Natural Language Query to Configuration for Retrieval Agents
Pith reviewed 2026-06-29 17:41 UTC · model grok-4.3
The pith
BRANE selects retrieval pipeline configurations per query by predicting success from LLM-extracted traits to optimize accuracy against cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
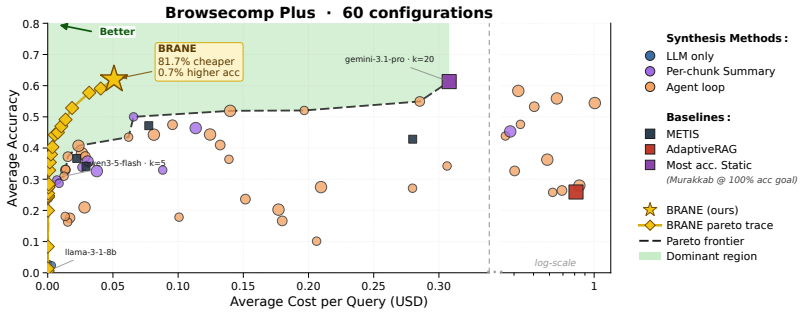
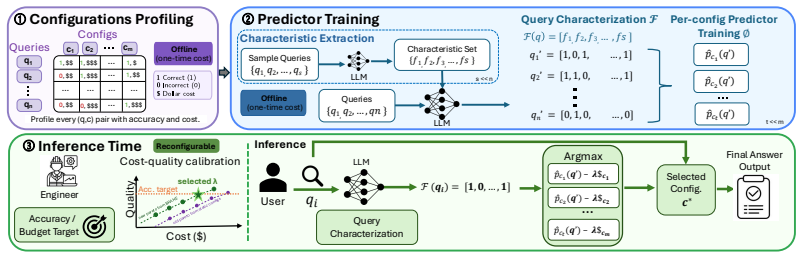
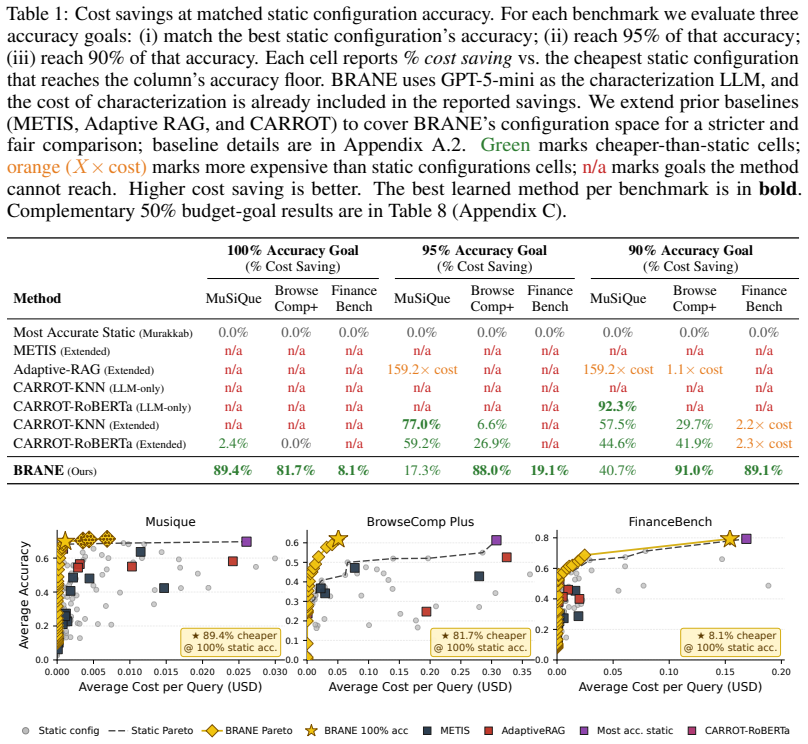
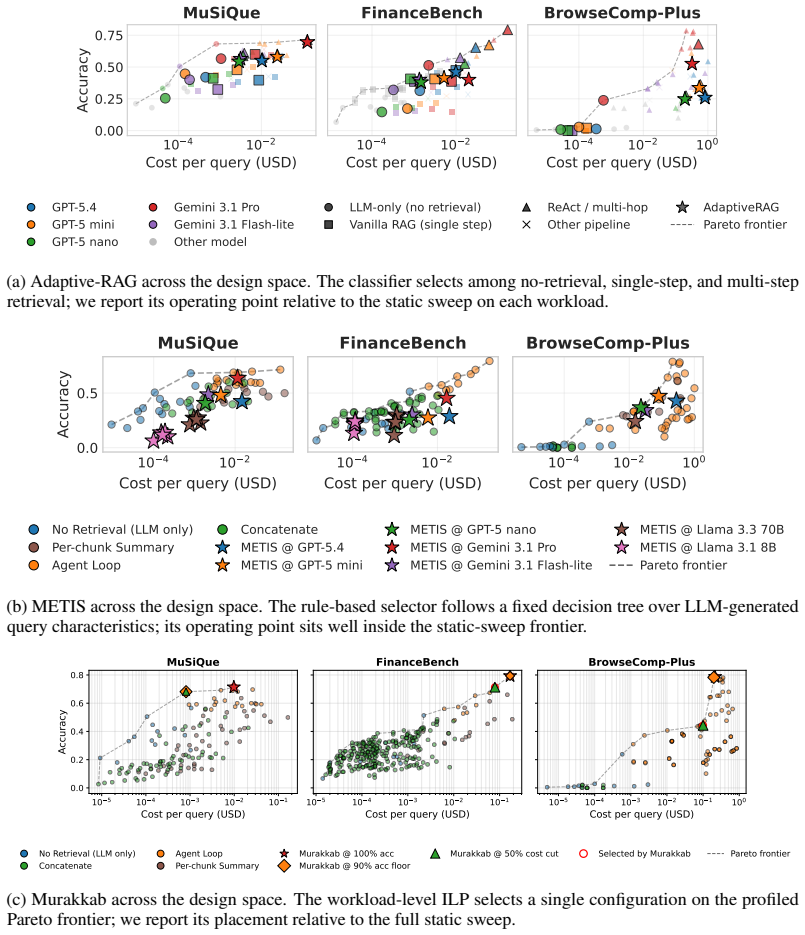
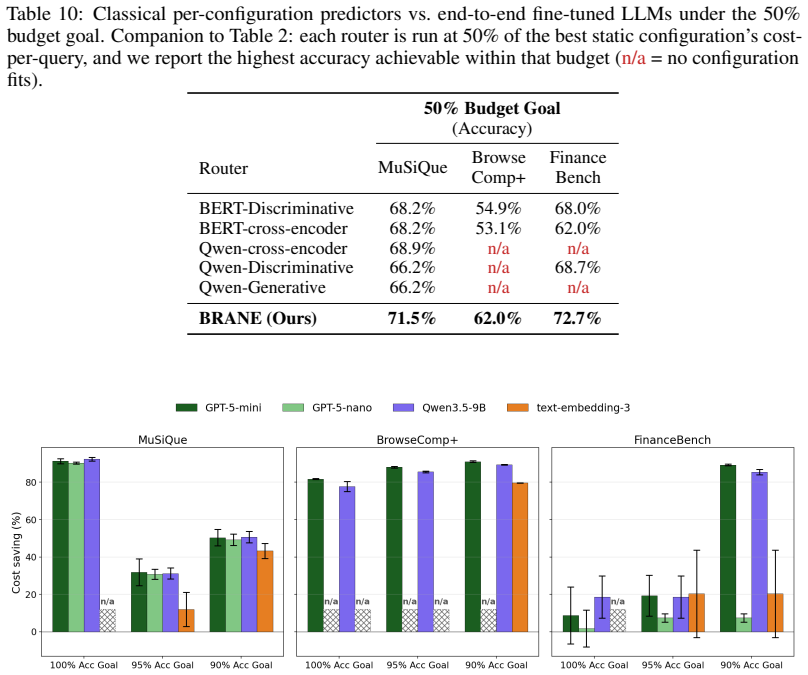
Given a natural-language query and either an accuracy or budget target, BRANE converts the query into workload-specific characteristics with an LLM, trains a lightweight predictor per configuration to estimate whether that pipeline will answer correctly, and at inference selects the configuration that maximizes predicted correctness penalized by cost. This produces a tunable cost-quality frontier without retraining. On MuSiQue, BrowseComp-Plus, and FinanceBench the method matches the accuracy of the best fixed configuration at up to 89 percent lower cost and outperforms LLM-routing, rule-based, and fine-tuned Qwen3-4B baselines.
What carries the argument
Lightweight per-configuration predictors that estimate success probability from LLM-derived query characteristics and are used at inference to select the cost-penalized best pipeline.
If this is right
- Matches the accuracy of the best fixed configuration at up to 89 percent lower cost across the tested benchmarks.
- Outperforms LLM-routing, rule-based, and fine-tuned Qwen3-4B baselines on MuSiQue, BrowseComp-Plus, and FinanceBench.
- Pushes the cost-quality Pareto frontier for each workload while exposing a tunable tradeoff parameter.
- Enables per-query configuration of the full retrieval pipeline as a practical alternative to static workload-level tuning.
Where Pith is reading between the lines
- The same predictor-based selection could be applied to other agent stages such as tool choice or synthesis strategy without changing the core training procedure.
- If the query-characteristic predictors prove stable, production systems could replace periodic manual retuning with continuous automated selection.
- Collecting correctness labels at serving time would allow the predictors to be updated online, potentially reducing the initial training data requirement.
- The approach suggests a general pattern for turning any multi-choice agent pipeline into a query-adaptive system by training cheap success estimators.
Load-bearing premise
The lightweight predictors trained on LLM-derived query characteristics will accurately estimate success probability on unseen queries without substantial distribution shift or overfitting.
What would settle it
Running BRANE on a new query distribution where its selected configurations fail to match the best fixed accuracy at the claimed cost reduction or fall below the strongest baseline.
Figures

read the original abstract
Modern retrieval agents expose many configuration choices -- LLM, retriever, number of documents, number of hops, and synthesis strategy -- each shaping both answer quality and serving cost. Today, these pipelines are typically hand-tuned once per workload, leaving substantial per-query optimization untapped. We formulate the problem: given a natural-language query and either an accuracy or a budget target, select from a predefined pipeline catalog the configuration that minimizes cost or maximizes accuracy at inference time. We propose **BRANE**, which uses an LLM to convert each query into workload-specific characteristics, then trains a lightweight per-configuration predictor that estimates whether the pipeline will answer the query correctly. At inference time, **BRANE** selects the configuration that maximizes predicted correctness penalized by cost, exposing a tunable cost-quality tradeoff without retraining. Across MuSiQue, BrowseComp-Plus, and FinanceBench, **BRANE** consistently pushes the cost-quality Pareto frontier, matches the best fixed configuration's accuracy at up to 89% lower cost, and outperforms LLM-routing, rule-based, and fine-tuned Qwen3-4B baselines. These results show that per-query configuration of the full retrieval pipeline is a practical alternative to static workload-level tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BRANE for per-query configuration selection in retrieval agents. An LLM extracts query characteristics, lightweight per-configuration predictors are trained to estimate success probability, and at inference the configuration maximizing predicted success minus lambda times cost is selected. On MuSiQue, BrowseComp-Plus, and FinanceBench, it is claimed to push the cost-quality Pareto frontier, match best fixed configuration accuracy at up to 89% lower cost, and outperform LLM-routing, rule-based, and fine-tuned Qwen3-4B baselines.
Significance. If the per-configuration predictors generalize well to unseen queries, this work could enable significant efficiency improvements in retrieval-augmented systems by allowing dynamic, query-specific optimization of the full pipeline without retraining. The tunable tradeoff and avoidance of per-workload hand-tuning are practical strengths.
major comments (2)
- [Abstract] The abstract reports concrete performance gains but provides no details on training data splits, predictor architecture, statistical significance, or error bars. This information is load-bearing for assessing whether the reported cost savings and outperformance are reliable.
- [BRANE method description] The inference-time selection rule relies on the predictors producing well-calibrated success probabilities on unseen queries. No metrics such as AUC, calibration error, or train-test performance differences are provided, which directly impacts the validity of the central claim that BRANE improves the Pareto frontier over baselines.
minor comments (1)
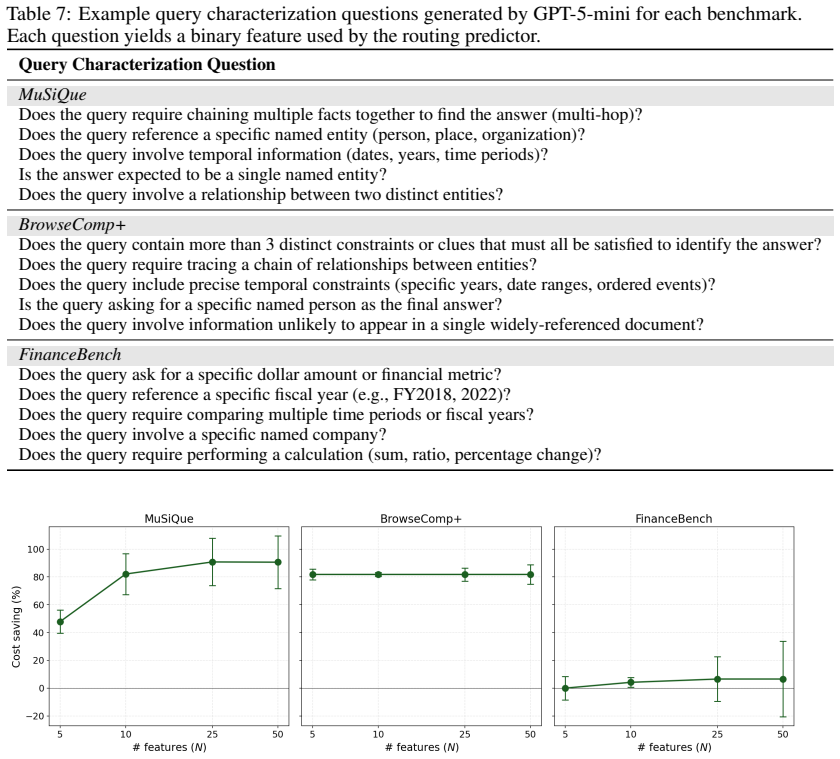
- The abstract could benefit from a brief mention of the number of configurations in the catalog or the specific query features extracted by the LLM.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of clarity and empirical validation. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract reports concrete performance gains but provides no details on training data splits, predictor architecture, statistical significance, or error bars. This information is load-bearing for assessing whether the reported cost savings and outperformance are reliable.
Authors: The abstract is written to be concise while conveying the core contribution. The full manuscript details the 80/20 query-level train-test splits, the per-configuration lightweight MLP predictors (two hidden layers of size 64), and statistical significance via 5 runs with standard error bars in Sections 3 and 4. To improve self-containment, we will expand the abstract with one sentence summarizing these elements. revision: yes
-
Referee: [BRANE method description] The inference-time selection rule relies on the predictors producing well-calibrated success probabilities on unseen queries. No metrics such as AUC, calibration error, or train-test performance differences are provided, which directly impacts the validity of the central claim that BRANE improves the Pareto frontier over baselines.
Authors: The primary validation is end-to-end: the selected configurations improve the measured Pareto frontier on held-out queries across three benchmarks, outperforming fixed, LLM-routing, and fine-tuned baselines. This provides task-level evidence that the predictors support effective selection. We agree that explicit calibration diagnostics would further support the claim and will add a subsection reporting AUC-ROC, ECE, and train/test accuracy gaps for the predictors. revision: yes
Circularity Check
No circularity; predictors trained independently on features and labels
full rationale
The described method extracts query characteristics via LLM, runs configurations on queries to obtain correctness labels, trains separate lightweight predictors per configuration, and at inference selects via argmax of predicted success minus cost. This is standard supervised ML with no equations shown, no self-definitional loops, no fitted inputs renamed as predictions by construction, and no load-bearing self-citations. The derivation chain is self-contained against external benchmarks and does not reduce to its inputs tautologically.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The distracting effect: Understanding irrelevant passages in rag
Chen Amiraz, Florin Cuconasu, Simone Filice, and Zohar Karnin. The distracting effect: Understanding irrelevant passages in rag. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page 18228–18258. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.acl-long.892. URL http:/...
-
[2]
RAG over Thinking Traces Can Improve Reasoning Tasks
Negar Arabzadeh, Wenjie Ma, Sewon Min, and Matei Zaharia. Rag over thinking traces can improve reasoning tasks, 2026. URLhttps://arxiv.org/abs/2605.03344
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Openscholar: Synthesizing scientific literature with retrieval-augmented lms, 2024
Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D’arcy, David Wadden, Matt Latzke, Minyang Tian, Pan Ji, Shengyan Liu, Hao Tong, Bohao Wu, Yanyu Xiong, Luke Zettlemoyer, Graham Neubig, Dan Weld, Doug Downey, Wen tau Yih, Pang Wei Koh, and Hannaneh Hajishirzi. Openscholar: ...
-
[4]
Murakkab: Resource-efficient agentic workflow orchestration in cloud platforms, 2025
Gohar Irfan Chaudhry, Esha Choukse, Haoran Qiu, Íñigo Goiri, Rodrigo Fonseca, Adam Belay, and Ricardo Bianchini. Murakkab: Resource-efficient agentic workflow orchestration in cloud platforms, 2025. URLhttps://arxiv.org/abs/2508.18298
-
[5]
Frugalgpt: How to use large language models while reducing cost and improving performance, 2023
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance, 2023. URLhttps://arxiv.org/abs/2305. 05176
2023
-
[6]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 785–794. ACM, August 2016. doi: 10.1145/2939672.2939785. URL http://dx.doi.org/10.1145/2939672.2939785
-
[7]
Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent, 2025
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Sharifymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent, 2025. ...
-
[8]
syftr: Pareto-optimal generative ai, 2025
Alexander Conway, Debadeepta Dey, Stefan Hackmann, Matthew Hausknecht, Michael Schmidt, Mark Steadman, and Nick V olynets. syftr: Pareto-optimal generative ai, 2025. URLhttps://arxiv.org/abs/2505.20266
-
[9]
The power of noise: Redefining retrieval for rag systems
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. The power of noise: Redefining retrieval for rag systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 719–729, 2024
2024
-
[10]
FinanceBench: A New Benchmark for Financial Question Answering
Islam et al. Financebench: A new benchmark for financial question answering.arXiv preprint arXiv:2311.11944, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Gemini deep research: Your personal research assistant
Google. Gemini deep research: Your personal research assistant. https://gemini.google/ overview/deep-research/, 2026. Accessed: 2026-05-06
2026
-
[12]
How we built our multi-agent research system
Jeremy Hadfield, Barry Zhang, Kenneth Lien, Florian Scholz, Jeremy Fox, and Daniel Ford. How we built our multi-agent research system. https://www.anthropic.com/ engineering/multi-agent-research-system , June 2025. Anthropic Engineering Blog. Accessed: 2026-05-05
2025
-
[13]
RouterBench: A Benchmark for Multi-LLM Routing System
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. Routerbench: A benchmark for multi-llm routing system.arXiv preprint arXiv:2403.12031, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Hedrarag: Coordinating llm generation and database retrieval in heterogeneous rag serving,
Zhengding Hu, Vibha Murthy, Zaifeng Pan, Wanlu Li, Xiaoyi Fang, Yufei Ding, and Yuke Wang. Hedrarag: Coordinating llm generation and database retrieval in heterogeneous rag serving,
- [15]
-
[16]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C. Park. Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity,
- [17]
-
[18]
Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
2017
-
[19]
vLLM Semantic Router: Signal Driven Decision Routing for Mixture-of-Modality Models
Xunzhuo Liu, Huamin Chen, Samzong Lu, Yossi Ovadia, Guohong Wen, Hao Wu, Zhengda Tan, Jintao Zhang, Senan Zedan, Yehudit Kerido, Liav Weiss, Haichen Zhang, Bishen Yu, Asaad Balum, Noa Limoy, Abdallah Samara, Baofa Fan, Brent Salisbury, Ryan Cook, Zhijie Wang, Qiping Pan, Rehan Khan, Avishek Goswami, Houston H. Zhang, Shuyi Wang, Ziang Tang, Fang Han, Zoha...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Omnirouter: Budget and performance controllable multi-llm routing.ACM SIGKDD Explorations Newsletter, 27(2): 107–116, 2025
Kai Mei, Wujiang Xu, Minghao Guo, Shuhang Lin, and Yongfeng Zhang. Omnirouter: Budget and performance controllable multi-llm routing.ACM SIGKDD Explorations Newsletter, 27(2): 107–116, 2025
2025
-
[21]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data, 2025. URLhttps://arxiv.org/abs/2406.18665
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Introducing deep research
OpenAI. Introducing deep research. https://openai.com/index/ introducing-deep-research/, February 2025. OpenAI Release. Accessed: 2026- 05-05
2025
-
[23]
Melissa Z. Pan, Negar Arabzadeh, Riccardo Cogo, Yuxuan Zhu, Alexander Xiong, Lakshya A Agrawal, Huanzhi Mao, Emma Shen, Sid Pallerla, Liana Patel, Shu Liu, Tianneng Shi, Xiaoyuan Liu, Jared Quincy Davis, Emmanuele Lacavalla, Alessandro Basile, Shuyi Yang, Paul Castro, Daniel Kang, Joseph E. Gonzalez, Koushik Sen, Dawn Song, Ion Stoica, Matei Zaharia, and ...
2026
-
[24]
Introducing perplexity deep research
Perplexity AI. Introducing perplexity deep research. https://www.perplexity.ai/hub/ blog/introducing-perplexity-deep-research , February 2025. Perplexity Blog. Ac- cessed: 2026-05-06
2025
-
[25]
Akshara Prabhakar, Roshan Ram, Zixiang Chen, Silvio Savarese, Frank Wang, Caiming Xiong, Huan Wang, and Weiran Yao. Enterprise deep research: Steerable multi-agent deep research for enterprise analytics.arXiv preprint arXiv:2510.17797, 2025
-
[26]
ChatDev: Communicative Agents for Software Development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. Chatdev: Communicative agents for software development, 2024. URL https://arxiv.org/abs/ 2307.07924
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Metis: Fast quality-aware rag systems with configuration adaptation
Siddhant Ray, Rui Pan, Zhuohan Gu, Kuntai Du, Shaoting Feng, Ganesh Ananthanarayanan, Ravi Netravali, and Junchen Jiang. Metis: Fast quality-aware rag systems with configuration adaptation. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP ’25, page 606–622, New York, NY , USA, 2025. Association for Computing Machinery. ...
-
[28]
2 million conversations handled by agentforce, and we’re just get- ting started
Jim Roth. 2 million conversations handled by agentforce, and we’re just get- ting started. https://www.salesforce.com/blog/support-requests-agentforce/, November 2025. Salesforce Blog. Accessed: 2026-05-05
2025
-
[29]
Carrot: A cost aware rate optimal router, 2025
Seamus Somerstep, Felipe Maia Polo, Allysson Flavio Melo de Oliveira, Prattyush Mangal, Mírian Silva, Onkar Bhardwaj, Mikhail Yurochkin, and Subha Maity. Carrot: A cost aware rate optimal router, 2025. URLhttps://arxiv.org/abs/2502.03261. 12
-
[30]
Musique: Multihop questions via single-hop question composition, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition, 2022. URL https://arxiv.org/ abs/2108.00573
-
[31]
R2-Router: A New Paradigm for LLM Routing with Reasoning
Jiaqi Xue, Qian Lou, Jiarong Xing, and Heng Huang. R2-router: A new paradigm for llm routing with reasoning, 2026. URLhttps://arxiv.org/abs/2602.02823
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
The shift from models to compound ai systems
Matei Zaharia, Omar Khattab, Lingjiao Chen, Jared Quincy Davis, Heather Miller, Chris Potts, James Zou, Michael Carbin, Jonathan Frankle, Naveen Rao, and Ali Ghodsi. The shift from models to compound ai systems. https://bair.berkeley.edu/blog/2024/02/18/ compound-ai-systems/, 2024
2024
-
[33]
DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
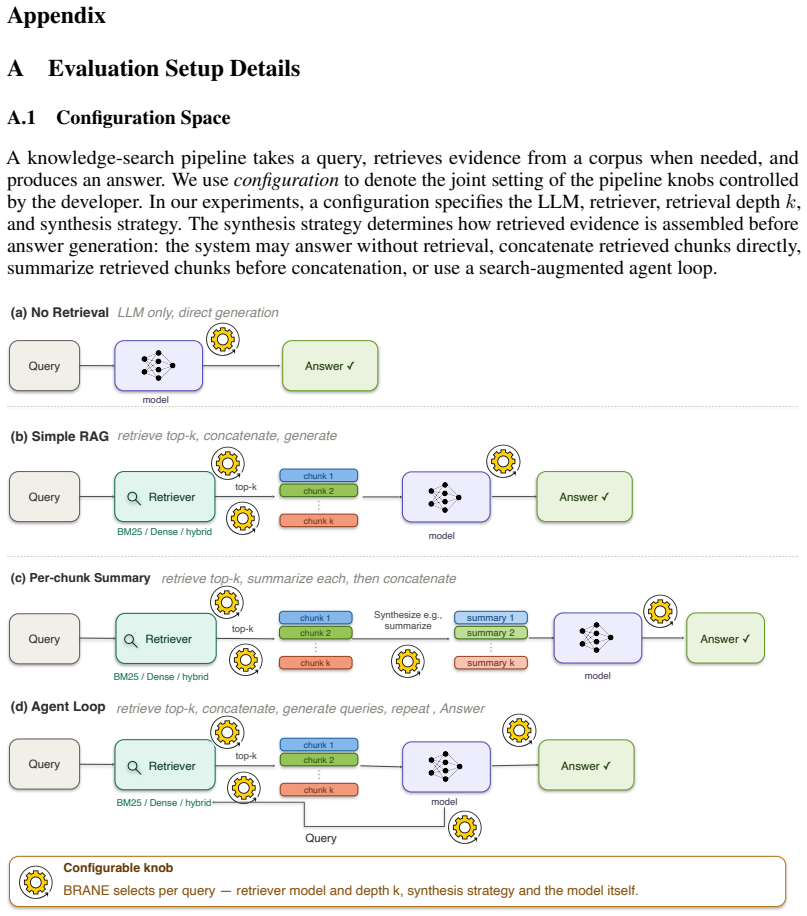
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. Deepresearcher: Scaling deep research via reinforcement learning in real-world environments, 2025. URLhttps://arxiv.org/abs/2504.03160. 13 Appendix A Evaluation Setup Details A.1 Configuration Space A knowledge-search pipeline takes a query, retrieves evidence ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.