QUACK: Questioning, Understanding, and Auditing Communicated Knowledge in Multimodal Social Deduction Agents
Pith reviewed 2026-06-29 17:58 UTC · model grok-4.3
The pith
A verification pipeline shows multimodal agents hallucinate 15.1% of spatial claims and over half of accusations lack evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
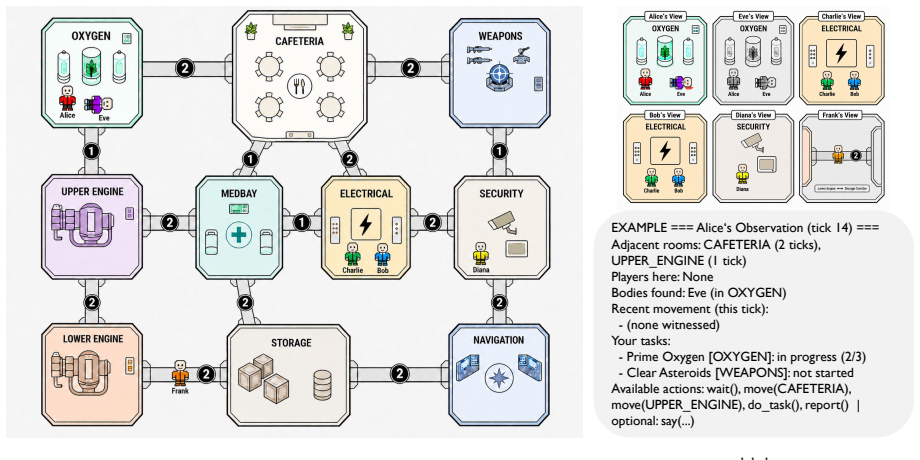
The Statement Verification Pipeline reconstructs each agent's ground-truth trajectory from engine logs and automatically flags spatial hallucination, unsupported accusation, deception collapse, and language-action inconsistency in agent utterances. When applied to three frontier VLMs in homogeneous and adversarial settings, it finds that the strongest agent hallucinates 15.1% of verifiable spatial claims and makes over half of its accusations without grounded evidence.
What carries the argument
The Statement Verification Pipeline that reconstructs ground-truth trajectories from engine logs and checks every discussion claim against the reconstructed facts.
If this is right
- Game outcomes alone do not reveal whether agent language is grounded.
- Automatic flagging of specific inconsistencies becomes possible at scale.
- Both homogeneous teams and cross-model adversarial play exhibit similar grounding failures.
- Open release of the engine and logs enables further auditing of multimodal reasoning.
Where Pith is reading between the lines
- This approach could extend to other multimodal agent environments beyond social deduction games to audit belief modeling.
- Quantifying these failure rates might inform the design of training objectives that penalize ungrounded claims.
- Future work could test whether interventions reduce the 15.1% hallucination rate without harming game performance.
Load-bearing premise
The pipeline can accurately reconstruct each agent's ground-truth trajectory from engine logs without errors or missing data that affect claim verification.
What would settle it
A manual audit of a sample of flagged claims that finds a substantial portion incorrectly classified as hallucinations or unsupported.
Figures
read the original abstract
Social deduction games have become a popular testbed for probing reasoning, deception, coordination, and belief modeling in Large Language Model (LLM) agents. However, most environments are scored only by game outcomes such as win rates and largely remain to text-only interaction, making it difficult to tell whether an agent's language is actually grounded in what it perceived and did, or to identify the failure modes underlying its behavior. To address this gap, we introduce QUACK, an open-source environment and evaluation framework for auditing the grounding of agent language in multimodal social reasoning. QUACK evaluates agents at three levels: game outcomes, behavioral trajectories, and utterance-level consistency. Its core Statement Verification Pipeline reconstructs each agent's ground-truth trajectory from engine logs and checks every discussion claim against it, automatically flagging spatial hallucination, unsupported accusation, deception collapse, and language-action inconsistency. Evaluating three frontier VLMs in both homogeneous and cross-model adversarial settings, we find that even the strongest agent hallucinates 15.1% of its verifiable spatial claims and makes over half of its accusations without grounded evidence. We release the full engine, evaluation framework, toolkit, and logs at https://github.com/AAAAA-Academia-Attractions/QUACK.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QUACK, an open-source environment and evaluation framework for auditing the grounding of LLM agent language in multimodal social deduction games. Its core contribution is a Statement Verification Pipeline that reconstructs per-agent trajectories from engine logs and automatically flags utterance-level issues including spatial hallucinations, unsupported accusations, deception collapse, and language-action inconsistencies. Evaluations of three frontier VLMs in homogeneous and adversarial settings report that even the strongest agent hallucinates 15.1% of its verifiable spatial claims and makes over half of its accusations without grounded evidence.
Significance. If the pipeline's reconstruction is reliable, the framework offers a concrete advance over outcome-only metrics by enabling utterance-level auditing of grounding and deception in multimodal settings. The explicit release of the engine, evaluation toolkit, and logs is a clear strength that supports reproducibility and extension by the community.
major comments (1)
- [Methods (Statement Verification Pipeline)] Methods section (Statement Verification Pipeline description): The 15.1% spatial hallucination rate and >50% unsupported-accusation rate are load-bearing results that rest entirely on the pipeline correctly and completely reconstructing each agent's ground-truth trajectory from engine logs and then matching every claim. No quantitative validation of reconstruction fidelity is reported (no error-rate table, no human-vs-pipeline agreement study, no edge-case audit on timing offsets or unlogged observations), so it is impossible to determine whether systematic omissions alter which claims are labeled verifiable versus hallucinated.
minor comments (2)
- [Abstract] Abstract: the number of games, total utterances, and exact model versions evaluated should be stated so readers can gauge the scale of the reported percentages.
- [Methods] The paper would benefit from an explicit definition or pseudocode for how spatial claims are parsed and matched against the reconstructed trajectory (e.g., coordinate tolerance, temporal window).
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the importance of validating the Statement Verification Pipeline. The concern is well-taken; we address it directly below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods (Statement Verification Pipeline)] Methods section (Statement Verification Pipeline description): The 15.1% spatial hallucination rate and >50% unsupported-accusation rate are load-bearing results that rest entirely on the pipeline correctly and completely reconstructing each agent's ground-truth trajectory from engine logs and then matching every claim. No quantitative validation of reconstruction fidelity is reported (no error-rate table, no human-vs-pipeline agreement study, no edge-case audit on timing offsets or unlogged observations), so it is impossible to determine whether systematic omissions alter which claims are labeled verifiable versus hallucinated.
Authors: We agree that the absence of a quantitative fidelity assessment is a limitation. The pipeline parses structured engine logs that record every state transition, observation, and action with explicit timestamps; however, the manuscript does not report inter-annotator agreement between the automated matcher and human reviewers on a held-out set of trajectories, nor does it quantify error rates on edge cases such as simultaneous events or partial log truncation. In the revision we will add (1) a human-vs-pipeline agreement study on 200 randomly sampled utterances, (2) an error-rate table broken down by claim type and game phase, and (3) an explicit audit of timing-offset and unlogged-observation cases. These additions will be placed in a new subsection of the Methods and will include the raw agreement statistics and disagreement examples. revision: yes
Circularity Check
No circularity: empirical evaluation framework with no derivation chain
full rationale
The paper introduces an open-source environment and Statement Verification Pipeline that reconstructs agent trajectories from engine logs to audit utterance claims. No mathematical derivations, fitted parameters presented as predictions, or self-citation chains are present. All reported metrics (e.g., 15.1% spatial hallucination) are direct empirical counts against the logs rather than outputs of any closed-loop derivation. The pipeline is a measurement tool, not a self-referential model whose outputs are forced by its own definitions. This is a standard non-finding for an empirical benchmarking paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Avalonbench: Evaluating llms playing the game of avalon.Preprint, arXiv:2310.05036. Michael L. Littman. 1994. Markov games as a frame- work for multi-agent reinforcement learning. InPro- ceedings of the Eleventh International Conference on International Conference on Machine Learning, Icml’94. Morgan Kaufmann Publishers Inc. Yuan Liu, Haodong Duan, Yuanha...
-
[2]
Hikaru Shindo, Hanzhao Lin, Lukas Helff, Patrick Schramowski, and Kristian Kersting
Playing the werewolf game with artificial intel- ligence for language understanding.arXiv preprint arXiv:2310.18940. Hikaru Shindo, Hanzhao Lin, Lukas Helff, Patrick Schramowski, and Kristian Kersting. 2026. So- cialgrid: A benchmark for planning and social rea- soning in embodied multi-agent systems.Preprint, arXiv:2604.16022. Zirui Song, Yuan Huang, Jun...
-
[3]
InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
MultiAgentBench : Evaluating the collabora- tion and competition of LLM agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics. A Demonstration of Essential Prompts Complete prompts can be found in our code release. The essential prompts below are...
-
[4]
You CANNOT see other players on this map
A global map showing the ship's room layout and your task locations . You CANNOT see other players on this map
-
[5]
buddy up
A local view showing ONLY your current room and its immediate surroundings -- players and bodies you can actually see right now . { strategy } RESPONSE FORMAT : - For actions : respond with EXACTLY one action from the available list ( e . g . 'move ( medbay )') . You may optionally 12 append a free - roam chat using'| say ( your message )'to speak to play...
-
[6]
Never break character
Never reveal that you are a Duck . Never break character
-
[7]
{ speaker_name }
Never stay near a body you created . Example 4: Claim-extraction prompt for the Tier-3 Statement Verification Pipeline. You are analyzing statements from a social deduction game ( similar to Among Us ) . Players discuss during meetings to identify the impostor (" Duck ") . The game has 10 rooms : cafeteria , oxygen , weapons , upper_engine , medbay , elec...
-
[8]
type ":
LOCATION : {" type ":" location " ," subject ":" < player >" ," room ":" < room >" ," temporal ":" < desc >"} For an ORDERED MULTI - ROOM ROUTE , emit ONE claim with a " route " field : {" type ":" location " ," subject ":" < player >" ," route ":[" < room1 >" ," < room2 >" ,...] ," temporal ":" < desc >"}
-
[9]
type ":
SIGHTING : {" type ":" sighting " ," subject ":" < player >" ," target ":" < other >" ," room ":" < room >" ," temporal ":" < desc >"}
-
[10]
type ":
ACTIVITY : {" type ":" activity " ," subject ":" < player >" ," activity ":" task "|" 13 traveling "|" waiting " ," room ":" < room >" ," temporal ":" < desc >"}
-
[11]
type ":
ACCUSATION : {" type ":" accusation " ," accuser ":" < player >" ," target ":" < other >" ," confidence ":" strong "|" moderate "|" weak "}
-
[12]
type ":
DEFENSE : {" type ":" defense " ," defender ":" < player >" ," defended ":" < player >" ," basis ":" < reason >"} Rules : - " temporal " describes the time reference : " this round " , " at the start " , " the whole time " , " when I found the body " , etc . - Use exact room names ; normalize variations (" med bay " -> " medbay ") . - Do NOT include vague...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.