Advancing Direct Training for Spiking Neural Networks with Circulate-Firing Neurons and Learnable Gradients
Pith reviewed 2026-06-30 19:56 UTC · model grok-4.3
The pith
A circulate-firing neuron, per-time-step learnable surrogate gradient, and balanced loss let SNNs reach competitive accuracy on standard datasets and transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
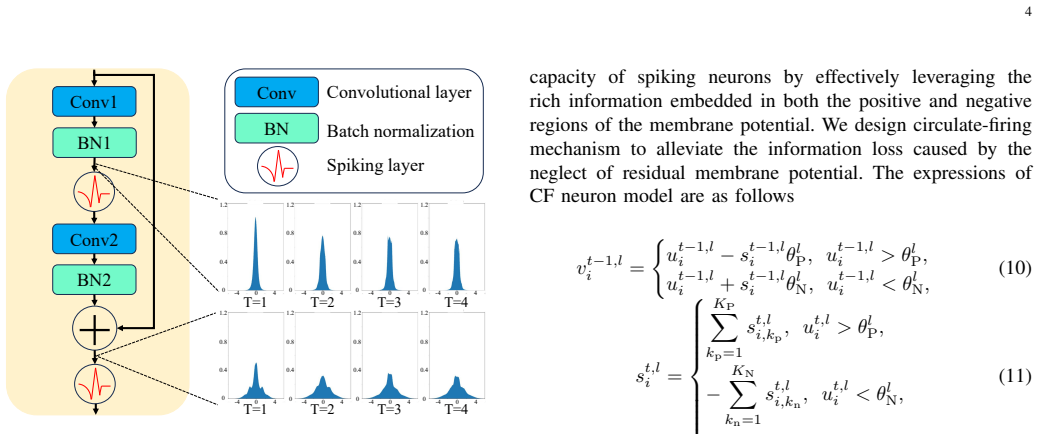
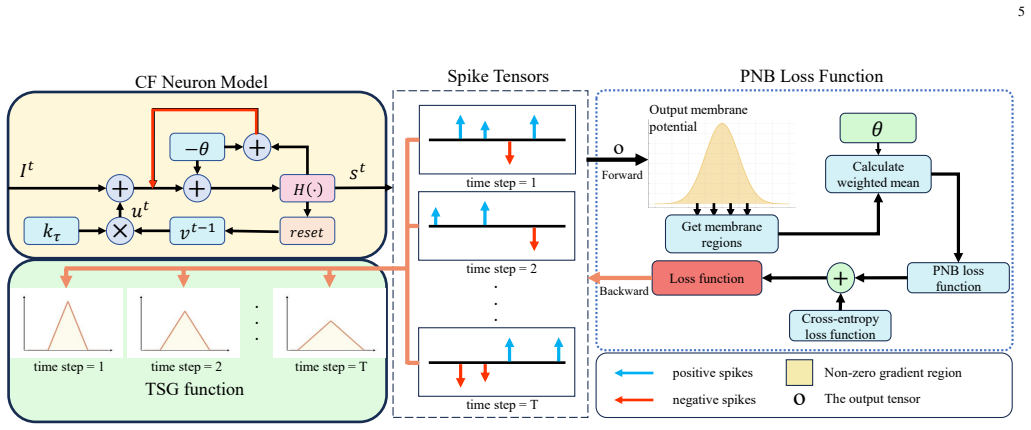
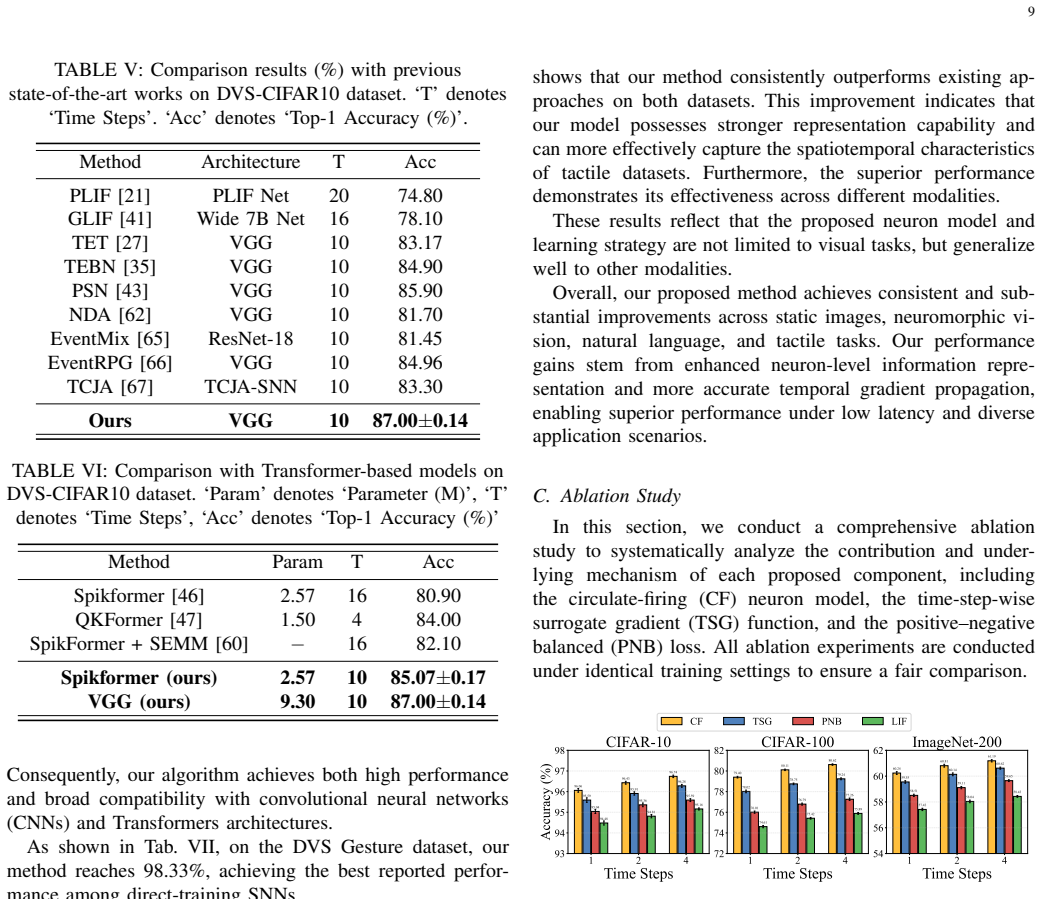
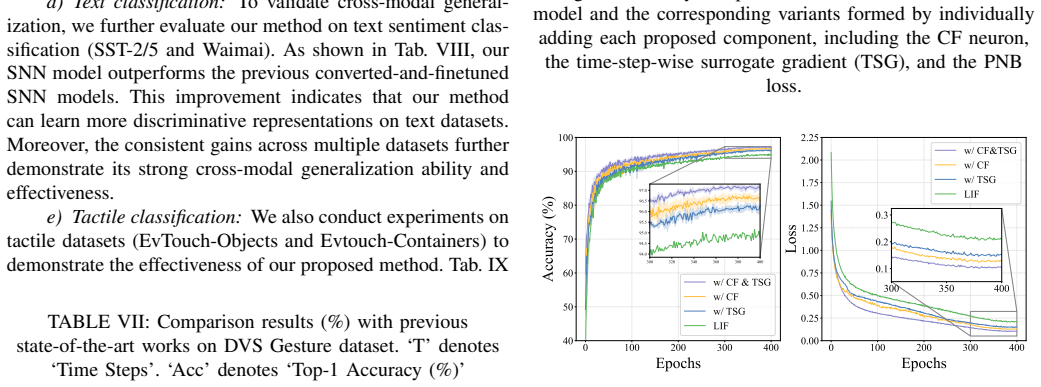
A circulate-firing spiking neuron model that enhances information representation by leveraging membrane potentials more effectively, combined with a time-step-wise learnable surrogate gradient for accurate back-propagation and a positive-negative balanced loss that equalizes membrane-potential contributions, enables direct training of SNNs that achieve competitive performance across multiple datasets and that generalize to transformer architectures while outperforming existing direct-training methods.
What carries the argument
The circulate-firing neuron (which cycles firing behavior to capture richer membrane-potential dynamics) together with the time-step-wise learnable surrogate gradient and the positive-negative balanced loss.
If this is right
- SNNs trained with these components can reach accuracy levels that make them practical alternatives to ANNs on image and sequence tasks.
- The same three changes apply without modification to transformer blocks built from spiking neurons.
- Better use of membrane-potential dynamics becomes the main route to further SNN gains rather than changes to the network topology alone.
- Direct training of SNNs no longer requires separate conversion from pre-trained ANNs.
Where Pith is reading between the lines
- Hardware designs could exploit the circulate-firing pattern to reduce the number of spikes needed per inference.
- Learnable per-step gradients might transfer to other recurrent or stateful network families that currently rely on fixed surrogate rules.
- The balanced loss could be tested on any task where positive and negative activations are known to be imbalanced.
Load-bearing premise
That the measured gains come from the three new components rather than from other unstated differences in the experimental setup or training procedure.
What would settle it
An ablation that removes the circulate-firing neuron, the per-time-step learnable gradient, or the balanced loss one at a time and measures whether accuracy falls back to the level of prior direct-training methods on the same datasets.
Figures

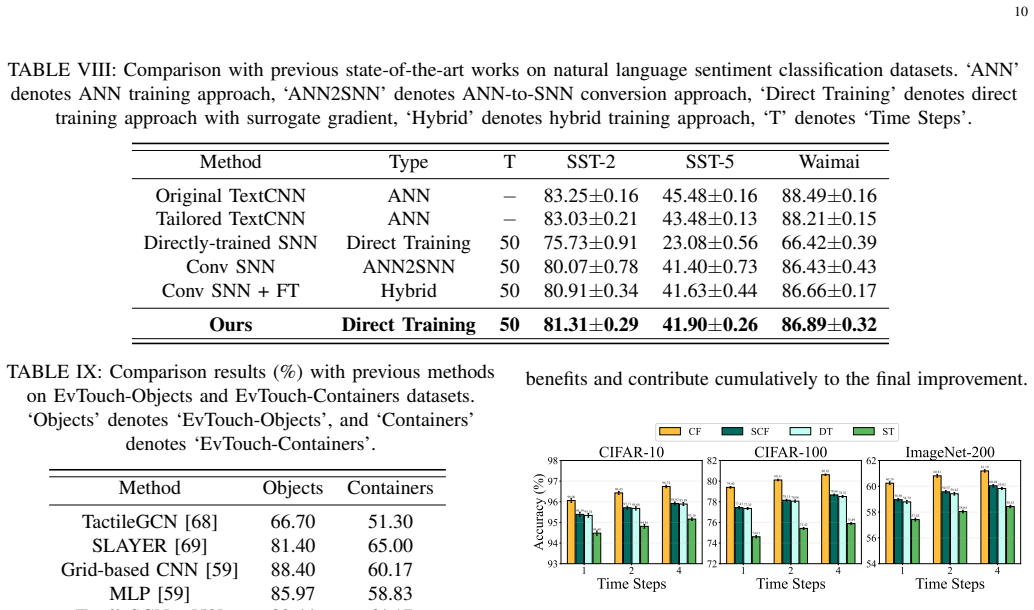
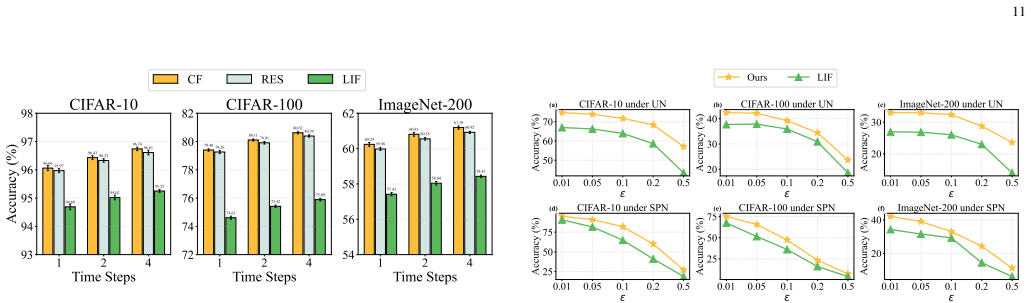
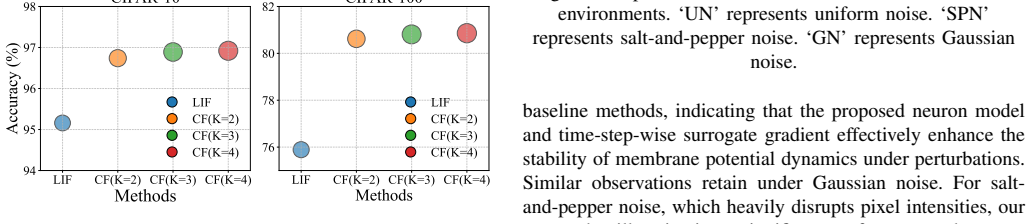
read the original abstract
Spiking Neural Networks (SNNs) have emerged with promising energy-efficient property, yet a substantial performance gap persists compared to Artificial Neural Networks (ANNs). This gap stems from at least two key limitations: first, conventional spiking neurons offer limited information representation capacity, underutilizing the rich dynamics of membrane potentials; second, fixed surrogate gradient (SG) functions across time steps leads to imprecise gradient propagation, impeding effective direct training. To address these two challenges, we propose a new direct training algorithm with three core innovations: first, a circulate-firing spiking neuron model that enhances information representation capacity by leveraging membrane potentials more effectively; second, a time-step-wise learnable surrogate gradient function, enabling accurate gradient estimation during backpropagation; third, a positive-negative balanced loss function to achieve equilibrium between positive and negative membrane potentials and further boost SNN performance. Extensive experiments demonstrate that our methods achieve competitive performance across multiple datasets. Our methods can generalize seamlessly to advanced architectures of Transformer, consistently outperforming existing methods. Our work highlights the effectiveness of further harnessing intrinsic membrane dynamics of SNNs for performance improvement, and thus open a new avenue for advancing high-performance spiking neural architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a direct training method for Spiking Neural Networks addressing two limitations: limited information capacity in conventional spiking neurons and fixed surrogate gradients across time steps. It introduces three components—a circulate-firing neuron model that leverages membrane potential dynamics, a time-step-wise learnable surrogate gradient function, and a positive-negative balanced loss function—and claims these yield competitive performance on multiple datasets while generalizing to Transformer architectures and outperforming existing methods.
Significance. If the attribution of gains to the three components is demonstrated via controlled experiments, the approach could meaningfully advance direct SNN training by better exploiting membrane dynamics, with potential value for energy-efficient neuromorphic systems. Generalization to Transformers would be a notable extension if the performance lifts are isolated from confounding factors.
major comments (2)
- [Abstract] Abstract: the central claim that the circulate-firing neuron, time-step-wise learnable SG, and balanced loss 'directly drive' competitive results and Transformer generalization requires component-wise ablations that hold optimizer, initialization, data augmentation, and baseline re-implementations fixed; the abstract provides no indication that such controls exist in the experimental section, leaving attribution as an assumption rather than a demonstrated result.
- [Abstract] The manuscript states that the methods 'consistently outperforming existing methods' on Transformers, but without reported statistical details, dataset sizes, or baseline re-implementation protocols, the load-bearing claim of seamless generalization cannot be evaluated for robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript arXiv:2605.27412. We provide point-by-point responses to the major comments and commit to revisions to improve clarity on experimental controls and robustness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the circulate-firing neuron, time-step-wise learnable SG, and balanced loss 'directly drive' competitive results and Transformer generalization requires component-wise ablations that hold optimizer, initialization, data augmentation, and baseline re-implementations fixed; the abstract provides no indication that such controls exist in the experimental section, leaving attribution as an assumption rather than a demonstrated result.
Authors: The full manuscript's experimental section includes component-wise ablation studies that isolate the effects of the circulate-firing neuron, learnable surrogate gradient, and balanced loss, with all other factors such as optimizer, initialization, data augmentation, and baseline implementations held fixed. We agree that the abstract should better communicate the presence of these controls to support the attribution claims. We will revise the abstract to explicitly state that the results are supported by such controlled ablations. revision: yes
-
Referee: [Abstract] The manuscript states that the methods 'consistently outperforming existing methods' on Transformers, but without reported statistical details, dataset sizes, or baseline re-implementation protocols, the load-bearing claim of seamless generalization cannot be evaluated for robustness.
Authors: The experimental section reports results on Transformer architectures across specified datasets, including performance metrics with statistical details (means and variances from multiple runs) and dataset sizes. The baseline re-implementation protocols are described in the experimental setup subsection. To make the robustness more evident, we will expand the description of statistical methods and re-implementation details in the revised version. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes three empirical innovations (circulate-firing neuron, time-step-wise learnable SG, balanced loss) and reports competitive results on datasets plus Transformer generalization. No derivation chain, equations, or first-principles results are presented that reduce by construction to fitted inputs, self-definitions, or self-citation load-bearing premises. Performance claims rest on external experimental benchmarks rather than internal renaming or ansatz smuggling. This is the common case of a self-contained empirical proposal with no circularity per the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[3]
Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition,
L. Dong, S. Xu, and B. Xu, “Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5884–5888
2018
-
[4]
End-to-end model-free reinforcement learning for urban driving using implicit affordances,
M. Toromanoff, E. Wirbel, and F. Moutarde, “End-to-end model-free reinforcement learning for urban driving using implicit affordances,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7153–7162
2020
-
[5]
Networks of spiking neurons: the third generation of neural network models,
W. Maass, “Networks of spiking neurons: the third generation of neural network models,”Neural Networks, vol. 10, no. 9, pp. 1659–1671, 1997
1997
-
[6]
Towards artificial general intelligence with hybrid tianjic chip architecture,
J. Pei, L. Deng, S. Song, M. Zhao, Y . Zhang, S. Wu, G. Wang, Z. Zou, Z. Wu, W. Heet al., “Towards artificial general intelligence with hybrid tianjic chip architecture,”Nature, vol. 572, no. 7767, pp. 106–111, 2019
2019
-
[7]
Truenorth: Accelerating from zero to 64 million neurons in 10 years,
M. V . DeBole, B. Taba, A. Amir, F. Akopyan, A. Andreopoulos, W. P. Risk, J. Kusnitz, C. O. Otero, T. K. Nayak, R. Appuswamyet al., “Truenorth: Accelerating from zero to 64 million neurons in 10 years,” Computer, vol. 52, no. 5, pp. 20–29, 2019
2019
-
[8]
Competitive hebbian learn- ing through spike-timing-dependent synaptic plasticity,
S. Song, K. D. Miller, and L. F. Abbott, “Competitive hebbian learn- ing through spike-timing-dependent synaptic plasticity,”Nature neuro- science, vol. 3, no. 9, pp. 919–926, 2000
2000
-
[9]
Spiking deep convolutional neural networks for energy-efficient object recognition,
Y . Cao, Y . Chen, and D. Khosla, “Spiking deep convolutional neural networks for energy-efficient object recognition,”Int. J. Comput. Vision, vol. 113, no. 1, p. 54–66, 2015
2015
-
[10]
Backpropagation through time: what it does and how to do it,
P. Werbos, “Backpropagation through time: what it does and how to do it,”Proceedings of the IEEE, vol. 78, no. 10, pp. 1550–1560, 1990
1990
-
[11]
Construct- ing accurate and efficient deep spiking neural networks with double- threshold and augmented schemes,
Q. Yu, C. Ma, S. Song, G. Zhang, J. Dang, and K. C. Tan, “Construct- ing accurate and efficient deep spiking neural networks with double- threshold and augmented schemes,”IEEE Transactions on Neural Net- works and Learning Systems, vol. 33, no. 4, pp. 1714–1726, 2022
2022
-
[12]
Optimal ann- snn conversion for high-accuracy and ultra-low-latency spiking neural networks,
T. Bu, W. Fang, J. Ding, P. Dai, Z. Yu, and T. Huang, “Optimal ann- snn conversion for high-accuracy and ultra-low-latency spiking neural networks,”arXiv preprint arXiv:2303.04347, 2023
-
[13]
Rmp-snn: Residual membrane potential neuron for enabling deeper high-accuracy and low-latency spiking neural network,
B. Han, G. Srinivasan, and K. Roy, “Rmp-snn: Residual membrane potential neuron for enabling deeper high-accuracy and low-latency spiking neural network,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 13 558–13 567
2020
-
[14]
A free lunch from ann: Towards efficient, accurate spiking neural networks calibration,
Y . Li, S. Deng, X. Dong, R. Gong, and S. Gu, “A free lunch from ann: Towards efficient, accurate spiking neural networks calibration,” inInternational conference on machine learning. PMLR, 2021, pp. 6316–6325
2021
-
[15]
Bridging the gap between anns and snns by calibrating offset spikes,
Z. Hao, J. Ding, T. Bu, T. Huang, and Z. Yu, “Bridging the gap between anns and snns by calibrating offset spikes,”arXiv preprint arXiv:2302.10685, 2023
-
[16]
Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks,
E. O. Neftci, H. Mostafa, and F. Zenke, “Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks,”IEEE, no. 6, 2019
2019
-
[17]
Training deep spiking neural networks using backpropagation,
J. H. Lee, T. Delbruck, and M. Pfeiffer, “Training deep spiking neural networks using backpropagation,”Frontiers in Neuroscience, vol. 10, 2016
2016
-
[18]
Spatio-temporal backpropa- gation for training high-performance spiking neural networks,
Y . Wu, L. Deng, G. Li, J. Zhu, and L. Shi, “Spatio-temporal backpropa- gation for training high-performance spiking neural networks,”Frontiers in Neuroscience, vol. 12, 2018
2018
-
[19]
Going deeper with directly-trained larger spiking neural networks,
H. Zheng, Y . Wu, L. Deng, Y . Hu, and G. Li, “Going deeper with directly-trained larger spiking neural networks,” inAAAI Conference on Artificial Intelligence, 2020
2020
-
[20]
Deep residual learning in spiking neural networks,
W. Fang, Z. Yu, Y . Chen, T. Huang, T. Masquelier, and Y . Tian, “Deep residual learning in spiking neural networks,”Advances in Neural Information Processing Systems, vol. 34, pp. 21 056–21 069, 2021
2021
-
[21]
Incorporating learnable membrane time constant to enhance learning of spiking neural networks,
W. Fang, Z. Yu, Y . Chen, T. Masquelier, T. Huang, and Y . Tian, “Incorporating learnable membrane time constant to enhance learning of spiking neural networks,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 2641–2651
2021
-
[22]
Multi-level firing with spiking ds-resnet: Enabling better and deeper directly-trained spiking neural networks,
L. Feng, Q. Liu, H. Tang, D. Ma, and G. Pan, “Multi-level firing with spiking ds-resnet: Enabling better and deeper directly-trained spiking neural networks,” inProceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, 2022, pp. 2471–2477
2022
-
[23]
Im-loss: Information maximization loss for spiking neural networks,
Y . Guo, Y . Chen, L. Zhang, X. Liu, Y . Wang, X. Huang, and Z. Ma, “Im-loss: Information maximization loss for spiking neural networks,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 156–166
2022
-
[24]
Rmp-loss: Regularizing membrane potential distribution for spiking neural networks,
Y . Guo, X. Liu, Y . Chen, L. Zhang, W. Peng, Y . Zhang, X. Huang, and Z. Ma, “Rmp-loss: Regularizing membrane potential distribution for spiking neural networks,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 391–17 401
2023
-
[25]
Ternary spike: Learning ternary spikes for spiking neural networks,
Y . Guo, Y . Chen, X. Liu, W. Peng, Y . Zhang, X. Huang, and Z. Ma, “Ternary spike: Learning ternary spikes for spiking neural networks,” in 13 Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 11, 2024, pp. 12 244–12 252
2024
-
[26]
Tab: Temporal accumulated batch normalization in spiking neural networks,
H. Jiang, V . Zoonekynd, G. De Masi, B. Gu, and H. Xiong, “Tab: Temporal accumulated batch normalization in spiking neural networks,” inThe Twelfth International Conference on Learning Representations
-
[27]
Temporal efficient training of spiking neural network via gradient re-weighting,
S. Deng, Y . Li, S. Zhang, and S. Gu, “Temporal efficient training of spiking neural network via gradient re-weighting,”arXiv preprint arXiv:2202.11946, 2022
-
[28]
Neuronal competition groups with supervised stdp for spike-based classification,
G. Goupy, P. Tirilly, and I. M. Bilasco, “Neuronal competition groups with supervised stdp for spike-based classification,”arXiv preprint arXiv:2410.17066, 2024
-
[29]
First-spike-based visual categorization using reward- modulated stdp,
M. Mozafari, S. R. Kheradpisheh, T. Masquelier, A. Nowzari-Dalini, and M. Ganjtabesh, “First-spike-based visual categorization using reward- modulated stdp,”IEEE transactions on neural networks and learning systems, vol. 29, no. 12, pp. 6178–6190, 2018
2018
-
[30]
Spikezip- tf: Conversion is all you need for transformer-based snn,
K. You, Z. Xu, C. Nie, Z. Deng, Q. Guo, X. Wang, and Z. He, “Spikezip- tf: Conversion is all you need for transformer-based snn,”arXiv preprint arXiv:2406.03470, 2024
-
[31]
Spatio-temporal approximation: A training-free snn conversion for transformers,
Y . Jiang, K. Hu, T. Zhang, H. Gao, Y . Liu, Y . Fang, and F. Chen, “Spatio-temporal approximation: A training-free snn conversion for transformers,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[32]
Spikedattention: Training-free and fully spike-driven transformer-to-snn conversion with winner-oriented spike shift for softmax operation,
S. Hwang, S. Lee, D. Park, D. Lee, and J. Kung, “Spikedattention: Training-free and fully spike-driven transformer-to-snn conversion with winner-oriented spike shift for softmax operation,”Advances in Neural Information Processing Systems, vol. 37, pp. 67 422–67 445, 2024
2024
-
[33]
Revisiting batch normalization for training low-latency deep spiking neural networks from scratch,
Y . Kim and P. Panda, “Revisiting batch normalization for training low-latency deep spiking neural networks from scratch,”Frontiers in neuroscience, vol. 15, p. 773954, 2021
2021
-
[34]
Membrane potential batch normalization for spiking neural networks,
Y . Guo, Y . Zhang, Y . Chen, W. Peng, X. Liu, L. Zhang, X. Huang, and Z. Ma, “Membrane potential batch normalization for spiking neural networks,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 19 420–19 430
2023
-
[35]
Temporal effective batch normalization in spiking neural networks,
C. Duan, J. Ding, S. Chen, Z. Yu, and T. Huang, “Temporal effective batch normalization in spiking neural networks,”Advances in Neural Information Processing Systems, vol. 35, pp. 34 377–34 390, 2022
2022
-
[36]
Learnable surrogate gradient for direct training spiking neural networks
S. Lian, J. Shen, Q. Liu, Z. Wang, R. Yan, and H. Tang, “Learnable surrogate gradient for direct training spiking neural networks.” inIJCAI, 2023, pp. 3002–3010
2023
-
[37]
Directly training temporal spiking neural network with sparse surrogate gradient,
Y . Li, F. Zhao, D. Zhao, and Y . Zeng, “Directly training temporal spiking neural network with sparse surrogate gradient,”Neural Networks, vol. 179, p. 106499, 2024
2024
-
[38]
Adaptive smoothing gradient learning for spiking neural networks,
Z. Wang, R. Jiang, S. Lian, R. Yan, and H. Tang, “Adaptive smoothing gradient learning for spiking neural networks,” inInternational Confer- ence on Machine Learning. PMLR, 2023, pp. 35 798–35 816
2023
-
[39]
Ltmd: Learning improvement of spiking neural networks with learnable thresholding neurons and moderate dropout,
S. Wang, T. H. Cheng, and M.-H. Lim, “Ltmd: Learning improvement of spiking neural networks with learnable thresholding neurons and moderate dropout,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 28 350–28 362
2022
-
[40]
N. Rathi and K. Roy, “Diet-snn: Direct input encoding with leakage and threshold optimization in deep spiking neural networks,”ArXiv, vol. abs/2008.03658, 2020
-
[41]
Glif: A unified gated leaky integrate-and-fire neuron for spiking neural networks,
X. Yao, F. Li, Z. Mo, and J. Cheng, “Glif: A unified gated leaky integrate-and-fire neuron for spiking neural networks,”Advances in Neural Information Processing Systems, vol. 35, pp. 32 160–32 171, 2022
2022
-
[42]
Tc-lif: A two- compartment spiking neuron model for long-term sequential modelling,
S. Zhang, Q. Yang, C. Ma, J. Wu, H. Li, and K. C. Tan, “Tc-lif: A two- compartment spiking neuron model for long-term sequential modelling,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 15, 2024, pp. 16 838–16 847
2024
-
[43]
Parallel spiking neurons with high efficiency and ability to learn long-term dependencies,
W. Fang, Z. Yu, Z. Zhou, D. Chen, Y . Chen, Z. Ma, T. Masquelier, and Y . Tian, “Parallel spiking neurons with high efficiency and ability to learn long-term dependencies,”Advances in Neural Information Processing Systems, vol. 36, pp. 53 674–53 687, 2023
2023
-
[44]
A progressive training framework for spiking neural networks with learnable multi- hierarchical model,
Z. Hao, X. Shi, Z. Huang, T. Bu, Z. Yu, and T. Huang, “A progressive training framework for spiking neural networks with learnable multi- hierarchical model,” inThe Twelfth International Conference on Learn- ing Representations, 2023
2023
-
[45]
Z. Hao, X. Shi, Z. Pan, Y . Liu, Z. Yu, and T. Huang, “Lm-ht snn: Enhancing the performance of snn to ann counterpart through learnable multi-hierarchical threshold model,”arXiv preprint arXiv:2402.00411, 2024
-
[46]
Spikformer: When spiking neural network meets transformer.arXiv preprint arXiv:2209.15425, 2022
Z. Zhou, Y . Zhu, C. He, Y . Wang, S. Yan, Y . Tian, and L. Yuan, “Spikformer: When spiking neural network meets transformer,”arXiv preprint arXiv:2209.15425, 2022
-
[47]
Qkformer: Hierarchical spiking transformer using qk attention,
C. Zhou, H. Zhang, Z. Zhou, L. Yu, L. Huang, X. Fan, L. Yuan, Z. Ma, H. Zhou, and Y . Tian, “Qkformer: Hierarchical spiking transformer using qk attention,”Advances in Neural Information Processing Systems, vol. 37, pp. 13 074–13 098, 2024
2024
-
[48]
Biologically inspired dynamic thresholds for spiking neural networks,
J. Ding, B. Dong, F. Heide, Y . Ding, Y . Zhou, B. Yin, and X. Yang, “Biologically inspired dynamic thresholds for spiking neural networks,” Advances in Neural Information Processing Systems, vol. 35, pp. 6090– 6103, 2022
2022
-
[49]
An adaptive threshold neuron for recurrent spiking neural networks with nanodevice hardware implementation,
A. Shaban, S. S. Bezugam, and M. Suri, “An adaptive threshold neuron for recurrent spiking neural networks with nanodevice hardware implementation,”Nature Communications, vol. 12, no. 1, p. 4234, 2021
2021
-
[50]
Direct training for spiking neural networks: Faster, larger, better,
Y . Wu, L. Deng, G. Li, J. Zhu, Y . Xie, and L. Shi, “Direct training for spiking neural networks: Faster, larger, better,” inProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, 2019
2019
-
[51]
An overview of gradient descent optimization algorithms,
S. Ruder, “An overview of gradient descent optimization algorithms,”
-
[52]
An overview of gradient descent optimization algorithms
[Online]. Available: https://arxiv.org/abs/1609.04747
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Long short-term memory and learning-to-learn in networks of spiking neurons,
G. Bellec, D. Salaj, A. Subramoney, R. Legenstein, and W. Maass, “Long short-term memory and learning-to-learn in networks of spiking neurons,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[54]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[55]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[56]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[57]
Cifar10-dvs: an event-stream dataset for object classification,
H. Li, H. Liu, X. Ji, G. Li, and L. Shi, “Cifar10-dvs: an event-stream dataset for object classification,”Frontiers in neuroscience, vol. 11, p. 309, 2017
2017
-
[58]
Synaptic plasticity dynamics for deep continuous local learning (decolle),
J. Kaiser, H. Mostafa, and E. Neftci, “Synaptic plasticity dynamics for deep continuous local learning (decolle),”Frontiers in Neuroscience, vol. 14, p. 424, 2020
2020
-
[59]
Recursive deep models for semantic compositionality over a sentiment treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Y . Ng, and C. Potts, “Recursive deep models for semantic compositionality over a sentiment treebank,” inProceedings of the 2013 conference on empirical methods in natural language processing, 2013, pp. 1631–1642
2013
-
[60]
Tactilesgnet: A spiking graph neural network for event-based tactile object recognition,
F. Gu, W. Sng, T. Taunyazov, and H. Soh, “Tactilesgnet: A spiking graph neural network for event-based tactile object recognition,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 9876–9882
2020
-
[61]
Spiking transformer with experts mixture,
Z. Zhou, Y . Lu, Y . Jia, K. Che, J. Niu, L. Huang, X. Shi, Y . Zhu, G. Li, Z. Yuet al., “Spiking transformer with experts mixture,”Advances in Neural Information Processing Systems, vol. 37, pp. 10 036–10 059, 2024
2024
-
[62]
Training spiking neural networks with local tandem learning,
Q. Yang, J. Wu, M. Zhang, Y . Chua, X. Wang, and H. Li, “Training spiking neural networks with local tandem learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 12 662–12 676, 2022
2022
-
[63]
Neuromorphic data augmentation for training spiking neural networks,
Y . Li, Y . Kim, H. Park, T. Geller, and P. Panda, “Neuromorphic data augmentation for training spiking neural networks,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 631–649
2022
-
[64]
Spiking convolutional neural networks for text classification,
C. Lv, J. Xu, and X. Zheng, “Spiking convolutional neural networks for text classification,” 2024
2024
-
[65]
Convolutional Neural Networks for Sentence Classification
Y . Kim, “Convolutional neural networks for sentence classification,” arXiv preprint arXiv:1408.5882, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[66]
Eventmix: An efficient data augmenta- tion strategy for event-based learning,
G. Shen, D. Zhao, and Y . Zeng, “Eventmix: An efficient data augmenta- tion strategy for event-based learning,”Information Sciences, vol. 644, p. 119170, 2023
2023
-
[67]
Eventrpg: event data augmentation with relevance propagation guidance. arxiv,
M. Sun, D. Zhang, Z. Ge, J. Wang, J. Li, Z. Fanget al., “Eventrpg: event data augmentation with relevance propagation guidance. arxiv,” Preprint, 2024
2024
-
[68]
Tcja- snn: Temporal-channel joint attention for spiking neural networks,
R.-J. Zhu, M. Zhang, Q. Zhao, H. Deng, Y . Duan, and L.-J. Deng, “Tcja- snn: Temporal-channel joint attention for spiking neural networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 3, pp. 5112–5125, 2024
2024
-
[69]
Tactilegcn: A graph convolutional network for predicting grasp stability with tactile sensors,
A. Garcia-Garcia, B. S. Zapata-Impata, S. Orts-Escolano, P. Gil, and J. Garcia-Rodriguez, “Tactilegcn: A graph convolutional network for predicting grasp stability with tactile sensors,” in2019 International Joint Conference on Neural Networks (IJCNN). IEEE, 2019, pp. 1–8
2019
-
[70]
Slayer: Spike layer error reassignment in time,
S. B. Shrestha and G. Orchard, “Slayer: Spike layer error reassignment in time,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[71]
Spiking deep residual networks,
Y . Hu, H. Tang, and G. Pan, “Spiking deep residual networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 8, pp. 5200–5205, 2021. 14
2021
-
[72]
Neuromorphic architectures for spiking deep neural networks,
G. Indiveri, F. Corradi, and N. Qiao, “Neuromorphic architectures for spiking deep neural networks,” in2015 IEEE International Electron Devices Meeting (IEDM). IEEE, 2015, pp. 4–2
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.