LUCoS: Latent Unsupervised Context Selection for Tabular Foundation Models
Pith reviewed 2026-06-29 18:19 UTC · model grok-4.3
The pith
Selecting context using latent embeddings from an unsupervised Prior-Fitted Network outperforms raw-feature and random selection for low-label tabular foundation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
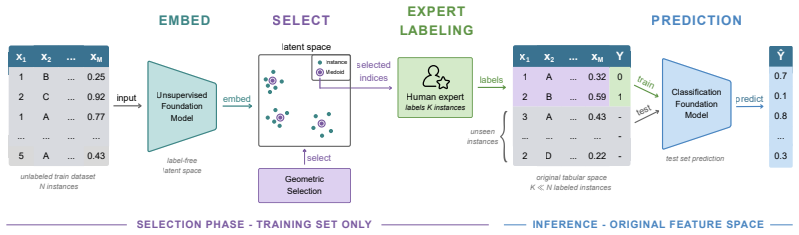
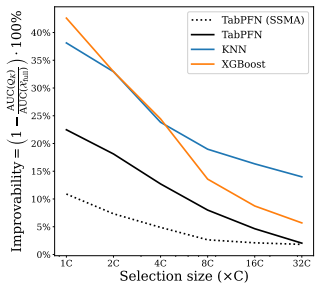
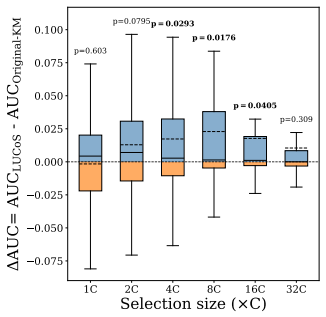
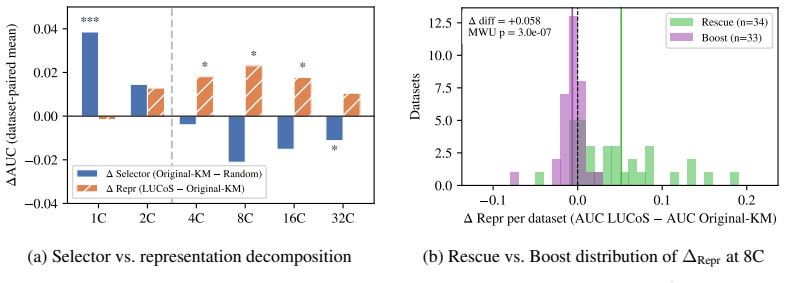
LUCoS replaces the unreliable geometry of the original heterogeneous tabular feature space with the latent geometry induced by embeddings from an unsupervised Prior-Fitted Network and selects representative medoids from this space to serve as the labeled context. Across 67 OpenML-CC18 datasets and six low-label budgets, this yields first rank under mean AUC, ACC, and F1, with conclusions stable across metrics and dataset-level checks. Gain decomposition reveals that at the smallest budgets the main benefit comes from enforcing coverage; as the budget increases, the decisive factor becomes the representation space in which coverage is measured. LUCoS thereby mitigates the failures of original
What carries the argument
Latent geometry induced by embeddings from an unsupervised Prior-Fitted Network, used to select representative medoids as context
If this is right
- Original-space selection performs below random on the majority of datasets as the labeling budget grows.
- Enforcing coverage via medoid selection supplies the primary performance gain at the smallest budgets.
- The choice of representation space becomes the decisive performance factor once budgets are moderately larger.
- Reliable unsupervised context selection depends less on selector sophistication than on using a meaningful representation geometry.
Where Pith is reading between the lines
- The same latent-geometry approach could supply a general metric for instance selection in other heterogeneous data settings where foundation models already produce embeddings.
- Pre-trained unsupervised networks may serve as label-free sources of representativeness metrics that transfer across tabular tasks without retraining.
- The budget-dependent shift from coverage to representation space suggests a natural schedule for switching selection strategies as more labels become available.
Load-bearing premise
The latent geometry induced by embeddings from an unsupervised Prior-Fitted Network provides a meaningfully better metric for selecting representative medoids than the original heterogeneous tabular feature space.
What would settle it
If raw-space medoid selection or random selection achieves equal or higher mean AUC than LUCoS on a majority of the 67 datasets at multiple low-label budgets under the same protocol, the claimed advantage of the latent geometry would be falsified.
Figures
read the original abstract
Selecting which instances to label is a key challenge in low-label tabular learning. For recent Tabular Foundation Models such as TabPFN, context selection directly determines predictive performance. Supervised oracle experiments show that carefully chosen labeled context sets can strongly outperform random selection under the same labeling budget. However, the cold-start setting, where instances must be selected before any labels are available, has received little attention in the TFM literature. This problem is fundamentally geometric. In vision and language, foundation models induce embedding spaces where simple geometric selection methods are effective. In contrast, tabular instance selection has so far been performed predominantly in the original tabular space, which lacks a natural metric; heterogeneous types, mixed scales, and nonlinear interactions make raw-space distances unreliable for context construction, and original-space selection falls below random on the majority of datasets as the budget grows. We propose LUCoS (Latent Unsupervised Context Selection), which replaces raw-feature geometry with the latent geometry induced by embeddings from an unsupervised Prior-Fitted Network (PFN) and selects representative medoids as context. Evaluated on 67 OpenML-CC18 datasets across six low-label budgets, LUCoS ranks first under mean AUC, ACC, and F1, with conclusions stable across metrics and dataset-level robustness checks. A gain decomposition reveals a simple mechanism: at the smallest budgets, the main benefit comes from enforcing coverage; as the budget increases, the decisive factor becomes the representation space in which coverage is measured. LUCoS mitigates failures of original feature space selection, showing that reliable unsupervised context selection depends less on selector sophistication than on defining representativeness in a meaningful representation geometry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LUCoS for unsupervised context selection in low-label tabular learning with models like TabPFN. It replaces raw-feature geometry with latent embeddings from an unsupervised Prior-Fitted Network, selects representative medoids as context, and reports that this ranks first in mean AUC, ACC, and F1 across 67 OpenML-CC18 datasets and six labeling budgets. A gain decomposition attributes benefits to coverage enforcement at the smallest budgets and to the representation space at larger budgets, with the central claim that reliable selection depends on defining representativeness in a meaningful geometry rather than selector sophistication.
Significance. If the results hold after verification of the embedding geometry and evaluation details, the work would establish that unsupervised PFN-induced spaces can mitigate failures of heterogeneous tabular feature spaces for cold-start context construction, providing a practical advance for tabular foundation models and highlighting representation choice over algorithmic complexity in instance selection.
major comments (3)
- [Abstract / gain decomposition] Abstract and gain decomposition: the claim that 'as the budget increases, the decisive factor becomes the representation space' is load-bearing for the central argument that PFN geometry is meaningfully superior, yet the manuscript provides no comparison of PFN embeddings against other unsupervised embeddings (e.g., autoencoders, PCA, or random projections) or analysis of embedding properties such as clustering quality or downstream relevance; this leaves open whether gains arise from the specific PFN space or generic effects of dimensionality reduction.
- [Evaluation] Evaluation section: the reported top ranking across 67 datasets and stability across metrics is presented without details on hyperparameter choices for the unsupervised PFN, statistical testing procedures, or explicit checks against post-hoc dataset exclusions, which directly affects verifiability of the robustness claims given the low-label regime.
- [Motivation / baseline comparison] § on original-space baseline: the statement that original-space selection 'falls below random on the majority of datasets as the budget grows' is used to motivate the latent approach, but without quantitative per-dataset breakdowns or controls for feature preprocessing, it is unclear whether the raw-space failure is due to heterogeneous metrics or other implementation factors.
minor comments (2)
- [Method] Notation for the medoid selection objective and the unsupervised PFN embedding function should be introduced with explicit equations rather than prose descriptions to improve reproducibility.
- [Results] Figure captions for the gain decomposition plots should include the exact formulas used for the coverage vs. representation attribution to allow readers to replicate the analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the central claims and improve verifiability. We address each major point below, proposing revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract / gain decomposition] Abstract and gain decomposition: the claim that 'as the budget increases, the decisive factor becomes the representation space' is load-bearing for the central argument that PFN geometry is meaningfully superior, yet the manuscript provides no comparison of PFN embeddings against other unsupervised embeddings (e.g., autoencoders, PCA, or random projections) or analysis of embedding properties such as clustering quality or downstream relevance; this leaves open whether gains arise from the specific PFN space or generic effects of dimensionality reduction.
Authors: We agree that direct comparisons to other unsupervised embeddings would better isolate the contribution of the PFN-induced geometry. The manuscript emphasizes PFN because it is a tabular foundation model whose unsupervised variant provides a natural latent space without requiring labels, but we acknowledge the need for broader controls. In revision we will add experiments comparing PFN embeddings against autoencoders, PCA, and random projections on the same 67 datasets, including metrics for clustering quality (e.g., silhouette score) and downstream relevance to the selection task. revision: yes
-
Referee: [Evaluation] Evaluation section: the reported top ranking across 67 datasets and stability across metrics is presented without details on hyperparameter choices for the unsupervised PFN, statistical testing procedures, or explicit checks against post-hoc dataset exclusions, which directly affects verifiability of the robustness claims given the low-label regime.
Authors: We will expand the evaluation section to include: (i) the exact hyperparameter settings used for the unsupervised PFN (inherited from the original TabPFN training protocol with no additional tuning); (ii) the statistical testing procedure (Wilcoxon signed-rank tests with Holm correction across datasets and budgets); and (iii) explicit confirmation that no datasets were excluded post-hoc—all 67 OpenML-CC18 datasets were retained. These details will be added to the main text and appendix. revision: yes
-
Referee: [Motivation / baseline comparison] § on original-space baseline: the statement that original-space selection 'falls below random on the majority of datasets as the budget grows' is used to motivate the latent approach, but without quantitative per-dataset breakdowns or controls for feature preprocessing, it is unclear whether the raw-space failure is due to heterogeneous metrics or other implementation factors.
Authors: The original-space baseline used standard preprocessing (one-hot encoding for categoricals followed by z-score normalization on numerical features) before distance computation. The aggregate result that it falls below random on the majority of datasets is driven by the lack of a natural metric in heterogeneous tabular spaces. We will add per-dataset breakdowns (showing the fraction below random at each budget) to the appendix and clarify the preprocessing steps in the main text. We maintain that the heterogeneous metrics are the primary cause, but the additional breakdowns will improve transparency. revision: partial
Circularity Check
No significant circularity; empirical evaluation stands independently
full rationale
The paper describes an empirical method (LUCoS) that applies an off-the-shelf unsupervised PFN to induce embeddings, then performs medoid selection in that space, with performance measured on 67 external OpenML datasets. No equations, fitted parameters, or self-referential definitions are present that would make reported gains equivalent to the inputs by construction. The gain decomposition is post-hoc analysis of experimental results rather than a derivation. No load-bearing self-citations, uniqueness theorems, or smuggled ansatzes appear; the central claim rests on direct comparison to random and original-space baselines, which is externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Position: Why Tabular Foundation Models Should Be a Research Priority,
B. van Breugel and M. van der Schaar, “Position: Why Tabular Foundation Models Should Be a Research Priority,” inProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[2]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
L. Grinsztajn, K. Flöge, O. Key, F. Birkel, P. Jund, B. Roof, B. Jäger, D. Safaric, S. Alessi, A. Hayler,et al., “TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models,” arXiv preprint arXiv:2511.08667, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Deep Neural Networks and Tabular Data: A Survey,
V . Borisov, T. Leemann, K. Seßler, J. Haug, M. Pawelczyk, and G. Kasneci, “Deep Neural Networks and Tabular Data: A Survey,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 6, pp. 7499–7519, 2022
2022
-
[4]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second,
N. Hollmann, S. Müller, K. Eggensperger, and F. Hutter, “TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[5]
Accurate Predictions on Small Data with a Tabular Foundation Model,
N. Hollmann, S. Müller, L. Purucker, A. Krishnakumar, M. Körfer, S. B. Hoo, R. T. Schirrmeis- ter, and F. Hutter, “Accurate Predictions on Small Data with a Tabular Foundation Model,” Nature, vol. 637, no. 8045, pp. 319–326, 2025
2025
-
[6]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data,
J. Qu, D. Holzmüller, G. Varoquaux, and M. Le Morvan, “TabICL: A Tabular Foundation Model for In-Context Learning on Large Data,” inProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[7]
TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv:2602.11139, 2026
J. Qu, D. Holzmüller, G. Varoquaux, and M. Le Morvan, “TabICLv2: A better, faster, scalable, and open Tabular Foundation Model,”arXiv preprint arXiv:2602.11139, 2026
-
[8]
TabDPT: Scaling Tabular Foundation Models on Real Data,
J. Ma, V . Thomas, R. Hosseinzadeh, A. Labach, J. C. Cresswell, K. Golestan, G. Yu, A. L. Caterini, and M. V olkovs, “TabDPT: Scaling Tabular Foundation Models on Real Data,” in Advances in Neural Information Processing Systems (NeurIPS), 2025. 10
2025
-
[9]
Language Models are Few-Shot Learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., “Language Models are Few-Shot Learners,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 1877–1901, 2020
1901
-
[10]
TabLLM: Few- shot classification of tabular data with large language models,
S. Hegselmann, A. Buendia, H. Lang, M. Agrawal, X. Jiang, and D. Sontag, “TabLLM: Few- shot classification of tabular data with large language models,” inInternational Conference on Artificial Intelligence and Statistics (AISTATS), pp. 5549–5581, PMLR, 2023
2023
-
[11]
Cold-start active learning for image classification,
Q. Jin, M. Yuan, S. Li, H. Wang, M. Wang, and Z. Song, “Cold-start active learning for image classification,”Information Sciences, vol. 616, pp. 16–36, 2022
2022
-
[12]
Unsupervised Selective Labeling for More Effective Semi- supervised Learning,
X. Wang, L. Lian, and S. X. Yu, “Unsupervised Selective Labeling for More Effective Semi- supervised Learning,” inProceedings of the European Conference on Computer Vision (ECCV), pp. 427–445, Springer, 2022
2022
-
[13]
Enhancing Semi- Supervised Learning via Representative and Diverse Sample Selection,
Q. Shao, J. Kang, Q. Chen, Z. Li, H. Xu, Y . Cao, J. Liang, and J. Wu, “Enhancing Semi- Supervised Learning via Representative and Diverse Sample Selection,”Advances in Neural Information Processing Systems (NeurIPS), vol. 37, pp. 111199–111226, 2024
2024
-
[14]
E. J. Mannix and H. D. Bondell, “Cold PAWS: Unsupervised Class Discovery and Addressing the Cold-start Problem for Semi-supervised Learning,”arXiv preprint arXiv:2305.10071, 2023
-
[15]
Active Learning for Convolutional Neural Networks: A Core-Set Approach,
O. Sener and S. Savarese, “Active Learning for Convolutional Neural Networks: A Core-Set Approach,” inInternational Conference on Learning Representations (ICLR), 2018
2018
-
[16]
Emerg- ing Properties in Self-Supervised Vision Transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerg- ing Properties in Self-Supervised Vision Transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9650–9660, 2021
2021
-
[17]
Masked Autoencoders are Scalable Vision Learners,
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick, “Masked Autoencoders are Scalable Vision Learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16000–16009, 2022
2022
-
[18]
Learning transferable visual models from natural language super- vision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language super- vision,” inProceedings of the 38th International Conference on Machine Learning (ICML), pp. 8748–8763, PMLR, 2021
2021
-
[19]
Representation Learning for Tabular Data: A Comprehensive Survey,
J.-P. Jiang, S.-Y . Liu, H.-R. Cai, Q.-L. Zhou, and H.-J. Ye, “Representation Learning for Tabular Data: A Comprehensive Survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 48, no. 6, pp. 6488–6508, 2026
2026
-
[20]
A Survey on Self-supervised Learning for Non-sequential Tabular Data,
W.-Y . Wang, W.-W. Du, D. Xu, W. Wang, and W.-C. Peng, “A Survey on Self-supervised Learning for Non-sequential Tabular Data,”Machine Learning, vol. 114, no. 1, p. 16, 2025
2025
-
[21]
Towards Localization via Data Em- bedding for TabPFN,
M. Koshil, T. Nagler, M. Feurer, and K. Eggensperger, “Towards Localization via Data Em- bedding for TabPFN,” inProceedings of the Third Table Representation Learning Workshop at NeurIPS, 2024
2024
-
[22]
TabClustPFN: A Prior-Fitted Network for Tabular Data Clustering
T. Zhao, G. Wang, Y . S. Tan, and Q. Zhang, “TabClustPFN: A Prior-Fitted Network for Tabular Data Clustering,”arXiv preprint arXiv:2601.21656, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
TuneTables: Context Optimization for Scalable Prior-data Fitted Networks,
B. Feuer, R. T. Schirrmeister, V . Cherepanova, C. Hegde, F. Hutter, M. Goldblum, N. Cohen, and C. White, “TuneTables: Context Optimization for Scalable Prior-data Fitted Networks,” Advances in Neural Information Processing Systems (NeurIPS), vol. 37, pp. 83430–83464, 2024
2024
-
[24]
End-to-End Compression for Tabular Foundation Models
G. Zabërgja, R. Kamel, A. Kadra, C. M. M. Frey, and J. Grabocka, “End-to-End Compression for Tabular Foundation Models,”arXiv preprint arXiv:2602.05649, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
A survey on deep semi-supervised learning,
X. Yang, Z. Song, I. King, and Z. Xu, “A survey on deep semi-supervised learning,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 9, pp. 8934–8954, 2023
2023
-
[26]
A survey on semi-supervised learning,
J. E. Van Engelen and H. H. Hoos, “A survey on semi-supervised learning,”Machine learning, vol. 109, no. 2, pp. 373–440, 2020
2020
-
[27]
Theoretical Insights into In-context Learning with Unlabeled Data,
Y . Li, X. Chang, M. Kara, X. Liu, A. Roy-Chowdhury, and S. Oymak, “Theoretical Insights into In-context Learning with Unlabeled Data,” inAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[28]
Generalizing from a few examples: A survey on few-shot learning,
Y . Wang, Q. Yao, J. T. Kwok, and L. M. Ni, “Generalizing from a few examples: A survey on few-shot learning,”ACM Computing Surveys, vol. 53, no. 3, pp. 1–34, 2020. 11
2020
-
[29]
Zero-Shot Coreset Selection via Iterative Subspace Sampling,
B. A. Griffin, J. Marks, and J. J. Corso, “Zero-Shot Coreset Selection via Iterative Subspace Sampling,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 2114–2124, 2026
2026
-
[30]
Prototype selection for nearest neighbor classifi- cation: Taxonomy and empirical study,
S. García, J. Derrac, J. Cano, and F. Herrera, “Prototype selection for nearest neighbor classifi- cation: Taxonomy and empirical study,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 34, no. 3, pp. 417–435, 2012
2012
-
[31]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 4171–4186, 2019
2019
-
[32]
VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain,
J. Yoon, Y . Zhang, J. Jordon, and M. van der Schaar, “VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain,”Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 11033–11043, 2020
2020
-
[33]
SCARF: Self-Supervised Contrastive Learning using Random Feature Corruption,
D. Bahri, H. Jiang, Y . Tay, and D. Metzler, “SCARF: Self-Supervised Contrastive Learning using Random Feature Corruption,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[34]
SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training,
G. Somepalli, A. Schwarzschild, M. Goldblum, C. B. Bruss, and T. Goldstein, “SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training,” inProceedings of the First Table Representation Learning Workshop at NeurIPS, 2022
2022
-
[35]
TransTab: Learning Transferable Tabular Transformers Across Tables,
Z. Wang and J. Sun, “TransTab: Learning Transferable Tabular Transformers Across Tables,” Advances in Neural Information Processing Systems (NeurIPS), vol. 35, pp. 2902–2915, 2022
2022
-
[36]
ZEUS: Zero-shot Embeddings for Unsupervised Separation of Tabular Data,
P. Marszałek, T. Ku´smierczyk, W. Wydma´nski, J. Tabor, and M. ´Smieja, “ZEUS: Zero-shot Embeddings for Unsupervised Separation of Tabular Data,” inAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[37]
OpenML Benchmarking Suites,
B. Bischl, G. Casalicchio, M. Feurer, P. Gijsbers, F. Hutter, M. Lang, R. G. Mantovani, J. N. van Rijn, and J. Vanschoren, “OpenML Benchmarking Suites,” inAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021
2021
-
[38]
A baseline for few-shot image classification,
G. S. Dhillon, P. Chaudhari, A. Ravichandran, and S. Soatto, “A baseline for few-shot image classification,” inInternational Conference on Learning Representations, 2020
2020
-
[39]
Statistical comparisons of classifiers over multiple data sets,
J. Demšar, “Statistical comparisons of classifiers over multiple data sets,”Journal of Machine Learning Research, vol. 7, pp. 1–30, 2006
2006
-
[40]
Controlling the false discovery rate: a practical and powerful approach to multiple testing,
Y . Benjamini and Y . Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,”Journal of the Royal Statistical Society: Series B (Methodological), vol. 57, no. 1, pp. 289–300, 1995
1995
-
[41]
On a test of whether one of two random variables is stochasti- cally larger than the other,
H. B. Mann and D. R. Whitney, “On a test of whether one of two random variables is stochasti- cally larger than the other,”The Annals of Mathematical Statistics, pp. 50–60, 1947
1947
-
[42]
Jackknife resampling,
H. Friedl and E. Stampfer, “Jackknife resampling,” inEncyclopedia of Environmetrics(A. H. El-Shaarawi and W. W. Piegorsch, eds.), John Wiley & Sons, 2002
2002
-
[43]
TabRepo: A Large Scale Repository of Tabular Model Evaluations and its AutoML Applications,
D. Salinaset al., “TabRepo: A Large Scale Repository of Tabular Model Evaluations and its AutoML Applications,” inProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[44]
XGBoost: A Scalable Tree Boosting System,
T. Chen and C. Guestrin, “XGBoost: A Scalable Tree Boosting System,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pp. 785–794, 2016
2016
-
[45]
A Memetic Algorithm for Evolutionary Prototype Selection: A Scaling Up Approach,
S. García, J. R. Cano, and F. Herrera, “A Memetic Algorithm for Evolutionary Prototype Selection: A Scaling Up Approach,”Pattern Recognition, vol. 41, no. 8, pp. 2693–2709, 2008
2008
-
[46]
k-means++: The Advantages of Careful Seeding,
D. Arthur and S. Vassilvitskii, “k-means++: The Advantages of Careful Seeding,” inProceed- ings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pp. 1027–1035, 2007. 12 A Societal Impact Statement We do not identify significant foreseeable risks associated with this work beyond those already present in existing unsupervised instance se...
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.