LLMs Are Already Good Tutors: Training-Free Prompt Optimization for Pedagogical Math Tutoring
Pith reviewed 2026-06-29 17:47 UTC · model grok-4.3
The pith
Optimizing system prompts alone produces math-tutoring LLMs that beat RL-trained baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
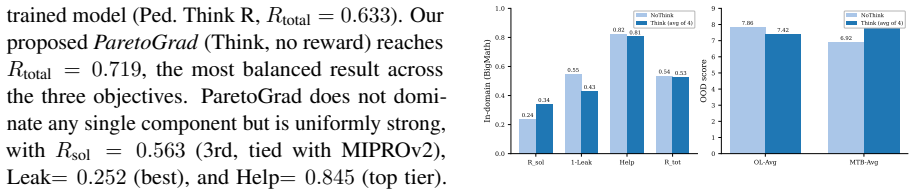
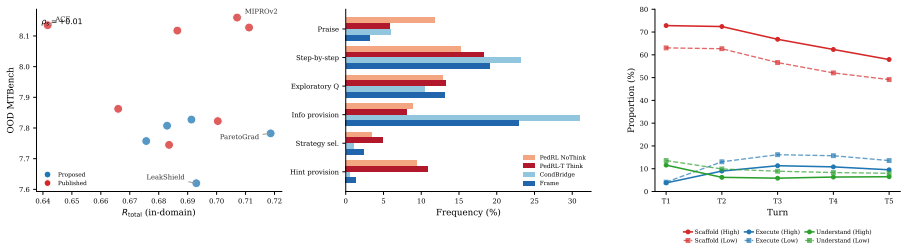
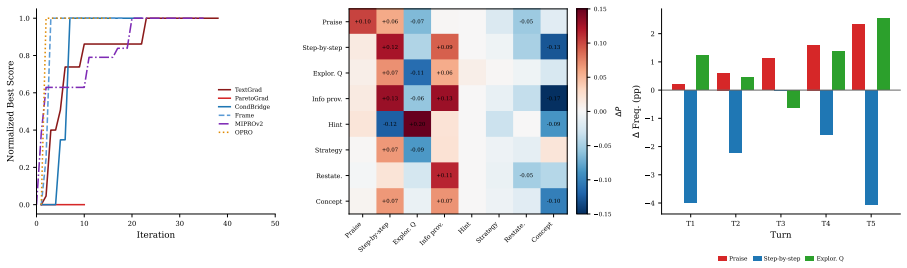
Training-free prompt optimization of system prompts alone can produce LLM math tutors that surpass RL-trained models on a composite score, with the ParetoGrad method delivering the strongest Pareto balance across solve rate, leak control, and helpfulness. Training-free approaches exhibit 2-3x higher rates of teaching-knowledge patterns and a ~10 percentage-point reduction in intent-level scaffolding, while both paradigms display the same task-dependent reasoning mode effect.
What carries the argument
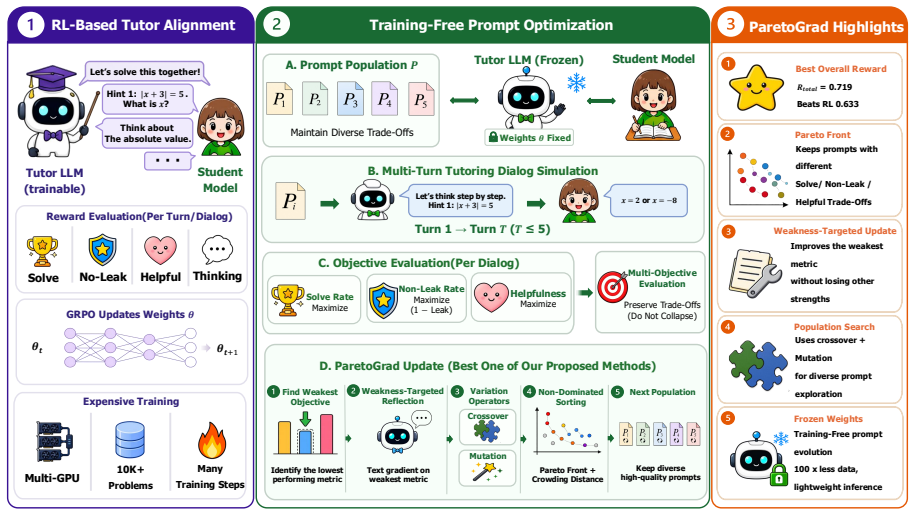
Training-free evolution of system prompts via API calls, paired with an 82-code educational codebook that quantifies teaching-knowledge patterns and scaffolding in responses.
If this is right
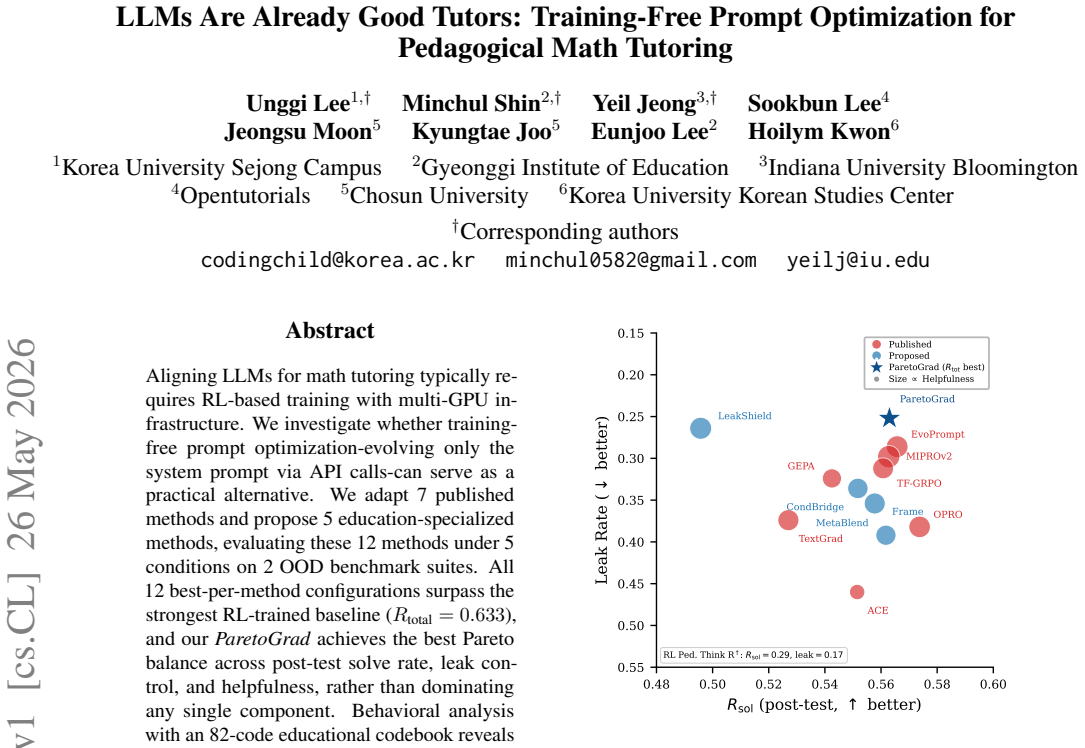
- All twelve best-per-method configurations surpass the RL baseline total score of 0.633.
- ParetoGrad achieves the best overall balance rather than leading on any single metric.
- Training-free methods rely on teaching-knowledge patterns at 2-3x the rate of RL models.
- A task-dependent reasoning mode effect holds across both training-free and RL paradigms.
- Pedagogically aligned tutors can be developed with prompts and minimal compute.
Where Pith is reading between the lines
- The same prompt-only approach could be applied to tutoring in other subjects without retraining.
- Lower compute requirements may allow smaller teams or schools to build custom tutors.
- Live classroom trials would test whether the measured patterns produce better student outcomes.
- The observed reasoning mode effect suggests a general property of LLM tutoring rather than a training artifact.
Load-bearing premise
The two OOD benchmark suites and the 82-code educational codebook sufficiently capture real pedagogical quality and generalization in math tutoring scenarios.
What would settle it
A controlled study with actual students using the optimized prompts versus the RL baseline, measuring real learning gains on post-tests; equal or lower gains would undermine the claim.
Figures
read the original abstract
Aligning LLMs for math tutoring typically requires RL-based training with multi-GPU infrastructure. We investigate whether training-free prompt optimization-evolving only the system prompt via API calls-can serve as a practical alternative. We adapt 7 published methods and propose 5 education-specialized methods, evaluating these 12 methods under 5 conditions on 2 OOD benchmark suites. All 12 best-per-method configurations surpass the strongest RL-trained baseline (R_total = 0.633), and our ParetoGrad achieves the best Pareto balance across post-test solve rate, leak control, and helpfulness, rather than dominating any single component. Behavioral analysis with an 82-code educational codebook reveals that training-free methods rely on teaching-knowledge patterns at 2-3x the rate of RL-trained models, with a compensating ~10 percentage-point reduction in intent-level scaffolding. We also find a task-dependent reasoning mode effect consistent across training-free and RL-based paradigms. Our approach enables efficient development of pedagogically aligned LLM tutors with prompts alone and minimal compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that training-free prompt optimization—evolving only the system prompt via API calls—can serve as a practical alternative to RL-based training for aligning LLMs as math tutors. It adapts 7 published methods and introduces 5 education-specialized methods, evaluates the resulting 12 methods under 5 conditions on 2 OOD benchmark suites, and reports that all 12 best-per-method configurations surpass the strongest RL baseline (R_total=0.633), with the proposed ParetoGrad achieving the best multi-objective Pareto balance across post-test solve rate, leak control, and helpfulness. Behavioral analysis via an 82-code educational codebook shows training-free methods using teaching-knowledge patterns at 2-3x the rate of RL models (with a compensating drop in intent-level scaffolding) and identifies a task-dependent reasoning-mode effect consistent across paradigms.
Significance. If the chosen benchmarks and codebook are accepted as valid proxies, the result would indicate that prompt optimization alone can yield pedagogically stronger tutors than RL at far lower compute cost, while also surfacing interpretable differences in teaching behavior. The multi-method comparison and Pareto analysis provide a concrete demonstration that training-free approaches need not trade off across the three axes.
major comments (1)
- [Evaluation and Behavioral Analysis sections] Evaluation and Behavioral Analysis sections: the headline superiority claim (all 12 configs > R_total=0.633 and ParetoGrad best on the three-way front) and the behavioral conclusion (2-3x teaching-knowledge rate) rest on the 2 OOD suites and 82-code codebook being faithful proxies for pedagogical quality and generalization. The manuscript supplies no validation of the codebook (inter-annotator agreement, correlation with learning gains, or coverage of common student misconceptions) nor any argument that the chosen OOD suites match the distribution of scaffolding needs that would arise in live tutoring; this is load-bearing for the pedagogical interpretation.
minor comments (1)
- Abstract and §3: R_total is reported as 0.633 without an explicit decomposition into its constituent metrics in the opening summary; a one-sentence definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback emphasizing the need to validate our evaluation proxies. We respond point-by-point below and outline planned revisions.
read point-by-point responses
-
Referee: [Evaluation and Behavioral Analysis sections] Evaluation and Behavioral Analysis sections: the headline superiority claim (all 12 configs > R_total=0.633 and ParetoGrad best on the three-way front) and the behavioral conclusion (2-3x teaching-knowledge rate) rest on the 2 OOD suites and 82-code codebook being faithful proxies for pedagogical quality and generalization. The manuscript supplies no validation of the codebook (inter-annotator agreement, correlation with learning gains, or coverage of common student misconceptions) nor any argument that the chosen OOD suites match the distribution of scaffolding needs that would arise in live tutoring; this is load-bearing for the pedagogical interpretation.
Authors: We agree that stronger validation of the proxies would reinforce the claims. In the revised manuscript we will add inter-annotator agreement statistics for the 82-code codebook (computed during annotation) and expand the Methods and Discussion sections with explicit arguments for the OOD suites, citing their coverage of diverse math topics, error types, and scaffolding scenarios drawn from prior educational datasets. A direct empirical correlation between the codebook and measured learning gains would require a separate human-subject study that lies outside the present scope; we will therefore note this explicitly as a limitation while retaining the comparative behavioral analysis as an interpretable signal across paradigms. revision: partial
- Empirical correlation between the 82-code codebook and actual student learning gains from live tutoring sessions
Circularity Check
No circularity in derivation chain
full rationale
The paper is an empirical evaluation comparing 12 prompt-optimization configurations (7 adapted + 5 proposed) against an RL baseline on two external OOD benchmark suites, using post-test solve rate, leak control, helpfulness, and behavioral rates from an 82-code educational codebook. No equations, parameter fits, self-definitional reductions, or load-bearing self-citations are present that would make any reported superiority equivalent to its inputs by construction. All claims rest on direct measurement against independent benchmarks and codebook analysis, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. 2026. GEPA : Reflective prompt evolution can outperform reinforcement learning. In Proceedings...
2026
- [2]
-
[3]
Deborah Loewenberg Ball, Mark Hoover Thames, and Geoffrey Phelps. 2008. Content knowledge for teaching: What makes it special? Journal of Teacher Education, 59(5):389--407
2008
-
[4]
Chi and Ruth Wylie
Michelene T.H. Chi and Ruth Wylie. 2014. The ICAP framework: Linking cognitive engagement to active learning outcomes. Educational Psychologist, 49(4):219--243
2014
-
[5]
David Dinucu-Jianu, Jakub Macina, Nico Daheim, Ido Hakimi, Iryna Gurevych, and Mrinmaya Sachan. 2025. From problem-solving to teaching problem-solving: Aligning LLMs with pedagogy using reinforcement learning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2025
-
[6]
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. 2024. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. In Proceedings of the Twelfth International Conference on Learning Representations (ICLR)
2024
-
[7]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2024. Dspy: Compiling declarative language model calls into self-improving pipelines. In International Conference on Learning Representations
2024
- [8]
-
[9]
Unggi Lee, Jiyeong Bae, Jaehyeon Park, Haeun Park, Taejun Park, Younghoon Jeon, Sungmin Cho, Junbo Koh, Yeil Jeong, and Gyeonggeon Lee. 2026 a . Rewarding how models think pedagogically: Integrating pedagogical reasoning and thinking rewards for LLMs in education. arXiv preprint arXiv:2601.14560
-
[10]
Unggi Lee, Sookbun Lee, Heungsoo Choi, Jinseo Lee, Haeun Park, Younghoon Jeon, Sungmin Cho, Minju Kang, Junbo Koh, Jiyeong Bae, Minwoo Nam, Juyeon Eun, Yeonji Jung, and Yeil Jeong. 2026 b . OpenLearnLM benchmark: A unified framework for evaluating knowledge, skill, and attitude in educational large language models. arXiv preprint arXiv:2601.13882
-
[11]
Jakub Macina, Nico Daheim, Sankalan Pal Chowdhury, Tanmay Sinha, Manu Kapur, Iryna Gurevych, and Mrinmaya Sachan. 2023. MathDial : A dialogue tutoring dataset with rich pedagogical properties grounded in math reasoning problems. In Findings of the Association for Computational Linguistics: EMNLP 2023
2023
-
[12]
Jakub Macina, Nico Daheim, Ido Hakimi, Manu Kapur, Iryna Gurevych, and Mrinmaya Sachan. 2025. MathTutorBench : A benchmark for measuring open-ended pedagogical capabilities of LLM tutors. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2025
- [13]
-
[14]
George P \'o lya. 1945. How to Solve It: A New Aspect of Mathematical Method. Princeton University Press
1945
-
[15]
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. 2023. Automatic prompt optimization with ``gradient descent'' and beam search. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[16]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Lee S. Shulman. 1986. Those who understand: Knowledge growth in teaching. Educational Researcher, 15(2):4--14
1986
-
[18]
Ana \" s Tack and Chris Piech. 2022. The AI teacher test: Measuring the pedagogical ability of blender and GPT-3 in educational dialogues. In Proceedings of the International Conference on Artificial Intelligence in Education
2022
-
[19]
Bruner, and Gail Ross
David Wood, Jerome S. Bruner, and Gail Ross. 1976. The role of tutoring in problem solving. Journal of Child Psychology and Psychiatry, 17(2):89--100
1976
-
[20]
Large Language Models as Optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. 2024. Large language models as optimizers. arXiv preprint arXiv:2309.03409
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. 2024. TextGrad : Automatic ``differentiation'' via text. arXiv preprint arXiv:2406.07496
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. 2026. Agentic context engineering: Evolving contexts for self-improving language models. In Proceedings of the Fourteenth International Conference on Learning Representatio...
2026
-
[23]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others. 2023. Judging LLM -as-a-judge with MT -bench and chatbot arena. Advances in Neural Information Processing Systems, 36
2023
-
[24]
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2023. Large language models are human-level prompt engineers. In International Conference on Learning Representations
2023
-
[25]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[26]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.