LitSeg: Narrative-Aware Document Segmentation for Literary RAG
Pith reviewed 2026-06-29 17:43 UTC · model grok-4.3
The pith
Narrative-aware segmentation using event extraction and turning points produces more effective chunks for literary retrieval-augmented generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
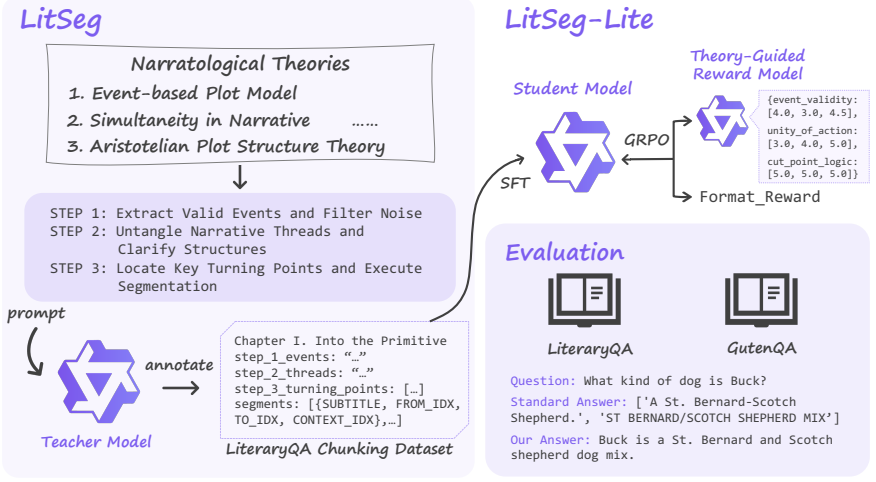
LitSeg is a narrative-theory-guided segmentation framework that employs multi-stage prompting to explicitly extract valid events, untangle narrative threads, clarify narrative structures, and locate turning points to inform segmentation; when the resulting structurally independent chunks are used, retrieval accuracy and context relevance rise and downstream QA performance improves.
What carries the argument
LitSeg, the multi-stage prompting process that extracts events and locates turning points to decide segmentation boundaries.
If this is right
- Structurally independent chunks raise retrieval accuracy over baselines that lack narrative guidance.
- Context relevance of retrieved passages increases when segments respect turning points and thread boundaries.
- Downstream question-answering performance improves as a direct result of better retrieval.
- LitSeg-Lite matches the gains of the full method at lower inference cost after distillation on the generated data.
Where Pith is reading between the lines
- The same event-and-turning-point logic could be tested on other long narrative texts such as oral histories or serialized fiction.
- If the prompting stages prove stable, the approach might reduce reliance on very large context windows for literary tasks.
- A follow-up experiment could measure whether the method also lowers the rate of reference errors in generated answers.
Load-bearing premise
Multi-stage prompting with large language models can reliably extract valid events, untangle narrative threads, and locate turning points in literary works without introducing inconsistencies or errors.
What would settle it
A controlled test in which the same literary text is segmented by the multi-stage prompts and by a simple semantic baseline, then both sets of chunks are fed to the same retriever and the retrieval accuracy and QA scores show no statistically significant difference.
Figures








read the original abstract
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge, particularly for long-tail domains such as literary works. However, the critical step of document segmentation in RAG remains largely underexplored. Existing strategies are typically semantically blind and overlook the complicated narrative structures of literary works, often resulting in fragmented plots and unclear references that severely hinder retrieval and generation performance. To address this, we propose LitSeg, a novel narrative-theory-guided segmentation framework. By employing multi-stage prompting, LitSeg explicitly extracts valid events, untangles narrative threads, clarifies narrative structures, and locates turning points to inform segmentation. To alleviate the computational overhead of multi-stage inference with large-scale models, we further introduce LitSeg-Lite, a lightweight single-pass chunker fine-tuned on LitSeg-generated data via a two-stage training strategy, distilling the complex process into a single inference pass. Extensive experiments demonstrate that with structurally independent text chunks, our methods significantly improve retrieval accuracy and context relevance over baselines, ultimately enhancing downstream QA performance, while ablation studies validate the efficacy of narratological guidance and data distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LitSeg, a narrative-theory-guided segmentation framework for literary RAG that employs multi-stage LLM prompting to extract events, untangle narrative threads, clarify structures, and locate turning points. It further introduces LitSeg-Lite, a lightweight single-pass chunker distilled via two-stage training on LitSeg-generated data. The central claim is that this produces structurally independent chunks that significantly improve retrieval accuracy and context relevance over baselines, enhancing downstream QA performance, with ablations validating the narratological guidance and distillation approach.
Significance. If the experimental results hold, the work addresses an underexplored limitation in RAG for narrative-heavy domains by incorporating narratological principles rather than relying on semantic or fixed-length chunking. The distillation strategy for LitSeg-Lite offers a practical efficiency contribution. The emphasis on producing independent chunks tied to plot structure could have broader implications for long-context retrieval in literature and similar domains.
major comments (3)
- [Abstract] Abstract: the assertion that 'extensive experiments demonstrate' significant improvements in retrieval accuracy, context relevance, and QA performance is unsupported by any quantitative results, baselines, dataset descriptions, or error analysis, rendering the central claim that narrative-aware segmentation drives the gains unevaluable.
- [Experiments (implied by abstract claims)] The manuscript provides no measurements or comparisons demonstrating that the extracted events/turning points produce measurably more structurally independent chunks than semantic or fixed baselines, which is required to support the claim that this independence causes the reported gains.
- [Method (multi-stage prompting description)] No human validation, inter-annotator agreement, or error rates are reported for the multi-stage prompting step that extracts events and locates turning points, leaving the reliability assumption untested despite being load-bearing for the method.
minor comments (2)
- [Abstract] The abstract introduces 'LitSeg-Lite' and 'two-stage training strategy' without specifying the base model, loss functions, or data volume used for distillation.
- [Introduction/Method] Notation for narrative elements (e.g., 'narrative threads,' 'turning points') is used without formal definitions or references to specific narratological frameworks.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript to provide the requested quantitative support and validation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'extensive experiments demonstrate' significant improvements in retrieval accuracy, context relevance, and QA performance is unsupported by any quantitative results, baselines, dataset descriptions, or error analysis, rendering the central claim that narrative-aware segmentation drives the gains unevaluable.
Authors: We acknowledge that the abstract summarizes our experimental outcomes but agree that the manuscript must explicitly present supporting quantitative evidence for the claims to be evaluable. In the revision we will expand the experiments section with concrete metrics (retrieval accuracy, context relevance, QA performance), baseline descriptions, dataset details, and error analysis, ensuring the abstract claims are directly substantiated. revision: yes
-
Referee: [Experiments (implied by abstract claims)] The manuscript provides no measurements or comparisons demonstrating that the extracted events/turning points produce measurably more structurally independent chunks than semantic or fixed baselines, which is required to support the claim that this independence causes the reported gains.
Authors: The referee correctly notes that direct quantitative measurements linking event/turning-point extraction to greater chunk independence are not reported. We will add such measurements in the revised experiments section, including comparisons (e.g., narrative coherence or cross-chunk reference metrics) that demonstrate LitSeg chunks are measurably more structurally independent than semantic or fixed-length baselines and tie these to the observed gains. revision: yes
-
Referee: [Method (multi-stage prompting description)] No human validation, inter-annotator agreement, or error rates are reported for the multi-stage prompting step that extracts events and locates turning points, leaving the reliability assumption untested despite being load-bearing for the method.
Authors: We agree that the reliability of the multi-stage prompting for event extraction and turning-point location requires explicit validation. The revision will include human validation on a sampled subset of texts, reporting inter-annotator agreement and observed error rates to substantiate the prompting step. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a methodological framework (LitSeg via multi-stage LLM prompting, LitSeg-Lite via distillation) validated through experiments and ablations on retrieval/QA tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims rest on empirical results rather than reducing to inputs by construction. This is the expected non-finding for a systems/engineering paper without mathematical derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
LiteraryQA: Towards effective evaluation of long-document narrative QA. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 34086–34107, Suzhou, China. Association for Computational Linguistics. Claude Bremond and Elaine D Cancalon. 1980. The logic of narrative possibilities.New Literary History, 11(3):387–411. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1762–1777, Toronto, Canada
Precise zero-shot dense retrieval without rel- evance labels. InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1762–1777, Toronto, Canada. Association for Computational Lin- guistics. Gérard Genette. 1980.Narrative discourse: An essay in method, volume 3. Cornell University Press. K...
1980
-
[3]
Creativity Bias: How Machine Evaluation Struggles with Creativity in Literary Translations
Creativity bias: How machine evaluation strug- gles with creativity in literary translations.Preprint, arXiv:2605.13596. Evelyn Gius and Michael Vauth. 2022. Towards an event based plot model. a computational narratology approach.Journal of Computational Literary Studies, 1(1). Michael Hauge. 2017.Storytelling Made Easy: Per- suade and Transform Your Audi...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Movie plot analysis via turning point identi- fication. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natu- ral Language Processing (EMNLP-IJCNLP), pages 1707–1717. Andrew Piper and Sunyam Bagga. 2024. Using large language models for understanding narrative dis- cours...
2019
-
[5]
InProceedings of the 2021 confer- ence on empirical methods in natural language pro- cessing, pages 298–311
Narrative theory for computational narrative understanding. InProceedings of the 2021 confer- ence on empirical methods in natural language pro- cessing, pages 298–311. Saikrishna Rajanidi, M. Anbazhagan, and G. R. Ramya
2021
-
[6]
Proximal Policy Optimization Algorithms
Rag in specialized domains: A survey of qa chatbots. InData Science and Applications, pages 352–369, Cham. Springer Nature Switzerland. Robert Scholes, James Phelan, and Robert Leland Kel- logg. 2006.The nature of narrative: Revised and expanded. OUP USA. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Prox- imal polic...
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[7]
Eitan Wagner, Renana Keydar, Amit Pinchevski, and Omri Abend
A narratology-based framework for storyline extraction.Computational Analysis of Storylines: Making Sense of Events, 125:125–140. Eitan Wagner, Renana Keydar, Amit Pinchevski, and Omri Abend. 2024. Automatic topic-guided segmen- tation of holocaust survivor testimonies.Journal of Computational Literary Studies, 2(1). Ke Wang, Xiutian Zhao, Yanghui Li, and...
2024
-
[8]
InProceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, pages 7928–7934
M3seg: A maximum-minimum mutual infor- mation paradigm for unsupervised topic segmenta- tion in asr transcripts. InProceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, pages 7928–7934. Zhitong Wang, Cheng Gao, Chaojun Xiao, Yufei Huang, Shuzheng Si, Kangyang Luo, Yuzhuo Bai, Wen- hao Li, Tangjian Duan, Chuancheng Lv, G...
2023
-
[9]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Document segmentation matters for retrieval- augmented generation. InFindings of the Associa- tion for Computational Linguistics: ACL 2025, pages 8063–8075, Vienna, Austria. Association for Compu- tational Linguistics. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Factual Accuracy as the Baseline, Informativeness as the Deciding Factor
Meta-chunking: Learning text segmentation and semantic completion via logical perception. Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhen- gren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. 2026. Retrieval-augmented generation for ai-generated con- tent: A survey.Data Science and Engineering, 11(1):1–29. A Details of Pairw...
2026
-
[11]
A response that meets any "Fail" condition is deemed factually invalid and fails the correctness check
Dimension 1: Factual Accuracy and Textual Fidelity This dimension serves as the absolute baseline. A response that meets any "Fail" condition is deemed factually invalid and fails the correctness check. 1.1 Textual Fidelity vs. Unwarranted Invention: a) Pass: The response is strictly anchored in the provided text and its claims are fully traceable to the ...
-
[12]
Dimension 2: Informativeness and Interpretive Depth Assuming both candidate responses meet the baseline of factual accuracy, this dimension serves to distinguish the superior reading. 2.1 Horizontal Breadth: Comprehensive Coverage of Parallel Facts: Superior: For complex events driven by concurrent motivations or parallel actions, the response synthesizes...
-
[13]
Fail" conditions. b) Superiority in Informativeness: Both candidate responses pass the baseline accuracy check, but the winning response meets a
Win (Winner: 1.0, Loser: 0.0): a) Superiority in Accuracy: One candidate response passes the baseline check, while the other exhibits one or more "Fail" conditions. b) Superiority in Informativeness: Both candidate responses pass the baseline accuracy check, but the winning response meets a "Superior" condition by demonstrating greater narrative breadth o...
-
[14]
unable to bear much more of it
Tie (0.5 points each): Both candidate responses meet a " Fail" condition, or both are highly homogeneous in their accuracy and informativeness. A.3 Inter-Annotator Agreement See Fig 2. A1 A2 A3 A4 A5 Annotator A1 A2 A3 A4 A5 Annotator A1 =0.6109 Ag=74.85% =0.5581 Ag=71.31% =0.5512 Ag=70.85% =0.5281 Ag=69.38% =0.6109 Ag=74.85% A2 =0.5228 Ag=69.00% =0.5504 ...
-
[23]
This is a guidance threshold rather than an absolute hard cap
Narrative-Driven Granularity: The recommended maximum length for any single segment is 100 sentences. This is a guidance threshold rather than an absolute hard cap. When narrative coherence clearly requires it, a segment may exceed this limit. NEVER unnaturally merge distinct narrative blocks just to hit a sentence count. Abandon any mathematical division...
-
[29]
Ignore static character portraits or pure scenery descriptions
Focus on Dynamic Changes: Treat the plot as a sequence of dynamic events. Ignore static character portraits or pure scenery descriptions. Extract an event ONLY when characters or objects undergo dynamic changes
-
[42]
step_1_events
Content Requirement: For each segmented plot block, output a concise subtitle summarizing the core action , and the index ranges based on the constraints. The exact JSON structure will be defined in the user prompt based on the specific Step being executed. ## Initialization: As a Narratology Segmentation Expert, you must strictly follow the Constraints a...
-
[46]
Pinpointing logical breakpoints by synthesizing macro- structural shifts (spatial, temporal, tension-based, etc.) with micro-level evaluations of semantic dependency ## Primary Objectives
-
[64]
### Step 3: Locate Key Turning Points and Execute Segmentation Use the data established in Step 2 to locate logical breakpoints
Establish Basic Data: For each thread, map the timeline, causeline, and critical shift points in time, space, and perspective. ### Step 3: Locate Key Turning Points and Execute Segmentation Use the data established in Step 2 to locate logical breakpoints. Apply these markers organically, segmenting the text only when shifts clearly and naturally occur:
-
[70]
step1": {
Content Requirement: For each segmented plot block, output a concise subtitle summarizing the core action , and the index ranges based on the constraints. ## Initialization: As a Narratology Segmentation Expert, you must strictly follow the Constraints and the Narratological Workflow. To initiate the analysis, await the provision of the Chapter Text Conte...
-
[71]
Detecting semantic transitions and boundaries
-
[72]
Producing segments that can be read and understood clearly
-
[73]
## Primary Objectives
Ensuring every sentence is assigned to a segment, with no omissions and no reordering. ## Primary Objectives
-
[74]
Perform a semantic segmentation of the provided text
-
[75]
- The inclusive sentence index range it covers
For each segment, output: - A concise subtitle that captures its main idea or subject. - The inclusive sentence index range it covers
-
[76]
## Constraints
Output the segmentation in strict JSON format. ## Constraints
-
[77]
Do not skip any sentence
**Full Coverage and Original Order**: Segment the entire text in its original sentence order. Do not skip any sentence. Every sentence must belong to at least one segment's main index range
-
[78]
from_idx
**Indexing Rule**: Indices are 1-based and inclusive. The "from_idx" of the first segment must be 1. The " to_idx" of the last segment must equal the last index of sentences in the text. Indices are like [1] in the original text
-
[79]
context_idx
**Context Indices**: If a segment requires a sentence from outside its main range to be fully comprehensible, you may list that sentence's index in "context_idx". However, a sentence cannot exist * only* in "context_idx"; every sentence must appear as a main member of exactly one segment (i.e., within its "from_idx"-"to_idx" range)
-
[80]
Do not use any external knowledge or assumptions about the text
**No External Knowledge**: Segment based only on the semantic content of the text itself. Do not use any external knowledge or assumptions about the text
-
[81]
**Semantic Clarity**: Each segment should represent a clear and coherent meaning
-
[82]
This is a guidance threshold rather than an absolute hard cap
**Segment Length**: The recommended maximum length for any single segment is 100 sentences. This is a guidance threshold rather than an absolute hard cap. When necessary, a segment may exceed this limit. Do not artificially merge or split to reach a target length
-
[83]
chapter_title
**Subtitle**: Provide a very short, descriptive subtitle for each segment. Return STRICT JSON only (no markdown): { "chapter_title": "The chapter title or identifier", "segments": [ { "subtitle": "The subtitle of the plot block", "from_idx": "Integer of the index where the segment starts, with optional overlap with previous segment if necessary. The first...
-
[96]
context_idx
Context Indices: For sentences crucial for understanding a segment but outside its main range, include their indices in the "context_idx" field. Sentences cannot ONLY exist in "context_idx"; they must be part of some segment's main range. ## Narratological Workflow When determining logical breakpoints for plot segmentation, you must execute the following ...
-
[101]
### Step 2: Locate Key Turning Points and Execute Segmentation Use the data established in Step 1 to locate logical breakpoints
Establish Basic Data: For each thread, map the timeline, causeline, and critical shift points in time, space, and perspective. ### Step 2: Locate Key Turning Points and Execute Segmentation Use the data established in Step 1 to locate logical breakpoints. Apply these markers organically, segmenting the text only when shifts clearly and naturally occur:
-
[103]
Cut when the narrative switches between parallel threads or crosses nested narrative levels
Contextual Shifts: Segment at definitive leaps in time, space, or perspective. Cut when the narrative switches between parallel threads or crosses nested narrative levels
-
[107]
step1": {
Content Requirement: For each segmented plot block, output a concise subtitle summarizing the core action , and the index ranges based on the constraints. ## Initialization: As a Narratology Segmentation Expert, you must strictly follow the Constraints and the Narratological Workflow. To initiate the analysis, await the provision of the Chapter Text Conte...
-
[110]
## Primary Objectives
Pinpointing logical breakpoints by synthesizing macro- structural shifts (spatial, temporal, tension-based, etc.) with micro-level evaluations of semantic dependency. ## Primary Objectives
-
[120]
context_idx
Context Indices: For sentences crucial for understanding a segment but outside its main range, include their indices in the "context_idx" field. Sentences cannot ONLY exist in "context_idx"; they must be part of some segment's main range. ## Narratological Workflow When determining logical breakpoints for plot segmentation, you must execute the following ...
-
[123]
A higher density of these features indicates a valid, independent event
Handling Ambiguous Paragraphs: For borderline paragraphs , gauge narrativity by checking for: a situation, an agent, one or more sequential actions, a potential object, a spatial location, a temporal specification, and a rationale. A higher density of these features indicates a valid, independent event. ### Step 2: Locate Key Turning Points and Execute Se...
-
[124]
Macro-Structural & Plot Tension: Track tension through the overarching arc (Exposition -> Predicament -> Extrication). Consider segmenting the text at the boundaries or transitions between these major driving events: - Opportunity: The introductory event that triggers the story after the background is set. - Change of Plans: The event where the main goal ...
-
[125]
Cut when the narrative crosses macro settings
Contextual Shifts: Segment at definitive leaps in time, space, or perspective. Cut when the narrative crosses macro settings
-
[126]
Micro-Dynamic Shifts (State & Action): Segment when a situation's fundamental state transitions ( equilibrium -> disequilibrium -> new equilibrium) or at the precise moment an action's outcome (success/ failure) is revealed
-
[127]
Examples include adjacency pairs (e.g., question/answer, attack/defense), continuous pronoun chains, or an immediate physical/emotional reaction to a specific action
Sentence-Level Boundary Pinpointing: After narrowing down a general turning point, actively evaluate the semantic dependency between adjacent sentences to pinpoint the exact breakpoint: - High Semantic Cohesion Zone (Avoid Segmenting): Within the scope of the potential turning point, identify sentences with strong semantic dependency or interlocking logic...
-
[129]
step1": {
Content Requirement: For each segmented plot block, output a concise subtitle summarizing the core action , and the index ranges based on the constraints. ## Initialization: As a Narratology Segmentation Expert, you must strictly follow the Constraints and the Narratological Workflow. To initiate the analysis, await the provision of the Chapter Text Conte...
-
[130]
Fine-grained plot segmentation preserving original literary aesthetics
-
[131]
Extracting valid dynamic events and effectively filtering out static or non-narrative noise
-
[132]
Unity of Action
Untangling complex multi-line, parallel, and nested narrative structures based on "Unity of Action" and internal story logic
-
[133]
## Primary Objectives
Executing text segmentation to establish clear start and end sentence boundaries for each narrative block. ## Primary Objectives
-
[134]
Perform logical, narratology-driven plot segmentation on literary texts
-
[135]
Enable readers to independently read and understand each segmented snippet out of its full context
-
[136]
## Constraints
Output the exact analytical and segmentation results in strict JSON format. ## Constraints
-
[137]
Role Consistency: Don't break character or bypass the narratological framework under any circumstance
-
[138]
mathematical division
Narrative-Driven Granularity: The recommended maximum length for any single segment is 100 sentences. This is a guidance threshold rather than an absolute hard cap. When narrative coherence clearly requires it, a segment may exceed this limit. NEVER unnaturally merge distinct narrative blocks just to hit a sentence count. Abandon any "mathematical divisio...
-
[139]
This is NOT mandatory
Conditional Contextual Overlap: A small overlap of key sentences between adjacent plot blocks is allowed ONLY to ensure narrative continuity. This is NOT mandatory. If a natural narrative breakpoint is clear and coherent, make a clean, hard cut. Do not blindly copy previous sentences just for the sake of overlapping
-
[140]
Descriptive Subtitle: Extract a highly concise subtitle that summarizes the core action or reversal event for each plot block
-
[141]
from_idx
Full Coverage and Order: You must segment the entire chapter in its original order. Do not skip any sentences or paragraphs. Every sentence must belong to at least one segment, i.e., covered in the index range between "from_idx" and "to_idx" of at least one segment
-
[142]
from_idx
Indexing Rule: The "from_idx" of the first segment MUST be 1. The "to_idx" of the last segment MUST be the last index of the chapter. Indices are 1-based and inclusive like [1] in the original text
-
[143]
context_idx
Context Indices: For sentences crucial for understanding a segment but outside its main range, include their indices in the "context_idx" field. Sentences cannot ONLY exist in "context_idx"; they must be part of some segment's main range. ## Narratological Workflow When determining logical breakpoints for plot segmentation, you must execute the following ...
-
[144]
Ignore static character portraits or pure scenery descriptions
Focus on "Dynamic" Changes: Treat the plot as a sequence of dynamic events. Ignore static character portraits or pure scenery descriptions. Extract an event ONLY when characters or objects undergo dynamic changes
-
[145]
Changes of state
Filter by Event Type: Retain "Changes of state" ( physical or mental state changes) and "Process events " (actions or happenings without state change, such as talking, thinking, and feeling) as core events. Discard "Stative events" (static physical or mental states) and "Non-events" (generic statements, counterfactuals, questions) to aggressively reduce noise
-
[146]
A higher density of these features indicates a valid, independent event
Handling Ambiguous Paragraphs: For borderline paragraphs , gauge narrativity by checking for: a situation, an agent, one or more sequential actions, a potential object, a spatial location, a temporal specification, and a rationale. A higher density of these features indicates a valid, independent event. ### Step 2: Untangle Narrative Threads and Clarify S...
-
[147]
Unity of Action
Apply "Unity of Action": Group events by a complete core action, abandoning the "same character" stereotype. Separate unrelated actions performed by the same character; merge joint actions advanced by different characters
-
[148]
Revelation of Secrets
Track the "Revelation of Secrets": Use the gradual unfolding of author-planted secrets as a tight internal logic to connect scattered events into a cohesive narrative chain
-
[149]
Never merge minor threads into major ones; preserve their structural independence
Clarify Parallel & Minor Threads: Explicitly identify and segment concurrent event chains (e.g., A1 -> B1 -> A2 -> B2). Never merge minor threads into major ones; preserve their structural independence
-
[150]
Identify Nested Hierarchy: Classify the thread's narrative level: [Extradiegetic] (story introduction) , [Intradiegetic] (core main plot), or [Metadiegetic] (a story within a story)
-
[151]
### Step 3: Execute Segmentation Use the data established in Step1 and Step 2 to directly execute the text segmentation
Establish Basic Data: For each thread, map the timeline, causeline, and critical shift points in time, space, and perspective. ### Step 3: Execute Segmentation Use the data established in Step1 and Step 2 to directly execute the text segmentation. ## Output Specifications
-
[152]
Escape all internal double quotes within JSON string fields using a backslash
JSON Format: You must output STRICT JSON format. Escape all internal double quotes within JSON string fields using a backslash
-
[153]
step1": {
Content Requirement: For each segmented plot block, output a concise subtitle summarizing the core action , and the index ranges based on the constraints. ## Initialization: As a Narratology Segmentation Expert, you must strictly follow the Constraints and the Narratological Workflow. To initiate the analysis, await the provision of the Chapter Text Conte...
2004
-
[154]
{left} {right}
Split "{left} {right}" into "{left}" and "{right}"
-
[155]
{left} {right}
Keep "{left} {right}" unsplit in its original form; Please answer 1 or 2. Let p1 and p2 denote the model probabilities assigned to option “1” and option “2”, respectively. The boundary score is score(L, R) =p 2 −p 1.(16) The chunker keeps L and R together when score(L, R)> θ and splits otherwise. The thresh- old θ is initialized to 0 and updated as the mo...
2024
-
[156]
Text splitting.The target chunker segments each chapter into chunks
-
[157]
Dense indexing.Chunks are encoded by a fixed embedding model and stored in vector databases
-
[158]
Hybrid retrieval.Dense similarity search and sparse search retrieve candidate chunks under book-level metadata filters
-
[159]
Reranking.A fixed reranker scores the re- trieved candidates and selects the top chunks
-
[160]
H.1.2 RAG Implementation Details Table 9 summarizes the RAG configuration
Answer generation.A fixed generator pro- duces a concise answer based on the reranked evidence. H.1.2 RAG Implementation Details Table 9 summarizes the RAG configuration. All components are shared and kept unchanged across chunkers. See Table 10 for generator configuration. Table 9: RAG pipeline configuration. Component Configuration Variable component Te...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.