Towards Controllable Image Generation through Representation-Conditioned Diffusion Models
Pith reviewed 2026-06-29 18:01 UTC · model grok-4.3
The pith
Conditioning diffusion models on representations from pre-trained self-supervised models improves unconditional generation quality and enables control via variation directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
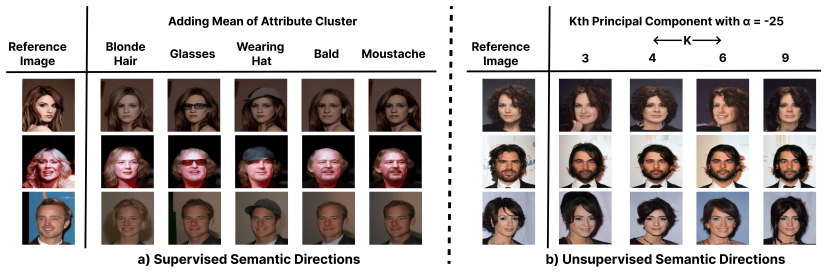
The central claim is that the self-conditioning mechanism not only improves the quality of unconditional image generation, but also provides a representation space that can be used to control the generation. The authors explore this conditioning space by identifying directions of variations and demonstrate promising properties in terms of smoothness and disentanglement.
What carries the argument
The self-conditioning mechanism that conditions the diffusion model on representations from a pre-trained self-supervised model, serving as both a quality booster and a controllable latent space.
If this is right
- Unconditional image generation quality increases without external conditions.
- Directions identified in the representation space allow control over generated images.
- Changes along those directions remain smooth.
- Different directions control separate attributes due to disentanglement.
Where Pith is reading between the lines
- This approach could reduce dependence on text or semantic annotations for guiding diffusion models.
- The same conditioning space might support image editing by moving along the discovered directions.
- Different choices of pre-trained self-supervised model could be tested to find which representations yield the strongest control.
- The method may transfer to other generative architectures beyond diffusion models.
Load-bearing premise
Representations extracted from an off-the-shelf pre-trained self-supervised model form a suitable latent space for both quality improvement and controllable generation without further adaptation or task-specific training.
What would settle it
If quantitative metrics show no improvement in unconditional generation quality, or if varying along the identified directions produces abrupt or entangled changes instead of smooth disentangled ones.
Figures



read the original abstract
Diffusion models have emerged as powerful tools for high-quality image generation and editing, but guiding these models to produce specific outputs remains a challenge. Conventional approaches rely on conditioning mechanisms, such as text prompts or semantic maps, which require extensively annotated datasets. In this preliminary work, we explore diffusion models conditioned on representations from a pre-trained self-supervised model. The self-conditioning mechanism not only improves the quality of unconditional image generation, but also provides a representation space that can be used to control the generation. We explore this conditioning space by identifying directions of variations, and demonstrate promising properties in terms of smoothness and disentanglement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper explores conditioning diffusion models on representations extracted from pre-trained self-supervised models. It claims that this self-conditioning mechanism improves the quality of unconditional image generation while also yielding a representation space that supports controllable generation via identification of variation directions, with promising properties in smoothness and disentanglement, all without requiring annotated datasets such as text prompts or semantic maps.
Significance. If the empirical claims hold, the approach could offer a data-efficient alternative for controllable diffusion-based generation by repurposing existing SSL models, reducing reliance on labeled conditioning data and potentially enabling new editing capabilities through the learned representation space.
major comments (2)
- [Abstract] Abstract: The manuscript asserts that self-conditioning 'improves the quality of unconditional image generation' and yields 'promising properties in terms of smoothness and disentanglement,' yet provides no quantitative metrics, baselines, ablation studies, or error analysis to support these claims. This absence is load-bearing, as the central contribution is an empirical exploration whose validity cannot be assessed from the given text.
- [Abstract] Abstract: The approach assumes that representations from an off-the-shelf pre-trained SSL model (e.g., SimCLR/DINO-style) simultaneously enhance generation quality and form a latent space with traversable, disentangled directions. However, SSL objectives explicitly encourage invariance to augmentations and other factors, which may collapse the very axes needed for control; no discussion, justification, or test of this compatibility is provided.
Simulated Author's Rebuttal
We thank the referee for their comments. As this is presented as preliminary work, we address the concerns regarding empirical support and theoretical compatibility below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that self-conditioning 'improves the quality of unconditional image generation' and yields 'promising properties in terms of smoothness and disentanglement,' yet provides no quantitative metrics, baselines, ablation studies, or error analysis to support these claims. This absence is load-bearing, as the central contribution is an empirical exploration whose validity cannot be assessed from the given text.
Authors: We agree that the current version lacks quantitative metrics, baselines, and ablations to support the claims on generation quality and representation properties. The manuscript is explicitly preliminary and relies on qualitative demonstrations. In revision we will add FID scores for unconditional generation quality, quantitative measures of smoothness and disentanglement, and comparisons against standard unconditional diffusion baselines. revision: yes
-
Referee: [Abstract] Abstract: The approach assumes that representations from an off-the-shelf pre-trained SSL model (e.g., SimCLR/DINO-style) simultaneously enhance generation quality and form a latent space with traversable, disentangled directions. However, SSL objectives explicitly encourage invariance to augmentations and other factors, which may collapse the very axes needed for control; no discussion, justification, or test of this compatibility is provided.
Authors: The potential tension between SSL invariance objectives and the need for traversable variation axes is a substantive point. While our empirical observations indicate that usable semantic variation remains, the manuscript provides no explicit discussion or targeted test of this compatibility. We will add a dedicated paragraph in the revised version analyzing preserved versus collapsed factors and, where feasible, supporting analysis. revision: partial
Circularity Check
No circularity; empirical exploration only
full rationale
The paper presents an empirical study of conditioning diffusion models on frozen off-the-shelf self-supervised representations. No equations, fitted parameters, or derivation steps are described that would reduce any claim to a self-referential definition or a renamed input. The abstract and provided text contain no self-citations invoked as load-bearing uniqueness theorems, no ansatzes smuggled via prior work, and no predictions that are statistically forced by construction. The central claims rest on reported experimental outcomes (quality improvement and observed smoothness/disentanglement) rather than any algebraic or definitional reduction to the inputs themselves.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generative adver- sarial networks,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adver- sarial networks,”Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020
2020
-
[2]
Interpreting the latent space of gans for semantic face editing,
Y . Shen, J. Gu, X. Tang, and B. Zhou, “Interpreting the latent space of gans for semantic face editing,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9243–9252
2020
-
[3]
Image2stylegan: How to embed images into the stylegan latent space?
R. Abdal, Y . Qin, and P. Wonka, “Image2stylegan: How to embed images into the stylegan latent space?” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4432–4441
2019
-
[4]
Ganspace: Discovering interpretable gan controls,
E. H ¨ark¨onen, A. Hertzmann, J. Lehtinen, and S. Paris, “Ganspace: Discovering interpretable gan controls,”Advances in neural infor- mation processing systems, vol. 33, pp. 9841–9850, 2020
2020
-
[5]
Training on thin air: Im- prove image classification with generated data,
Y . Zhou, H. Sahak, and J. Ba, “Training on thin air: Im- prove image classification with generated data,”arXiv preprint arXiv:2305.15316, 2023
-
[6]
Diffusion models already have a semantic latent space,
M. Kwon, J. Jeong, and Y . Uh, “Diffusion models already have a semantic latent space,”arXiv preprint arXiv:2210.10960, 2022
-
[7]
Discovering interpretable directions in the semantic latent space of diffusion models,
R. Haas, I. Huberman-Spiegelglas, R. Mulayoff, S. Graßhof, S. S. Brandt, and T. Michaeli, “Discovering interpretable directions in the semantic latent space of diffusion models,” in2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 2024, pp. 1–9
2024
-
[8]
Diffusion autoencoders: Toward a meaningful and de- codable representation,
K. Preechakul, N. Chatthee, S. Wizadwongsa, and S. Suwa- janakorn, “Diffusion autoencoders: Toward a meaningful and de- codable representation,” inProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, 2022, pp. 10 619–10 629
2022
-
[9]
Return of unconditional generation: A self-supervised representation generation method,
T. Li, D. Katabi, and K. He, “Return of unconditional generation: A self-supervised representation generation method,”Advances in Neural Information Processing Systems, vol. 37, pp. 125 441– 125 468, 2025
2025
-
[10]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[11]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
R. Gal, Y . Alaluf, Y . Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-Or, “An image is worth one word: Personalizing text-to-image generation using textual inversion,” arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aber- man, “Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22 500–22 510
2023
-
[13]
Multi-concept customization of text-to-image diffusion,
N. Kumari, B. Zhang, R. Zhang, E. Shechtman, and J.-Y . Zhu, “Multi-concept customization of text-to-image diffusion,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1931–1941
2023
-
[14]
High fidelity visual- ization of what your self-supervised representation knows about,
F. Bordes, R. Balestriero, and P. Vincent, “High fidelity visual- ization of what your self-supervised representation knows about,” arXiv preprint arXiv:2112.09164, 2021
-
[15]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bo- janowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF interna- tional conference on computer vision, 2021, pp. 9650–9660
2021
-
[16]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
F. Yu, A. Seff, Y . Zhang, S. Song, T. Funkhouser, and J. Xiao, “Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop,”arXiv preprint arXiv:1506.03365, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Large-scale celebfaces attributes (celeba) dataset,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Large-scale celebfaces attributes (celeba) dataset,”Retrieved August, vol. 15, no. 2018, p. 11, 2018
2018
-
[18]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[19]
An analysis of single-layer networks in unsupervised feature learning,
A. Coates, A. Ng, and H. Lee, “An analysis of single-layer networks in unsupervised feature learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 215–223
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.