RE-TRIANGLE: Does TRIANGLE Enable Multimodal Alignment Beyond Cosine Similarity in Retrieval?
Pith reviewed 2026-06-30 15:00 UTC · model grok-4.3
The pith
TRIANGLE's hypersphere triplet minimization improves zero-shot multimodal retrieval but resists exact reproduction from scratch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
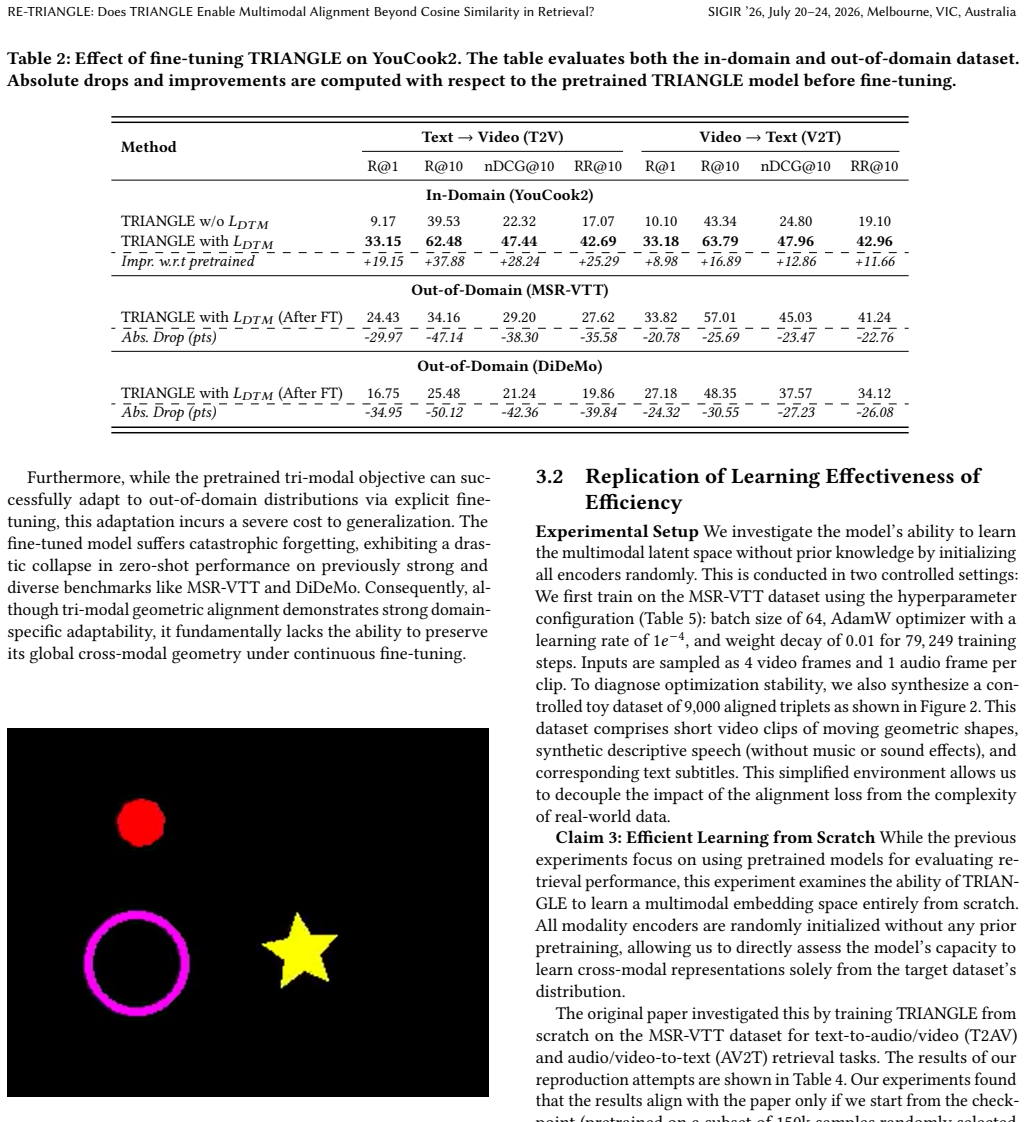
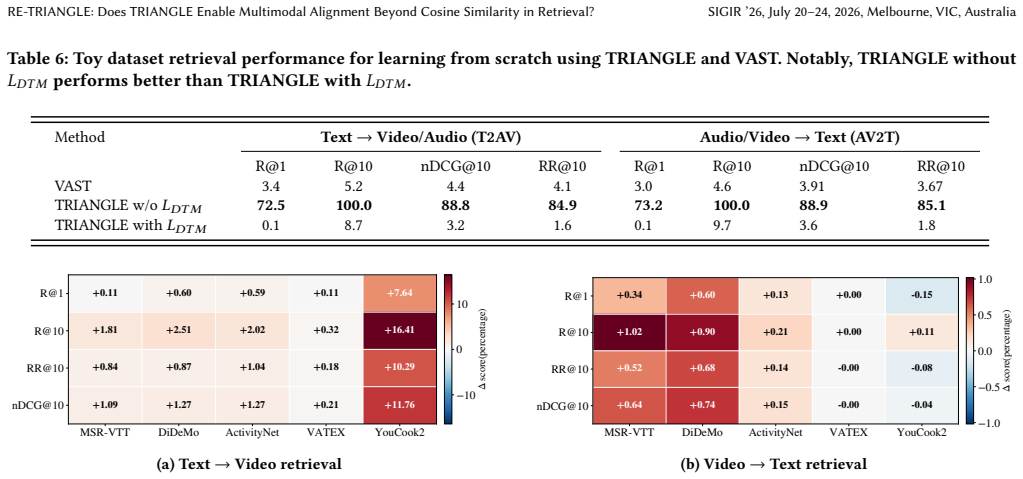
The paper reports that TRIANGLE outperforms pairwise baselines in zero-shot settings, achieving Recall@1 gains of up to +8.7 points, though benefits are domain-dependent. It fails to reproduce the reported learning-from-scratch results, attributing this to instability when jointly optimizing geometric alignment with Data-Text Matching loss, as diagnosed via a synthetic toy dataset. Cosine regularization is observed to stabilize text-to-video retrieval primarily, and fine-tuning with domain supervision amplifies geometric benefits while reducing cross-dataset generalization.
What carries the argument
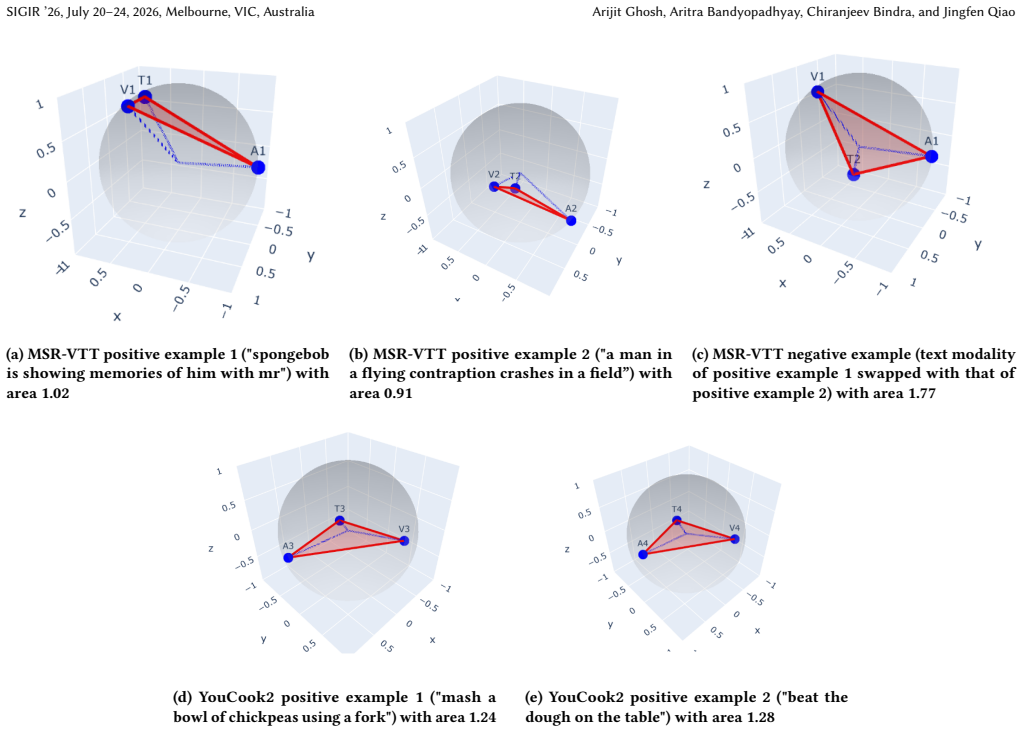
TRIANGLE geometric objective that minimizes the area of modality triplets on a hypersphere to enforce holistic alignment between anchor and peripheral modalities.
Load-bearing premise
The original TRIANGLE training procedure and hyper-parameters can be exactly replicated from prior work so that any failure to reproduce is attributable to the geometric objective rather than implementation differences.
What would settle it
A stable training run from scratch that jointly optimizes the TRIANGLE geometric loss with DTM loss and recovers the originally reported performance metrics on the same datasets.
Figures

read the original abstract
Multimodal alignment is critical for bridging the semantic gap in information retrieval. However, traditional pairwise strategies introduce a geometric blind spot: while they align anchor modalities (e.g., text) with others, they lack constraints to enforce mutual consistency between peripheral modalities (e.g., video and audio). The TRIANGLE framework addresses this by minimizing the area of modality triplets on a hypersphere to enforce holistic alignment. In this reproducibility study, we verify the robustness of this geometric objective for retrieval tasks. We confirm that TRIANGLE outperforms pairwise baselines in zero-shot settings, achieving Recall@1 gains of up to +8.7 points, though benefits are domain-dependent. However, we fail to reproduce the reported learning-from-scratch results. Analysis using a synthetic toy dataset attributes this to instability when jointly optimizing geometric alignment with Data-Text Matching (DTM) loss. Furthermore, we find that cosine regularization primarily stabilizes text-to-video retrieval, and fine-tuning with domain supervision amplifies geometric benefits but reduces cross-dataset generalization. Our findings support the efficacy of geometric alignment while highlighting critical optimization sensitivities. Code available at https://github.com/ARIJIT00171/RE-TRIANGLE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This is a reproducibility study of the TRIANGLE geometric alignment framework for multimodal retrieval. The manuscript confirms zero-shot Recall@1 gains of up to +8.7 points over pairwise baselines (domain-dependent), but reports failure to reproduce the original learning-from-scratch results. It attributes the failure to optimization instability when jointly optimizing the TRIANGLE geometric objective with DTM loss, supported by a synthetic toy dataset analysis. Secondary findings note that cosine regularization stabilizes text-to-video retrieval and that domain fine-tuning amplifies geometric benefits at the cost of cross-dataset generalization. Code is provided.
Significance. If the reproduction details are shown to match the original exactly, the work would usefully document both the zero-shot efficacy of triplet-area minimization on the hypersphere and the practical sensitivities of combining it with standard contrastive losses. The open code and toy-dataset instability demonstration are concrete strengths that could inform future multimodal alignment research.
major comments (3)
- [Abstract and §4 (learning-from-scratch results)] The central attribution of learning-from-scratch non-reproducibility to instability in the geometric + DTM joint optimization (Abstract, §4) is load-bearing for the paper's conclusions yet rests on the unverified premise that every hyperparameter, loss weight, optimizer setting, and data pipeline exactly matches the prior TRIANGLE work. No side-by-side replication checklist or comparison table is provided, so alternative explanations (implementation drift) cannot be excluded.
- [Abstract and results tables] Reported Recall@1 numbers (Abstract, Table 2 or equivalent) lack error bars, number of runs, or explicit data-split descriptions, making it impossible to judge whether the +8.7-point gains are statistically reliable or sensitive to random seeds.
- [§5 (toy dataset)] The synthetic toy dataset analysis (§5) demonstrates instability but does not include an ablation that isolates the geometric term while holding all other factors fixed to the original implementation; this weakens the causal link to the TRIANGLE objective.
minor comments (2)
- [Title and Abstract] The title poses a question about alignment 'beyond cosine similarity,' but the abstract and conclusions do not explicitly quantify how much of the observed gain is attributable to the geometric term versus other factors; a direct comparison sentence would improve clarity.
- [Methods] Notation for the triplet-area loss and its relation to the original TRIANGLE equations is introduced without a dedicated methods subsection restating the prior formulation; readers must consult the cited work to verify equivalence.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our reproducibility study. We address each of the major comments below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (learning-from-scratch results)] The central attribution of learning-from-scratch non-reproducibility to instability in the geometric + DTM joint optimization (Abstract, §4) is load-bearing for the paper's conclusions yet rests on the unverified premise that every hyperparameter, loss weight, optimizer setting, and data pipeline exactly matches the prior TRIANGLE work. No side-by-side replication checklist or comparison table is provided, so alternative explanations (implementation drift) cannot be excluded.
Authors: We agree that providing a side-by-side replication checklist would better substantiate our claim that the reproduction matches the original setup. In the revised manuscript, we will include a detailed comparison table listing the key hyperparameters, loss weights, optimizer settings, data pipelines, and other implementation details from both our study and the original TRIANGLE paper. This will help exclude implementation drift as an alternative explanation. revision: yes
-
Referee: [Abstract and results tables] Reported Recall@1 numbers (Abstract, Table 2 or equivalent) lack error bars, number of runs, or explicit data-split descriptions, making it impossible to judge whether the +8.7-point gains are statistically reliable or sensitive to random seeds.
Authors: This is a valid point. The reported gains would be more robust with statistical measures. We will perform additional runs with different random seeds and report mean Recall@1 with standard deviations in the revised abstract and tables. We will also add explicit descriptions of the data splits used. revision: yes
-
Referee: [§5 (toy dataset)] The synthetic toy dataset analysis (§5) demonstrates instability but does not include an ablation that isolates the geometric term while holding all other factors fixed to the original implementation; this weakens the causal link to the TRIANGLE objective.
Authors: We appreciate this observation. The toy dataset was constructed to illustrate the optimization challenges in the joint setting. To address the request for an isolating ablation, in the revision we will add an experiment that varies only the presence of the geometric term while keeping other components fixed, to more directly link the instability to the TRIANGLE objective. revision: yes
Circularity Check
Reproducibility study exhibits no circular derivation or self-referential reduction
full rationale
This is an external reproducibility study of the TRIANGLE framework rather than a self-contained derivation of new theoretical results. The central claims rest on empirical verification (zero-shot Recall@1 gains up to +8.7) and a failure to reproduce learning-from-scratch results, with attribution to optimization instability supported by a synthetic toy dataset analysis. No equations, fitted parameters, or predictions are presented that reduce by construction to the paper's own inputs or prior self-citations. The work does not invoke uniqueness theorems, smuggle ansatzes, or rename known results as novel organization. Self-citation of the original TRIANGLE procedure is present but not load-bearing for a circular reduction, as the study explicitly tests and partially falsifies aspects of the prior claims. Per the hard rules, this qualifies as a normal non-finding with only minor self-citation that does not affect the central empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. 2017. Localizing moments in video with natural language. In Proceedings of the IEEE international conference on computer vision. 5803–5812
2017
-
[2]
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles
-
[3]
InProceedings of the ieee conference on computer vision and pattern recognition
Activitynet: A large-scale video benchmark for human activity understand- ing. InProceedings of the ieee conference on computer vision and pattern recognition. 961–970
-
[4]
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. 2023. Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset.Advances in Neural Information Processing Systems36 (2023), 72842–72866
2023
-
[5]
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, Wanxiang Che, Xiangzhan Yu, and Furu Wei. 2023. BEATs: Audio Pre-Training with Acoustic Tokenizers. InProceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara En...
2023
-
[6]
Giordano Cicchetti, Eleonora Grassucci, and Danilo Comminiello. 2026. A triangle enables multimodal alignment beyond cosine similarity.Advances in Neural Information Processing Systems38 (2026), 112004–112022
2026
-
[7]
Giordano Cicchetti, Eleonora Grassucci, Luigi Sigillo, and Danilo Comminiello
-
[8]
InInterna- tional Conference on Learning Representations, Vol
Gramian multimodal representation learning and alignment. InInterna- tional Conference on Learning Representations, Vol. 2025. 42128–42149
2025
-
[9]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[10]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang
-
[11]
InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Clap learning audio concepts from natural language supervision. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[12]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. 2025. ColPali: Efficient Document Retrieval with Vision Language Models. InThe Thirteenth International Conference on Learn- ing Representations. https://proceedings.iclr.cc/paper_files/paper/2025/hash/ 99e9e141aafc314f76b0ca3dd66898b3-Abstract-Conference.html
2025
-
[13]
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Audio set: An ontology and human-labeled dataset for audio events. In2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 776–780
2017
-
[14]
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. 2023. ImageBind: One Embedding Space To Bind Them All. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 15180–15190
2023
-
[15]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision- language representation learning with noisy text supervision. InInternational conference on machine learning. PMLR, 4904–4916
2021
-
[16]
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. Audiocaps: Generating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 119–132
2019
-
[18]
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. 2022. CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning.Neurocomput.508, C (Oct. 2022), 293–304. doi:10.1016/j.neucom. 2022.07.028
-
[19]
Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin
-
[20]
In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Unifying multimodal retrieval via document screenshot embedding. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 6492–6505
2024
-
[21]
Jingfen Qiao, Jia-Huei Ju, Xinyu Ma, Evangelos Kanoulas, and Andrew Yates. 2025. Reproducibility, Replicability, and Insights into Visual Document Retrieval with Late Interaction. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for Computing Machinery, ...
-
[22]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[23]
Adriel Saporta, Aahlad Manas Puli, Mark Goldstein, and Rajesh Ranganath. 2024. Contrasting with Symile: Simple Model-Agnostic Representation Learning for Unlimited Modalities.Advances in Neural Information Processing Systems37 (2024), 56919–56957
2024
-
[24]
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. 2023. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Toshimitsu Uesaka, Taiji Suzuki, Yuhta Takida, Chieh-Hsin Lai, Naoki Murata, and Yuki Mitsufuji. 2025. Weighted Point Set Embedding for Multimodal Con- trastive Learning Toward Optimal Similarity Metric. InInternational Conference on Learning Representations, Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (Eds.), Vol. 2025. 32997–33018. https://proceedings.i...
2025
-
[26]
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. 2019. Vatex: A large-scale, high-quality multilingual dataset for video- and-language research. InProceedings of the IEEE/CVF international conference on computer vision. 4581–4591
2019
-
[27]
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. 2016. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE conference on computer vision and pattern recognition. 5288–5296
2016
-
[28]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid Loss for Language Image Pre-Training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 11975–11986
2023
-
[29]
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, and Hongsheng Li. 2022. Pointclip: Point cloud understanding by clip. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8552–8562
2022
-
[30]
Luowei Zhou, Chenliang Xu, and Jason Corso. 2018. Towards automatic learning of procedures from web instructional videos. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.