ReMoE: Boosting Expert Reuse through Router Fine-Tuning in Memory-Constrained MoE LLM Inference
Pith reviewed 2026-06-29 18:56 UTC · model grok-4.3
The pith
Fine-tuning the MoE router to favor recent experts increases reuse by 26% without losing accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
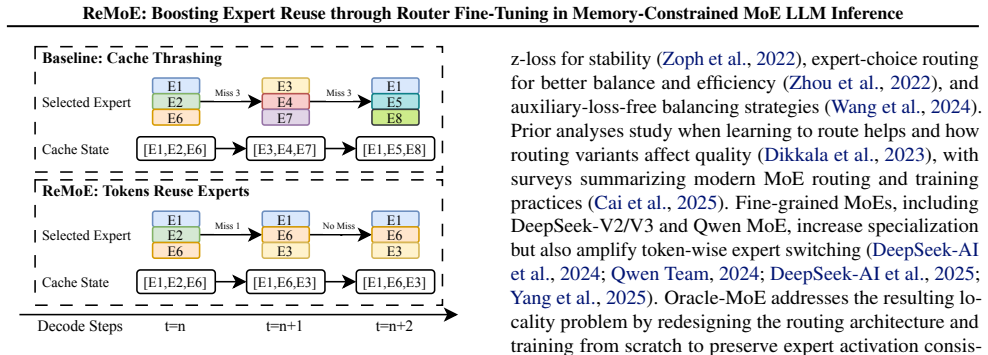
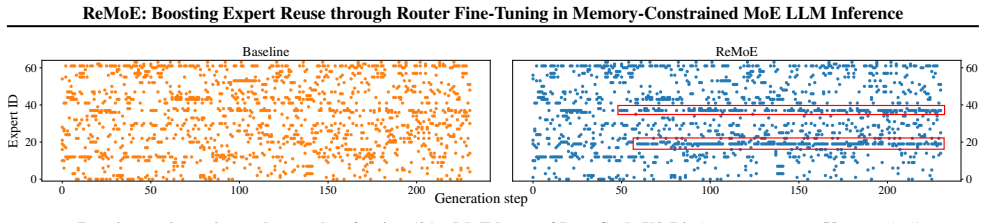
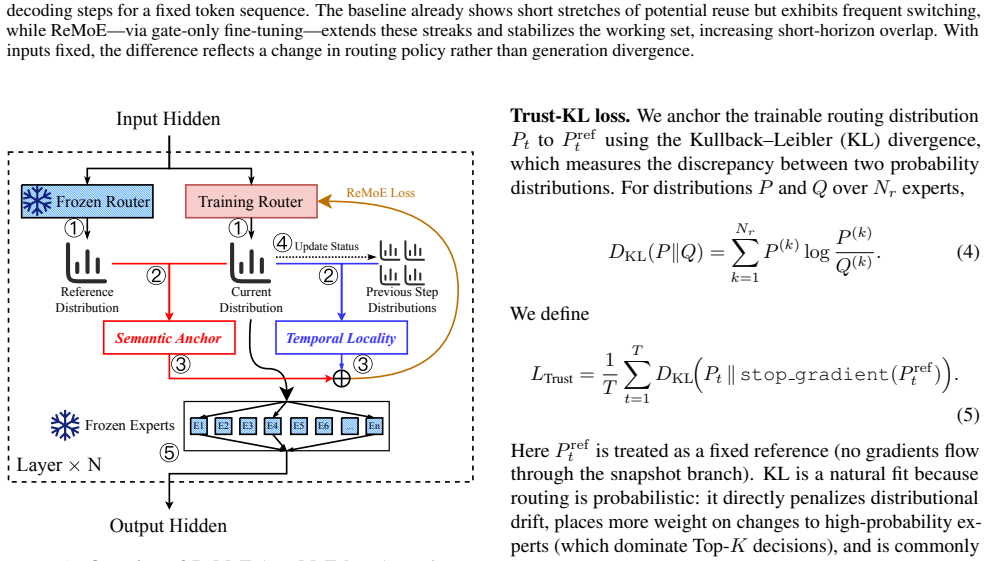
ReMoE applies fine-tuning to the router to bias it toward recently selected experts. The resulting temporally stable routing decisions better match the locality needs of a small expert cache, lowering the frequency of loads from external storage during inference on models such as DeepSeek and Qwen.
What carries the argument
Router fine-tuning objective that encourages selection of recently used experts to promote temporal stability in routing.
If this is right
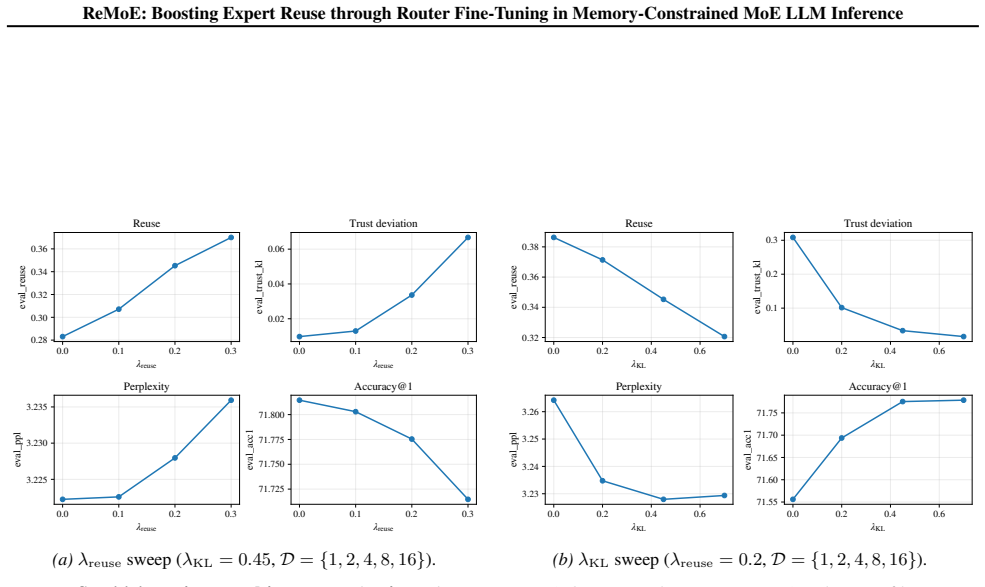
- Expert reuse improves by 26 percent across tested models.
- Downstream task performance remains unchanged.
- Output throughput rises 8.4 percent under vLLM with GPU-CPU offloading.
- Decode time per output token drops 43.6-49.8 percent on Jetson Orin NX, for 1.77-1.99x speedup.
Where Pith is reading between the lines
- Similar fine-tuning could be applied to other caching policies beyond simple LRU in MoE systems.
- Edge deployments of large MoE models become more feasible if reuse gains hold across hardware.
- The approach may extend to reducing communication costs in distributed MoE inference.
Load-bearing premise
Fine-tuning the router for short-horizon reuse leaves its selection quality intact on unseen or long inputs.
What would settle it
Measuring a decline in accuracy on held-out benchmarks or a failure to increase reuse on long-context prompts would disprove the central claim.
Figures

read the original abstract
Fine-grained Mixture-of-Experts (MoE) models sparsely activate only a subset of experts per token, reducing activated computation while maintaining high model capacity. However, in memory-constrained inference scenarios, only a small set of experts can be cached. Experts not in the cache must be fetched from slow external storage (e.g., UFS), leading to frequent evictions and substantial I/O overhead. We propose ReMoE, a router fine-tuning framework designed to boost token-wise expert reuse. ReMoE biases the router toward recently selected experts, producing temporally stable routing that better matches cache locality constraints. By increasing short-horizon expert reuse, ReMoE reduces expert fetches from storage without adding inference-time computation. Experiments on DeepSeek and Qwen models show that ReMoE improves expert reuse by 26% while maintaining downstream task performance. Real-system evaluations further confirm these benefits, improving output throughput by 8.4% under vLLM GPU-CPU expert offloading and reducing TPOT by 43.6-49.8% under llama.cpp on Jetson Orin NX, corresponding to a 1.77-1.99$\times$ decode speedup across diverse workloads. Checkpoints and usage instructions are available at https://github.com/BUAA-OSCAR/ReMoE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReMoE, a router fine-tuning approach for Mixture-of-Experts LLMs that adds a bias toward recently used experts to increase token-wise reuse under memory constraints. It reports a 26% improvement in expert reuse on DeepSeek and Qwen models while preserving downstream task performance, along with measured gains of 8.4% throughput under vLLM GPU-CPU offloading and 1.77-1.99× decode speedup (via 43.6-49.8% TPOT reduction) on Jetson Orin NX with llama.cpp.
Significance. If the core assumption holds, the work addresses a practical bottleneck in deploying large MoE models on memory-limited hardware by improving cache locality without runtime overhead. The real-system results on two platforms and two model families add practical value, and the public release of checkpoints strengthens reproducibility. However, the absence of key methodological details and targeted ablations limits assessment of broader applicability.
major comments (3)
- [§3] §3 (method): The fine-tuning objective and bias mechanism toward recently selected experts are described only at a high level; the precise loss formulation, temporal horizon, and how the bias is added to the router logits without altering inference compute are unspecified. This is load-bearing for the 26% reuse claim, as it prevents determining whether the gain arises from the proposed mechanism or from training data characteristics.
- [§4-5] §4-5 (experiments): Downstream performance is reported as maintained on standard benchmarks, but no ablation or evaluation on long-context inputs or out-of-distribution tasks is described. The short-horizon reuse objective could override context-dependent signals on sequences exceeding the fine-tuning horizon, directly risking the central claim that performance is preserved under the same conditions where reuse gains are measured.
- [Abstract and §4] Abstract and §4: No information is provided on the fine-tuning dataset, hyperparameters, number of random seeds, or statistical significance testing for the 26% reuse figure. This makes it impossible to assess whether workload selection was post-hoc or whether the reported gains are robust, undermining confidence in the empirical results.
minor comments (2)
- [Abstract] Abstract: The relationship between the 43.6-49.8% TPOT reduction and the 1.77-1.99× decode speedup should be clarified explicitly, including any assumptions about batching or sequence length.
- The manuscript would benefit from additional citations to prior work on cache-aware MoE inference and temporal routing stability to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each of the major comments below, agreeing to provide additional details and ablations in a revised manuscript where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (method): The fine-tuning objective and bias mechanism toward recently selected experts are described only at a high level; the precise loss formulation, temporal horizon, and how the bias is added to the router logits without altering inference compute are unspecified. This is load-bearing for the 26% reuse claim, as it prevents determining whether the gain arises from the proposed mechanism or from training data characteristics.
Authors: We acknowledge that the description in the manuscript is high-level. We will revise §3 to provide the precise loss formulation, specify the temporal horizon, and detail how the bias is incorporated into the router logits during fine-tuning only, ensuring no additional inference compute. This revision will make it clear that the 26% reuse improvement stems from the proposed bias mechanism. revision: yes
-
Referee: [§4-5] §4-5 (experiments): Downstream performance is reported as maintained on standard benchmarks, but no ablation or evaluation on long-context inputs or out-of-distribution tasks is described. The short-horizon reuse objective could override context-dependent signals on sequences exceeding the fine-tuning horizon, directly risking the central claim that performance is preserved under the same conditions where reuse gains are measured.
Authors: We note that the current experiments focus on standard benchmarks to demonstrate maintained performance. However, to directly address the potential issue with long-context inputs, we will add ablations and evaluations on long-context tasks in the revised version to confirm that the short-horizon objective does not degrade performance on sequences longer than the fine-tuning horizon. revision: yes
-
Referee: [Abstract and §4] Abstract and §4: No information is provided on the fine-tuning dataset, hyperparameters, number of random seeds, or statistical significance testing for the 26% reuse figure. This makes it impossible to assess whether workload selection was post-hoc or whether the reported gains are robust, undermining confidence in the empirical results.
Authors: We agree that the manuscript should include more details on the experimental setup. We will update the abstract and §4 to specify the fine-tuning dataset, list the hyperparameters, report the number of random seeds, and include statistical significance testing for the reported improvements. The public release of checkpoints already aids reproducibility, but these additions will further strengthen the paper. revision: yes
Circularity Check
No circularity: empirical gains from router fine-tuning are measured outcomes, not identities by construction
full rationale
The paper proposes ReMoE as a fine-tuning method that adds a bias toward recently-used experts to improve cache locality in memory-constrained MoE inference. The 26% reuse improvement, 8.4% throughput gain, and 1.77-1.99x speedup are reported as direct experimental measurements on DeepSeek/Qwen models and real hardware (vLLM, llama.cpp on Jetson), not as quantities algebraically forced by the fine-tuning objective or by any self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that would reduce the central claims to the inputs; the method and its evaluation remain independent of the reported numbers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
URL https://arxiv.org/abs/2107.0 3374. Chen, M., Shao, W., Xu, P., Wang, J., Gao, P., Zhang, K., and Luo, P. EfficientQAT: Efficient quantization- aware training for large language models. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Proceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: L...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-long.498 2025
-
[2]
Du, H., Wu, S., Kharlamova, A., Guan, N., and Xue, C
URL https://openreview.net/forum ?id=QV79qiKAjD. Du, H., Wu, S., Kharlamova, A., Guan, N., and Xue, C. J. Flexinfer: Breaking memory constraint via flexible and efficient offloading for on-device llm inference, 2025. URLhttps://arxiv.org/abs/2503.03777. Du, N., Huang, Y ., Dai, A. M., Tong, S., Lepikhin, D., Xu, Y ., Krikun, M., Zhou, Y ., Yu, A. W., Fira...
-
[3]
URL https://aclanthology.org/2025.findin gs-acl.997/
doi: 10.18653/v1/2025.findings-acl.997. URL https://aclanthology.org/2025.findin gs-acl.997/. Jiang, X., Zhou, Y ., Cao, S., Stoica, I., and Yu, M. Neo: Saving gpu memory crisis with cpu offloading for online llm inference, 2024. URL https://arxiv.org/ab s/2411.01142. Kamahori, K., Tang, T., Gu, Y ., Zhu, K., and Kasikci, B. Fiddler: CPU-GPU orchestration...
-
[4]
Shen, M., Yin, H., Molchanov, P., Mao, L., Liu, J., and Alvarez, J
URL https://openreview.net/forum ?id=B1ckMDqlg. Shen, M., Yin, H., Molchanov, P., Mao, L., Liu, J., and Alvarez, J. M. Structural pruning via latency-saliency knapsack, 2022. URL https://arxiv.org/abs/ 2210.06659. Sheng, Y ., Zheng, L., Yuan, B., Li, Z., Ryabinin, M., Fu, D. Y ., Xie, Z., Chen, B., Barrett, C., Gonzalez, J. E., Liang, P., R´e, C., Stoica,...
-
[5]
URL https://arxiv.org/abs/2408.1 5664. Wang, X., Tang, Z., Guo, J., Meng, T., Wang, C., Wang, T., and Jia, W. Empowering edge intelligence: A compre- hensive survey on on-device ai models.ACM Computing Surveys, 57(9):1–39, April 2025. ISSN 1557-7341. doi: 10.1145/3724420. URL http://dx.doi.org/10. 1145/3724420. Xiao, G., Lin, J., Seznec, M., Wu, H., Demou...
-
[6]
For instance, if K= 6 and C= 4 , even if Et =E t−1, the cache cannot hold all 6 experts simultaneously, so a guarantee of the form(17) no longer holds
If C < K , misses are unavoidable.When capacity is insufficient to hold a full routed set, then regardless of routing overlap, at least K−C experts must be missing at every step. For instance, if K= 6 and C= 4 , even if Et =E t−1, the cache cannot hold all 6 experts simultaneously, so a guarantee of the form(17) no longer holds. This is why we restrict toC≥K
-
[7]
Then even if Et−1 was fully loaded during step t−1 , some of these experts might be evicted before step t begins, and the containment in Lemma A.5 can fail
If cache isolation is violated, Et−1 ⊆ C t may fail.Suppose expert weights share the same memory pool with other objects that can evict experts between steps (e.g., KV-cache expansion, activation buffers, or a different layer/request). Then even if Et−1 was fully loaded during step t−1 , some of these experts might be evicted before step t begins, and the...
-
[8]
For example, with C=K , any insertion of an expert not in Et−1 forces an eviction; if the policy/prefetcher evicts from Et−1, then Et−1 ⊈C t
Inter-step insertions (e.g., aggressive prefetch) can break the guarantee.If a prefetcher inserts additional experts into the cache between step t−1 and t and triggers evictions, it may evict members of Et−1 even under C≥K . For example, with C=K , any insertion of an expert not in Et−1 forces an eviction; if the policy/prefetcher evicts from Et−1, then E...
-
[9]
Non-admitting or unusual policies.Assumption A.2 requires that the cache admits the experts it just served (when C≥K ). Pathological policies that can evict an expert immediately after it is fetched/used (within the same step), or that refuse to retain the requested set, can violate (15) and invalidate the proof. Such policies are atypical for expert-weig...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.