Large Language Model-Powered Query-Driven Event Timeline Summarization in Industrial Search
Pith reviewed 2026-06-29 18:01 UTC · model grok-4.3
The pith
Domain-specific fine-tuning lets a 7B model match a 671B model's performance on query-driven event timelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
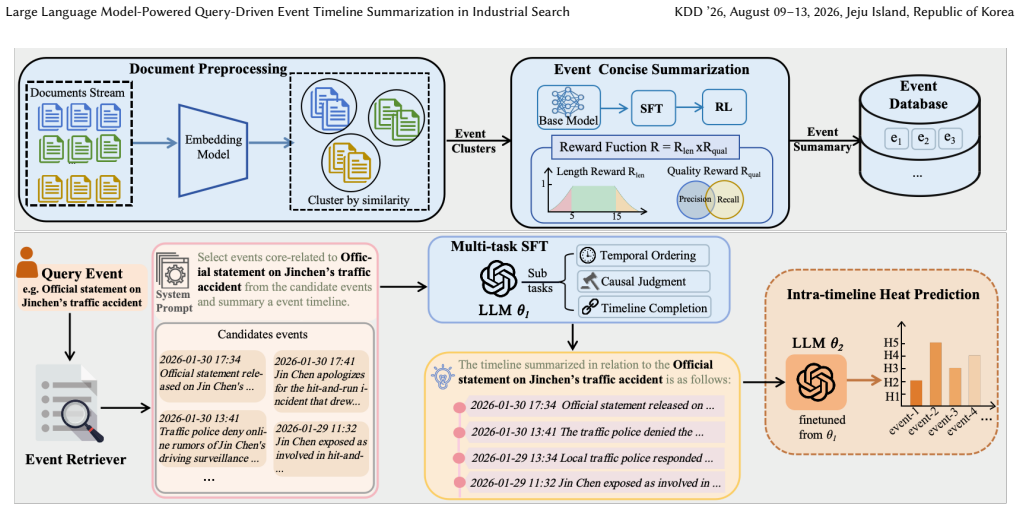
Multi-task supervised fine-tuning with temporal ordering, causal judgment, and timeline completion auxiliary tasks, combined with reinforcement learning for concise summarization, enables a 7B-parameter model to achieve 76.2% F1 on timeline summarization, slightly above the 76.1% F1 of a 671B model while using 1% of the parameters, and produces 5.5% CTR improvement plus 4.6% longer dwell time in live search traffic.
What carries the argument
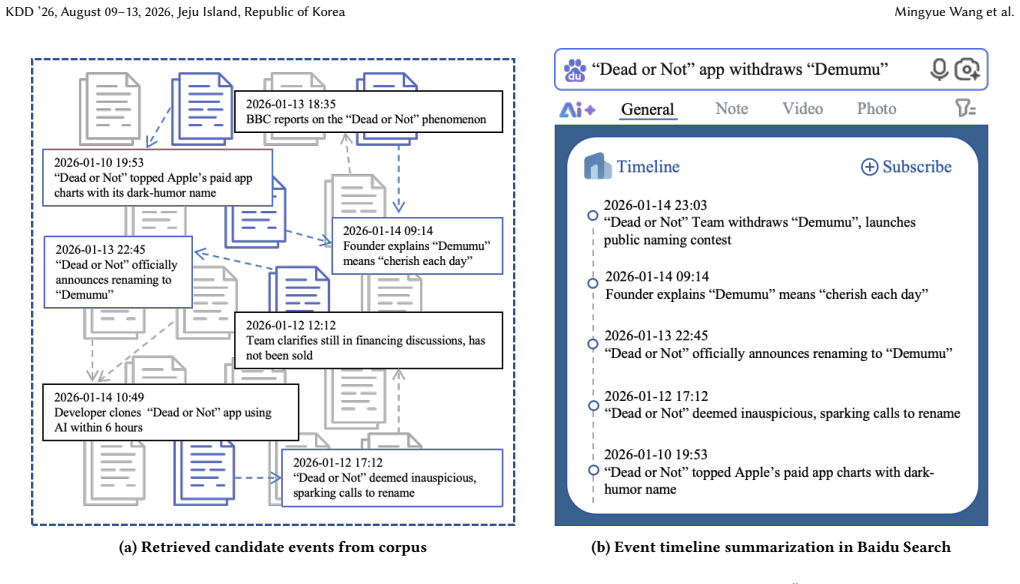
Multi-task supervised fine-tuning on three auxiliary tasks (temporal ordering, causal judgment, timeline completion) that transfers general capabilities to query-specific timeline construction from large noisy document sets.
If this is right
- Production search systems can deploy timeline features at far lower compute cost while meeting strict length constraints at 88.2% compliance.
- Timeline representations learned this way transfer directly to downstream tasks such as heat prediction.
- Online A/B tests confirm 4.4% deeper user exploration compared with single-task baselines.
Where Pith is reading between the lines
- The same auxiliary-task pattern could be tested on other industrial tasks that require temporal reasoning from noisy text streams.
- If the auxiliary tasks prove portable, similar compact models might reduce overall energy use for repeated inference in high-volume search applications.
Load-bearing premise
The three auxiliary tasks are what allow the small model to reach the performance level of the much larger general model rather than data selection or other training details.
What would settle it
Train the same 7B model on only the main timeline task without the three auxiliary tasks and measure whether its F1 on the summarization benchmark falls below 76.1%.
Figures
read the original abstract
Understanding how events evolve over time is essential for search engines handling queries about trending news. We present QDET (Query-Driven Event Timeline Summarization), a production system deployed on Baidu Search that constructs focused event timelines to explain specific query events. Unlike traditional topic-centric approaches that aim for comprehensive coverage, QDET identifies and organizes sub-events closely relevant to the query from noisy candidate sets formed by millions of documents retrieved daily. QDET incorporates two key innovations: (1) multi-task supervised fine-tuning with three auxiliary tasks-temporal ordering, causal judgment, and timeline completion-that enable compact models to match the performance of much larger general-purpose models in specialized domains; (2) reinforcement learning-based event concise summarization that enforces strict length constraints while maintaining semantic quality, achieving 88.2% length compliance and outperforming 671B-scale models by 7.7 points in constraint satisfaction. Our fine-tuned 7B parameter model achieves 76.2% F1 score on timeline summarization, slightly surpassing the zero-shot performance of DeepSeek-R1-671B (76.1% F1) while using only 1% of its parameters-demonstrating that domain-specific optimization enables production-ready models with comparable quality at drastically reduced computational costs. Online A/B tests on Baidu Search validate real-world effectiveness, showing 5.5% CTR improvement, 4.6% longer dwell time, and 4.4% deeper exploration compared to single-task baselines. We further demonstrate that timeline understanding transfers to heat prediction, confirming effective knowledge transfer to downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces QDET, a production-deployed system on Baidu Search for query-driven event timeline summarization from noisy document sets. It proposes two innovations: (1) multi-task supervised fine-tuning of a 7B model on the primary timeline task plus three auxiliary tasks (temporal ordering, causal judgment, timeline completion) claimed to enable compact models to match much larger general-purpose LLMs, and (2) RL-based summarization enforcing length constraints. The fine-tuned 7B model reports 76.2% F1 on timeline summarization, marginally above DeepSeek-R1-671B zero-shot at 76.1% F1; RL achieves 88.2% length compliance. Online A/B tests report 5.5% CTR lift, 4.6% longer dwell time, and 4.4% deeper exploration versus single-task baselines, with transfer shown to heat prediction.
Significance. If the central performance claims hold after proper controls, the work would demonstrate that domain-specific multi-task optimization can yield production-viable compact models for specialized search tasks at ~1% the parameter count of frontier models, with direct industrial impact via A/B-validated metrics and downstream transfer. The real-world deployment and A/B testing constitute a strength for applied NLP research.
major comments (2)
- [Abstract and Experimental Evaluation] Abstract and results on multi-task SFT: the headline claim that the three auxiliary tasks (temporal ordering, causal judgment, timeline completion) enable the 7B model to match 671B zero-shot performance is not isolated from generic domain adaptation. No ablation is reported comparing the multi-task 7B model against a 7B model fine-tuned solely on the primary timeline task using the same domain data, nor against the 671B model after identical fine-tuning; the 0.1-point F1 delta is therefore compatible with non-specific adaptation rather than the auxiliary-task construction.
- [Online A/B Tests] Online A/B tests section: the reported lifts (5.5% CTR, 4.6% dwell time, 4.4% exploration) lack any description of test duration, traffic allocation, statistical significance testing, or controls for production confounds, which directly undermines support for the real-world effectiveness claim tied to the proposed method.
minor comments (2)
- [Reinforcement Learning Component] The RL reward formulation and length-constraint enforcement mechanism are described at high level only; a precise statement of the reward components and how they interact with the 88.2% compliance metric would improve reproducibility.
- [Results] Table or figure presenting the F1 scores should include confidence intervals or standard deviations across runs to allow assessment of the 76.2% vs 76.1% comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on isolating the auxiliary tasks' contribution and strengthening the online evaluation details. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract and Experimental Evaluation] Abstract and results on multi-task SFT: the headline claim that the three auxiliary tasks (temporal ordering, causal judgment, timeline completion) enable the 7B model to match 671B zero-shot performance is not isolated from generic domain adaptation. No ablation is reported comparing the multi-task 7B model against a 7B model fine-tuned solely on the primary timeline task using the same domain data, nor against the 671B model after identical fine-tuning; the 0.1-point F1 delta is therefore compatible with non-specific adaptation rather than the auxiliary-task construction.
Authors: We agree that an ablation isolating the auxiliary tasks from single-task domain adaptation on the same data would more rigorously support the specific role of the three auxiliary tasks. The current results focus on the practical outcome that multi-task fine-tuning allows the 7B model to match the zero-shot 671B model while also showing production gains over single-task baselines in A/B tests. In the revision we will add an ablation comparing the multi-task 7B model to a 7B model fine-tuned solely on the primary timeline task using identical data and hyperparameters. Fine-tuning the 671B model is computationally prohibitive; we will explicitly note this limitation and its implications for the comparison. revision: yes
-
Referee: [Online A/B Tests] Online A/B tests section: the reported lifts (5.5% CTR, 4.6% dwell time, 4.4% exploration) lack any description of test duration, traffic allocation, statistical significance testing, or controls for production confounds, which directly undermines support for the real-world effectiveness claim tied to the proposed method.
Authors: We acknowledge that the online evaluation section requires additional methodological details to substantiate the reported lifts. In the revised manuscript we will expand this section to specify test duration, traffic allocation (e.g., percentage split), statistical significance testing (including p-values), and controls for production confounds such as query distribution shifts and temporal effects. These additions will directly address the concern and strengthen the evidence for real-world effectiveness. revision: yes
Circularity Check
No significant circularity; empirical results rest on external benchmarks
full rationale
The paper reports measured F1 scores, length compliance, and online A/B metrics from a fine-tuned 7B model, directly compared against the zero-shot performance of an external 671B model (DeepSeek-R1) and real-world CTR/dwell-time lifts. These external references and production deployment data are independent of the training procedure itself. No equations, self-citations, or fitted parameters are presented as derivations that reduce to the inputs by construction; the auxiliary-task construction is an empirical design choice whose contribution is evaluated via held-out and live metrics rather than tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A temporally sensitive submodularity framework for timeline summarization
Sebastian Martschat and Katja Markert. A temporally sensitive submodularity framework for timeline summarization. In Anna Korhonen and Ivan Titov, editors, Proceedings of the 22nd Conference on Computational Natural Language Learning, pages 230–240, Brussels, Belgium, October 2018. Association for Computational Linguistics
2018
-
[2]
Timeline summarization based on event graph compression via time- aware optimal transport
Manling Li, Tengfei Ma, Mo Yu, Lingfei Wu, Tian Gao, Heng Ji, and Kathleen McKeown. Timeline summarization based on event graph compression via time- aware optimal transport. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6443–6456, 2021
2021
-
[3]
Summpip: Unsupervised multi-document summariza- tion with sentence graph compression
Jinming Zhao, Ming Liu, Longxiang Gao, Yuan Jin, Lan Du, He Zhao, He Zhang, and Gholamreza Haffari. Summpip: Unsupervised multi-document summariza- tion with sentence graph compression. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, page 1949–1952. ACM, 2020
1949
-
[4]
Abstractive timeline summarization
Julius Steen and Katja Markert. Abstractive timeline summarization. In Lu Wang, Jackie Chi Kit Cheung, Giuseppe Carenini, and Fei Liu, editors,Proceedings of the 2nd Workshop on New Frontiers in Summarization, pages 21–31, Hong Kong, China, November 2019. Association for Computational Linguistics
2019
-
[5]
From moments to milestones: In- cremental timeline summarization leveraging large language models
Qisheng Hu, Geonsik Moon, and Hwee Tou Ng. From moments to milestones: In- cremental timeline summarization leveraging large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7232–7246, Bangkok, Thailand, August 2...
2024
-
[6]
Predicting salient updates for disaster summarization
Chris Kedzie, Kathleen McKeown, and Fernando Diaz. Predicting salient updates for disaster summarization. InProceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1608–1617, 2015
2015
-
[7]
Event timeline generation from history textbooks
Harsimran Bedi, Sangameshwar Patil, Swapnil Hingmire, and Girish Palshikar. Event timeline generation from history textbooks. In Yuen-Hsien Tseng, Hsin-Hsi Chen, Lung-Hao Lee, and Liang-Chih Yu, editors,Proceedings of the 4th Workshop on Natural Language Processing Techniques for Educational Applications (NLPTEA 2017), pages 69–77, Taipei, Taiwan, Decembe...
2017
-
[8]
CrisisLTLSum: A benchmark for local crisis event time- line extraction and summarization
Hossein Rajaby Faghihi, Bashar Alhafni, Ke Zhang, Shihao Ran, Joel Tetreault, and Alejandro Jaimes. CrisisLTLSum: A benchmark for local crisis event time- line extraction and summarization. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 5455–5477, Abu Dhabi, United A...
2022
-
[9]
Association for Computational Linguistics
-
[10]
Ranking multi- document event descriptions for building thematic timelines
Kiem-Hieu Nguyen, Xavier Tannier, and Véronique Moriceau. Ranking multi- document event descriptions for building thematic timelines. InProceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, pages 1208–1217, 2014
2014
-
[11]
Examining the state-of- the-art in news timeline summarization
Demian Gholipour Ghalandari and Georgiana Ifrim. Examining the state-of- the-art in news timeline summarization. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1322–1334, Online, July 2020. Association for Computational Linguistics
2020
-
[12]
Multi-timeline summarization (mtls): Improving timeline summa- rization by generating multiple summaries
Yi Yu, Adam Jatowt, Antoine Doucet, Kazunari Sugiyama, and Masatoshi Yoshikawa. Multi-timeline summarization (mtls): Improving timeline summa- rization by generating multiple summaries. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volum...
2021
-
[13]
Large Language Models are Zero-Shot Reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.ArXiv, abs/2205.11916, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Gpt-4 technical report, 2024
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, et al. Gpt-4 technical report, 2024
2024
-
[15]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenhang Ge, Yu Han, et al. Qwen technical report.ArXiv, abs/2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Ernie 5.0 technical report, 2026
Haifeng Wang, Hua Wu, Tian Wu, Yu Sun, Jing Liu, Dianhai Yu, Yanjun Ma, Jingzhou He, et al. Ernie 5.0 technical report, 2026
2026
-
[17]
Unfolding the headline: Iterative self-questioning for news retrieval and timeline summarization
Weiqi Wu, Shen Huang, Yong Jiang, Pengjun Xie, Fei Huang, and Hai Zhao. Unfolding the headline: Iterative self-questioning for news retrieval and timeline summarization. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational Linguistics: NAACL 2025, pages 4385–4398, Albuquerque, New Mexico, April 2025. Associatio...
2025
-
[18]
Hashimoto
Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, and Tatsunori B. Hashimoto. Benchmarking large language models for news summarization.Transactions of the Association for Computational Linguistics, 12:39–57, 2024
2024
-
[19]
Timeline summarization in the era of llms
Daivik Sojitra, Raghav Jain, Sriparna Saha, Adam Jatowt, and Manish Gupta. Timeline summarization in the era of llms. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2657–2661, 2024
2024
-
[20]
A graph is worth a thousand words: Telling event stories using timeline summa- rization graphs
Jeffery Ansah, Lin Liu, Wei Kang, Selasie Kwashie, Jixue Li, and Jiuyong Li. A graph is worth a thousand words: Telling event stories using timeline summa- rization graphs. InThe World Wide Web Conference, WWW ’19, page 2565–2571, New York, NY, USA, 2019. Association for Computing Machinery
2019
-
[21]
Follow the timeline! generating abstractive and extractive timeline summary in chronological order, 2023
Xiuying Chen, Mingzhe Li, Shen Gao, Zhangming Chan, Dongyan Zhao, Xin Gao, Xiangliang Zhang, and Rui Yan. Follow the timeline! generating abstractive and extractive timeline summary in chronological order, 2023
2023
-
[22]
Unsupervised key event detection from massive text corpora
Yunyi Zhang, Fang Guo, Jiaming Shen, and Jiawei Han. Unsupervised key event detection from massive text corpora. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’22, page 2535–2544, New York, NY, USA, 2022. Association for Computing Machinery
2022
-
[23]
Multi-document event extraction using large and small language models
Qingkai Min, Zitian Qu, Qipeng Guo, Xiangkun Hu, Zheng Zhang, and Yue Zhang. Multi-document event extraction using large and small language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Nat- ural Language Processing, pages 19265–19296, Suzhou, C...
2025
-
[24]
Large language models can learn temporal reasoning.arXiv preprint arXiv:2401.06853, 2024
Siheng Xiong, Ali Payani, Ramana Kompella, and Faramarz Fekri. Large language models can learn temporal reasoning.arXiv preprint arXiv:2401.06853, 2024
-
[25]
Time-r1: Towards comprehensive temporal reasoning in llms.arXiv preprint arXiv:2505.13508, 2025
Zijia Liu, Peixuan Han, Haofei Yu, Haoru Li, and Jiaxuan You. Time-r1: Towards comprehensive temporal reasoning in llms.arXiv preprint arXiv:2505.13508, 2025
-
[26]
Temporal knowledge graph reasoning based on evolutional representation learning
Zixuan Li, Xiaolong Jin, Wei Li, Saiping Guan, Jiafeng Guo, Huawei Shen, Yuanzhuo Wang, and Xueqi Cheng. Temporal knowledge graph reasoning based on evolutional representation learning. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, pages 408–417, 2021
2021
-
[27]
Enhancing event causality identification with llm knowledge and concept-level event relations
Ya Su, Hu Zhang, Guangjun Zhang, Yujie Wang, Yue Fan, Ru Li, and Yuan- long Wang. Enhancing event causality identification with llm knowledge and concept-level event relations. InProceedings of the 31st International Conference on Computational Linguistics, pages 7403–7414, 2025
2025
-
[28]
RAG-Enhanced Large Language Models for Dynamic Content Expiration Prediction in Web Search
Tingyu Chen, Wenkai Zhang, Li Gao, Lixin Su, Ge Chen, Dawei Yin, and Dait- ing Shi. Rag-enhanced large language models for dynamic content expiration prediction in web search.arXiv preprint arXiv:2605.13052, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Predicting social media popularity with large language models: Transforming metadata into semantic-enriched and contextualized text.IEEE Access, 2024
Tianjian Chen, Jiang Huang, Xuetong Wu, and Changcheng Shao. Predicting social media popularity with large language models: Transforming metadata into semantic-enriched and contextualized text.IEEE Access, 2024
2024
-
[30]
Fore- casting the buzz: Enriching hashtag popularity prediction with llm reasoning
Yifei Xu, Jiaying Wu, Herun Wan, Yang Li, Zhen Hou, and Min-Yen Kan. Fore- casting the buzz: Enriching hashtag popularity prediction with llm reasoning. In Proceedings of the 34th ACM International Conference on Information and Knowl- edge Management, pages 5396–5400, 2025
2025
-
[31]
Fusing time series and tweet semantics: A cross-modal llm framework for topic popularity fore- casting
Jiakun Zheng, Xiaojiang Peng, Genan Dai, and Bowen Zhang. Fusing time series and tweet semantics: A cross-modal llm framework for topic popularity fore- casting. In2025 6th International Conference on Machine Learning and Computer Application (ICMLCA), pages 883–887. IEEE, 2025
2025
-
[32]
Llama 2: Open foundation and fine-tuned chat models, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, et al. Llama 2: Open foundation and fine-tuned chat models, 2023
2023
-
[33]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216, 4(5), 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised con- trastive pre-training.arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. A comprehen- sive survey and experimental comparison of graph-based approximate nearest neighbor search.arXiv preprint arXiv:2101.12631, 2021
-
[36]
Improving ROUGE for timeline sum- marization
Sebastian Martschat and Katja Markert. Improving ROUGE for timeline sum- marization. In Mirella Lapata, Phil Blunsom, and Alexander Koller, editors, Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 285–290, Valencia, Spain, April 2017. Association for Computational L...
2017
-
[37]
Testing for changes in kendall’s tau.Econometric Theory, 33(6):1352–1386, 2017
Herold Dehling, Daniel Vogel, Martin Wendler, and Dominik Wied. Testing for changes in kendall’s tau.Econometric Theory, 33(6):1352–1386, 2017
2017
-
[38]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.