Maat: The Agentic Legal Research Assistant for Competition Protection
Pith reviewed 2026-06-29 16:33 UTC · model grok-4.3
The pith
Maat is a ReAct agent that grounds competition law research in official sources via RAG and web fallback, outperforming general assistants on case-specific tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
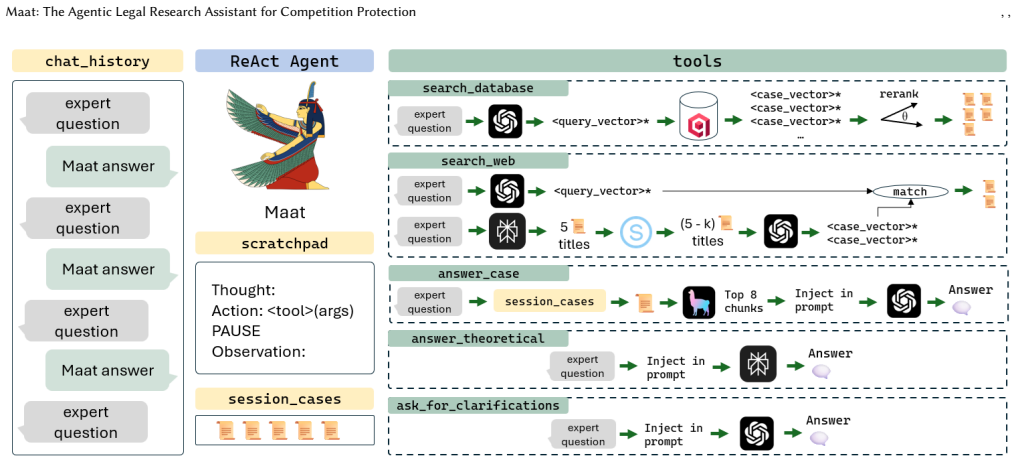
Maat significantly outperforms all baseline assistants on case-specific tasks and performs within range of the top baseline on theoretical question tasks by using a ReAct loop to call specialized tools, retrieving from an official-source RAG index for grounding and citations, and invoking web search only when database coverage is insufficient.
What carries the argument
ReAct agent that orchestrates task-specific tools, combined with RAG over official competition-law sources for citations and a web-search fallback for coverage gaps.
If this is right
- Competition-law practitioners could reduce time spent manually cross-checking precedents while maintaining traceability to official documents.
- The same agent structure could be adapted to other regulatory domains that rely on large bodies of case decisions.
- Releasing the evaluation dataset allows direct comparison of future agents on the same case-specific and theoretical benchmarks.
- Prompting users for clarification on ambiguous queries reduces downstream errors in precedent identification.
Where Pith is reading between the lines
- If the reliability claims hold, similar agent designs could shorten the review cycle for merger filings that currently require extensive manual case retrieval.
- Extending the RAG index to include more recent decisions would be a direct next step to test whether performance gains persist as the case corpus grows.
- The approach suggests that tool orchestration plus source grounding may be more important than model size alone for domain-specific legal accuracy.
Load-bearing premise
The RAG index and web-search fallback will retrieve and cite only accurate official sources without coverage gaps or errors that change the measured performance advantage.
What would settle it
A blind test set of competition-law queries where Maat produces a higher rate of incorrect case citations or fabricated precedents than the strongest baseline.
Figures
read the original abstract
Competition law experts conducting legal research must review extensive volumes of cases, decisions, and judicial reports to identify precedents and assess key elements in competition and merger cases. Although general research assistants such as Claude and ChatGPT and legal assistants such as SaulLM-7B and LegalGPT are increasingly used to assist legal research, they remain inadequate for competition law analysis: they lack specialized domain expertise, provide insufficient official citations, or hallucinate competition law cases. We propose Maat, a ReAct agent that orchestrates tools corresponding to different tasks of the research process. Designed iteratively with competition law experts, Maat grounds cases and findings in official sources using RAG for reliability, provides rich in-line citations, falls back to web search when database coverage is insufficient, and prompts the user for clarification when queries are ambiguous. Maat significantly outperforms all baseline assistants on case-specific tasks and performs within range of the top baseline on theoretical question tasks. The dataset used is available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Maat, a ReAct agent for competition-law research that orchestrates specialized tools, uses RAG to ground answers in official sources with rich citations, falls back to web search for coverage gaps, and seeks user clarification on ambiguous queries. It claims that Maat significantly outperforms general assistants (Claude, ChatGPT) and legal assistants (SaulLM-7B, LegalGPT) on case-specific tasks while performing within the range of the top baseline on theoretical questions; a dataset is released on GitHub.
Significance. If the performance claims were supported by rigorous, reproducible evaluation, the work would demonstrate a practical advance in domain-specialized agentic systems for legal research by showing how tool orchestration and source grounding can reduce hallucinations relative to general LLMs.
major comments (3)
- [Evaluation / Abstract] Evaluation section (and abstract): the headline claim that Maat 'significantly outperforms all baseline assistants on case-specific tasks' is presented without any reported metrics, baseline descriptions, statistical tests, error analysis, or task counts, so the data cannot be checked against the claim.
- [System description / Evaluation] RAG and web-search description: the system is said to 'ground cases and findings in official sources using RAG' and to 'provide rich in-line citations,' yet no quantitative measurement of citation error rate, coverage gaps, or hallucinated precedents is supplied; this is load-bearing for the reliability and outperformance assertions.
- [Dataset / Evaluation] Dataset and reproducibility: while the dataset is stated to be available on GitHub, the paper supplies no details on how the case-specific and theoretical tasks were constructed, how baselines were prompted or evaluated, or any inter-annotator agreement for the expert-designed tasks.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction repeatedly use 'competition protection' and 'competition law' interchangeably without clarifying whether the scope is limited to EU, US, or multi-jurisdictional sources.
- [System architecture] No explicit list or description of the 'tools corresponding to different tasks of the research process' is provided, making the ReAct orchestration hard to replicate from the text alone.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important gaps in the presentation of evaluation results, system reliability metrics, and methodological details. We address each point below and will revise the manuscript to provide the requested rigor and transparency.
read point-by-point responses
-
Referee: [Evaluation / Abstract] Evaluation section (and abstract): the headline claim that Maat 'significantly outperforms all baseline assistants on case-specific tasks' is presented without any reported metrics, baseline descriptions, statistical tests, error analysis, or task counts, so the data cannot be checked against the claim.
Authors: We agree that the current version of the manuscript does not supply the quantitative details needed to substantiate the performance claims. In the revision we will expand the evaluation section (and update the abstract) to report concrete metrics, full baseline prompting and evaluation protocols, task counts, statistical significance tests, and error analysis. revision: yes
-
Referee: [System description / Evaluation] RAG and web-search description: the system is said to 'ground cases and findings in official sources using RAG' and to 'provide rich in-line citations,' yet no quantitative measurement of citation error rate, coverage gaps, or hallucinated precedents is supplied; this is load-bearing for the reliability and outperformance assertions.
Authors: The observation is correct: the manuscript currently lacks quantitative assessment of citation accuracy, coverage, or hallucination rates. We will add an evaluation subsection that measures citation error rates (via expert review or automated verification against official sources), quantifies coverage gaps, and reports any detected hallucinated precedents. revision: yes
-
Referee: [Dataset / Evaluation] Dataset and reproducibility: while the dataset is stated to be available on GitHub, the paper supplies no details on how the case-specific and theoretical tasks were constructed, how baselines were prompted or evaluated, or any inter-annotator agreement for the expert-designed tasks.
Authors: We will insert a new subsection that fully describes task construction (including expert involvement), baseline prompting templates and evaluation procedures, and any inter-annotator or expert-validation steps used. The GitHub repository will be updated with corresponding documentation and scripts. revision: yes
Circularity Check
No circularity: empirical system evaluation with external baselines
full rationale
The paper describes an agent architecture (ReAct + RAG + web fallback) and reports empirical outperformance on case-specific tasks versus named external baselines (Claude, ChatGPT, SaulLM-7B, LegalGPT). No equations, fitted parameters, or predictions appear. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The central claim is a direct comparison to independent systems, not a reduction to the paper's own definitions or prior self-citations. This is the normal non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RAG retrieval from official sources will produce reliable, non-hallucinated citations for competition law cases
invented entities (1)
-
Maat ReAct agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026.Claude Sonnet 4.6 System Card
Anthropic. 2026.Claude Sonnet 4.6 System Card. Technical Report. https: //www.anthropic.com/claude-sonnet-4-6-system-card
2026
-
[2]
Farid Ariai, Joel Mackenzie, and Gianluca Demartini. 2025. Natural language pro- cessing for the legal domain: A survey of tasks, datasets, models, and challenges. Comput. Surveys58, 6 (2025), 1–37
2025
-
[3]
In: European Conference on Com- puter Vision
Felix Beuter, Johannes Gussenbauer, Elias Minther, Viktoria Szabo, and Susanne Wegner. 2025.Approaches to Automated NACE Coding of German Business Activity Descriptions. Springer Nature Switzerland, Cham, 179–211. doi:10.1007/978-3- 032-10004-7_10
-
[4]
Bundeskartellamt. 2024. Entscheidungen [Decisions]. https://www. bundeskartellamt.de/SharedDocs/Entscheidung/. Official decision database of the German Federal Cartel Office, published pursuant to § 5 UrhG
2024
- [5]
-
[6]
Concurrences. [n. d.]. Concurrences: Competition Law Review. https://www. concurrences.com/en/
- [7]
-
[8]
Directorate-General for Competition, European Commission. 2026. EU Com- petition Case Search. https://competition-cases.ec.europa.eu/search. Offi- cial European Commission database for antitrust, cartel, merger, and state aid cases distributed in JSON format. License: European Commission Reuse Notice (Dec. 2011/833/OJ)
2026
-
[9]
Rajaa El Hamdani, Thomas Bonald, Fragkiskos D Malliaros, Nils Holzenberger, and Fabian Suchanek. 2024. The factuality of large language models in the legal domain. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 3741–3746
2024
-
[10]
Eternal Space. [n. d.]. Maat (Goddess). https://commons.wikimedia.org/wiki/File: Maat_(Goddess).png Licensed under CC BY-SA 4.0
-
[11]
European Commission. [n. d.]. Antitrust and Cartels: Procedures. https:// competition-policy.ec.europa.eu/antitrust-and-cartels/procedures_en
-
[12]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling large lan- guage models to generate text with citations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 6465–6488
2023
-
[13]
Ginsburg and Tim Eicke (Eds.)
Douglas H. Ginsburg and Tim Eicke (Eds.). 2023.Judicial Review of Competition Cases. Concurrences. Multi-jurisdictional comparative study
2023
-
[14]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, chal- lenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
2025
-
[15]
Internet Archive. [n. d.]. Wayback Machine APIs. https://archive.org/help/ wayback_api.php. Documents the Wayback Availability JSON API and CDX Server API
- [16]
-
[17]
Radhika V Kulkarni, Avish Agrawal, Aryan Vimal, Rohan Barde, Raghav Bajaj, and Khursheed Gaddi. 2025. Legal Case Search: An AI-Powered Legal Search Engine. InInternational Conference on ICT for Sustainable Development. Springer, 354–363
2025
-
[18]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[19]
LexiAI. [n. d.]. Legal GPT. https://chatgpt.com/g/g-jxqQ0lepc-legal-gpt
-
[20]
Bulou Liu, Yiran Hu, Qingyao Ai, Yiqun Liu, Yueyue Wu, Chenliang Li, and Weixing Shen. 2023. Leveraging event schema to ask clarifying questions for conversational legal case retrieval. InProceedings of the 32nd ACM international conference on information and knowledge management. 1513–1522
2023
-
[21]
LlamaIndex. 2025. Embeddings. https://developers.llamaindex.ai/python/ framework/module_guides/models/embeddings/ LlamaIndex Developer Docu- mentation
2025
-
[22]
LlamaIndex. 2025. Introduction to RAG. https://developers.llamaindex.ai/python/ framework/understanding/rag/ LlamaIndex Developer Documentation
2025
-
[23]
LlamaIndex. 2025. Loading Data (Ingestion). https://developers.llamaindex.ai/ python/framework/understanding/rag/loading/ LlamaIndex Developer Docu- mentation
2025
- [24]
-
[25]
Antoine Louis, Gijs Van Dijck, and Gerasimos Spanakis. 2024. Interpretable long-form legal question answering with retrieval-augmented large language models. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 22266–22275
2024
-
[26]
2024.The Standard and Burden of Proof in Competition Law Cases
OECD. 2024.The Standard and Burden of Proof in Competition Law Cases. Techni- cal Report. OECD Competition Committee. https://doi.org/10.1787/0199f63f-en
-
[27]
OpenAI. 2024. GPT-4o mini: Advancing Cost-Efficient Intelligence. https:// openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/
2024
-
[28]
2026.GPT-5.5 System Card
OpenAI. 2026.GPT-5.5 System Card. Technical Report. OpenAI. https://openai. com/index/gpt-5-5-system-card/ Accessed: May 2026
2026
-
[29]
Organisation for Economic Co-operation and Development. [n. d.]. OECD. https: //www.oecd.org/en.html
-
[30]
Perplexity AI. 2025. Meet New Sonar. Perplexity Blog. https://www.perplexity. ai/hub/blog/meet-new-sonar
2025
- [31]
-
[32]
Albert Sadowski and Jaroslaw A Chudziak. 2025. On verifiable legal reasoning: A multi-agent framework with formalized knowledge representations. InPro- ceedings of the 34th ACM International Conference on Information and Knowledge Management. 2535–2545
2025
-
[33]
Serper. 2025. Serper: Google Search API. https://serper.dev/
2025
-
[34]
Reasoning before Responding
Utkarsh Ujwal, Sai Sri Harsha Surampudi, Sayantan Mitra, and Tulika Saha. 2024. " Reasoning before Responding": Towards Legal Long-form Question Answering with Interpretability. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 4922–4930
2024
-
[35]
Rahman SM Wahidur, Sumin Kim, Haeung Choi, David S Bhatti, and Heung-No Lee. 2025. Legal query rag.IEEE Access(2025)
2025
- [36]
-
[37]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[38]
Wikipedia contributors. [n. d.]. Maat. https://en.wikipedia.org/wiki/Maat
-
[39]
Rujing Yao, Yang Wu, Chenghao Wang, Jingwei Xiong, Fang Wang, and Xi- aozhong Liu. 2025. Elevating legal LLM responses: harnessing trainable logical structures and semantic knowledge with legal reasoning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologie...
2025
-
[40]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [41]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.