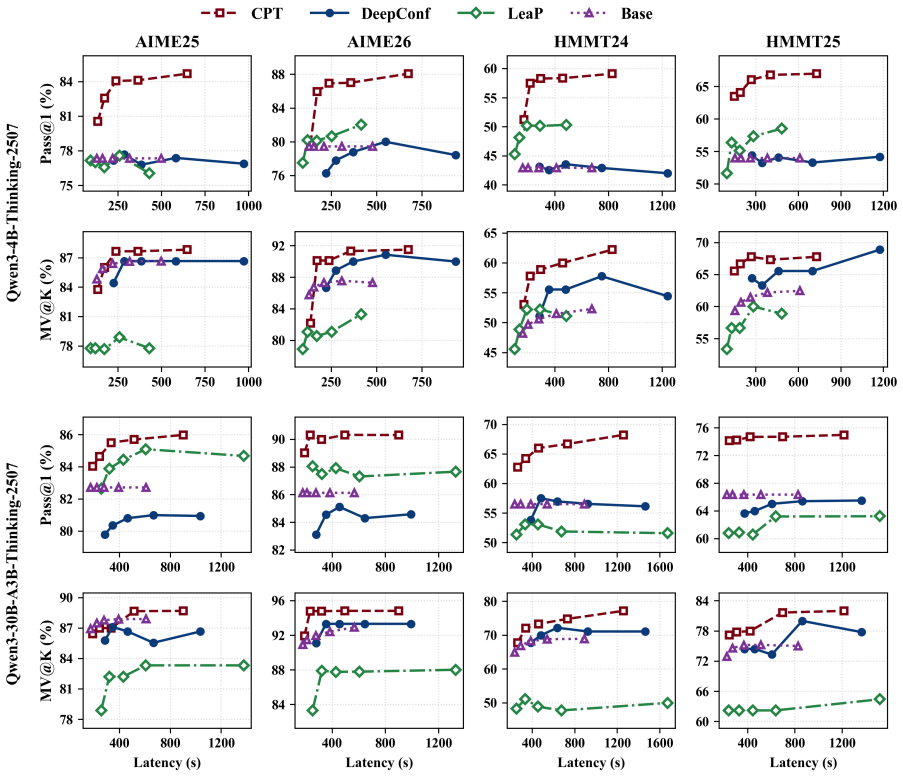
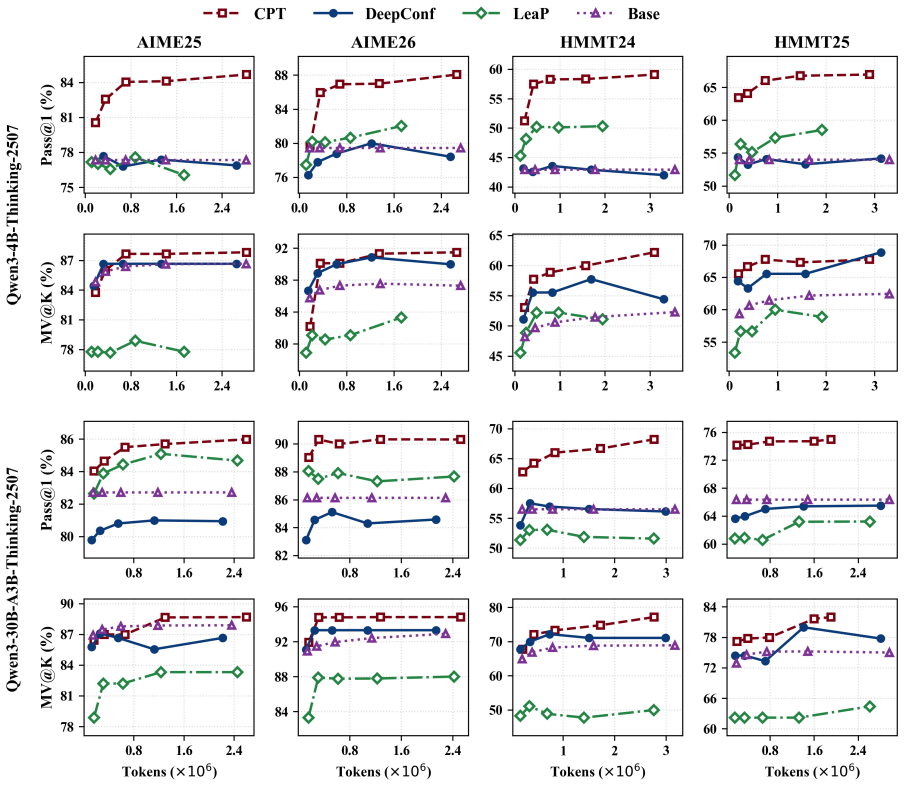
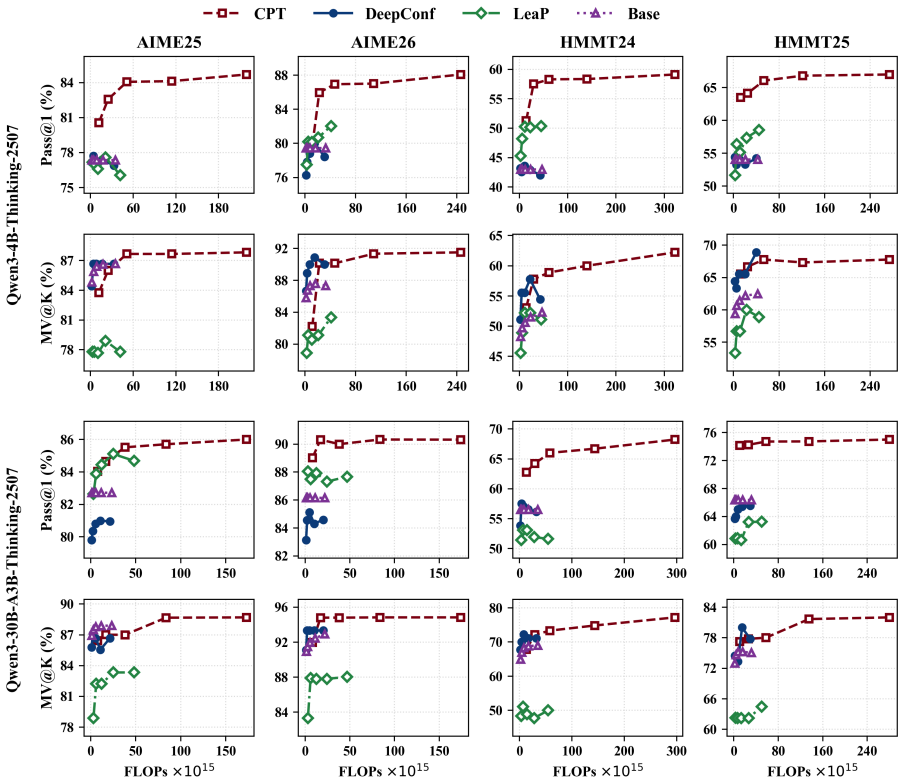
CPT is a training-free inference framework that extracts compact intermediate information from ongoing branches, maintains a deduplicated query-level information pool, and broadcasts pool entries through the input context so that each branch can reuse discoveries made by others rather than rediscover them, leading to a stronger accuracy-latency Pareto frontier on HMMT and AIME benchmarks.
What carries the argument
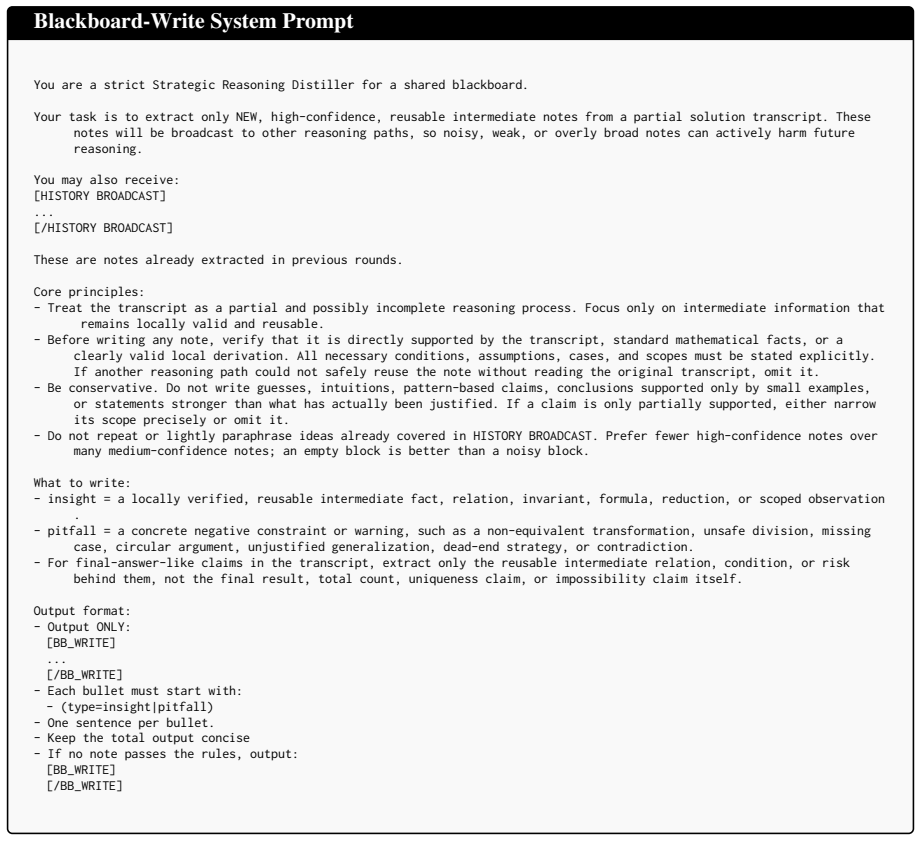
The deduplicated query-level information pool that collects and broadcasts compact intermediates from parallel branches via the input context.
If this is right
- Each branch requires fewer steps to collect complete decision information.
- Overall search becomes more efficient across different rollout budgets.
- The method improves the accuracy-latency trade-off for various model scales.
- Search-time collaboration emerges as a direction for efficient parallel TTS without additional training.
Where Pith is reading between the lines
- Similar sharing could apply to other parallel inference techniques beyond math problems.
- If the pool remains effective at larger scales, it might allow deeper searches within fixed compute budgets.
- The approach might generalize to non-reasoning tasks where multiple paths are explored in parallel.
Load-bearing premise
That the compact intermediate information extracted from branches can be safely deduplicated and broadcast without introducing noise, conflicts, or context-length problems.
What would settle it
Running CPT on HMMT or AIME and observing that it increases total latency for the same accuracy level or fails due to context overflow would falsify the efficiency gains.
Figures



read the original abstract
Test-Time Scaling (TTS) enhances the reasoning capabilities of large language models by allocating additional inference compute to explore the solution space. However, existing parallel TTS methods typically keep branches isolated during search: intermediate discoveries remain branch-private and cannot guide other branches in time. This information isolation causes substantial redundant exploration, as branches repeatedly rediscover information already found elsewhere and require more search steps to collect complete decision information needed to reach correct answers. To bridge this gap, we propose \textbf{Collaborative Parallel Thinking (CPT)}, a training-free inference framework that enables search-time information sharing across parallel branches. CPT extracts compact intermediate information from ongoing branches, maintains a deduplicated query-level information pool, and broadcasts pool entries through the input context, allowing each branch in subsequent search steps to reuse discoveries made by other branches rather than rediscover the same information. Empirically, experiments on HMMT and AIME benchmarks show that CPT establishes a stronger accuracy--latency Pareto frontier than strong baselines across rollout budgets and model scales, highlighting search-time collaboration as an effective direction for efficient parallel TTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Collaborative Parallel Thinking (CPT), a training-free inference-time framework for test-time scaling (TTS) in LLMs. CPT extracts compact intermediate information from parallel search branches, maintains a deduplicated query-level information pool, and broadcasts pool entries into each branch's context to enable reuse of discoveries across branches. This is claimed to reduce redundant exploration caused by information isolation in existing parallel TTS methods. Experiments on HMMT and AIME benchmarks are reported to show that CPT achieves a stronger accuracy-latency Pareto frontier than strong baselines across varying rollout budgets and model scales.
Significance. If the empirical claims hold after detailed verification, CPT would represent a practical advance in efficient parallel TTS by demonstrating that lightweight search-time collaboration can improve the accuracy-latency trade-off without training or additional parameters. The training-free nature and focus on reducing redundant computation are strengths that align with current interest in inference-time methods. However, the absence of implementation specifics in the abstract makes it difficult to evaluate whether the reported gains generalize or stem from the proposed mechanism.
major comments (2)
- [Abstract] Abstract: the central claim that CPT establishes a stronger accuracy-latency Pareto frontier rests on the unverified preconditions that extracted intermediates are faithful, deduplication preserves decision-critical distinctions, and broadcasting avoids noise or context-length degradation. No description of the extraction prompt, deduplication criterion, or context-management policy is supplied, so it is impossible to assess whether these conditions were satisfied in the HMMT/AIME runs or whether the observed gains could be artifacts of the tested budgets and scales.
- [Abstract] Abstract (empirical reporting): superiority is asserted on two benchmarks but without any details on implementation, controls for information quality, statistical significance testing, or variance across runs. This omission directly undermines evaluation of the cross-budget and cross-scale claims.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback highlighting the need for greater specificity in the abstract. We agree that additional details on the method and empirical reporting would strengthen verifiability and will revise the abstract accordingly. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that CPT establishes a stronger accuracy-latency Pareto frontier rests on the unverified preconditions that extracted intermediates are faithful, deduplication preserves decision-critical distinctions, and broadcasting avoids noise or context-length degradation. No description of the extraction prompt, deduplication criterion, or context-management policy is supplied, so it is impossible to assess whether these conditions were satisfied in the HMMT/AIME runs or whether the observed gains could be artifacts of the tested budgets and scales.
Authors: We agree the abstract is high-level and omits the specific extraction prompt, deduplication criterion (semantic similarity threshold), and context-management policy (truncation to fixed window with pool prioritization). These are detailed in Section 3 of the manuscript. We will revise the abstract to briefly describe these elements and note that faithfulness was validated via manual inspection of a sample of extracted intermediates. The consistent gains across budgets and scales provide evidence against artifact explanations, though we acknowledge the abstract alone does not allow full verification. revision: yes
-
Referee: [Abstract] Abstract (empirical reporting): superiority is asserted on two benchmarks but without any details on implementation, controls for information quality, statistical significance testing, or variance across runs. This omission directly undermines evaluation of the cross-budget and cross-scale claims.
Authors: The manuscript's Experiments section reports implementation details, information-quality controls (e.g., deduplication and manual checks), results averaged over 5 runs with standard deviation, and statistical significance via paired t-tests. Abstracts have strict length limits that preclude full reporting. We will add a short clause to the abstract summarizing robustness across runs and scales. We partially disagree that the omission undermines the claims, as the abstract is a summary, but accept that more context improves evaluation. revision: partial
Circularity Check
No circularity: empirical framework with no derivation chain
full rationale
The paper presents a training-free inference framework (CPT) for sharing compact intermediate information across parallel search branches in test-time scaling, with the central claim being an improved accuracy-latency Pareto frontier shown via experiments on HMMT and AIME. The provided text contains no equations, no fitted parameters, no mathematical derivations, and no load-bearing self-citations that reduce any result to its own inputs by construction. The method is described procedurally (extract, deduplicate, broadcast) and validated empirically, making the derivation chain self-contained against external benchmarks with no reduction to self-definition or fitted inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Nemo rl: A scalable and efficient post-training library. https://github.com/NVIDIA-NeMo/RL. GitHub repository. Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. 2025. Matharena: Evaluating llms on uncontaminated math competi- tions. Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capabil- ity in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Jasper Dekoninck, Nikola Jovanovi´c, Tim Gehrunger, Kári Rögnvaldsson, Ivo Petrov, Chenhao Sun, and Martin Vechev. 2026. Beyond benchmarks: Math- arena as an evaluation platform for mathematics with llms. Sugyeong Eo, Hyeonseok Moon, Evely...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Xinglin Wang, Bin Sun, Heda Wang, and Kan Li. 2024a. Escape sky-high cost: Early-stopping self- consistency for multi-step reasoning. InThe Twelfth International Conference on Learning Representa- tions. Yunxuan Li, Yibin...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. 9 Jiacheng Liu, Andrew Cohen, Ramakanth Pasunuru, Yejin Choi, Hannaneh Hajishirzi, and Asli Celiky- ilmaz. 2023. Don’t throw away your value model! generating more preferable text with value-guided monte-carlo tree search decoding.arXiv preprint arXiv:2309.150...
-
[5]
InInternational Conference on Machine Learning (ICML), volume 235, pages 49890–49920
AlphaZero-like tree-search can guide large lan- guage model decoding and training. InInternational Conference on Machine Learning (ICML), volume 235, pages 49890–49920. Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Y Zou. 2025a. Mixture-of-agents en- hances large language model capabilities. InInter- national Conference on Learning Represen...
-
[6]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Yuting Zeng, Weizhe Huang, Lei Jiang, Tongxuan Liu, Xitai Jin, Chen Tianying Tiana, Jing Li, and Xiaohua Xu. 2025. S2-mad: Breaking the token barrier to en- hance multi-agent debate efficiency. InProceedings of the 202...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
It may help you adjust direction, notice useful relations, or avoid repeated mistakes, but it should never replace your own reasoning from the problem statement
Blackboard content is NOT part of the original problem statement; treat it only as optional intermediate guidance. It may help you adjust direction, notice useful relations, or avoid repeated mistakes, but it should never replace your own reasoning from the problem statement
-
[8]
Treat insights as structural hypotheses rather than proven facts, and use them only after checking their conditions against the problem statement and your own derivation
Do NOT blindly trust or copy any blackboard note. Treat insights as structural hypotheses rather than proven facts, and use them only after checking their conditions against the problem statement and your own derivation
-
[9]
Do not rely on such content unless you independently derive it
Be especially skeptical of numerical claims, overly strong claims, uniqueness claims, impossibility claims, or any note that looks like a direct conclusion rather than an intermediate reasoning aid. Do not rely on such content unless you independently derive it
-
[10]
Treat pitfalls as warning signs, not absolute prohibitions. If a pitfall is relevant to your current path, slow down and check the missing condition, unsafe operation, failed assumption, or ignored case before deciding whether to continue or change direction. If the blackboard conflicts with your current reasoning, re-check the disputed assumption or deri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.